






一、环境配置
流程:系统安装—>安装显卡驱动—>安装CUDA—>安装Cudnn—>安装Tensorflow-gpu
其中Tensorflow版本要与CUDA、Cudnn对应,对应关系如下:
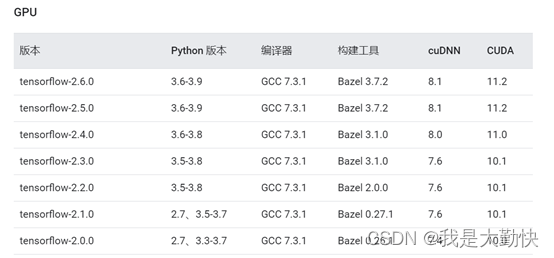
配置环境为:TF2.3(2.1、2.2)—CUDN10.1—Cudnn7.6
(1)系统安装
安装系统版为本Ubuntu 18.04.6 LTS;系统自带python版本python 3.6.9;为系统安装了pip
(2)安装显卡驱动步骤
显卡型号:NVIDIA Quadro RTX4000;使用添加PPA源的安装方式安装显卡驱动
参考链接:Ubuntu18.04系统下最新版GPU环境配置详细教程_思绪无限的博客-CSDN博客
安装驱动版本:470.103.01;最高支持的CUDA版本为11.4;
(3)安装CUDA
根据TF-GPU与CUDA的对应关系,安装CUDA10.1,V10.1.105;
参考链接:
ubuntu18.04安装cuda10.1和对应的cudnn_qq_41549249的博客-CSDN博客_cuda10.1对应的cudnn
(4)安装CUDNN
已安装CUDNN7.6.0
参考链接:Ubuntu18.04系统下最新版GPU环境配置详细教程_思绪无限的博客-CSDN博客
(5)安装Tensorflow-gpu
在虚拟环境中安装tf-gpu2.3.0
参考链接:
Linux中安装TensorFlow教程-Ubuntu18.04安装TensorFlow教程-一步一步完全版!_Lukea11的博客-CSDN博客
安装tensorflow-gpu步骤将命令改为:“pip install tensorflow-gpu == 2.x(1/2/3).0”
激活虚拟环境,终端输入指令:source ./虚拟环境文件夹名称/bin/activate
退出虚拟环境,终端输入指令:deactivate
(6)pycharm中配置python编译器并为pycharm配置编译器
Pycharm默认为项目配置自带的编译器;在设置中为项目配置tensorflow2.3.0的python3.6;终端激活该虚拟环境,项目可以由该编译器运行。
二、运行代码遇到的问题
问题1:Could not load dynamic library 'libcupti.so.10.1'
W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcupti.so.10.1'; dlerror: libcupti.so.10.1: cannot open shared object file: No such file or directory动态连接库问题
(1)找到libcupti.so.10.1 位置:
/usr/local/cuda-10.1/extras/CUPTI/lib64(2)将文件路径添加到LD_LIBRARY_PATH变量
Export LD_LIBRARY_PATH=/usr/local/cuda-10.1/extras/CUPTI/lib64:${LD_LIBRARY_PATH}这种方法不好使
(3)建立文件链接
查看该路径下的文件
ls /usr/lib/x86_64-linux-gnu/libcup*没有libcupti.so.10.1文件,建立文件链接:
sudo ln –s /usr/local/cuda-10.1/extras/CUPTI/lib64/libcupti.so.10.1 /usr/lib/x86_64-linux-gnu/libcupti.so.10.1解决了问题。步骤二、三都是是在终端虚拟环境中进行的操作。
问题2:CUPTI_ERROR_NOT_INITIALIZED
E tensorflow/core/profiler/internal/gpu/cupti_tracer.cc:1408] function cupti_interface _->Subscribe( &subscriber_, ( CUpti_CallbackFunc ) ApiCallback , this)failed with error CUPTI_ERROR_NOT_INITIALIZED问题原因:无法获取GPU权限
(1)官方网站解决方案:(将英文翻译成了汉语)
使用'sudo'或作为具有CAP_SYS_ADMIN功能集的用户启动该工具
GPU性能计数器控制需要 Linux 显示驱动程序 418.43 或更高版本
1.卸载旧模块。在您可以插入带有键设置/取消设置的模块之前,您首先需要停止窗口管理器,
并卸载所有基于nvidia的模块。所以以root身份,或者使用
sudo: systemctl isolate multi-user[1] # 停止窗口管理器。
modprobe -r nvidia_uvm nvidia_drm nvidia_modeset nvidia-vgpu-vfio nvidia[2] #卸载依赖模块
[1] 假设一个基于systemd的分布。对于非基于systemd的发行版,需要不同的过程。
[2] 假设没有进程正在使用这些模块,以便成功卸载。2.指定您想要的访问权限:插入带有设置/未设置注册表项的模块。需要管理权限(CAP_SYS_ADMIN 功能集)才能使用 NVIDIA GPU 性能计数器进行分析
modprobe nvidia NVreg_RestrictProfilingToAdminUsers=1 [1][4][7][8]
[4]这些设置在重新启动后不会保留。
[7]在Ubuntu系统上,通过发行版原生软件包安装时,内核模块从nvidia重命名为 nvidia-xxx,然后nvidia别名为 nvidia-xxx(其中xxx是驱动程序的主编号。所以418.67驱动程序将使用nvidia-418)对于Container/Docker用户:如果'CTRL+F "container" 或 "docker"' 为空,
[8]使用'sudo'或作为用户启动工具的第一个解决方案CAP_SYS_ADMIN功能集应该可以工作。或者,允许任何用户使用NVIDIA GPU性能计数器进行分析
modprobe nvidia NVreg_RestrictProfilingToAdminUsers=0[1]或者,可以将扩展名为.conf,且包含
options nvidia "NVreg_RestrictProfilingToAdminUsers=1"的文件保存到
/etc/modprobe.d [3][5]
[3]可能需要重新启动才能使其生效,但这些设置将保留
[5]在某些系统上(或使用deb安装时),可能需要在将配置文件写入/etc/modprobe.d
后重新构建 initrd[6]
[6]在重新构建initrd时,运行“update -initramfs -u”也是必需的。[2]或者,扩展名为.conf的文件包含
options nvidia "NVreg_RestrictProfilingToAdminUsers=0"可能会保存到
/etc/modprobe.d [3][5]
[3]可能需要重新启动才能使其生效,但这些设置将保留
[5]在某些系统上(或使用deb安装时),可能需要在将配置文件写入/etc/modprobe.d后
重新构建 initrd[6]
[6]在重新构建initrd时,运行“update -initramfs -u”也是必需的。[9] 使用nvidia mod标志的第二种解决方案应该在容器内或容器外工作,并且不需要 Docker 的任何标志。
3.重新启动窗口管理器(如果需要)。
systemctl isolate graphics[1] # 重启窗口管理器。
[1]假设一个基于systemd的分布。对于非基于systemd的发行版,需要不同的过程。4.如果上述步骤不起作用,则可能还需要重新启动系统。另请参阅Linux驱动程序中README.txt的“限制对GPU性能计数器的访问”部分
(2)解决方法:按照官方网站给出的2.[1],在系统的终端进行以下操作
- 在Ubuntu中,需要创建一个文件
/etc/modprobe.d/nvidia-kernel-common.conf文件内容为:
options nvidia "NVreg_RestrictProfilingToAdminUsers=0"即创建文件:
touch /etc/modprobe.d/nvidia-kernel-common.conf提示没有权限,改为:
sudo touch /etc/modprobe.d/nvidia-kernel-common.conf(2)然后编辑文件内容
sudo gedit /etc/modprobe.d/nvidia-kernel-common.conf打开文件后填入文件内容,保存,出现了警告不用管。
(3)运行
sudo update-initramfs -u让上述命令生效。重新启动系统,问题解决。
问题3:Model.fit_generator
Model.fit_generator (from tensorflow.python.keras.engine.training) is deprecated and will be removed in a future version.
Instructions for updating:Please use Model.fit, which supports generators.原因是tf2.x版本弃用Model.fit_generator函数
解决方案:改为Model.fit(),并将第一项参数改为 X = generator
#model.fit_generator(
model.fit(
#generator = train_dataloader,
x = train_dataloader,
steps_per_epoch = epoch_step,
validation_data = val_dataloader,
validation_steps = epoch_step_val,
epochs = end_epoch,
initial_epoch = start_epoch,
use_multiprocessing = True if num_workers > 1 else False,
workers = num_workers,
callbacks = callbacks
)问题4:layout failed: Invalid argument:Subshape must have computed start >= end since stride is negative, but is 0 and 2
E tensorflow/core/grappler/optimizers/meta_optimizer.cc:563] layout failed: Invalid argument: Subshape must have computed start >= end since stride is negative, but is 0 and 2 (computed from start 0 and end 9223372036854775807 over shape with rank 2 and stride-1)在训练的第一个epoch出现了该问题,有博主说该问题不影响正确的检测结果,暂时未解决该问题。。。














 4713
4713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









