







Vision Transformer在捕获浅层的局部特征时可能会受到高冗余的影响。
在神经网络的早期阶段获得高效且有效的全局上下文建模:
①从超像素的设计中汲取灵感,减少了后续处理中图像基元的数量,并将超级令牌引入到Vision Transformer中。
超像素(Superpixel)是图像处理中的一种概念,它指的是具有相似颜色、纹理等特征的相邻像素组成的小区域。这些小区域被视为一个整体,从而代替了传统的单个像素作为图像处理的基本单位。
图像基元指的是图像中具有显著特点的基本单元,是一个相对概括和模糊的概念。
常见的图像基元包括边缘、角点、直线段、圆、孔、椭圆以及其他兴趣点等,还包括这些基本单元的一些结合体。
②超级令牌试图提供视觉内容的语义上有意义的镶嵌,从而减少自注意力的令牌数量并保留全局建模。
超像素算法
传统的超像素算法:基于图的方法和基于聚类的方法
基于图的方法将图像像素视为图节点,并通过相邻像素之间的边缘连接来划分节点。
基于聚类的方法利用传统的聚类技术来构造超像素。例如不同特征表示上的 K-均值聚类。
超级令牌注意力(STA)机制
- 通过稀疏关联学习从视觉令牌中采样超级令牌
- 对超级令牌执行自注意力,最后将它们映射回原始令牌空间
基本介绍
Transformer主导着自然语言处理领域,并表现出通过自注意力捕获长程依赖关系的出色能力。
自注意力的计算复杂度与令牌数量成二次方,导致高分辨率视觉任务(例如物体检测和分割)的计算成本巨大。
ViT倾向于捕获具有高冗余的浅层局部特征。如图(b)所示,给定一个锚标记,浅层全局注意力集中在一些相邻的标记上(用红色填充),而忽略了大多数距离较远的标记。所有令牌之间的全局比较导致在捕获此类局部相关性时产生巨大的不必要的计算成本。
对于局部注意力,如图(c)所示,冗余减少了,但仍然存在于浅层中,其中只有少数附近的令牌获得高权重。
如图(d)所示,所提出的超级标记注意力即使在浅层也可以学习全局表示。
另一方面,利用浅层中的卷积,有效地减少了局部特征的计算冗余。
处理图像或序列数据时,尤其是当数据具有高度的局部相关性时,直接在整个数据集上进行计算可能会导致大量的计算冗余。通过使用卷积操作,Uniformer模型能够针对局部特征进行高效的计算,因为它只需要在局部区域内进行操作,而不是在整个数据集上进行。这样可以大大减少不必要的计算,提高模型的效率。

对于浅层,超像素在感知上将相似的像素组合在一起,从而减少后续处理的图像基元的数量。我们将超像素的思想从像素空间借用到令牌空间,并将超级令牌假设为视觉内容的紧凑表示。
STA(超级令牌注意力)机制
首先,我们应用 快速采样算法 通过学习令牌和超级令牌之间的稀疏关联来预测超级令牌
稀疏关联(Sparse Connectivity)指的是通过设置规模远小于图像规模的卷积核,让卷积核仅与部分图像单元产生交互,以探寻图像局部有意义的特征。
然后,我们在超级令牌空间中执行自注意力,以获取超级令牌之间的长距离依赖关系;与令牌空间中的自注意力相比,由于超级令牌的表示和计算效率,这种自注意力可以显着降低计算复杂度,同时学习全局上下文信息。
最后,我们利用第一步中学习到的关联将超级令牌映射回原始令牌空间。
STViT的整体架构
通用视觉主干(Super Token Vision Transformer)STViT 被设计为具有卷积层的分层ViT混合体。采用卷积层来补偿捕获局部特征的能力。在每个阶段,我们都使用一堆超级令牌转换器(STT)块来进行高效且有效的表示学习。
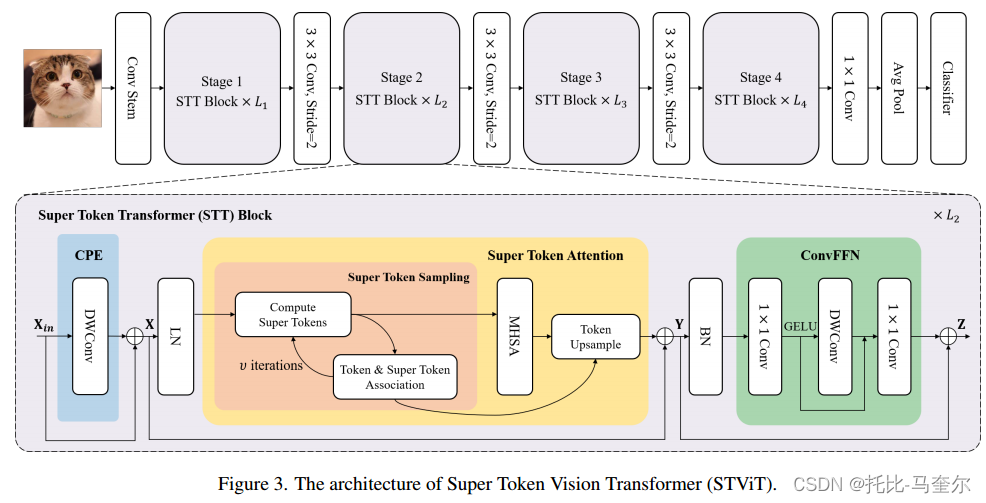
给定输入图像,首先将其输入 由四个3*3卷积组成的茎,步长分别为2、1、2、1。
然后,令牌经过四个阶段的堆叠超级令牌转换器块(STT Block),以进行分层表示提取。
每个阶段之间使用步长为2的3*3卷积来减少令牌数量。最后,使用1*1卷积来投影、全局平均池化和全连接层来输出预测。
STT Block
SST块由三个关键模块组成,即卷积位置嵌入Convolutional Position Embedding(CPE)、超级令牌注意力(STA)和卷积前馈网络(ConvFFN)。
所提出的 STA 可以有效地学习全局表示,特别是对于浅层。具有深度卷积的CPE和ConvFFN可以以较低的计算成本增强局部特征的表示能力。
STT 块包含三个关键模块:卷积位置嵌入(CPE)、超级令牌注意力(STA)和卷积前馈网络(ConvFFN):
;
;
给定输入令牌向量,首先使用
(即3*3深度卷积) 将位置信息添加到所有令牌中。与绝对位置编码(APE)和相对位置编码(PRE)相比,CRE可以通过零填充来学习绝对位置。
DWConv![]() https://blog.csdn.net/zfjBIT/article/details/127521956然后,我们通过
https://blog.csdn.net/zfjBIT/article/details/127521956然后,我们通过有效探索和充分利用长距离依赖关系来提取全局上下文表示。
最后,我们采用卷积来增强局部表示。它由两个1*1卷积、一个3*3深度卷积和一个非线性函数(即GELU)组成。因此,CPE、STA 和 ConvFFN 的组合使 STT 能够捕获局部和全局依赖关系。
超级令牌注意力(STA)
超级令牌注意力(STA)模块由三个过程组成,即超级令牌采样(STS)、多头自注意力(MHSA)和令牌上采样(TU)。
我们首先通过 STS 将令牌聚合为超级令牌,然后执行 MHSA 对超级令牌空间中的全局依赖关系进行建模,最后通过 TU 将超级令牌映射回视觉令牌。
超级令牌采样(Super Token Sampling)
在STS过程中,我们将SSN(Superpixel Sampling Network)中基于soft k-均值的超像素算法从像素空间适用到令牌空间。
给定视觉令牌,其中
是令牌编号,其中每个令牌
被假设属于m个超级令牌
。
首先,我们对规则网络区域中的令牌进行平均来对初始超级令牌进行采样,如果网格大小为
,则超级令牌的数量为
。
令牌和超级令牌关联
在SSN中,迭代 t 的像素-超像素关联计算为:
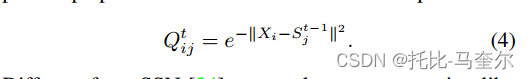
与SSN不同,我们采用类似注意力的方式来计算关联图,
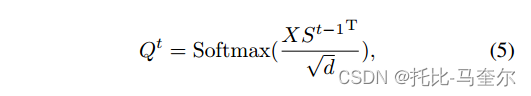
其中d是通道C的数量。
超级令牌更新
超级令牌更新为令牌的加权和:

其中,是
的列归一化。上述采样算法的计算复杂度为:

其中是迭代次数。即使对于少量的超级令牌数量m来说也是耗时的。
为了加快采样过程,按照SSN(超级像素采样工作),将每个令牌的关联计算限制为仅9个周围的超级令牌。对于绿色框中的每个令牌,仅使用红色框中的超级令牌用于计算关联。

我们仅在时更新超级令牌一次。复杂性显著降低为:
,其中获取初始超级令牌、计算稀疏关联和更新超级令牌的复杂度分别为NC、9NC、9NC.
超级令牌的自注意力
由于超级令牌是视觉内容的紧凑表示,对它们应用自注意力可以更多地关注全局上下文依赖性而不是局部特征。将标准自注意力应用于采样的超级令牌。
其中是注意力图,
,
,
。
令牌上采样
虽然超级令牌可以通过自注意力捕获更好的全局表示,但是它们在采样过程中丢失了大部分局部细节。因此,我们并不直接使用它们作为后续层的输入,而是将其映射回视觉令牌并将其添加到原始令牌X,我们使用关联映射Q从超级令牌S中对令牌进行上采样。
复杂性和冗余分析
将超级令牌注意力(STA)与标准全局自注意力进行比较
标准全局自注意力(GSA)
,
是输入令牌的注意力图。
GSA的计算复杂度为:
超级令牌注意力(STA)
,其中
是输入令牌对应的注意力图。
注意力图(Attention Map)是自注意力机制中的一个可视化工具,它展示了每个输入元素对其他元素的影响程度。具体来说,注意力图是一个二维矩阵,其中每个元素(i, j)表示输入序列中第i个元素对第j个元素的注意力权重。这个矩阵可以直观地展示模型在处理输入序列时,各个元素之间的交互和依赖关系。
STA的计算复杂度为:
其中,给定m小于N,STA的计算成本比全局注意力低得多。
冗余讨论
图像具有较大的局部冗余,例如视觉内容在局部区域往往相似。对于浅层中的某个锚标记,全局注意力会突出显示局部区域中的少数令牌,从而导致所有令牌之间的比较存在高冗余。与视觉令牌相比,所呈现的超级令牌往往具有独特的模式并抑制局部冗余。

超级令牌从初始网格到学习网格的可视化;
仅使用红色框中周围的超级令牌来计算绿色框中每个令牌的关联。
鸟头及周围区域与超级令牌存在显著差异。因此,超级令牌空间中的自注意力可以更好地捕获全局依赖关系。
STA可以被视为一种特定的全局注意力,将计算量大的注意力
分解为稀疏矩阵和小矩阵的乘法,即稀疏关联Q和小
注意力
,计算成本低得多。
对于最后两个阶段,在前两个阶段的表示学习之后,局部冗余已经很低。因此,我们将网格大小设置为 1 × 1,并直接将令牌用作超级令牌,而无需 STS 和 TU 过程。
实验
图像分类
在 ImageNet-1K数据上从头开始训练我们的模型。为了公平比较,我们遵循 DeiT中提出的相同训练策略,并采用默认的数据增强和正则化。我们所有的模型都从头开始训练 300 个时期,输入大小为 224 × 224。我们采用 AdamW 优化器,带有余弦衰减学习率调度程序和 5 个时期的线性预热。
总结
超级令牌是为了解决浅层的局部冗余而开发的,网格尺寸越大,性能越好。
更大的超级令牌可以覆盖更多的令牌并更好地捕获全局表示。
超级令牌是通过平均池化对特征进行下采样的,并且可能覆盖不同的语义区域,导致性能下降。
引入超级令牌Vision Transformer(STViT)来学习浅层中高效且有效的全局表示,将超像素的设计适应令牌空间,引入将相似令牌聚合在一起的超级令牌。超级令牌具有独特的模式,从而减少局部冗余。
超级令牌注意力将普通全局注意力分解为稀疏关联图和低维注意力的乘法,从而提高捕获全局依赖关系的效率。
超级令牌注意力算法
所提出的超级令牌注意力(STA)由三个过程组成,即超级令牌采样(STS)、多头自注意力(MHSA)和令牌上采样(TU)。
超级令牌采样又可以分解为两个迭代步骤:
,
其中是
的列归一化,对于
次迭代,上述步骤的复杂度为
。将
设置为1并以稀疏方式计算关联
。对于每个令牌,使用其周围3*3的超级令牌来计算Q。
在稀疏矩阵乘法中,只考虑非零元素,忽略零元素,按照元素的位置关系逐个计算非零元素的乘积,并将结果加到结果矩阵的相应位置上。这种方法可以显著减少计算量和存储空间的使用。
- 给定输入令牌
,首先通过平均池化来生成超级令牌
,其中
,而
是网格的大小。
- 然后,我们通过
函数提取与每个令牌对应的
超级令牌
,并计算关联
,更新
并通过
函数将周围的令牌合并到
中。S 除以 Q 的总和以进行归一化。
- 由于迭代次数设置为1,对
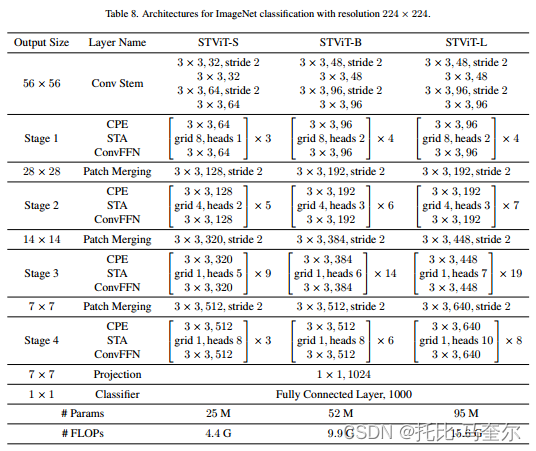
对于卷积主干,采用四个 3 × 3 卷积将输入图像嵌入到令牌中,每次卷积之后使用GELU和批量归一化。阶段之间使用步幅为 2 的 3 × 3 卷积来降低特征分辨率。CPE和ConvFFN采用 3×3 深度卷积来增强局部建模的能力。投影层由 1 × 1 卷积、批量归一化层和 Swish 激活层组成。全局平均池化在投影层之后使用,后面是全连接分类器。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









