







乳腺癌 的非侵入性诊断程序涉及体检和成像技术,例如乳房 X 光检查、超声检查和磁共振成像 [3,4]。然而,体外检查可能无法及早发现它,并且影像学检查对于更全面地评估癌变区域和识别癌症亚型的敏感性较低[5,6]。通过乳腺活检进行的组织病理学成像,即使是微创的,也可以准确识别癌症亚型并精确定位病变[7]。
CNN 表现出固有的归纳偏差,并且会随着图像中感兴趣对象的平移、旋转和位置而变化。
因此,在训练 CNN 模型时通常会应用图像增强,尽管数据增强可能无法在训练集中提供预期的变化。因此,基于自注意力的深度学习模型对图像中感兴趣对象的方向和位置更加鲁棒。
Vision Transformer(ViT)采用Transformer来处理图像。用于分类任务的 ViT 实现了全局自注意力,其中计算图像块和所有其他块之间的关联。这种全局量化会导致补丁数量的二次计算复杂性,使其不太适合处理高分辨率图像。
swin Transformer 的 ViT 变体,可以在移动窗口上工作并提供可变的图像块分辨率。为了高效建模,提出并计算了局部窗口内的自注意力,为了均匀划分图像,窗口以不重叠的方式排列。基于窗口的自注意力具有线性复杂度并且可扩展。然而,基于窗口的自注意力的建模能力有限,因为它缺乏跨窗口的连接。
因此,提出了一种移位窗口分区方法,该方法在连续的 swin Transformer 块中的分区配置之间交替,以允许跨窗口连接,同时保持非重叠窗口的高效计算。swin Transformer 中的移位窗口方案通过将自注意力计算限制在非重叠的局部窗口上,同时促进跨窗口连接,从而提高了效率。
2. 相关工作
2.1 基于乳腺X线摄影
在对特定感兴趣区域 (ROI) 进行分类时,需要考虑的乳房 X 光检查的典型特征是质量大小、ROI 的规则/不规则形状、ROI 边界的均匀性和组织的密度。这些手工制作的特征被输入到多个分类器,例如支持向量机、k 最近邻、逻辑回归、二元决策树和人工神经网络,以将乳房 X 光照片分类为健康或癌性。
采用了 AlexNet、GoogLeNet、ResNet50 的迁移学习、多级微调 CNN、生成对抗网络、自动编码器和多 ResNet 等基于深度学习的方法来进行乳房肿块分类。
2.2 基于超声检查
超声检查也是非侵入性的,比乳房X线检查更便携,对疾病更敏感。
超声检查也是非侵入性的,比乳房X线检查更便携,对疾病更敏感。存在基于 ML 和 DL 的方法用于从超声图像中对 BC 进行分类。基于 ML 的方法包括基于 ROI 的放射组学特征,用于使用各种 ML 分类器进行分类。希尔伯特变换和标记控制的分水岭变换用于提取形状和纹理特征,这些特征进一步馈送到 KNN 分类器和集成决策树模型。
采用预训练 CNN 块之间的深度表示缩放层来实现更好的信息流,并且所得模型表现出改进的性能。其他几项研究包括形状自适应 CNN、U-Net 编码器-解码器 CNN 架构、扩展语义分割技术以及 DarkNet53 的改进特征。总体而言,超声图像的 乳腺癌 分类已经得到了很好的研究,并且大多数研究都是基于熟悉的 BUSI 数据集。
2.3 基于组织病理学
非侵入性成像程序可能无法识别癌症区域及其亚型。为了弥补这一缺点,活检被用于更广泛地研究乳腺组织中的恶性肿瘤。活检包括收集样本并对安装在显微镜载玻片上的组织进行染色,以更好地显示细胞质和细胞核。
经过微调的 VGG16 和 VGG19 CNN 模型,从 544 张全幻灯片图像中对癌与非癌进行了两类分类 。在其他最近的研究中,使用 BreaKHis 数据集,分别实施了改进的残差神经网络和基于图像矩的人工神经网络,仅使用 40 倍缩放因子的图像进行良性和恶性分类。
3. 方法
3.1 数据集
BreaKHis 数据集包含 7909 张显微 RGB 图像,这些图像是通过对 82 名患者的乳腺肿瘤进行手术活检而获得的,放大倍数为 50×、100×、200× 和 400× 。数据包含良性和恶性亚型。此外,良性癌症亚型包括纤维腺瘤、管状腺瘤、叶状肿瘤和腺病,而恶性亚型包括导管癌、乳头状癌、小叶癌和粘液性癌。
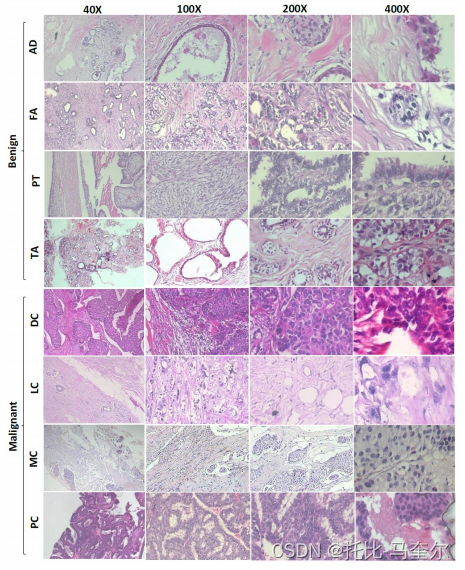
AD:腺病、FA:纤维腺瘤、PT:叶状肿瘤、TA:管状腺瘤、
DC:导管癌、LC:小叶癌、MC:粘液性癌、PC:乳头状癌
3.2 Swin Transformer
首先,将原始图像分辨率 700 × 460 调整为 224 × 224,因为这是预训练和微调的 SwinT 的要求。此外,输入尺寸为 H × W × 3 的输入 RGB 图像分割成大小等于 4 × 4 的小补丁。因此,每个图像补丁的尺寸为 4 × 4 × 3 = 48。
随后,在大小为 48 的原始特征张量上应用线性嵌入层,将其投影到任意特征维度 C。 在这些大小为 C 的补丁线性嵌入上应用了几个具有改进的自注意力的 Swin Transformer 块,并保持标记数量等于 。线性嵌入层与 Swin Transformer 块一起构成了 swin Transformer 架构的第 1 阶段。
从 SwinT-B 架构的第 2 阶段开始,通过补丁合并层降低了补丁的数量。第 2 阶段中的补丁合并层将每组 2×2 相邻补丁的特征连接起来,并对 4C 维连接的特征应用线性层。这将补丁数量减少了 4 倍,线性层的输出深度设置为 2C。此外,Swin Transformer Block 用于特征变换,而第 2 阶段的输出补丁数量保持在 。
该过程重复两次,构成第 3 阶段和第 4 阶段,分别产生 和
的输出分辨率。
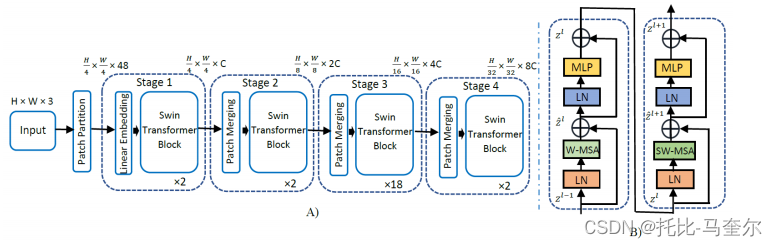
(A) swin Transformer 基础模型的架构 (B) 两个连续的 swin Transformer 块
输入图像尺寸为224×224×3,C=128,层数={2, 2, 18, 2}
3.3 模型交叉验证和测试
原始数据集中图像的强度值在 0 到 255 之间。
使用 vit-keras 模块中可用的预处理方法将这些强度重新调整为介于 -1 和 1 之间的值。当包含所有缩放因子的图像时,数据集被分为 62:8:30 分别用于训练、验证和测试。当对特定缩放系数的图像进行分类时,遵循 72:8:20 的分割。
3.4 模型集成
基于对 N 个单独模型的预测 向量进行平均来实现集成模型。最终的类别预测是给出的
向量中最高概率的索引。















 5365
5365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









