







Vision Transformer在各种视觉任务上都取得了显著的改进,但它们之间的二次相互作用显著降低了计算效率。现有的研究主要关注标记重要性以保留局部注意标记,但完全忽略了全局标记多样性。
在本文中,我们强调了多样化全局语义的重要性,并提出了一种有效的标记解耦合、合并方法,该方法可以共同考虑标记重要性和多样性进行标记修剪。
根据类标记注意力,我们将注意标记和非注意标记解耦。除了保留最具辨别力的局部标记外,我们还合并相似的非注意标记并匹配同质的注意标记以最大化标记多样性。
一种处理类标记的方法,旨在提高模型的效率和性能,通过解耦注意和非注意标记,保留最具辨别力的标记,合并相似的非注意标记,并匹配同质的注意标记来最大化标记的多样性。
最大化标记多样性:模型会尝试将那些具有相似性质的注意标记进行匹配或组合,以确保数据的多样性。这样做可以确保模型在处理数据时不会过于偏向于某些特定的标记,从而提高其泛化能力。
(a) 基于重要性的方法根据类标记注意力保留注意标记并掩盖所有不注意标记;
(b) 基于多样性的方法将相似的标记聚集成一个组,然后将来自同一组的标记组合成一个新的标记。
(c) Incorporate 方法解耦并合并 token,同时考虑 token 的重要性和多样性。
介绍
Transformer成为自然语言处理和计算机视觉社区中最流行的架构。Vision Transformer在不同的视觉任务中实现了卓越的性能并超越了标准CNN,例如图像分类、语义分割和对象检测。Transformer最显著的特点是它能够通过自注意力机制有效捕获输入图像中的块之间的长程依赖关系。然而,令牌之间的二次交互显著降低了计算效率。
令牌剪枝
令牌剪枝(Token Pruning)是指通过减少输入令牌数量,从而减少模型计算量的一种方法
现有研究主要集中于设计不同的重要性评估策略来保留注意力集中的token并剪枝不注意力集中的token.
DyViT引入了一个额外的模块来估计每个 token 的重要性,而 EViT则根据类注意力重要性得分重新组织图像 token。
受到最近ViT变体中多样性保留研究的启发,我们认为促进token多样性对于token剪枝也至关重要
虽然图像背景和低级纹理等不注意力token与分类对象没有直接关系,但它们可以增加token多样性并提高模型的表达力。
DeiT-S上基于多样性的剪枝策略,采用不同的保留率。它并不是突出token的重要性,而是直接将相似的token聚类并组合成一个,从而最大化token多样性。基于多样性的策略无法保留原始的注意力标记,因此可能会削弱模型的判别能力。

一个令人满意的剪枝方法应该同时考虑令牌的重要性和多样性,从而能够同时保留最重要的局部信息和多样化的全局信息。
提出的修剪方法
通过有效的令牌解耦和合并来合并令牌重要性和多样性。
有效地修剪token,并最大限度地保留token多样性。
- 首先根据类标记注意力将原始标记序列解耦为注意部分和不注意部分。
- 通过一种简化的密度峰值聚类算法来有效地对相似的不注意力的标记进行聚类,并将来自同一组的这些标记组合成一个新的标记。
- 与保留所有注意标记的现有方法不同,设计一种简单的匹配算法来融合同质注意标记并进一步提高计算效率。
相关工作
Vision Transformer
与卷积网络不同,Transformer具有对远程依赖性和最小归纳偏差进行建模的显著能力。
归纳偏差是指机器学习算法在学习过程中出现的不准确和不稳定的情况;
SOTA性能指的是在特定任务上,当前最佳方法或技术所达到的最高性能水平
Visual Transformer(ViT)是第一个应用Transformer架构来实现SOTA性能的工作,但它仅在大规模图像数据集上取代了深度神经网络中的标准卷积。
为了使 ViT 摆脱对大型数据集的依赖,DeiT结合了一个用于知识蒸馏的附加标记,以提高视觉 Transformer 的训练效率。
LV-ViT通过利用所有图像补丁标记来集中计算训练损失,并进一步提高了性能。相当于把图像分类问题转化为各个token识别问题。
令牌剪枝旨在减少冗余令牌并提高各种 ViT 主干的推理效率
ViT令牌修剪
尽管ViT在视觉任务中取得了有竞争力的准确性,但它需要大量的内存和计算资源。Transformer的计算成本较高,主要是由于多头自注意力(MHSA)的二次时间复杂度。因此,尝试根据Transformer中的重要性得分来修剪token。
根据模型中是否需要引入额外的参数,我们将现有的token剪枝方法分为以下两类:
①通过插入预测模块来执行token修剪
- DyViT设计了一个插入不同层的轻量级预测模块,以估计每个标记的重要性得分,以在给定当前特征的情况下修剪冗余token;
- IA-RED2引入可解释模块来动态删除与输入无关的冗余token;
- AdaViT将轻量级决策网络连接到骨干网以动态生成决策;
②利用 class token注意力来保持注意力token
- EViT根据类别标记注意力将图像标记分为注意标记和非注意标记,保留注意标记并丢弃非注意图像标记以重新组织图像标记;
- Evo-ViT通过全局类别注意力分别对慢速和快速更新来区分信息性和非信息性标记;
- A-ViT设计了一种基于class token注意力的自适应token剪枝机制,动态调整不同复杂度图像的计算成本。
与仅关注token重要性的token修剪方法不同,我们的方法还考虑了token语义信息的多样性。
预处理工作
在标准vision Transformer中,每个输入图像首先被转为一维块序列
。然后,所有补丁通过可训练的线性层映射到D维标记嵌入。此外,将可学习的位置嵌入
添加到令牌嵌入中以保留位置信息。
形式上,输入补丁序列可以表示为:
其中表示用作图像表示的可学习类标记,
表示
的第i个补丁的标记。然后,将此类标记序列输入到具有L个堆叠Transformer块的ViT模型中,每个Transformer块由多头自注意力(MHSA)模块和前馈网络(FFN)组成。
MHSA
在 MHSA 中,输入令牌序列分别线性映射为查询 Q、键 K 和值 V 三个不同的矩阵。
其中Z是N+1个令牌的令牌序列,Concat[.]输出H个头的特征串联。分别是Q,K,V在第h个头中的投影矩阵。d是单个头的特征尺寸。
FFN
FFN通常由两个全连接层和一个非线性映射层组成,可以表示为:
计算复杂度
输入token序列的维度为N×D,其中N是token的数量,D是每个token的嵌入维度。
MHSA模块的计算复杂度为;FFN模块的计算复杂度为
;总计计算复杂度为
。由于减少通道维度D仅影响当前矩阵乘法的计算,因此大多数相关工作倾向于修剪标记,例如减少N的数量,以线性甚至二次方的方式减少所有操作。
方法
综述
我们的方法结合了token的重要性和多样性来获得高效且准确的Vision Transformer。为此,我们提出了token解耦和合并方法,在FLOP和准确性之间实现有希望的权衡。
将我们的方法插入 DeiT-S 模型的第 4、7 和 10 层。

(底部)单个变压器块内的模型结构。我们根据类令牌注意力将注意力和不注意力令牌解耦。然后,我们对不专心的令牌进行聚类,并将同一组中的令牌组合成一个新令牌。同时,我们匹配同质注意力标记并组合同一对标记。
Token Decoupler指的是token(令牌)的解耦
该方法有两个主要组件:token 解耦器和 token 合并器。解耦器根据类 token 注意力将原始 token 序列划分为注意部分和非注意部分。然后,合并器将相似的非注意 token 聚类并匹配同类的注意 token。
令牌多样性
即使图像背景也可以帮助改善前景实例分类,我们认为不太重要的标记也可以包含有用的语义信息,并成为信息多样性的有效补充。
令牌多样性对于优化变压器结构非常关键。因此,适当地保留这些无注意力的标记可以增加语义信息的多样性,这有利于标记修剪。相反,盲目丢弃令牌会导致语义信息不可逆的丢失,尤其是在保留率较低的情况下。
我们利用token和rank-1矩阵之间的差异来衡量token序列Z的多样性。
多样性得分:
,
其中指的是
范数,
是N个token和z的token序列;
是其中的一个token。
是z的矩阵转置,1是全1向量。
的秩为1。多样性得分越大,表示token序列越多样化。
多样性分数影响令牌修剪性能
令牌序列多样性得分与分类准确率正相关。无论是 EViT 方法还是我们提出的方法,较高的多样性得分始终会带来较高的准确性。
令牌解耦器(Token Decoupler)
为了在保持多样性的同时充分考虑 token 的重要性,我们优先考虑注意力 token,以保留最重要的语义信息。因此,我们将原始 token 序列解耦为注意力 token 和不注意力 token,以便同时保持 token 的多样性和重要性。
我们通过比较 token 与类 token 的相似性将 token 分成两组。从数学上讲,类 token 与其他 token 之间的相似性得分 Attncls 可以计算为类 token 注意力。
其中,表示查询向量的类标记。总共有N个令牌,保留率为
,我们根据注意力分数选择前K个令牌作为注意力令牌。剩余的N-K个令牌被识别为包含较少信息的无注意力令牌。
在多头自注意力层中,我们计算所有头的注意力分数的平均值。
令牌合并
在合并令牌时,我们对注意力集中和注意力不集中的令牌应用不同的策略。对于不注意令牌,我们首先应用密度峰值聚类算法对不注意令牌进行聚类,然后通过加权和将来自同一组的令牌组合成新的令牌。
我们就可以整合出一个新的不注意的令牌序列。对于注意力令牌,我们采用简单的匹配算法来融合同质注意力令牌。融合后的令牌序列为
。我们连接T和P以获得修剪后的令牌序列
。
不注意的令牌聚类
常见的K-means聚类算法需要多次迭代才能获得满意的结果,降低了实践中的吞吐量,违背了加速模型的初衷。我们发现密度聚类算法可以利用类的密度连通性来快速找到任意形状的类。因此,我们简化了高效的密度峰值聚类算法(DPC),既不需要迭代过程,也不需要更多参数。
它假设聚类中心被低密度邻居包围,并且聚类中心与任何高密度点之间的距离相对较大。我们为每个令牌 i 计算两个变量:密度 ρ 和距较高密度标记的最小距离 δ。给定一组令牌 x,我们计算每个令牌的密度 ρ
。其中Z表示令牌集合,
则是对应的令牌特征。
对于密度最高的令牌,其最小距离设置为它与任何其他令牌之间的最大距离。我们将 定义为令牌 i 与任何其他具有更高密度的令牌之间的最小距离。
每个令牌的最小距离为:
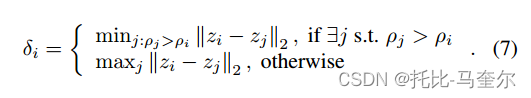
我们将第i个标记的聚类中心得分表示为,分数越高意味着成为集群中心的潜力越大。
DPC算法将每个剩余的token分配给聚类中心距离该token最近且密度较高的聚类。
注意力令牌匹配
由于注意力令牌包含最终分类任务的关键语义信息,因此最好能够保留原始令牌。
为了解决这个问题,我们定制了一种简单的匹配算法,该算法在融合同质令牌的同时保留最重要的令牌。具体来说,我们定义余弦相似度度量来确定不同标记之间的相似度并计算注意令牌之间的余弦相似度得分。然后我们选择前 K 个最相似的令牌对作为同质令牌。最后,我们将每对令牌组合成一个新令牌,并联系剩余的注意力令牌。
尽管同一集合中令牌具有相似的语义信息,但每个令牌的语义重要性不一定相同。我们并不是盲目地对同一组中的标记进行平均,而是通过加权和来组合这些标记。通过引入类令牌注意力来表示重要性,将同一组令牌组合成一个新令牌:
,其中
表示token
的重要性得分,
表示第i个集合。
实验
数据集和评估指标
在 ImageNet-1K上进行的,有 128 万张训练图像和 50000 张验证图像。报告 top1 分类精度和浮点运算 (FLOP) 以评估模型效率。此外,我们还测量了单个 NVIDIA V100 GPU 上模型的吞吐量,批量大小固定为 256。
完全丢弃无注意的token会大大降低token的多样性,从而导致原始标记序列的语义信息减少。我们应用token解耦和合并来同时考虑token的重要性和多样性。
当我们只保留一些token时,合并token显然比只保留前 K 个注意力token更有意义。
方法的主要介绍
我们的方法关注对图像预测贡献更大的区域,而不是无信息的背景。
例如,动物的五个感觉器官被保留下来。它表明我们的方法有效地解耦了注意力和不注意力的标记。与掩盖所有疏忽标记的其他方法不同,我们的方法将具有相似语义的背景补丁结合在一起。
例如,动物的皮毛被合并成一个token。这意味着我们的方法不仅关注注意标记,而且保持标记语义的多样性。还值得指出的是,第五张和第六张图中,一对眼睛是匹配并组合成令牌的。这表明我们的方法有效地融合了同质注意力标记并减少了潜在的冗余。
消融实验
每个模块的有效性
根据剪枝层中的类token注意力丢弃不注意的标记;将所有不注意的token打包成一个token;
将不注意的token进行聚类,并将同一组的token组合成一个新的token;
匹配注意力token,将同一组的token组合成一个新的token;
同质注意力(Homogeneous Attention)是指个体将注意力集中在与自身具有相似特征、兴趣、经历或认知结构的信息上。这种注意力倾向使得个体更容易理解和处理与自己相似的信息。
不同的token合并策略
利用池化操作来减少token数量;在MHSA和FFN之间添加一系列卷积层以减少token维度;
对token进行聚类,并将同一组的token组合成一个新的token;
简化了一个高效的 DPC 算法,既不需要迭代过程,也不需要更多参数,
这在准确性和效率上都优于其他策略。
我们的方法在不施加额外参数的情况下实现了准确性和 FLOP 之间的 SOTA 性能权衡。














 2846
2846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









