






文章目录
1. init函数
go语言中init函数用于包(package)的初始化。其有以下几个特征:
- init函数是用于程序执行前做包的初始化的函数,比如初始化包中的变量等
- 每个包中可以拥有多个init函数
- 包的每个源文件也可以拥有多个init函数
- 同一个包中的多个init函数的执行顺序go语言没有明确的定义
- 不同包中的init函数按照包导入的依赖关系决定该初始化函数的执行顺序
- init函数不能被其他函数调用,而是在main函数执行之前,自动被调用
2. main函数
Go语言默认入口函数(主函数):func main()
3. init函数和main函数两者的异同
相同点:
两个函数在定义时不能有任何的函数和返回值,且go程序自动调用
不同点:
init可以应用于任意包中,且可以重复定义多个。
main函数只能用于main包中,且只能定义一个。
两个函数的执行顺序:
对同一个go文件的init()调用顺序是从上到下的。
对同一个package中不同文件是按文件名字符串比较“从小到大”顺序调用各文件中的init()函数。
对于不同的package,如果不相互依赖的话,按照main包中”先import的后调用”的顺序调用其包中的init(),如果package存在依赖,则先调用最早被依赖的package中的init(),最后调用main函数。

运行结果:

4. 命令
-
go env用于打印Go语言的环境信息。
-
go run命令可以编译并运行命令源码文件。
-
go get可以根据要求和实际情况从互联网上下载或更新指定的代码包及其依赖包,并对它们进行编译和安装。
-
go build命令用于编译我们指定的源码文件或代码包以及它们的依赖包。
-
go install用于编译并安装指定的代码包及它们的依赖包。
-
go clean命令会删除掉执行其它命令时产生的一些文件和目录。
-
go doc命令可以打印附于Go语言程序实体上的文档。我们可以通过把程序实体的标识符作为该命令的参数来达到查看其文档的目的。
-
go test命令用于对Go语言编写的程序进行测试。
-
go list命令的作用是列出指定的代码包的信息。
-
go fix会把指定代码包的所有Go语言源码文件中的旧版本代码修正为新版本的代码。
-
go vet是一个用于检查Go语言源码中静态错误的简单工具。
-
go tool pprof命令来交互式的访问概要文件的内容。
5.下划线
a. 下划线在import中的作用
import 下划线的作用:当导入一个包时,该包下的文件里所有init()函数都会被执行,然而,有些时候我们并不需要把整个包都导入进来,仅仅是是希望它执行init()函数而已。这个时候就可以使用 import _ 引用该包。即使用【import _ 包路径】只是引用该包,仅仅是为了调用init()函数,所以无法通过包名来调用包中的其他函数。
src
|
+--- main.go
|
+--- hello
|
+--- hello.go
package main
import _ "./hello"
func main() {
// hello.Print()
//编译报错:./main.go:6:5: undefined: hello
}
package hello
import "fmt"
func init() {
fmt.Println("imp-init() come here.")
}
func Print() {
fmt.Println("Hello!")
}
输出结果:
imp-init() come here.
b.下划线在代码中的应用
下划线意思是忽略这个变量.
比如os.Open,返回值为*os.File,error
普通写法是f,err := os.Open("xxxxxxx")
如果此时不需要知道返回的错误值
就可以用f, _ := os.Open("xxxxxx")
如此则忽略了error变量
6.基本数据类型

a. 多行字符串
Go语言中要定义一个多行字符串时,就必须使用反引号字符
s1 := `第一行
第二行
第三行
`
fmt.Println(s1)
b. 字符串的常用操作

strings.Split()的用法:

输出结果:
[goy yanni bi]
true
true
false
3
hahawuwuhehe
byte 和rune类型
Go 语言的字符有以下两种:
uint8类型,或者叫 byte 型,代表了ASCII码的一个字符。
rune类型,代表一个 UTF-8字符。
修改字符串
要修改字符串,需要先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
func changeString() {
s1 := "hello"
// 强制类型转换
byteS1 := []byte(s1)
byteS1[0] = 'H'
fmt.Println(string(byteS1))
s2 := "博客"
runeS2 := []rune(s2)
runeS2[0] = '狗'
fmt.Println(string(runeS2))
}
类型转换
Go语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用。
强制类型转换的基本语法如下:
T(表达式)
7.数组
1. 数组:是同一种数据类型的固定长度的序列。
2. 数组定义:var a [len]int,比如:var a [5]int,数组长度必须是常量,且是类型的组成部分。一旦定义,长度不能变。
3. 长度是数组类型的一部分,因此,var a[5] int和var a[10]int是不同的类型。
4. 数组可以通过下标进行访问,下标是从0开始,最后一个元素下标是:len-1
for i := 0; i < len(a); i++ {
}
for index, v := range a {
}
5. 访问越界,如果下标在数组合法范围之外,则触发访问越界,会panic
6. 数组是值类型,赋值和传参会复制整个数组,而不是指针。因此改变副本的值,不会改变本身的值。
7.支持 "=="、"!=" 操作符,因为内存总是被初始化过的。
8.指针数组 [n]*T,数组指针 *[n]T。
package main
import "fmt"
func main() {
arr2 := [...]int{2,4,6,8,10}
arr1 := [...]int{1,2,3,4,7}
printArr(&arr1)
fmt.Println(arr1)
printArr1(arr2)
fmt.Println(arr2)
}
func printArr(arr *[5]int) {
arr[0] = 10
for i, v := range arr {
fmt.Println(i, v)
}
}
func printArr1(arr [5]int) {
arr[0] = 10
for i, v := range arr {
fmt.Println(i, v)
}
}

a.一维数组的初始化方法:
全局:
var arr0 [5]int = [5]int{1, 2, 3}
var arr1 = [5]int{1, 2, 3, 4, 5}
var arr2 = [...]int{1, 2, 3, 4, 5, 6}
var str = [5]string{3: "hello world", 4: "tom"}
局部:
a := [3]int{1, 2} // 未初始化元素值为 0。
b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组长度。
c := [5]int{2: 100, 4: 200} // 使用索引号初始化元素。
d := [...]struct {
name string
age uint8
}{
{"user1", 10}, // 可省略元素类型。
{"user2", 20}, // 别忘了最后一行的逗号。
}
b. 多维数组
全局
var arr0 [5][3]int
var arr1 [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
局部:
a := [2][3]int{{1, 2, 3}, {4, 5, 6}}
b := [...][2]int{{1, 1}, {2, 2}, {3, 3}} // 第 2 纬度不能用 "..."。
8.切片
1. 切片:切片是数组的一个引用,因此切片是引用类型。但自身是结构体,值拷贝传递。
2. 切片的长度可以改变,因此,切片是一个可变的数组。
3. 切片遍历方式和数组一样,可以用len()求长度。表示可用元素数量,读写操作不能超过该限制。
4. cap可以求出slice最大扩张容量,不能超出数组限制。0 <= len(slice) <= len(array),其中array是slice引用的数组。
5. 切片的定义:var 变量名 []类型,比如 var str []string var arr []int。
6. 如果 slice == nil,那么 len、cap 结果都等于 0。
a.创建切片的各种方式
package main
import "fmt"
func main() {
//1.声明切片
var s1 []int
if s1 == nil {
fmt.Println("是空")
} else {
fmt.Println("不是空")
}
// 2.:=
s2 := []int{}
// 3.make()
var s3 []int = make([]int, 0)
fmt.Println(s1, s2, s3)
// 4.初始化赋值
var s4 []int = make([]int, 0, 0)
fmt.Println(s4)
s5 := []int{1, 2, 3}
fmt.Println(s5)
// 5.从数组切片
arr := [5]int{1, 2, 3, 4, 5}
var s6 []int
// 前包后不包
s6 = arr[1:4]
fmt.Println(s6)
}

b. 切片的内存布局

c. 用append内置函数操作切片
用append内置函数操作切片(切片追加),向slice尾部添加数据时,返回的时新的slice对象。
append函数,因为slice底层数据结构是,由数组、len、cap组成,所以,在使用append扩容时,会查看数组后面有没有连续内存快,有就在后面添加,没有就重新生成一个大的素组。

输出结果:
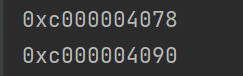
d. slice中cap重新分配规律:
首先判断,如果新申请容量大于 2 倍的旧容量,最终容量就是新申请的容量。否则判断,如果旧切片的长度小于 1024,则最终容量就是旧容量的两倍。
否则判断,如果旧切片长度大于等于 1024,则最终容量从旧容量开始循环增加原来的 1/4 , 直到最终容量大于等于新申请的容量。如果最终容量计算值溢出,则最终容量就是新申请容量。
情况一:原数组还有容量可以扩容(实际容量没有填充完),这种情况下,扩容以后的数组还是指向原来的数组,对一个切片的操作可能影响多个指针指向相同地址的Slice。
情况二:原来数组的容量已经达到了最大值,再想扩容, Go 默认会先开一片内存区域,把原来的值拷贝过来,然后再执行 append() 操作。这种情况丝毫不影响原数组。
e.切片的数据结构
切片的数据结构如下:
type slice struct {
array unsafe.Pointer
len int
cap int
}
f.切片和数组的区别
数组是具有固定长度,且拥有零个或者多个,相同数据类型元素的序列。数组的长度是数组类型的一部分,所以[3]int 和 [4]int 是两种不同的数组类型。数组需要指定大小,不指定也会根据初始化的自动推算出大小,不可改变;数组是值传递。数组是内置类型,是一组同类型数据的集合,它是值类型,通过从0开始的下标索引访问元素值。在初始化后长度是固定的,无法修改其长度。
当作为方法的参数传入时将复制一份数组而不是引用同一指针。数组的长度也是其类型的一部分,通过内置函数len(array)获取其长度。数组定义:
var array [10]int
var array =[5]int{1,2,3,4,5}
切片表示一个拥有相同类型元素的可变长度的序列。切片是一种轻量级的数据结构,它有三个属性:指针、长度和容量。切片不需要指定大小;切片是地址传递;切片可以通过数组来初始化,也可以通过内置函数make()初始化 。初始化时len=cap,在追加元素时如果容量cap不足时将按len的2倍扩容。切片定义:
var slice []type = make([]type, len)















 3103
3103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









