






MySQL高可用方案
单点方案
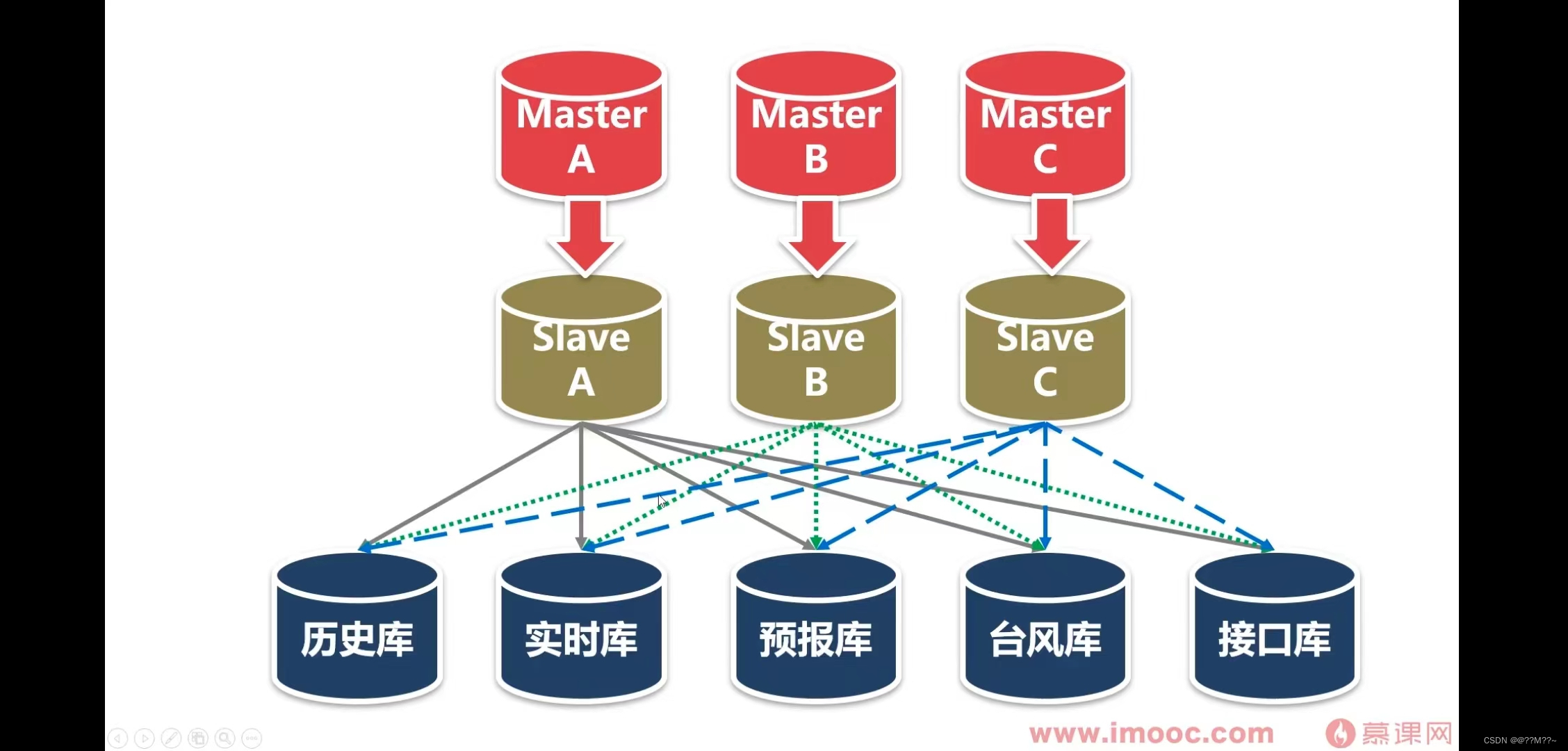
数据同步(复制)子系统
Federated引擎
开发基于Federated引擎的刷新同步模块
就是要将不同的Master中的数据,复制下来,但是要注意,从Master复制过来的字段名有可能和我的数据库需要的字段名是不一样的,所以也是一个参数。
参数意义
struct st_arg
{
char localconnstr[101]; // 本地数据库的连接参数。
char charset[51]; // 数据库的字符集。
char fedtname[31]; // Federated表名。
char localtname[31]; // 本地表名。
char remotecols[1001]; // 远程表的字段列表。
char localcols[1001]; // 本地表的字段列表。
char where[1001]; // 同步数据的条件。
int synctype; // 同步方式:1-不分批同步;2-分批同步。
char remoteconnstr[101]; // 远程数据库的连接参数。
char remotetname[31]; // 远程表名。
char remotekeycol[31]; // 远程表的键值字段名。
char localkeycol[31]; // 本地表的键值字段名。
int maxcount; // 每批执行一次同步操作的记录数。
int timeout; // 本程序运行时的超时时间。
char pname[51]; // 本程序运行时的程序名。
} starg;
void _help(char *argv[])
{
printf("Using:/project/tools1/bin/syncupdate logfilename xmlbuffer\n\n");
printf("Sample:/project/tools1/bin/procctl 10 /project/tools1/bin/syncupdate /log/idc/syncupdate_ZHOBTCODE2.log \"<localconnstr>192.168.174.129,root,mysqlpwd,mysql,3306</localconnstr><charset>utf8</charset><fedtname>LK_ZHOBTCODE1</fedtname><localtname>T_ZHOBTCODE2</localtname><remotecols>obtid,cityname,provname,lat,lon,height/10,upttime,keyid</remotecols><localcols>stid,cityname,provname,lat,lon,altitude,upttime,keyid</localcols><synctype>1</synctype><timeout>50</timeout><pname>syncupdate_ZHOBTCODE2</pname>\"\n\n");
// 因为测试的需要,xmltodb程序每次会删除LK_ZHOBTCODE1中的数据,全部的记录重新入库,keyid会变。
// 所以以下脚本不能用keyid,要用obtid,用keyid会出问题,可以试试。
printf(" /project/tools1/bin/procctl 10 /project/tools1/bin/syncupdate /log/idc/syncupdate_ZHOBTCODE3.log \"<localconnstr>192.168.174.129,root,mysqlpwd,mysql,3306</localconnstr><charset>utf8</charset><fedtname>LK_ZHOBTCODE1</fedtname><localtname>T_ZHOBTCODE3</localtname><remotecols>obtid,cityname,provname,lat,lon,height/10,upttime,keyid</remotecols><localcols>stid,cityname,provname,lat,lon,altitude,upttime,keyid</localcols><where>where obtid like '54%%%%'</where><synctype>2</synctype><remoteconnstr>192.168.174.132,root,mysqlpwd,mysql,3306</remoteconnstr><remotetname>T_ZHOBTCODE1</remotetname><remotekeycol>obtid</remotekeycol><localkeycol>stid</localkeycol><maxcount>10</maxcount><timeout>50</timeout><pname>syncupdate_ZHOBTCODE3</pname>\"\n\n");
printf(" /project/tools1/bin/procctl 10 /project/tools1/bin/syncupdate /log/idc/syncupdate_ZHOBTMIND2.log \"<localconnstr>192.168.174.129,root,mysqlpwd,mysql,3306</localconnstr><charset>utf8</charset><fedtname>LK_ZHOBTMIND1</fedtname><localtname>T_ZHOBTMIND2</localtname><remotecols>obtid,ddatetime,t,p,u,wd,wf,r,vis,upttime,keyid</remotecols><localcols>stid,ddatetime,t,p,u,wd,wf,r,vis,upttime,recid</localcols><where>where ddatetime>timestampadd(minute,-120,now())</where><synctype>2</synctype><remoteconnstr>192.168.174.132,root,mysqlpwd,mysql,3306</remoteconnstr><remotetname>T_ZHOBTMIND1</remotetname><remotekeycol>keyid</remotekeycol><localkeycol>recid</localkeycol><maxcount>300</maxcount><timeout>50</timeout><pname>syncupdate_ZHOBTMIND2</pname>\"\n\n");
printf("本程序是数据中心的公共功能模块,采用刷新的方法同步MySQL数据库之间的表。\n\n");
printf("logfilename 本程序运行的日志文件。\n");
printf("xmlbuffer 本程序运行的参数,用xml表示,具体如下:\n\n");
printf("localconnstr 本地数据库的连接参数,格式:ip,username,password,dbname,port。\n");
printf("charset 数据库的字符集,这个参数要与远程数据库保持一致,否则会出现中文乱码的情况。\n");
printf("fedtname Federated表名。\n");
printf("localtname 本地表名。\n");
printf("remotecols 远程表的字段列表,用于填充在select和from之间,所以,remotecols可以是真实的字段,\n"
" 也可以是函数的返回值或者运算结果。如果本参数为空,就用localtname表的字段列表填充。\n");
printf("localcols 本地表的字段列表,与remotecols不同,它必须是真实存在的字段。如果本参数为空,\n"
" 就用localtname表的字段列表填充。\n");
printf("where 同步数据的条件,为空则表示同步全部的记录,填充在delete本地表和select Federated表\n"
" 之后,注意:1)where中的字段必须同时在本地表和Federated表中;2)不要用系统时间作\n"
" 为条件,当synctype==2时无此问题。\n");
printf("synctype 同步方式:1-不分批同步;2-分批同步。\n");
printf("remoteconnstr 远程数据库的连接参数,格式与localconnstr相同,当synctype==2时有效。\n");
printf("remotetname 远程表名,当synctype==2时有效。\n");
printf("remotekeycol 远程表的键值字段名,必须是唯一的,当synctype==2时有效。\n");
printf("localkeycol 本地表的键值字段名,必须是唯一的,当synctype==2时有效。\n");
printf("maxcount 每批执行一次同步操作的记录数,不能超过MAXPARAMS宏(在_mysql.h中定义),当synctype==2时有效。\n");
printf("timeout 本程序的超时时间,单位:秒,视数据量的大小而定,建议设置30以上。\n");
printf("pname 本程序运行时的进程名,尽可能采用易懂的、与其它进程不同的名称,方便故障排查。\n\n");
printf("注意:\n1)remotekeycol和localkeycol字段的选取很重要,如果用了MySQL的自增字段,那么在远程表中数据生成后自增字段的值不可改变,否则同步会失败;\n2)当远程表中存在delete操作时,无法分批同步,因为远程表的记录被delete后就找不到了,无法从本地表中执行delete操作。\n\n\n");
}
全量同步:
先删除表原先的数据
在通过远程表,将远程表的值按照字段名放进去
注意,此时远程表的值和我需要的字段名可能出现不同和函数关系,可以在这里进行处理,但是没有太大的必要。无非就是,把远程表的值拿出来,进行处理之后,然后在存放给表的字段名之下。
obtid,cityname,provname,lat,lon,height/10,upttime,keyid
stid,cityname,provname,lat,lon,altitude,upttime,keyid
"insert into %s(%s) select %s from %s %s", starg.localtname, starg.localcols, starg.remotecols, starg.fedtname, starg.where
1.先删除全表
删除本地库中,需要被删除的东西,使用where进行说明
stmtdel.prepare("delete from %s %s", starg.localtname, starg.where);
2.将远程表中满足要求的插入进去
stmtins.prepare("insert into %s(%s) select %s from %s %s", starg.localtname, starg.localcols, starg.remotecols, starg.fedtname, starg.where);
分批同步:
通过where条件找到符合条件的键值
然后在要存储的表中,通过“可能不一样的关键字”匹配,然后删除,插入。
逻辑:
每一条结果,存放进去
待会进行入库。
循环读取结果集中的数据,并进行插入。
这里是一次性把一定数量的结果集先取出来存放,然后等待条件一次性插入进去。
否则就是不断地从结果集中拿出数据存放到数组中。
while (true)
{
// 获取需要同步数据的结果集。
if (stmtsel.next() != 0)
break;
strcpy(keyvalues[ccount], remkeyvalue);
ccount++;
// 每starg.maxcount条记录执行一次同步。
if (ccount == starg.maxcount)
{
// 从本地表中删除记录。
if (stmtdel.execute() != 0)
{
// 执行从本地表中删除记录的操作一般不会出错。
// 如果报错,就肯定是数据库的问题或同步的参数配置不正确,流程不必继续。
logfile.Write("stmtdel.execute() failed.\n%s\n%s\n", stmtdel.m_sql, stmtdel.m_cda.message);
return false;
}
// 向本地表中插入记录。
if (stmtins.execute() != 0)
{
// 执行向本地表中插入记录的操作一般不会出错。
// 如果报错,就肯定是数据库的问题或同步的参数配置不正确,流程不必继续。
logfile.Write("stmtins.execute() failed.\n%s\n%s\n", stmtins.m_sql, stmtins.m_cda.message);
return false;
}
logfile.Write("sync %s to %s(%d rows) in %.2fsec.\n", starg.fedtname, starg.localtname, ccount, Timer.Elapsed());
connloc.commit();
ccount = 0; // 记录从结果集中已获取记录的计数器。
memset(keyvalues, 0, sizeof(keyvalues));
PActive.UptATime();
}
}
这行语句就是绑定到插入SQL语句的空间精心该数据存储的语句
stmtins.prepare("insert into %s(%s) select %s from %s where %s in (%s)", starg.localtname, starg.localcols, starg.remotecols, starg.fedtname, starg.remotekeycol, bindstr);
for (int ii = 0; ii < starg.maxcount; ii++)
{
stmtins.bindin(ii + 1, keyvalues[ii], 50);
}
strcpy(keyvalues[ccount], remkeyvalue);
okok,我们来梳理下。
首先,进行SQL操作,一定是要拼接出操作语句的,其次,操作语句的主体是不变的,变的是一些参数。
解决方案:将那些变化的参数,使用内存进行绑定,然而语句的主体不变,从而实现,一条语句的多个数据的操作。
比如说这个,说明从结果集中取出来的数据是不超过50个字符的一条数据。
数字已经不用了,现在都是用字符来描述,因为会有NULL的存在,所以干脆大家都使用字符来进行传输。
char remkeyvalue[51]; // 从远程表查到的需要同步记录的key字段的值。
sqlstatement stmtsel(&connrem);
stmtsel.prepare("select %s from %s %s", starg.remotekeycol, starg.remotetname, starg.where);
stmtsel.bindout(1, remkeyvalue, 50);
char bindstr[2001]; // 绑定同步SQL语句参数的字符串。
char strtemp[11];
memset(bindstr, 0, sizeof(bindstr));
for (int ii = 0; ii < starg.maxcount; ii++)
{
memset(strtemp, 0, sizeof(strtemp));
sprintf(strtemp, ":%lu,", ii + 1);
strcat(bindstr, strtemp);
}
// 从远程表查找的需要同步记录的key字段的值。
char remkeyvalue[51]; // 从远程表查到的需要同步记录的key字段的值。
sqlstatement stmtsel(&connrem);
stmtsel.prepare("select %s from %s %s", starg.remotekeycol, starg.remotetname, starg.where);
stmtsel.bindout(1, remkeyvalue, 50);
// 拼接绑定同步SQL语句参数的字符串(:1,:2,:3,...,:starg.maxcount)。
char bindstr[2001]; // 绑定同步SQL语句参数的字符串。
char strtemp[11];
memset(bindstr, 0, sizeof(bindstr));
for (int ii = 0; ii < starg.maxcount; ii++)
{
memset(strtemp, 0, sizeof(strtemp));
sprintf(strtemp, ":%lu,", ii + 1);
strcat(bindstr, strtemp);
}
bindstr[strlen(bindstr) - 1] = 0; // 最后一个逗号是多余的。
char keyvalues[starg.maxcount][51]; // 存放key字段的值。
// 准备删除本地表数据的SQL语句,一次删除starg.maxcount条记录。
// delete from T_ZHOBTCODE3 where stid in (:1,:2,:3,...,:starg.maxcount);
stmtdel.prepare("delete from %s where %s in (%s)", starg.localtname, starg.localkeycol, bindstr);
for (int ii = 0; ii < starg.maxcount; ii++)
{
stmtdel.bindin(ii + 1, keyvalues[ii], 50);
}
// 准备插入本地表数据的SQL语句,一次插入starg.maxcount条记录。
// insert into T_ZHOBTCODE3(stid ,cityname,provname,lat,lon,altitude,upttime,keyid)
// select obtid,cityname,provname,lat,lon,height/10,upttime,keyid from LK_ZHOBTCODE1
// where obtid in (:1,:2,:3);
stmtins.prepare("insert into %s(%s) select %s from %s where %s in (%s)", starg.localtname, starg.localcols, starg.remotecols, starg.fedtname, starg.remotekeycol, bindstr);
for (int ii = 0; ii < starg.maxcount; ii++)
{
stmtins.bindin(ii + 1, keyvalues[ii], 50);
}
int ccount = 0; // 记录从结果集中已获取记录的计数器。
memset(keyvalues, 0, sizeof(keyvalues));
if (stmtsel.execute() != 0)
{
logfile.Write("stmtsel.execute() failed.\n%s\n%s\n", stmtsel.m_sql, stmtsel.m_cda.message);
return false;
}
while (true)
{
// 获取需要同步数据的结果集。
if (stmtsel.next() != 0)
break;
strcpy(keyvalues[ccount], remkeyvalue);
ccount++;
// 每starg.maxcount条记录执行一次同步。
if (ccount == starg.maxcount)
{
// 从本地表中删除记录。
if (stmtdel.execute() != 0)
{
// 执行从本地表中删除记录的操作一般不会出错。
// 如果报错,就肯定是数据库的问题或同步的参数配置不正确,流程不必继续。
logfile.Write("stmtdel.execute() failed.\n%s\n%s\n", stmtdel.m_sql, stmtdel.m_cda.message);
return false;
}
// 向本地表中插入记录。
if (stmtins.execute() != 0)
{
// 执行向本地表中插入记录的操作一般不会出错。
// 如果报错,就肯定是数据库的问题或同步的参数配置不正确,流程不必继续。
logfile.Write("stmtins.execute() failed.\n%s\n%s\n", stmtins.m_sql, stmtins.m_cda.message);
return false;
}
logfile.Write("sync %s to %s(%d rows) in %.2fsec.\n", starg.fedtname, starg.localtname, ccount, Timer.Elapsed());
connloc.commit();
ccount = 0; // 记录从结果集中已获取记录的计数器。
memset(keyvalues, 0, sizeof(keyvalues));
PActive.UptATime();
}
}
开发基于Federated引擎的增量同步模块
每次只同步远程表中新增的字段
要求:远程表只有插入,没有修改和删除操作
远程表有自增字段。
注意
本地表的自增字段和远程表的自增字段也有不同,一定要根据具体的自增字段进行选择的范围。
逻辑就是,每次从远程表中查找每次都新增的数据,通过什么来查找呢,通过自增字段进行查找。
struct st_arg
{
char localconnstr[101]; // 本地数据库的连接参数。
char charset[51]; // 数据库的字符集。
char fedtname[31]; // Federated表名。
char localtname[31]; // 本地表名。
char remotecols[1001]; // 远程表的字段列表。
char localcols[1001]; // 本地表的字段列表。
char where[1001]; // 同步数据的条件。
char remoteconnstr[101]; // 远程数据库的连接参数。
char remotetname[31]; // 远程表名。
char remotekeycol[31]; // 远程表的自增字段名。
char localkeycol[31]; // 本地表的自增字段名。
int maxcount; // 每批执行一次同步操作的记录数。
int timetvl; // 同步时间间隔,单位:秒,取值1-30。
int timeout; // 本程序运行时的超时时间。
char pname[51]; // 本程序运行时的程序名。
} starg;
void _help(char *argv[])
{
printf("Using:/project/tools1/bin/syncincrement logfilename xmlbuffer\n\n");
printf("Sample:/project/tools1/bin/procctl 10 /project/tools1/bin/syncincrement /log/idc/syncincrement_ZHOBTMIND2.log \"<localconnstr>192.168.174.129,root,mysqlpwd,mysql,3306</localconnstr><remoteconnstr>192.168.174.132,root,mysqlpwd,mysql,3306</remoteconnstr><charset>utf8</charset><remotetname>T_ZHOBTMIND1</remotetname><fedtname>LK_ZHOBTMIND1</fedtname><localtname>T_ZHOBTMIND2</localtname><remotecols>obtid,ddatetime,t,p,u,wd,wf,r,vis,upttime,keyid</remotecols><localcols>stid,ddatetime,t,p,u,wd,wf,r,vis,upttime,recid</localcols><remotekeycol>keyid</remotekeycol><localkeycol>recid</localkeycol><maxcount>300</maxcount><timetvl>2</timetvl><timeout>50</timeout><pname>syncincrement_ZHOBTMIND2</pname>\"\n\n");
printf(" /project/tools1/bin/procctl 10 /project/tools1/bin/syncincrement /log/idc/syncincrement_ZHOBTMIND3.log \"<localconnstr>192.168.174.129,root,mysqlpwd,mysql,3306</localconnstr><remoteconnstr>192.168.174.132,root,mysqlpwd,mysql,3306</remoteconnstr><charset>utf8</charset><remotetname>T_ZHOBTMIND1</remotetname><fedtname>LK_ZHOBTMIND1</fedtname><localtname>T_ZHOBTMIND3</localtname><remotecols>obtid,ddatetime,t,p,u,wd,wf,r,vis,upttime,keyid</remotecols><localcols>stid,ddatetime,t,p,u,wd,wf,r,vis,upttime,recid</localcols><where>and obtid like '54%%%%'</where><remotekeycol>keyid</remotekeycol><localkeycol>recid</localkeycol><maxcount>300</maxcount><timetvl>2</timetvl><timeout>50</timeout><pname>syncincrement_ZHOBTMIND3</pname>\"\n\n");
printf("本程序是数据中心的公共功能模块,采用增量的方法同步MySQL数据库之间的表。\n\n");
printf("logfilename 本程序运行的日志文件。\n");
printf("xmlbuffer 本程序运行的参数,用xml表示,具体如下:\n\n");
printf("localconnstr 本地数据库的连接参数,格式:ip,username,password,dbname,port。\n");
printf("charset 数据库的字符集,这个参数要与远程数据库保持一致,否则会出现中文乱码的情况。\n");
printf("fedtname Federated表名。\n");
printf("localtname 本地表名。\n");
printf("remotecols 远程表的字段列表,用于填充在select和from之间,所以,remotecols可以是真实的字段,\n"\
" 也可以是函数的返回值或者运算结果。如果本参数为空,就用localtname表的字段列表填充。\n");
printf("localcols 本地表的字段列表,与remotecols不同,它必须是真实存在的字段。如果本参数为空,\n"\
" 就用localtname表的字段列表填充。\n");
printf("where 同步数据的条件,填充在select remotekeycol from remotetname where remotekeycol>:1之后,\n"\
" 注意,不要加where关键字,但是,需要加and关键字。\n");
printf("remoteconnstr 远程数据库的连接参数,格式与localconnstr相同。\n");
printf("remotetname 远程表名。\n");
printf("remotekeycol 远程表的自增字段名。\n");
printf("localkeycol 本地表的自增字段名。\n");
printf("maxcount 每批执行一次同步操作的记录数,不能超过MAXPARAMS宏(在_mysql.h中定义),当synctype==2时有效。\n");
printf("timetvl 执行同步的时间间隔,单位:秒,取值1-30。\n");
printf("timeout 本程序的超时时间,单位:秒,视数据量的大小而定,建议设置30以上。\n");
printf("pname 本程序运行时的进程名,尽可能采用易懂的、与其它进程不同的名称,方便故障排查。\n\n\n");
}















 1446
1446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









