







具有收缩和扩展路径的全卷积神经网络 (FCNN) 在大多数医学图像分割应用中表现出了突出的作用。在 FCNN 中,编码器通过学习全局和局部特征以及上下文表示来发挥不可或缺的作用,这些特征和上下文表示可用于解码器的语义输出预测。
在FCNN中,收缩路径通常用于捕获图像的上下文信息,并逐步减少空间维度;而扩展路径则用于恢复空间维度,使输出图像的尺寸与输入图像相近,并提供更精细的分割结果。
FCNN中卷积层的局部性限制了学习远程空间远程依赖性的能力。受到自然语言处理(NLP)转换器最近在远程序列学习中取得成功的启发,将体积(3D)医学图像分割任务重新表述为序列到序列的预测问题。
UNET Transformers (UNETR)
利用 Transformer 作为编码器来学习输入量的序列表示并有效捕获全局多尺度信息,同时也遵循成功的“U 形”网络编码器和解码器的设计。
Transformer编码器通过不同分辨率的跳跃连接直接连接到解码器,以计算最终的语义分割输出。
多器官分割的颅穹外多图集标记 (BTCV) 数据集和用于脑肿瘤和脾脏分割任务的医学分割十项全能 (MSD) 数据集
“U形”编码器-解码器架构在各种医学语义分割任务中取得了最先进的结果。在典型的U-Net架构中,编码器负责通过逐渐下采样提取的特征来学习全局上下文表示,而解码器将提取的表示上采样到输入分辨率,以进行像素/体素语义预测。此外,跳跃连接将编码器的输出与不同分辨率的解码器合并,从而允许恢复在下采样期间丢失的空间信息。
跳跃连接![]() https://blog.csdn.net/j_qin/article/details/127843666
https://blog.csdn.net/j_qin/article/details/127843666
尽管基于FCNN的方法具有强大的表示学习能力,但它们在学习远程依赖性方面的性能仅限于其局部感受野。因此,捕获多尺度信息的缺陷导致对形状和尺度可变的结构(不同大小的脑损伤)的分割不理想。可以使用多孔卷积层来扩大感受野。然而,卷积层中感受野的局部性仍然将其学习能力限制在相对较小的区域。将自注意力模块与卷积层相结合来提高非局部建模能力。
在自然语言处理(NLP)中,Transformer 的自注意力机制可以动态突出单词序列的重要特征。在计算机视觉中,使用 Transformer 作为骨干编码器是有益的,因为它们具有建模远程依赖关系和捕获全局上下文的强大能力。Transformer 将图像编码为一维补丁嵌入序列,并利用自注意力模块来学习从隐藏层计算的值的加权和。
将三维分割任务重新表述为一维序列到序列预测问题,并利用Transformer作为编码器从嵌入的输入补丁中学习上下文信息。从Transformer编码器提取的表示通过多个分辨率的跳跃连接与基于CNN的解码器合并,以预测分割输出。
提出的框架没有在解码器中使用 Transformer,而是使用基于 CNN 的解码器。这是因为,尽管 Transformer 具有很强的学习全局信息的能力,但它们无法正确捕获局部信息。
主要贡献
① Transformer 编码器直接利用嵌入式 3维 体积来有效捕获远程依赖性;
② 跳跃连接编码器组合提取的不同分辨率的表示并预测分割输出;
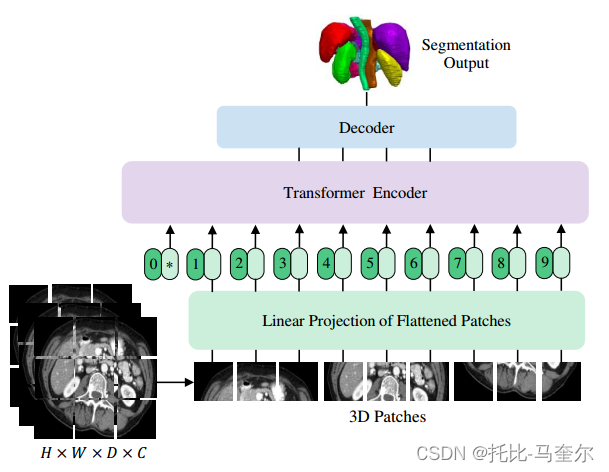
2. 相关工作
基于 CNN 的分割网络:对于体积分割,三平面架构有时用于组合每个体素的三视图切片,也称为 2.5D 方法。相比之下,3D 方法直接利用由一系列 2D 切片或模态表示的完整体积图像。采用不同尺寸的直观理解是利用多扫描、多路径模型来捕获图像的下采样特征。
Vision Transformers
通过对纯 Transformer 进行大规模预训练和微调,展示了图像分类数据集上最先进的性能。在目标检测中,基于端到端 Transformer 的模型在多个基准测试中表现出了突出的优势。具有不同分辨率和空间嵌入的分层Vision Transformers。这些方法逐渐降低变压器层中特征的分辨率并利用子采样注意模块。
使用基于 Transformer 的模型进行 2D 图像分割任务的可能性。Cheng等人介绍了SETR模型,其中提出了一种预训练的变压器编码器,具有基于CNN的解码器的不同变体,用于语义分割任务。Chen 等人提出了一种多器官分割方法,通过使用 Transformer 作为 U-Net 架构瓶颈中的附加层。张等人提出在单独的流中使用 CNN 和 Transformer 并融合它们的输出。 Valanarasu 等人提出了一种基于 Transformer 的轴向注意机制,用于 2D 医学图像分割。
本文模型的主要区别
- UNETR是为3D分割量身定制的,并直接利用体积数据;
- UNETR采用Transformer作为分割网络的主要编码器,并通过跳跃连接直接连接到解码器,而不是将其作为分割网络中的注意力层;
- UNETR不依赖于主干CNN用于生成输入序列而是直接利用标记化补丁。
对于3D医学图像分割,提出了一个框架,该框架利用主干CNN进行特征提取,利用Transformer 来处理编码表示,并利用CNN解码器来预测分割输出。Wang 等人提出在3D编码器-解码器CNN的连接处 使用 Transformer 来完成语义脑肿瘤分割的任务。
与这些方法相反,我们的方法通过使用跳跃连接直接将编码表示从转换器连接到解码器。
3. 架构
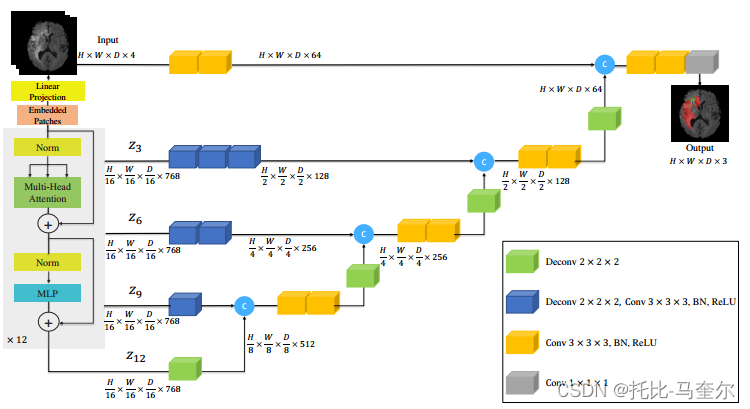
UNETR 利用由一堆变压器组成的收缩-扩展模式作为编码器,通过跳跃连接连接到解码器。通过将分辨率为(H,W,D)和C个输入通道的3D输入体积 创建一个一维序列,将其划分为平坦的均匀非重叠块
,其中(P, P, P) 表示每个补丁的分辨率,
是序列的长度。
随后,我们使用线性层讲补丁投影到 K 维嵌入空间中,该空间在整个Transformer层中保持不变。为了保留提取的图块的空间信息,根据以下公式将一维可学习位置嵌入添加到投影图块嵌入
。
可学习的标记不会添加到嵌入序列中,Transformer主干是为语义分割而设计的。在嵌入层之后,利用一堆Transformer块,其中包括多头自注意力(MSA)和多层感知器(MLP)子层。
其中Norm()表示层归一化,MLP由两个具有GELU激活函数的线性层组成, 是中间块标识符,L是Transformer 层的数量。
MSA 子层由 n 个并行的自注意力 (SA) 头组成。具体来说,SA 块是一个参数化函数,它学习查询 (q) 与序列 中相应的键 (k) 和值 (v) 表示之间的映射。注意力权重 (A) 是通过测量 z 中两个元素及其键值对之间的相似度来计算的。
其中, 是一个比例因子,用于在不同的键 k 值下将参数数量保持为恒定值。使用计算出的注意力权重,序列 z 中值 v 的 SA 输出计算如下:
v 表示输入序列中的值, 是缩放因子。MSA 的输出定义为
其中表示多头可训练参数权重。
在U-Net中,编码器的多尺度特征通常通过跳跃连接直接融合到解码器的相应层中,以帮助保留空间细节。从Transformer 提取大小为的序列表示
,并将它们重塑为
大小的张量。
K是特征大小(即Transformer的嵌入大小)。提取的特征序列 3×3×3卷积层完成的,这些卷积层后面通常跟着归一化层(例如批量归一化或层归一化)。
在编码器的瓶颈处(即 Transformer 的最后一层的输出),我们将反卷积层应用于转换后的特征图,以将其分辨率提高 2 倍。然后,我们将调整大小后的特征图与前一个 Transformer 输出的特征图(例如 z9)连接起来。并将它们输入到连续的 3 × 3 × 3 卷积层中,并使用反卷积层对输出进行上采样。对所有其他后续层重复此过程,直到达到原始输入分辨率,其中最终输出被输入到具有 softmax 激活函数的 1×1×1 卷积层中,以生成体素级语义预测。
3.2 损失函数
损失函数是soft dice loss 和 cross-entropy loss 的组合,并且可以根据以下方式以体素方式计算
其中 I 是体素的数量;J是类别数;表示第
i 个体素属于第 j 个类别的概率; 表示在one-hot编码中,如果体素
i 属于类别 j,则 为1,否则为0。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









