







前言:
还是有一些朋友联系想整个评论获取,据我所知这方面的单子确实有,但也不值几个元子啊???不过作为宠粉博主,为了构建和谐社会,我还是决定给大伙玩一下,玩一下这个案例!!!(电脑端观看更佳)

动手动手!!!
基本思路:
①接口抓包分析(大佬可以略过)
②拿响应数据(工具构建请求)
③内容解析(想学的可以仔细了解)
④持久化存储 (弄完能站着把元子挣了)
评论留言处理:
1)数据来源分析/接口抓包
- 定位接口抓包 F12 / Fiddler / Postman皆可
随机找个视频 ,进入开发者工具监听数据,深圳天气有点热,我找个凉快点的视频
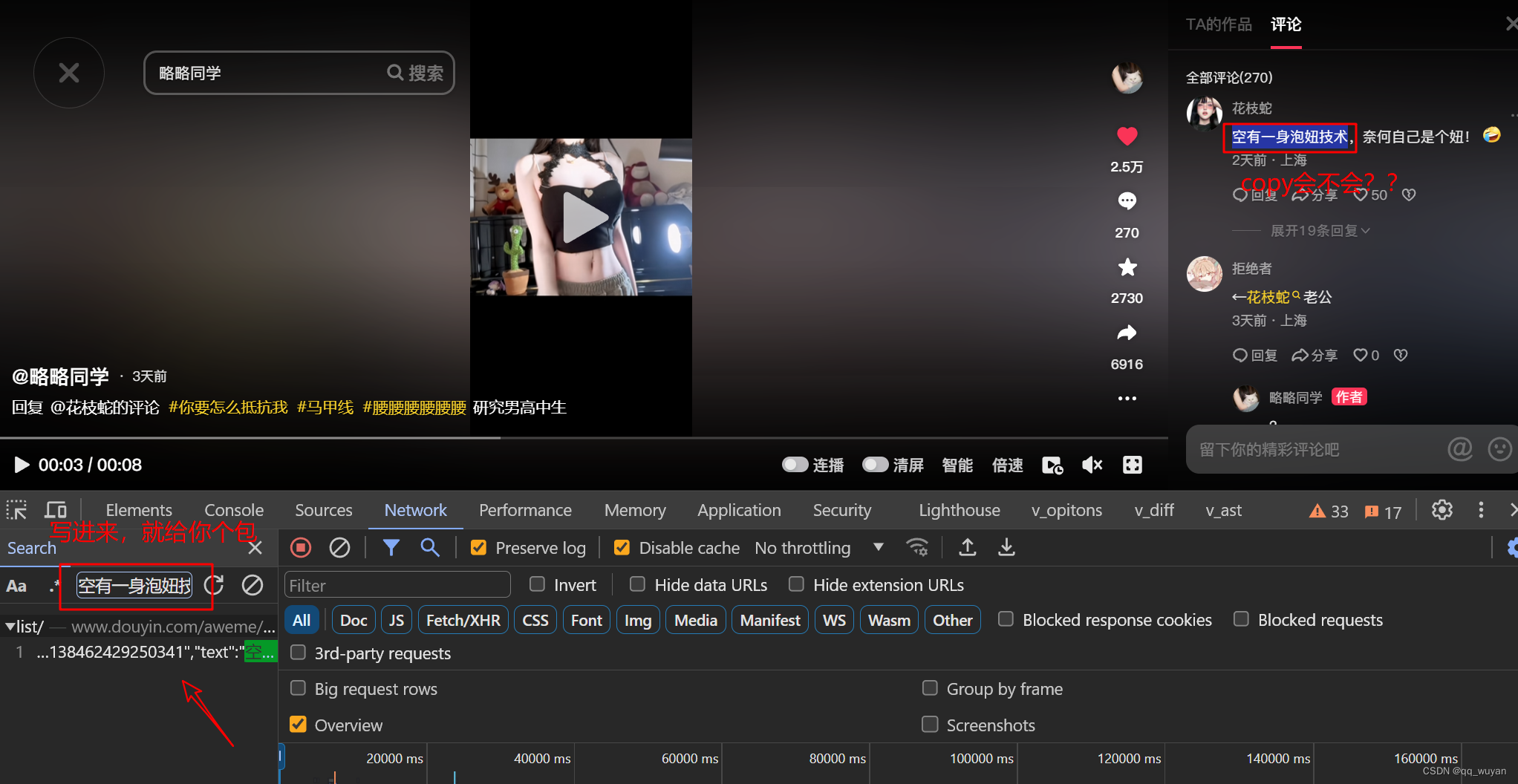
- 拿到你三舅的留言然后进行搜索,看有没有东西出来,没有就多刷新几次,总得给你个包
- 好基本就是这玩意 检查下是个什么猫腻 什么请求 有没有加密 要不要处理逆向
我先申明一下,看归看不能影响学习
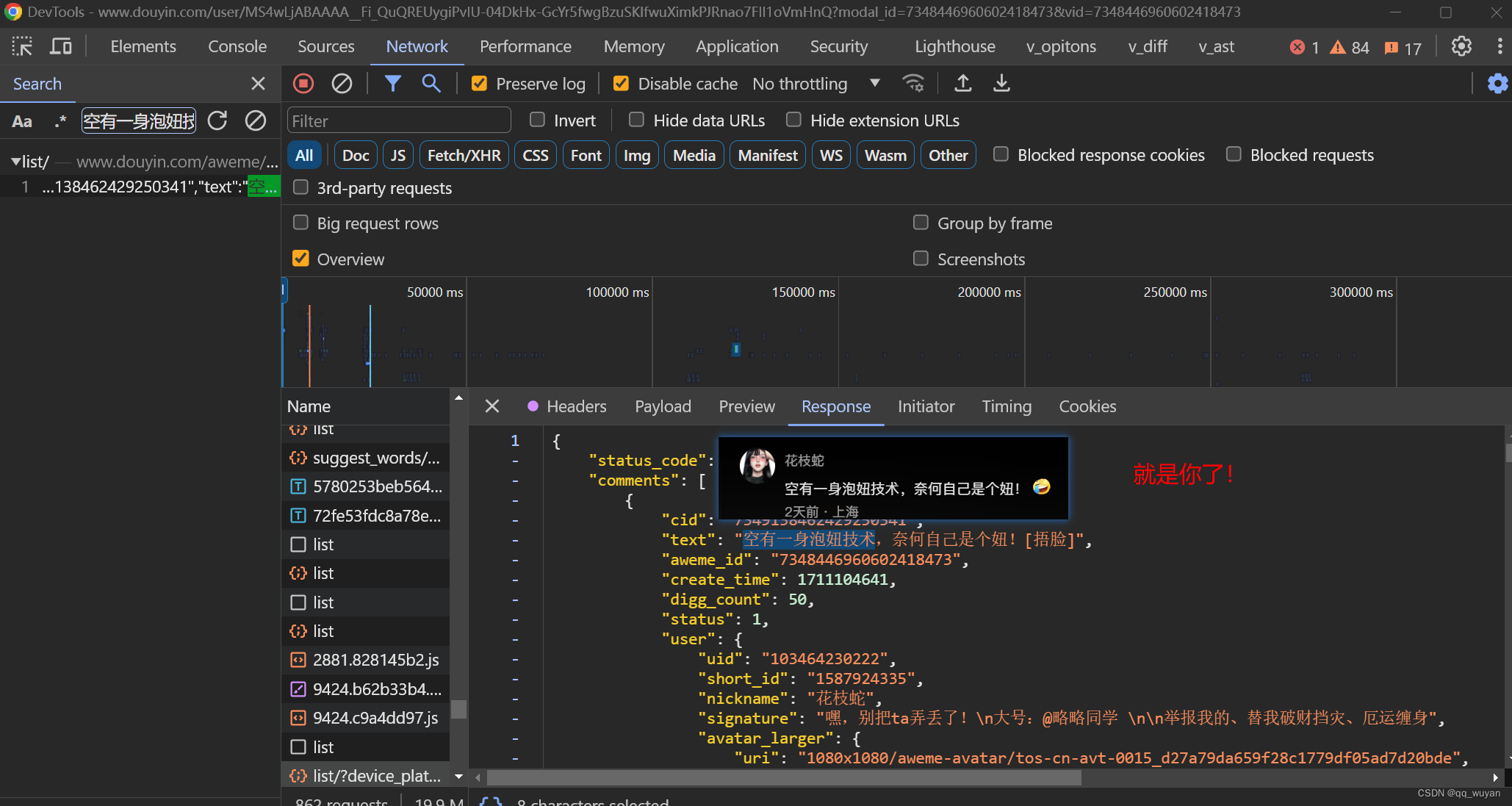
2)发送请求/获取数据
明确之后就开始抓包分析请求了,就是一个Get没啥好说的,payload里面会有x-bogus和mstoken,x-b可加可不加,想拿程序换杯奶茶喝的话最好是加上,mstoekn目前会把他当作一个常量,影响不大。所以一个点,先构建基本请求代码,x-b随你自己。
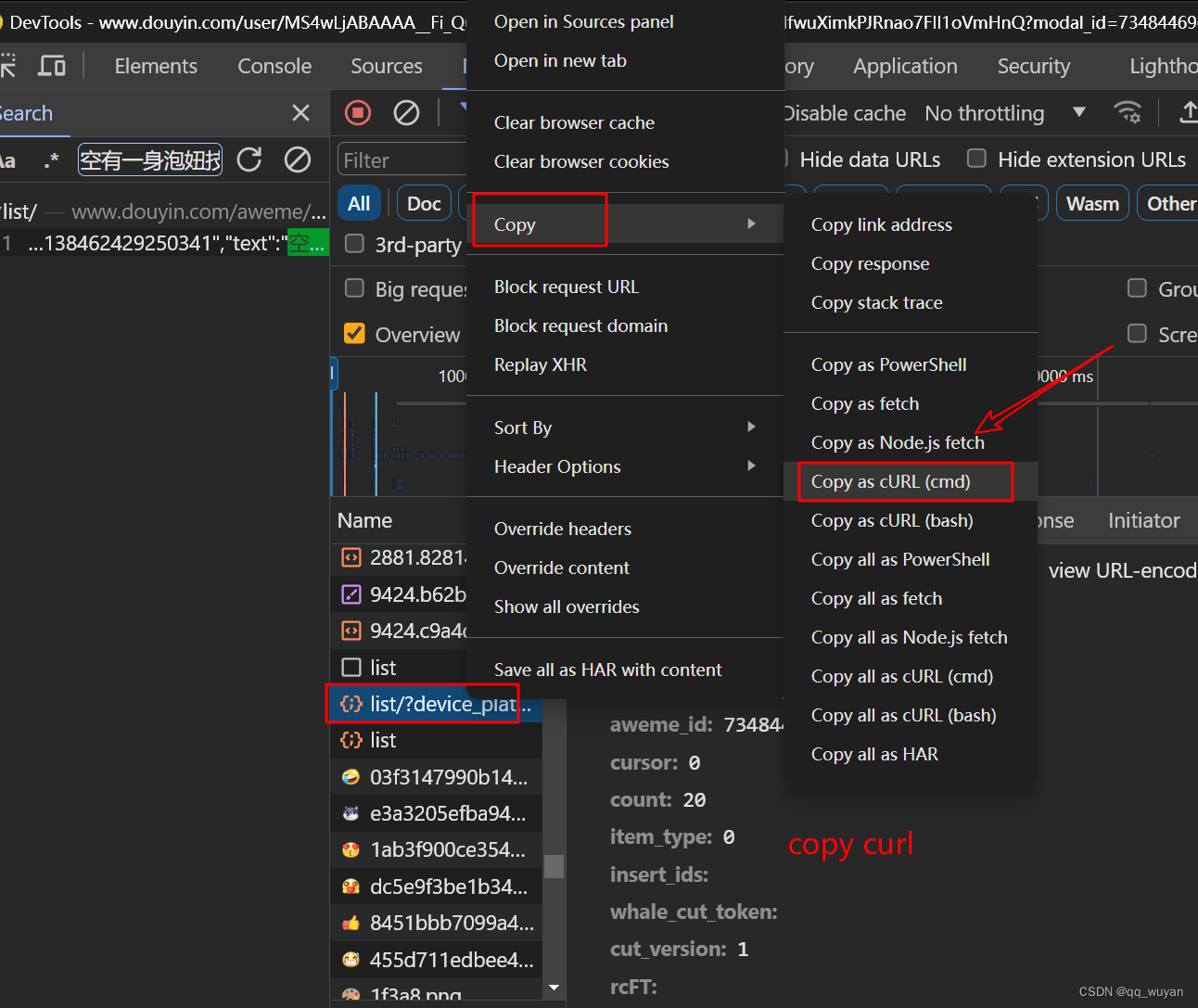
- 定位到接口复制curl(bash) (
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2391
2391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









