







XuanYuan: An AI-Native Database
这篇文章主要是讨论了AI4DB 和 DB4AI 集成的数据库架构,以此提出了AI原生的数据库,架构如下:
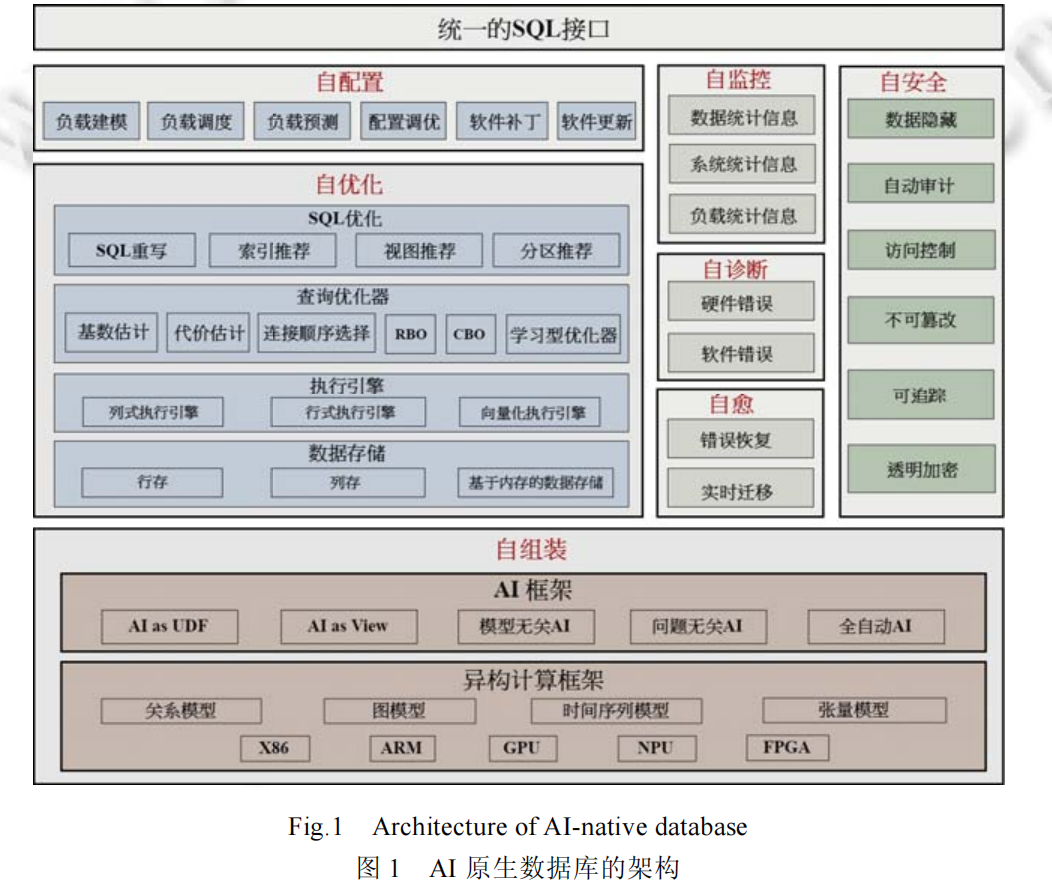
而具体发展阶段来说,AI原生数据库主要由五个阶段组成
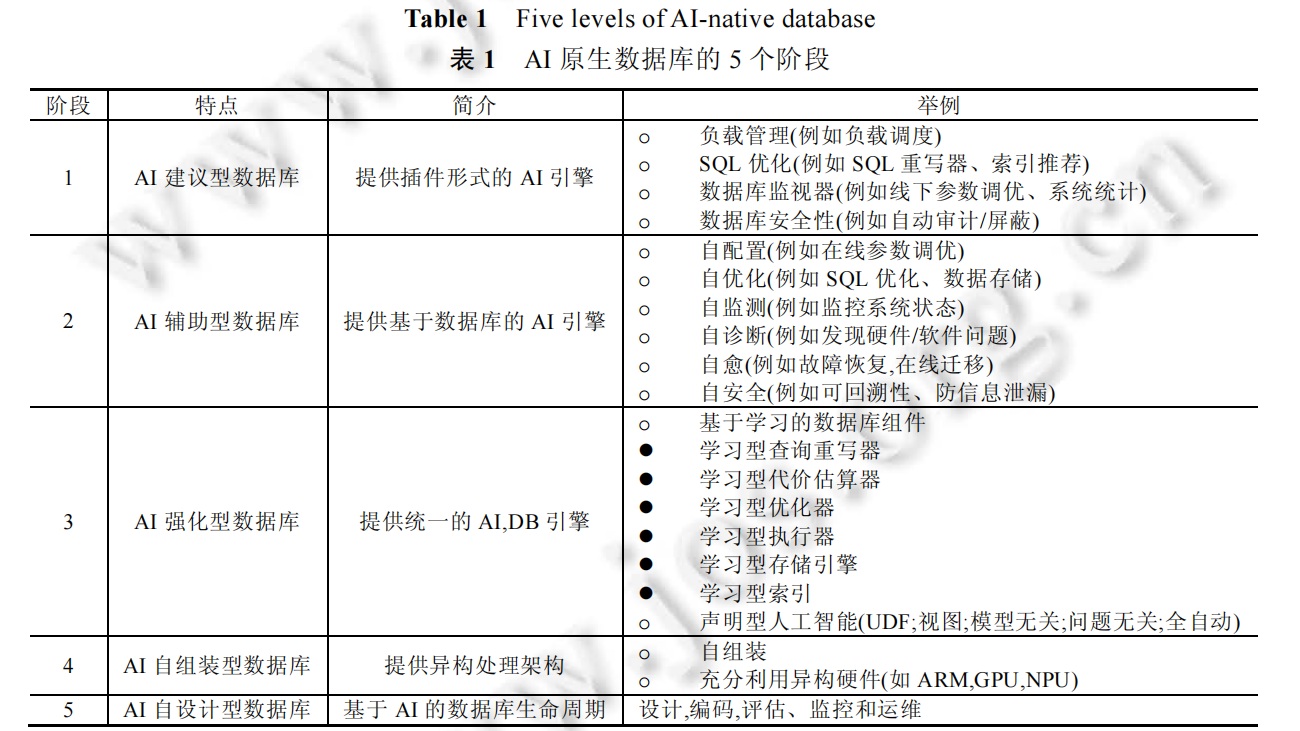
- 第一阶段,AI建议型数据库:像是有一个外挂方式存在的chat/advisor,能够提供离线优化的建议,但是可能还得人工去action
- 第二阶段,AI辅助型数据库:将 AI 引擎集成到数据库内核中,作为数据库的一个环节/组件,比如在查询过程中加入 AI支持的查询调优过程。
- 第三阶段,AI增强型数据库:AI 增强型数据库不仅用人工智能技术优化数据库设计,而且提供基于数据库内置的 AI 原生服务.
- 这里许多数据库组件可以利用人工智能算法进行增强,比如配置优化、查询优化、成本估计、索引等
- 数据库内置的AI服务:1. 扩展SQL来支持AI;2. 利用数据库优化技术来加速 AI 算法,例如索引、增量计算和共享计算,将数据库中支持人工智能功能的技术分为 5 个层次
- AI 模型作为用户定义函数(UDF):在数据库中嵌入 AI 框架(如 MADlib,TensorFlow,Scikit-learn),提供用户定义函数,,用户可以按照 SQL 原有的语法或内嵌其他语言自定义 AI 模型,从数据库调用这些实例来使用 AI 模型
- AI 模型作为视图:将训练出来的模型物化下来(materialized view),之后,其他用户就可以直接使用这个模型.
- 模型无关 AI:通过自动根据问题选择算法,数据库可以自动推荐最适合用户场景的算法
- 问题无关 AI:很多时候用户甚至不能解释清楚需要解决的问题,例如具体的分类标准.在给定数据库的情况下,全自动 AI 能自动发现哪些问题可以由人工智能算法来解决,并推荐合适的人工智能算法;
- 全自动 AI:该系统最终可以自动发现人工智能的应用机会,包括自动发现问题,选择合适的 AI 模型、算法、数据和训练方法等.
- 所以需要设计一个混合型引擎同时支持人工智能和数据库服务
- 第四阶段,AI自组装数据库:不仅自动地组装数据库组件来生成最适合给定场景的数据库,而且还将不同任务调度到合适的硬件上.
- 自组装:执行路径可以看成是自然语言序列(NLS),比如〈pg_parser,optimizer_RBO,row-based executor,accelerator〉,使用强化学习RL,它以整个路径序列为一个 epoch,以一个动作为一个 episode.在每个 eposide,强化学习选择执行查询的下一个组件(action),可以选DDQN、GAN算法
- 异构计算架构:充分利用 x86、ARM、GPU、NPU、加速器等多种计算能力,比如如何从关系模型转化为其他模型(tensor模型),还有就是NVM和RDMA。
- 第五阶段:AI自设计数据库,数据库完全由人工智能设计,包括设计、编码、评估、监控和维护等各个阶段
挑战和机遇:
-
Stonebraker 认为,由于应用程序的多样性(例如 OLTP,OLAP,stream,graph)和硬件的多样性(例如 CPU,ARM,GPU,FPGA,NVM),一种数据库并不能适合所有的情况(one-size-doesn’t-fit-all).
通过构建一个智能的数据库栈可能能够适应所有的情况(one-stack-fits-all).
“One-stack-fits-all”的挑战:
(1) 每个组件应该提供标准接口,以便不同的组件可以集成在一起;
(2) 每个组件应该有不同的变体或实现,例如不同的索引类型、不同的优化器;
(3) 它需要一个基于学习的组件来组装不同的组件;
(4) 在部署数据库之前,需要对所装配的数据库进行评估和验证;
(5) 支持异构的计算框架.不同组件可能需要运行在不同硬件上,例如,学习优化器应该运行在 AI 芯片上,传统的基于成本的优化器应该运行在通用芯片上,它需要有效的硬件调度算法来安排不同的任务;
(6) 传统芯片设计有 EDA 等软件辅助,但是软件设计并没有类似的工具来评价设计效果,因此需要设计类似软件来对数据库的设计给出评估. -
OLAP 2.0
图数据、时间序列数据、空间数据、文本数据、图像数据,需要新的数据分析技术来分析这些多模型数据,集成 AI和 DB技术来提供新的数据分析功能是很挑战性的.我们认为,多模型数据的 DB 和 AI 混合在线分析处理应该是下一代 OLAP,即OLAP 2.0.
挑战:首先,不同的数据类型使用不同的模型,如关系模型、图模型、KV 模型、张量模型,需要一个新的模型来支持多模数据分析;其次,OLAP 2.0 查询可能涉及数据库和人工智能操作,它需要设计新的模型来优化这些跨硬件的异构操作
-
OLTP 2.0
传统OLTP不能充分利用新硬件,如 AI 芯片、RDMA 和NVM.实际上,我们可以利用新的硬件来改进事务处理
- 使用 NVM 替换 RAM,并使用 NVM 上的记录级存储替换页级存储
- 利用RDMA来改进数据库中的数据传输.我们可以利用智能以太网卡的可编程特性,实现对RDMA 的过滤,避免在 RAM 和 CPU 中进行不必要的处理;
- 设计专门为数据库定义的硬件芯片也是很有前景
挑战:
- 充分利用新硬件设计新一代数据库需要集成多种数据模型和调度策略
- 评估和验证新硬件是否能使数据库体系结构受益也是一件很难的事情
-
AI4DB
挑战:
- 针对数据库调优的有效样本数据很难获得
- ,很难针对不同的场景自动选择合适的模型算法,还要平衡速度和质量
- 在调优中,如果模型不收敛,我们就不能利用模型对参数进行建议;
- 适应性:模型应该适应不同的场景.例如,如果硬件环境发生变化,模型可以适应新的硬件;
- 泛化能力:模型应该适应不同的设置.例如,如果工作负载发生了更改,那么模型应该支持新的工作负载.如果更新了数据,模型需要有能力适应新的数据.
-
DB4AI
- 使用索引技术加速人工智能算法,利用数据库技术来提高人工智能算法的性能,可以对样本和特征建立索引,利用索引来进行高效节能的训练
- AI 原生数据库要有能力理解需求、发现模型.普通用户可能只知道他们的需求,例如,使用一个分类算法来解决一个问题,但不知道应该使用哪个 AI 算法.因此,自动发现人工智能算法非常重要
-
边缘计算数据库
- 需要在小型设备中嵌入微型数据库
- 挑战:安全性、实时数据处理能力、数据迁移、实时控制是 5G,IOT 的重要需求
















 6824
6824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











