







前言:
推荐一个把自动化和爬虫进行完美结合的框架DP库,目前是属于一个开源阶段,非常适合一些正在学习逆向但是基础又不算很好的朋友,他兼备爬虫的高效率和自动化的便捷易懂。具体的开发文档我放在下面了。这个技术在圈内现在是引发了一个热潮,像是瑞数加密和cloudflare都可以用他来解决!
注意事项:如果你的dp再采集数据过程中一直未响应,建议直接升级更新一下
https://drissionpage.cn/get_start/installation https://drissionpage.cn/get_start/installation
https://drissionpage.cn/get_start/installation
我们用它来简单的去抓取下boss直聘平台的基本简历要求信息!
详细步骤:
进入详情列表页访问网站!执行的结果,不被平台检测!还会持续保持登录状态,不需要处理boss的加密参数Zp_token。
from DrissionPage import ChromiumPage
cp = ChromiumPage()
cp.get('https://www.zhipin.com/web/geek/job?query=python&city=100010000')f12进行接口文档搜索 然后选择其中的部分参数 进行数据监听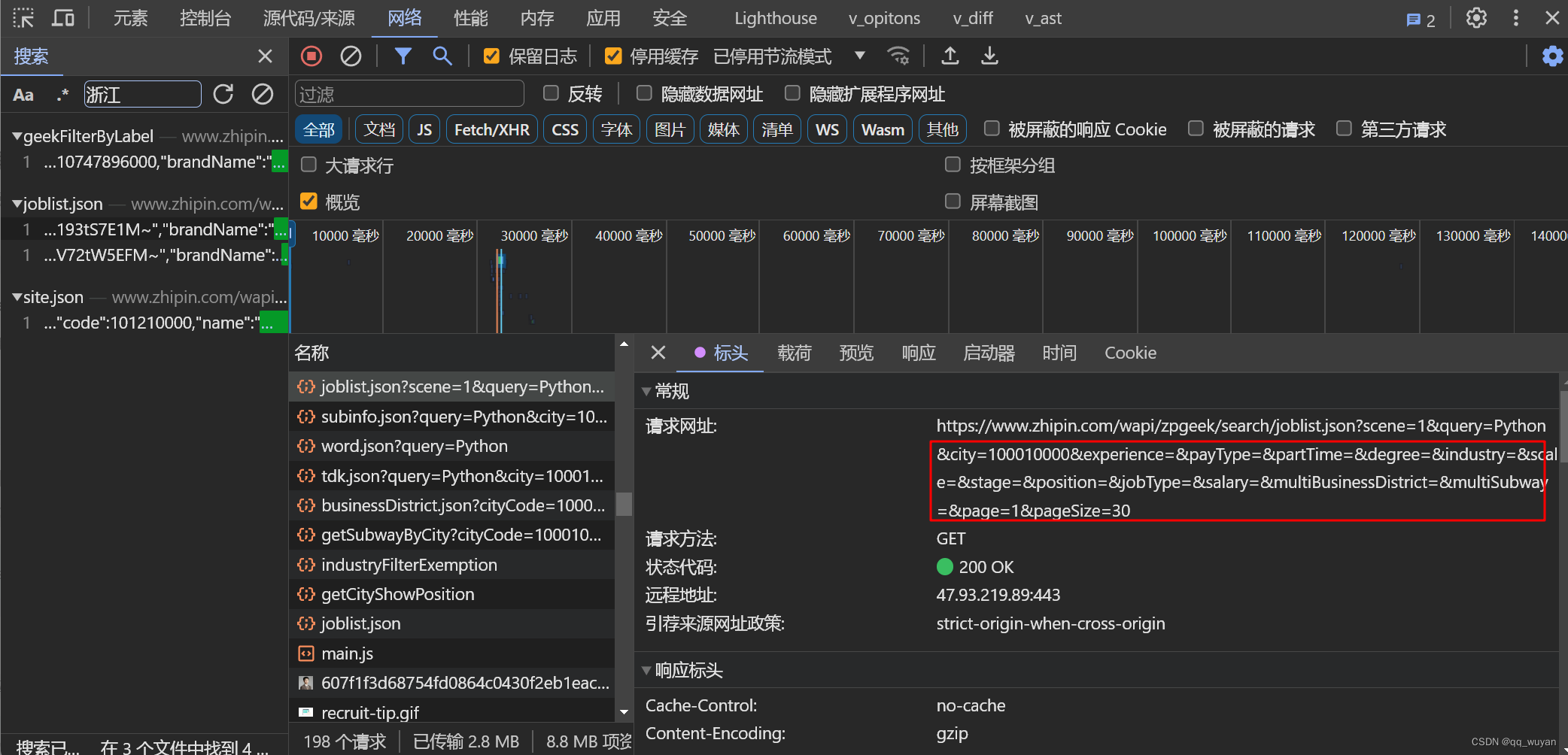
然后你千思万想的数据就这么干下来了!都感觉以前做boss搁几天就给这程序改脚本的操作真的是一坨。。。

然后基本的数据就可以直接这样获取到了
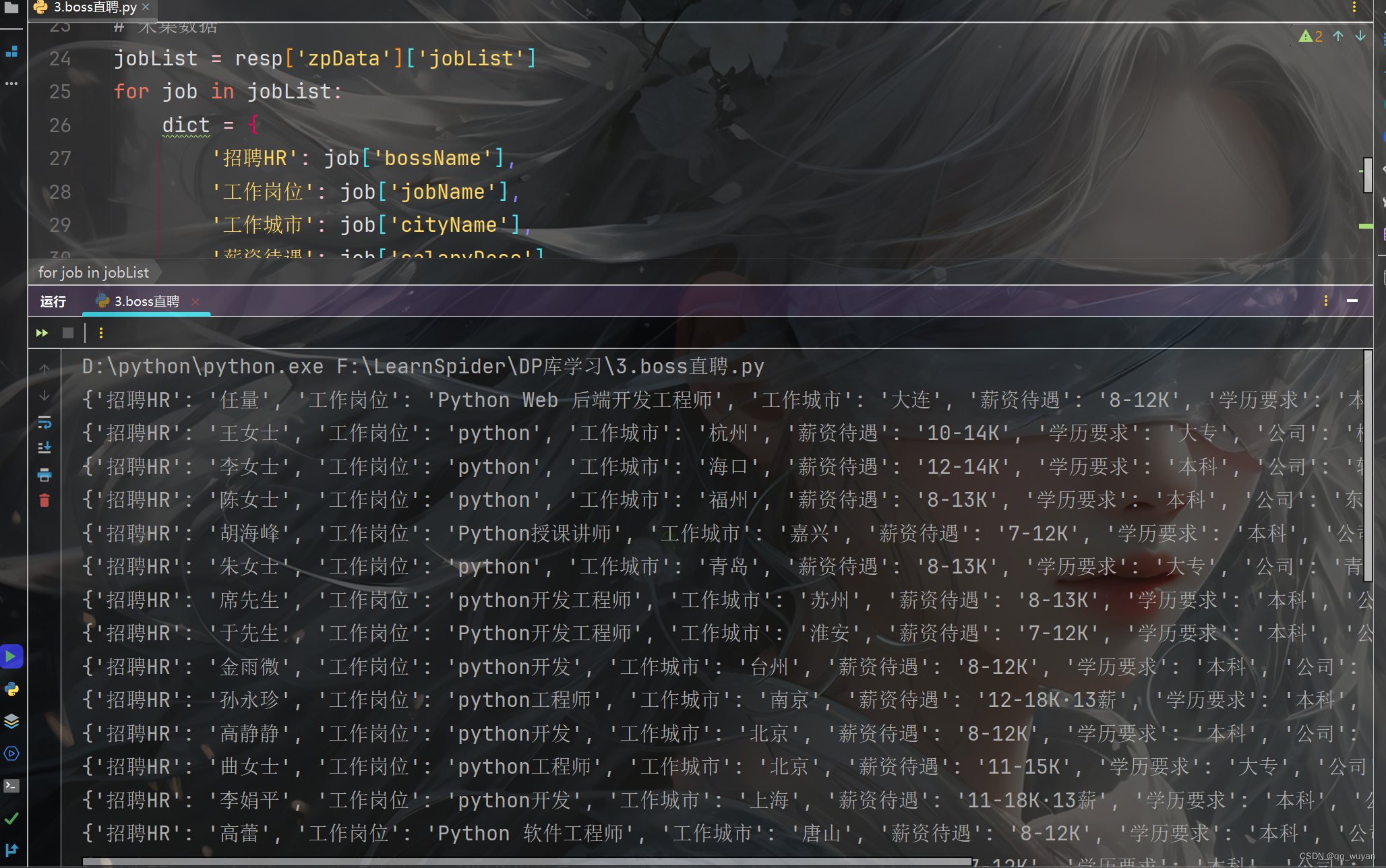
再补充一个简单的翻页操作,喜欢的朋友可以学起来,适用面很广哦!
from DrissionPage import ChromiumPage
import csv
f = open('boss直聘.csv', 'w', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'招聘HR',
'工作岗位',
'工作城市',
'薪资待遇',
'学历要求',
'公司',
'公司规模',
])
csv_writer.writeheader()
num = input('请输入你要采集的页码:')
cp = ChromiumPage()
cp.get('https://www.zhipin.com/web/geek/job?query=python&city=100010000')
for page in range(1, int(num)):
print(f'正在采集第{page}页数据'.center(50, '-'))
# 监听数据
cp.listen.start('scene=1&query=python&city=100010000&experience=&payType=&partTime=&')
# 等待监听响应
response = cp.listen.wait().response
resp = response.body
# print(resp)
# 采集数据
jobList = resp['zpData']['jobList']
for job in jobList:
dict = {
'招聘HR': job['bossName'],
'工作岗位': job['jobName'],
'工作城市': job['cityName'],
'薪资待遇': job['salaryDesc'],
'学历要求': job['jobDegree'],
'公司': job['brandName'],
'公司规模': job['brandScaleName'],
}
print(dict)
csv_writer.writerow(dict)
cp.ele('css:.ui-icon-arrow-right').click()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









