







前置知识
注意力机制
见 这篇
二维 TSP 问题
给定二维平面上
n
n
n 个点的坐标
S
=
{
x
i
}
i
=
1
n
S=\{x_i\}_{i=1}^n
S={xi}i=1n,其中
x
i
∈
[
0
,
1
]
2
x_i\in [0,1]^2
xi∈[0,1]2,要找到一个
1
∼
n
1\sim n
1∼n 的排列
π
\pi
π ,使得目标函数
L
(
π
∣
s
)
=
∥
x
π
1
−
x
π
n
∥
2
+
∑
i
=
1
n
−
1
∥
x
π
i
−
x
π
i
+
1
∥
2
L(\pi|s)=\Vert x_{\pi_1}-x_{\pi_n} \Vert_2+\sum_{i=1}^{n-1}\Vert x_{\pi_{i}}-x_{\pi_{i+1}}\Vert_2
L(π∣s)=∥xπ1−xπn∥2+i=1∑n−1∥xπi−xπi+1∥2
尽可能小。
Pointer Networks
指定 π 1 = 1 \pi_1=1 π1=1 ,然后依次预测 π 2 , π 3 , . . . , π n \pi_2,\pi_3,...,\pi_n π2,π3,...,πn 。
预测方式利用了注意力机制(加性模型):
u
j
i
=
v
T
tanh
(
W
1
e
j
+
W
2
d
i
)
u_j^i=v^T\tanh(W_1e_j+W_2d_i)
uji=vTtanh(W1ej+W2di)
其中
v
,
W
1
,
W
2
v,W_1,W_2
v,W1,W2 是可学习的参数,
e
j
e_j
ej 是(节点
j
j
j 的)encoder 隐状态,
d
i
d_i
di 是(已选
i
−
1
i-1
i−1 个点的图的) decoder 隐状态。然后,直接将 softmax 后的
u
i
u^i
ui 作为输出:
P
(
π
i
∣
π
1
:
i
−
1
,
P
)
=
softmax
(
u
i
)
P(\pi_i|\pi_{1:i-1},\mathcal{P})=\text{softmax}(u^i)
P(πi∣π1:i−1,P)=softmax(ui)
encoder 和 decoder 使用单层 LSTM 实现(隐藏层维度
256或512)。
训练使用 SGD(lr=1.0, batch_size=128,权重取值[-0.08, 0.08],L2 梯度裁剪阈值2.0)。
训练数据量 1M。
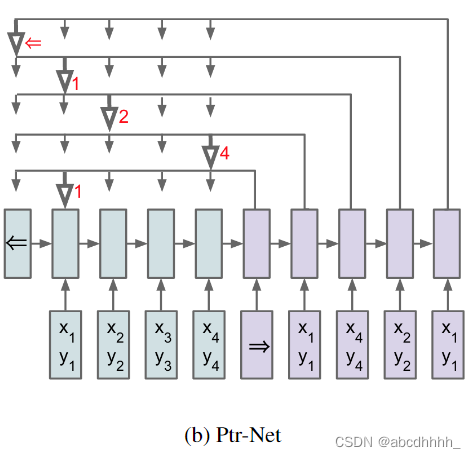
效果如下:
由于是监督学习,只用了 n ∈ [ 5 , 20 ] n\in [5,20] n∈[5,20] 的训练集,方便获取 label
传统的 RNN 的输出是固定词汇表上的分布,因此不能应对 n n n 比训练集大的情况。而 Pointer Networks 的输出是输入序列上的分布,因此可以应对任意大小的 n n n 。
Neural Combinatorial Optimization with Reinforcement Learning
引入强化学习,学习策略函数 p θ ( π ∣ s ) = ∏ t = 1 n p θ ( π t ∣ s , π 1 : t − 1 ) p_{\theta}(\pi|s)=\prod_{t=1}^np_{\theta}(\pi_t|s,\pi_{1:t-1}) pθ(π∣s)=∏t=1npθ(πt∣s,π1:t−1)。
encoder 和 decoder 与 Pointer Networks 相同。
训练使用强化学习(REINFORCE+baseline):
∇ θ J ( θ ∣ s ) = E p θ ( π ∣ s ) [ ( L ( π ) − b ( s ) ) ∇ θ log p θ ( π ∣ s ) ] \nabla_{\theta}J(\theta|s)=E_{p_\theta(\pi|s)}[(L(\pi)-b(s))\nabla_{\theta} \log p_{\theta}(\pi|s)] ∇θJ(θ∣s)=Epθ(π∣s)[(L(π)−b(s))∇θlogpθ(π∣s)]
其中 b ( s ) b(s) b(s) 使用 critic network 近似 L ( π ∣ s ) L(\pi|s) L(π∣s),结构包括 1 个 LSTM encoder,1 个 LSTM 处理块和 2 层带 ReLU 的 MLP decoder。
求解时,使用 active search 方法,不断进行 采样-更新答案-更新参数 的过程,baseline 改为指数滑动平均(无需求导,更简单)
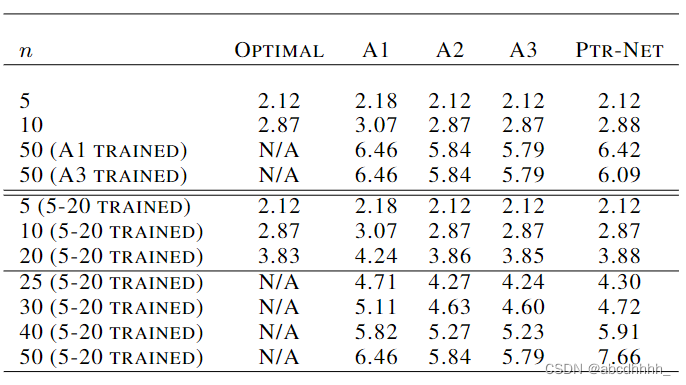
结果如下:

Attention, Learn to Solve Routing Problems!
encoder 和 decoder 参考了 Transformer 的结构。
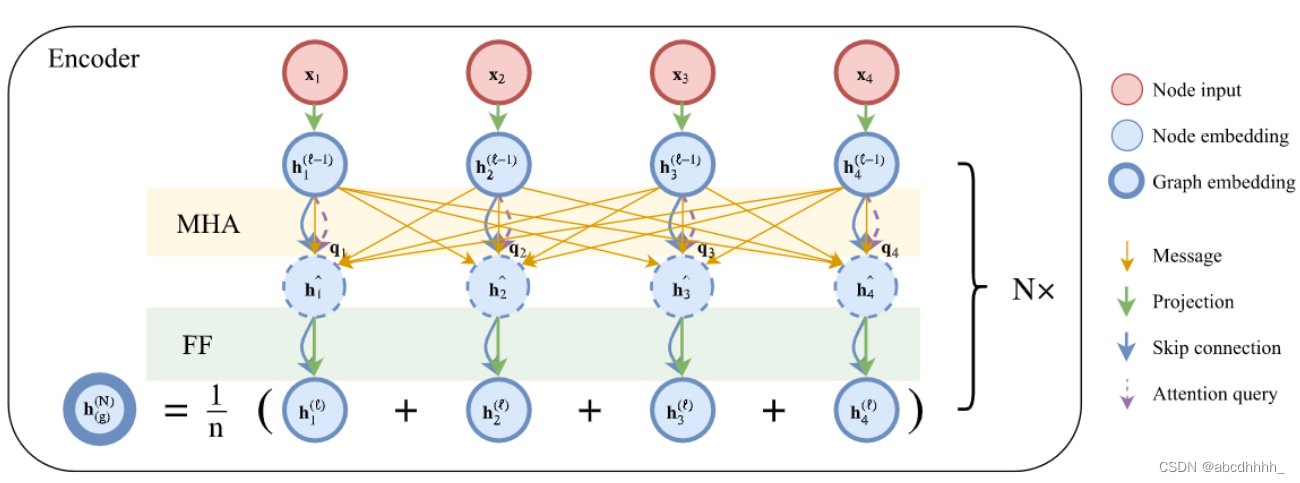
encoder 部分:
共有 N N N 层,记 h i ( l ) h_i^{(l)} hi(l) 为节点 i i i 在第 l l l 层的编码。
- h i ( 0 ) = W x x i + b x h_i^{(0)}=W^xx_i+b^x hi(0)=Wxxi+bx
- h ^ i ( l ) = B N l ( h i ( l − 1 ) + M H A i l ( h 1 : n ( l − 1 ) ) ) \hat h_i^{(l)}=BN^l(h_i^{(l-1)}+MHA_i^l(h_{1:n}^{(l-1)})) h^i(l)=BNl(hi(l−1)+MHAil(h1:n(l−1)))
- h i ( l ) = B N l ( h ^ i ( l ) + F F l ( h ^ i ( l ) ) ) h_i^{(l)}=BN^l(\hat h_i^{(l)}+FF^l(\hat h_i^{(l)})) hi(l)=BNl(h^i(l)+FFl(h^i(l)))
- h ˉ ( N ) = 1 n ∑ i = 1 n h i ( N ) \bar h^{(N)}=\frac{1}{n}\sum_{i=1}^nh_i^{(N)} hˉ(N)=n1∑i=1nhi(N)
W x , b x W^x, b^x Wx,bx 是可学习的参数
h i ( l ) h_i^{(l)} hi(l) 维度 d h = 128 d_h=128 dh=128
MHA 层 head 数 M = 8 M=8 M=8
FF 包括一个 512 512 512 维隐藏层+ReLU
decoder 部分:
令 h ( c ) ( N ) h_{(c)}^{(N)} h(c)(N) 为当前时刻的上下文特征
h ( c ) ( N ) = { [ h ˉ ( N ) , h π t − 1 ( N ) , h π 1 ( N ) ] t > 1 [ h ˉ ( N ) , v l , v f ] t = 1 h_{(c)}^{(N)}=\begin{cases}[\bar h^{(N)},h_{\pi_{t-1}}^{(N)},h_{\pi_1}^{(N)}] & t>1\\ [\bar h^{(N)},v^l,v^f] & t=1\end{cases} h(c)(N)={[hˉ(N),hπt−1(N),hπ1(N)][hˉ(N),vl,vf]t>1t=1
其中 v l , v f ∈ R d h v^l,v^f\in \R^{d_h} vl,vf∈Rdh 是可学习的参数
然后利用注意力机制(缩放点积模型,再用 tanh 截断)
- q ( c ) = W Q h ( c ) ( N ) q_{(c)}=W^Qh_{(c)}^{(N)} q(c)=WQh(c)(N)
- k i = W K h i ( N ) k_i=W^Kh_i^{(N)} ki=WKhi(N)
- v i = W V h i ( N ) v_i=W^Vh_i^{(N)} vi=WVhi(N)
- u ( c ) j = { C tanh ( q ( c ) T k j d k ) j ∉ π 1 : t − 1 − ∞ o t h e r w i s e u_{(c)j}=\begin{cases}C\tanh(\frac{q_{(c)}^Tk_j}{\sqrt{d_k}})&j\notin \pi_{1:t-1}\\-\infty & otherwise\end{cases} u(c)j={Ctanh(dkq(c)Tkj)−∞j∈/π1:t−1otherwise
- p θ ( π t ∣ s , π 1 : t − 1 ) = softmax ( u ( c ) ) p_{\theta}(\pi_t|s,\pi_{1:t-1})=\text{softmax}(u_{(c)}) pθ(πt∣s,π1:t−1)=softmax(u(c))
其中 d k = d h M = 16 d_k=\frac{d_h}{M}=16 dk=Mdh=16, C = 10 C=10 C=10
训练使用强化学习(REINFORCE+baseline):
∇ θ J ( θ ∣ s ) = E p θ ( π ∣ s ) [ ( L ( π ) − b ( s ) ) ∇ θ log p θ ( π ∣ s ) ] \nabla_{\theta} J(\theta|s)=E_{p_\theta(\pi|s)}[(L(\pi)-b(s))\nabla_{\theta} \log p_{\theta}(\pi|s)] ∇θJ(θ∣s)=Epθ(π∣s)[(L(π)−b(s))∇θlogpθ(π∣s)]
与 《Neural Combinatorial Optimization with Reinforcement Learning
》不同的是,
b
(
s
)
b(s)
b(s) 是当前最优模型 + 贪心策略得到的路径长度(greedy rollout)。
为稳定 baseline,每个 epoch 冻结 greedy rollout
当通过 paired t-test ( α = 5 % \alpha=5\% α=5%)时才更新 baseline
当 baseline 更新时,采样新的验证集防止过拟合
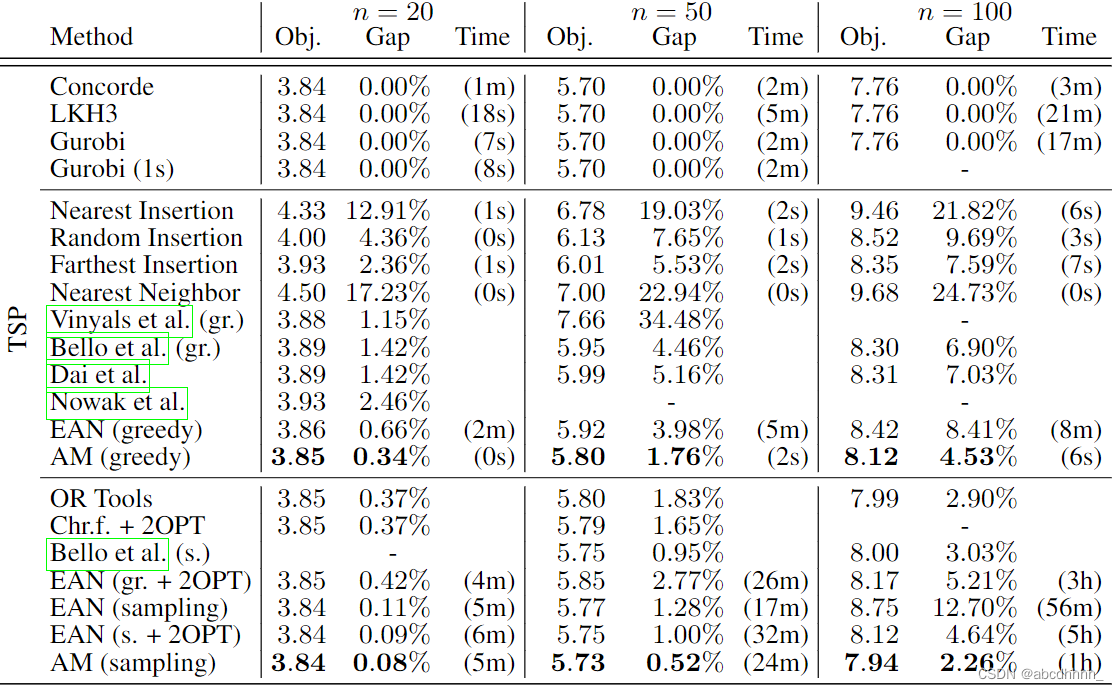
结果如下:
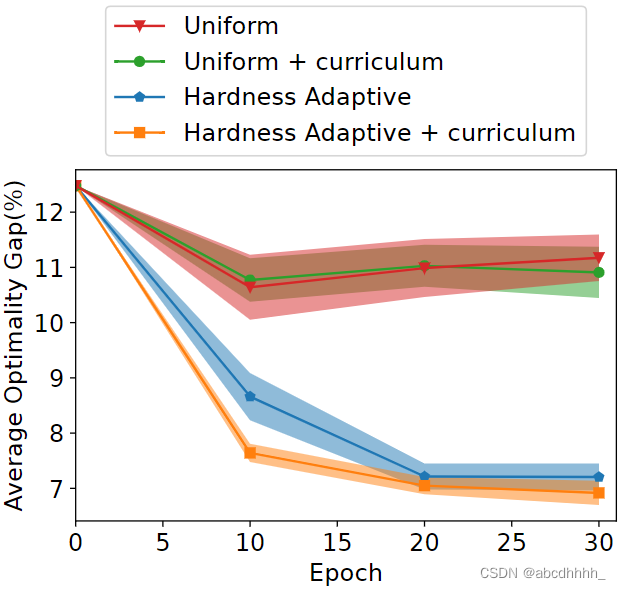
Learning to Solve Travelling Salesman Problem with Hardness-Adaptive Curriculum
若最优解的代价为 C ∗ ( X ) C^*(X) C∗(X) ,策略 M M M 的代价为 C M ( X ) C_M(X) CM(X) ,定义策略 M M M 的最优性差距为
G M ( X ) = C M ( X ) C ∗ ( X ) − 1 G_M(X)=\frac{C_M(X)}{C^*(X)}-1 GM(X)=C∗(X)CM(X)−1
由于 C ∗ ( X ) C^*(X) C∗(X) 不方便求解,令 M ′ M' M′ 为 M M M + 贪心产生的更优策略,定义策略 M M M 的困难度为
H ( X , M ) = C M ( X ) C M ′ ( X ) − 1 H(X,M)=\frac{C_M(X)}{C_{M'}(X)}-1 H(X,M)=CM′(X)CM(X)−1
M M M 与 M ′ M' M′ 代价差距越大, X X X 对 M M M 越困难
生成样本时,利用梯度上升增加样本的困难度(hardness adaptive):
X ( t + 1 ) = ϕ ( X ( t ) + η ∇ X ( t ) H ( X ( t ) , M ) ) X^{(t+1)}=\phi(X^{(t)}+\eta \nabla_{X^{(t)}}H(X^{(t)},M)) X(t+1)=ϕ(X(t)+η∇X(t)H(X(t),M))
其中 ϕ \phi ϕ 为归一化函数,学习率 η \eta η 和步数 T T T 是超参数
∇ X H ( X , M ) = E p M ( π ∣ X ) [ C M ( X ) C M ′ ( X ) ∇ X log p M ( π ∣ x ) + ∇ X C M ( X ) C M ′ ( X ) ] \nabla_XH(X,M)=E_{p_M(\pi|X)}[\frac{C_M(X)}{C_{M'}(X)}\nabla_X\log p_M(\pi|x)+\frac{\nabla_X C_M(X)}{C_{M'}(X)}] ∇XH(X,M)=EpM(π∣X)[CM′(X)CM(X)∇XlogpM(π∣x)+CM′(X)∇XCM(X)]
这里将 C M ′ ( X ) C_{M'}(X) CM′(X) 视为常数
训练也使用 REINFORCE+baseline,但对样本 X i X_i Xi 增加权重 w i = softmax ( F ( H ( M , X ) ) / T ) w_i=\text{softmax}(F(H(M,X))/T) wi=softmax(F(H(M,X))/T)(curriculum)。
这里的 T T T 是“温度”,随训练过程降低,困难的样本越来越重要
F F F 是一个变换
其他细节与 《Attention, Learn to Solve Routing Problems!》 相同
训练效果如下:















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









