







关键词
音画同步、CNN、SyncNet
前言
在视频播放中,常常出现音画不同步的现象,它们的时差通常在 -125ms~45ms 之间。
解决该问题通常有以下几种思路:
- 传统方式:场记板 (clapperboard)
- 现代方式:时间码 (timecode)、时间规整技术 (time warping)
(大多数相关工作并未以观众可直接访问的音视频作为数据集)
(一些文章借助因素、母音等)
(更新的文章尝试寻找音视频数据之间的一致性)
贡献点
- 提出语言和说话人无关的模型
- 通过无标注数据基于卷积网络对音频和嘴形经行特征嵌入
- 第一个端到端的音唇同步网络
- 应用场景:
- 检测音唇同步误差
- 判断多人场景中的发言人
- 读唇术
模型
SyncNet网络结构,输入0.2s 的音频和视频片段(无标签),但假设它们通常是同步的。
音频流
输入数据为 MFCC 数值(声音的短时功率谱,参考)
可编码为热图,如下所示。(13×20×1)
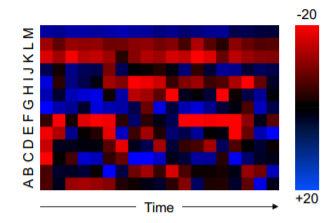
采用基于VGG-M (参考) 的CNN进行训练。
视频流
预处理得到嘴唇部分的灰色图片。
时间方向上以 25fps 的速率取连续5帧。(111×111×5)

损失函数
采用对比损失(用于孪生网络)
E
=
1
2
N
∑
i
=
1
N
(
y
n
)
d
n
2
+
(
1
−
y
n
)
max
(
m
a
r
g
i
n
−
d
n
,
0
)
2
E=\frac{1}{2N}\sum_{i=1}^{N}(y_n)d_n^2+(1-y_n)\max(margin-d_n, 0)^2
E=2N1i=1∑N(yn)dn2+(1−yn)max(margin−dn,0)2
d
n
=
∣
∣
v
n
−
a
n
∣
∣
2
d_n=||v_n-a_n||_2
dn=∣∣vn−an∣∣2
训练
采用CNN,运用带momentum的SGD进行训练。
数据增强:
- 所有样本音频随机调整±10%
- 负样本进行随机截取
- 对视频采用ImageNet的标准增强方法
数据集
BBC
实验
3个应用场景
音唇同步误差
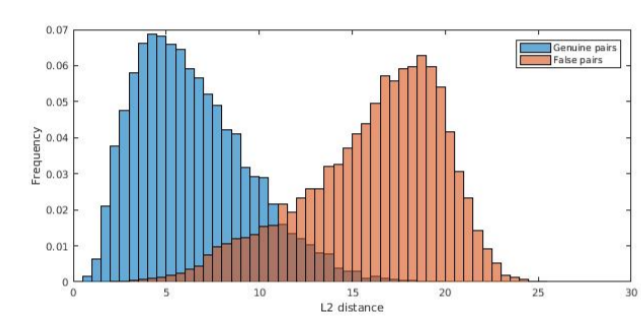

另外对不同语言也适用。
发言人检测
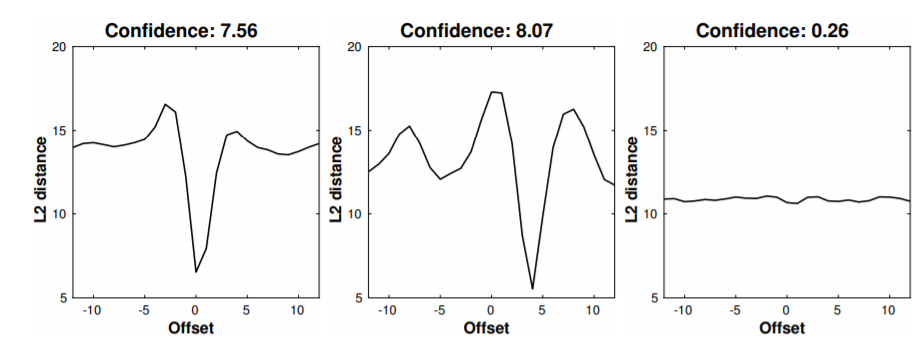
通过计算匹配度得到。

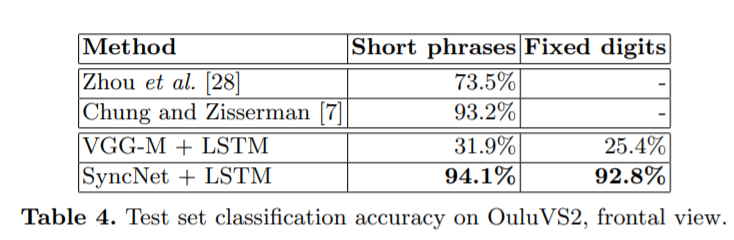
读唇术
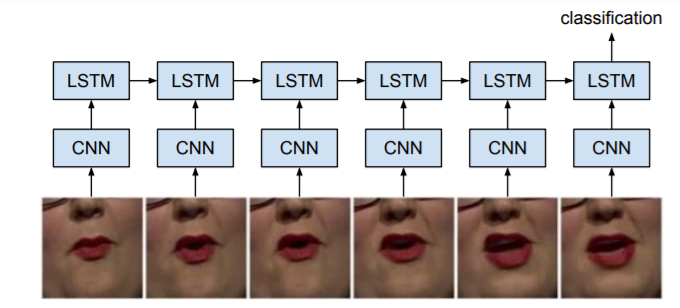
增加LSTM对图像帧做序列标注。















 2534
2534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









