






 本文详细介绍了如何使用浏览器开发者工具分析快手短视频的网络数据包,找到视频标题和链接。通过步骤演示了从打开网页、使用开发者工具、查找关键数据到编写Python爬虫代码的过程。代码中展示了如何伪装请求头并发送POST请求获取视频信息,最终解析并下载视频。
本文详细介绍了如何使用浏览器开发者工具分析快手短视频的网络数据包,找到视频标题和链接。通过步骤演示了从打开网页、使用开发者工具、查找关键数据到编写Python爬虫代码的过程。代码中展示了如何伪装请求头并发送POST请求获取视频信息,最终解析并下载视频。
一、思路分析:
第一步、进入浏览器打开快手的网址:【快手短视频App】快手,拥抱每一种生活
为了方便内容的获取,可以登录账号进入个人主页在关注里面随机找一个博主的视频,进行操作。(图1所)
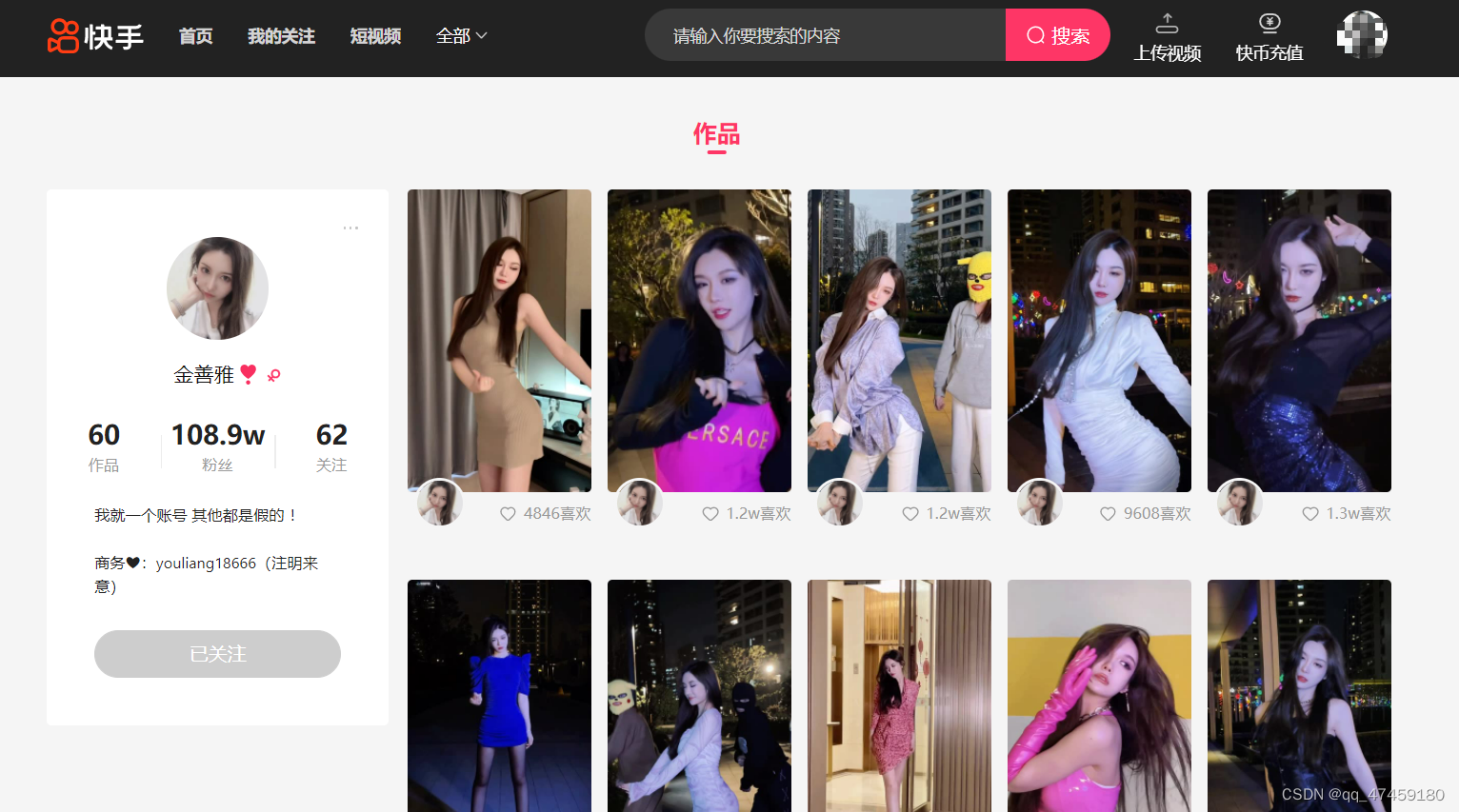
图1
第二步,辅助工具使用:
鼠标右键网页点击检查,打开开发者工具。然后我们要找到network这个面板,进入后再刷新网页(图2所示),会在all下面出现该网页的全部数据包。我们再点开一个视频,会刷新新的数据包出来(图3所示)。这是因为我们要找到一个包含视频内容的一个数据包。如何找到呢?
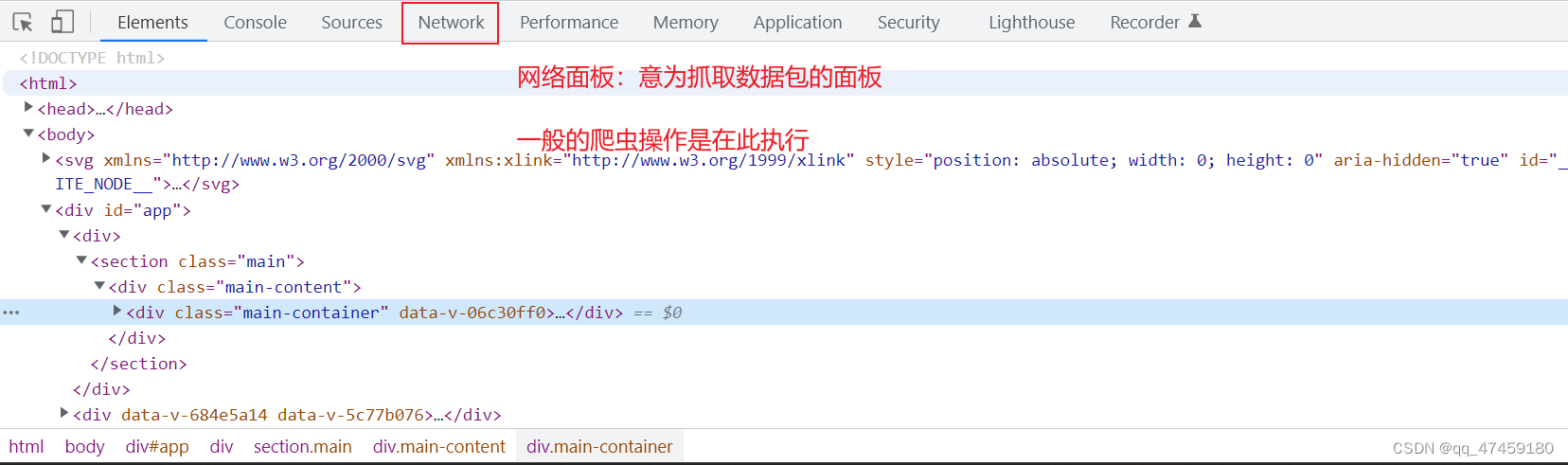
图2
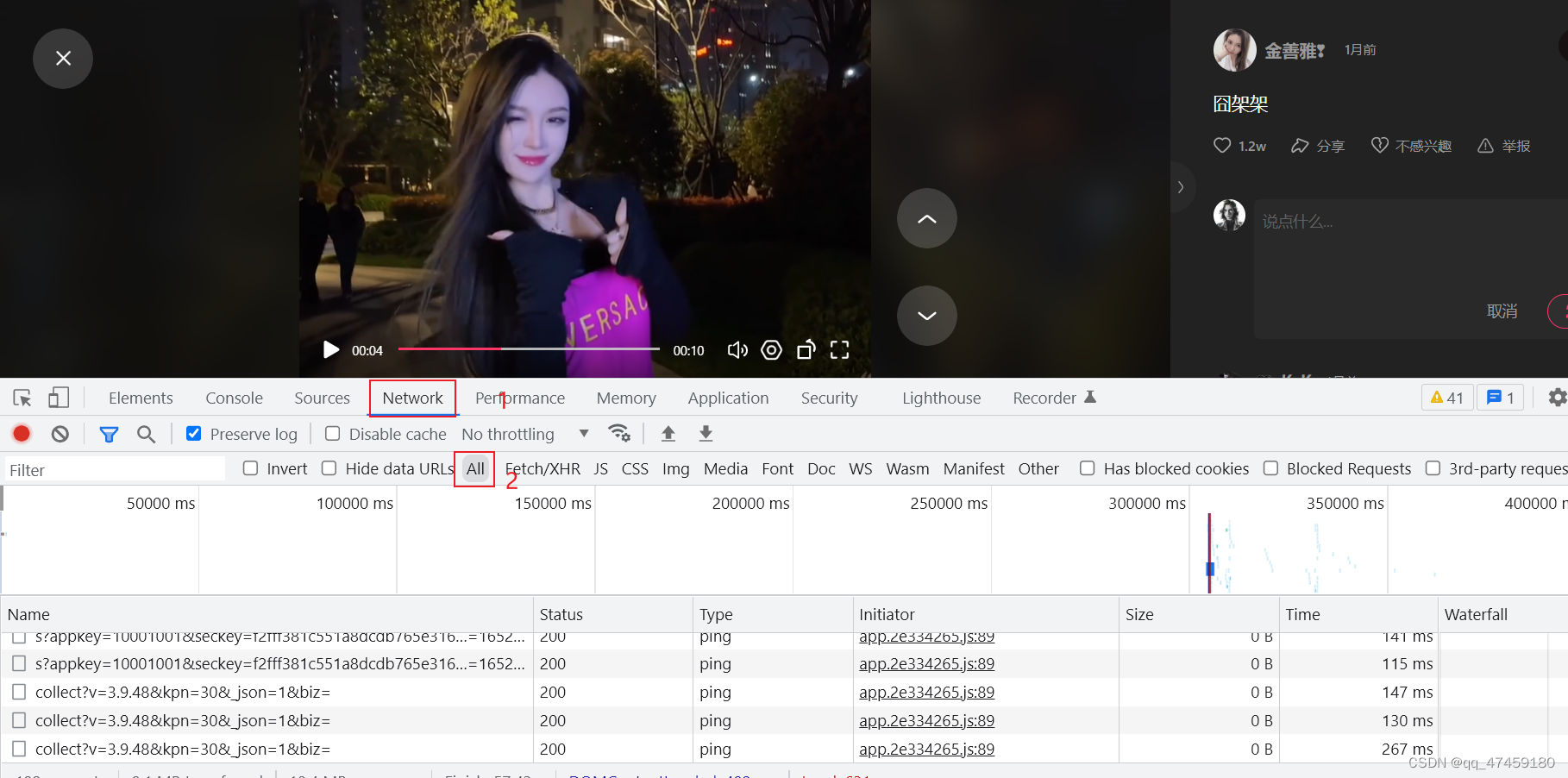
图3
第三步、数据来源分析:
可以直接找到视频的标题,也就是文案。我们Ctrl+C复制一下,然后到开发者工具里面,找打一个像放大镜一样的东西,他的功能就是搜索,把标题内容输入后,按回车就能看到新数据包出现。(如图4、图5所示)
对得到的数据包进行进一步分析。在response里面不方便查看,可以在preview里面分析(图6所示)有0到19共20条数据。
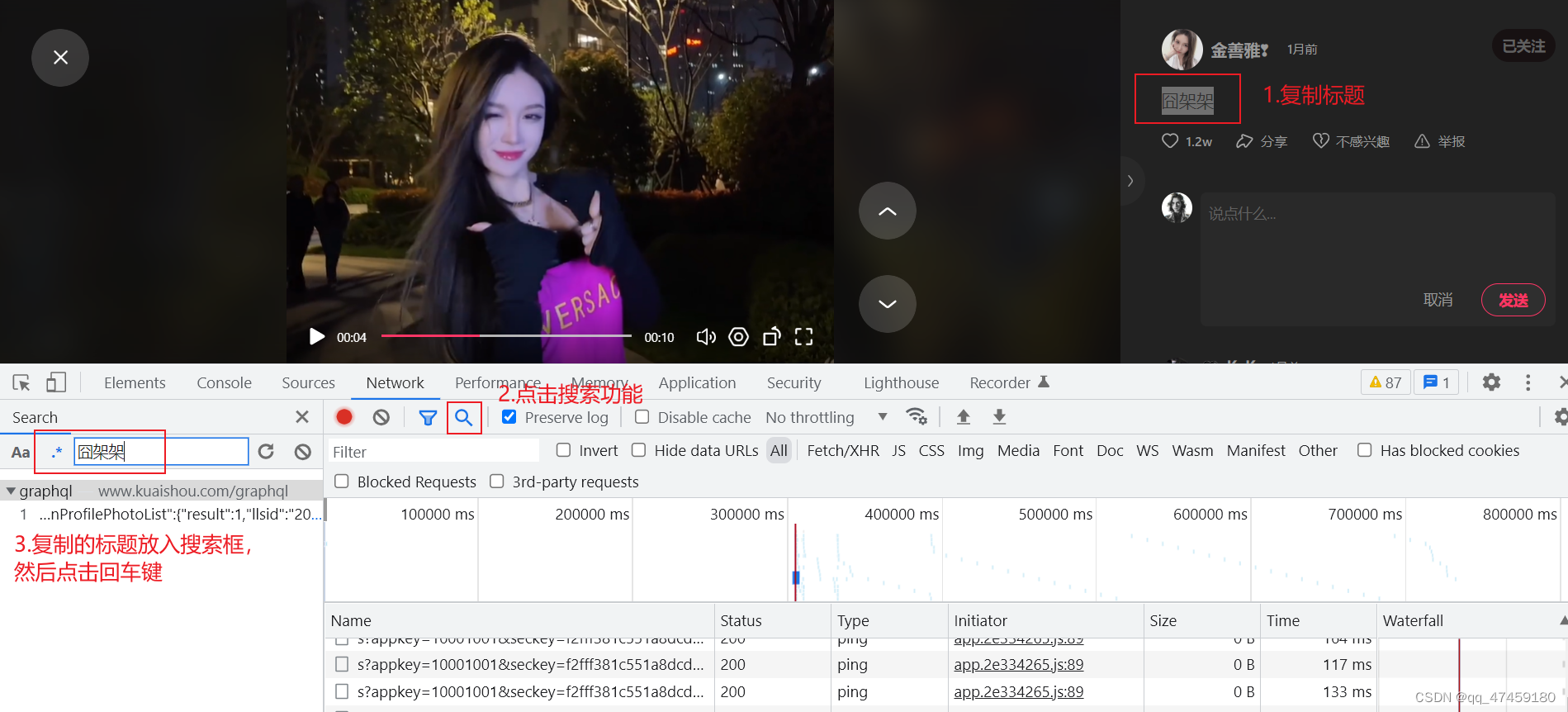
图4
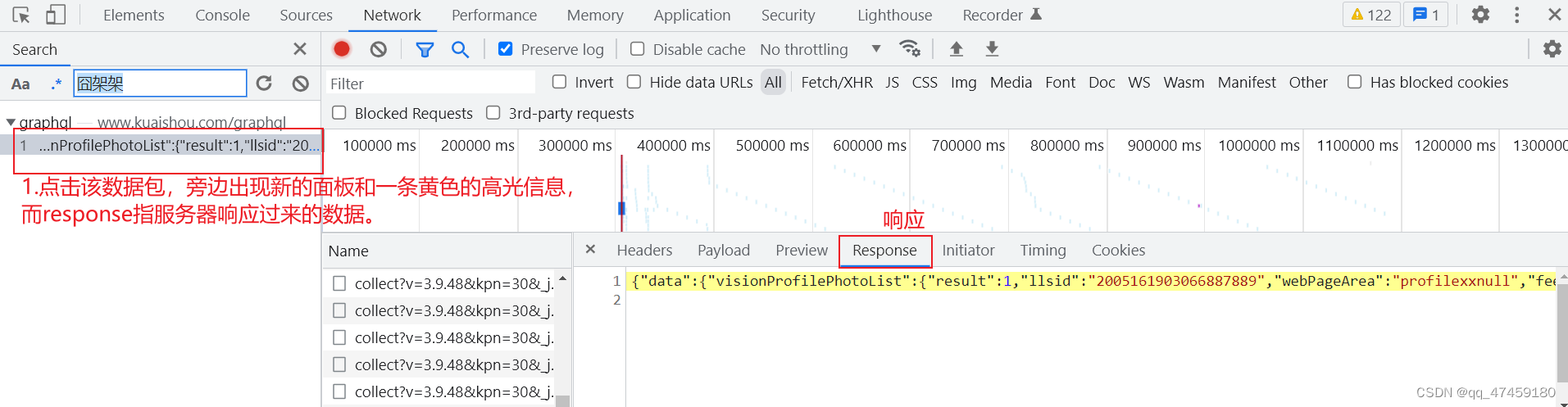
图5
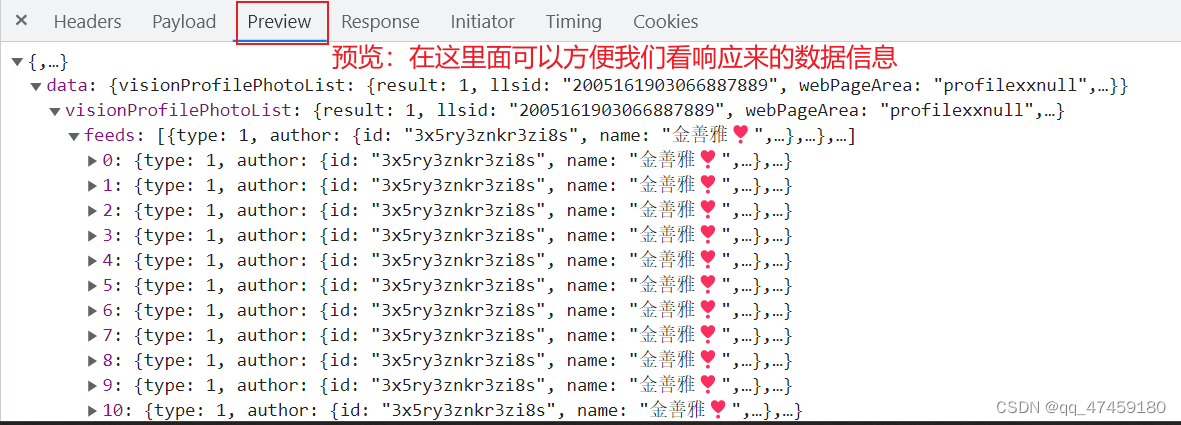
图6
第四步:找视频链接和标题:
我们点开第0条数据查看,在这里面有个值photo,photo里面有caption和photoUrl,他们分别代表标题和视频链接。(图7和图8所示)再进一步确定到网址的链接。(如图9所示)该网页的请求方式是post带参请求。和get请求不一样的是,PSOT请求的参数信息大部分隐藏。(图10)
如果想换爬取其他快手博主的视频,只需要改一下PSOT信息。
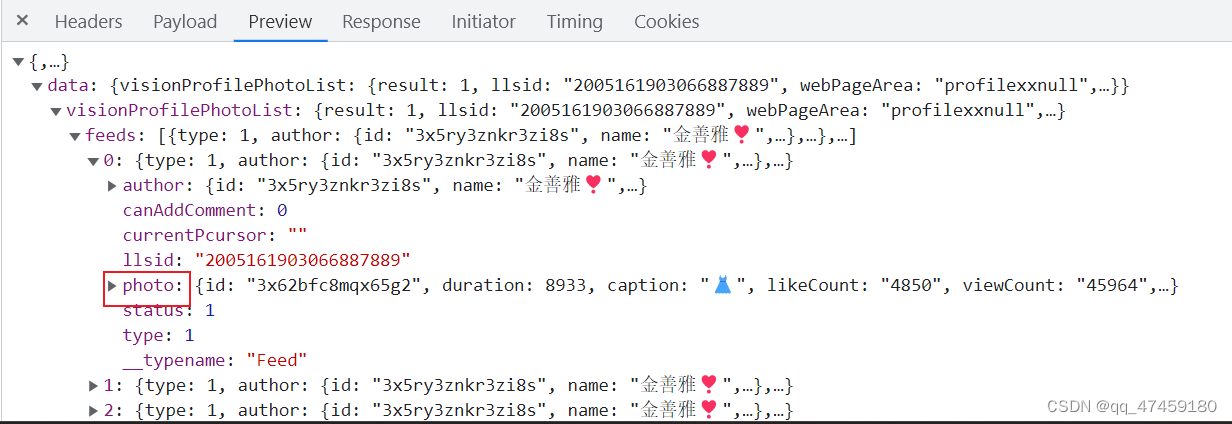
图7
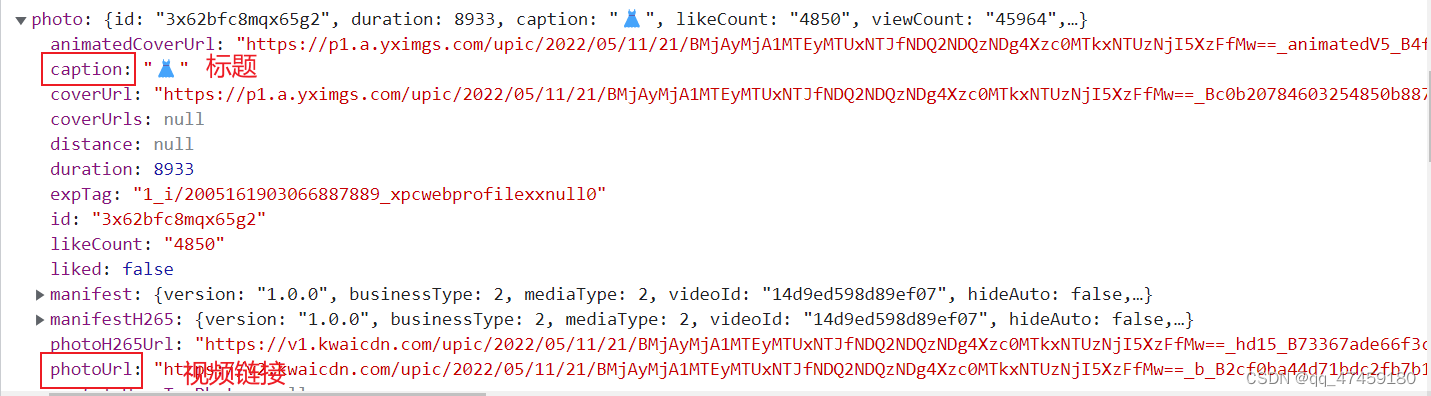 图8
图8
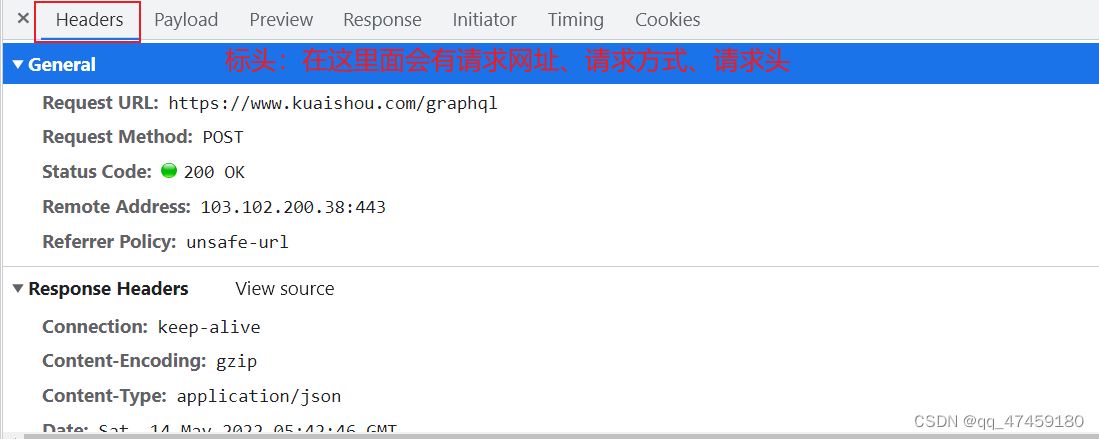
图9

图10
二、代码编写
#导入数据请求包和格式化输出
import requests
import pprint
#1.确定爬取的网址 也就是刚刚数据源分析得出来的网址
url='https://www.kuaishou.com/graphql'
# 2.加入参数
data={
'operationName': "visionProfilePhotoList",
'query': "fragment photoContent on PhotoEntity {\n id\n duration\n caption\n likeCount\n viewCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n __typename\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n __typename\n}\n\nquery visionProfilePhotoList($pcursor: String, $userId: String, $page: String, $webPageArea: String) {\n visionProfilePhotoList(pcursor: $pcursor, userId: $userId, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n ...feedContent\n __typename\n }\n hostName\n pcursor\n __typename\n }\n}\n",
'variables': {'userId': "3x3iabhcnyqpjry", 'pcursor': "", 'page': "profile"}
}
#3.伪装请求头==把爬虫工具变成浏览器
headers={
'content-type':'application/json',
'Cookie':'kpf=PC_WEB; kpn=KUAISHOU_VISION; clientid=3; did=web_ce160109a1bf80d6944c513ac1b89e35; client_key=65890b29; didv=1650350313666; userId=280125945; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqAB_lK0btH-z_yagSgMpgATInBwZ4__ULXh3W99D5dkU0egbhnM8iwL9DWt7LRUabIrw-lH0VAAhuvd68v0el3bpvbZQ3uXTOPbtvBBiJpYqnv_JmxJEedSw-mCHzksLi4e6nI6N8ZTmhy47vnJF3XE0jnXZnhA9fB_iI2ML3epLJiTeAM5SN8_yT7_59JamLdhzlPNE0Rp3FlUVMtMEhgKaxoSzFZBnBL4suA5hQVn0dPKLsMxIiBpDnAKlJAXQmofMqNYmrl6JSlHwTaiBKwxKDhxfPW2PigFMAE; kuaishou.server.web_ph=7fb016f4c4ed842ab0ea0f9d8c00224d4b99',
'Host':'www.kuaishou.com',
'Origin':'https://www.kuaishou.com',
'Referer':'https://www.kuaishou.com/profile/3x3iabhcnyqpjry',
'sec-ch-ua':'" Not A;Brand";v="99", "Chromium";v="99", "Google Chrome";v="99"',
'sec-ch-ua-mobile':'?0',
'sec-ch-ua-platform':'"Windows"',
'Sec-Fetch-Dest':'empty',
'Sec-Fetch-Mode':'cors',
'Sec-Fetch-Site':'same-origin',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
}
# 4.发送请求 post请求 可以直接转JSON格式
response=requests.post(url=url,json=data,headers=headers)
# 5.获取数据 .json 拿到字典类型数据
# pprint.pprint(response.json())
# 6.解析数据 字典 键值对
feeds=response.json()['data']['visionProfilePhotoList']['feeds']
for feed in feeds:
# 标题
caption=feed['photo']['caption']
photoUrl=feed['photo']['photoUrl']
print(caption,photoUrl)
# 转化成二进制
videro_url=requests.get(url=photoUrl).content
#保存数据
with open('video\\'+caption+'.mp4','wb')as f:
f.write(videro_url)


















 980
980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









