







数学建模复习
【1】线性规划问题的MATLAB求解
linprog函数主要用来求线型规划中的最小值问题(最大值的镜像问题,求最大值只需要加个“-”)
函数linprog格式:
[x,fval,exitflag]=linprog(f,A,b,Aeq,beq,lb,ub,x0,options)
左端参数含义:
X表示返回决策向量的取值,
fval表示返回目标的最优解,
exitflag>0表示函数收敛于解x,
exitflag=0表示超过函数估计值或迭代的最大数字,
options为指定优化参数选项。
右端参数含义:
f:目标函数
A:不等式约束条件矩阵
b:对应不等式右侧的矩阵
Aeq:等式约束条件矩阵
beq:不等式右侧的矩阵
Aeq:等式约束条件矩阵
beq:对应等式右侧的矩阵
lb:x的下界
ub:x的上界
x0和options一般用不到
下面记录一段代码【源自课本P20例2】
f=[-2 1 -3 -1 1 0 0];
Aeq=[1 -1 1 1 -4 1 0
-2 -3 -5 0 0 0 0
1 0 -2 2 -2 0 -1];
beq=[7;8;1];
lb=zeros(1,7);
[x,fval]=linprog(-f,[],[],Aeq,beq,lb);#不需要的部分用[]替代
disp(x);
disp(-fval)
运行结果就让人很迷,没有符合条件的值?
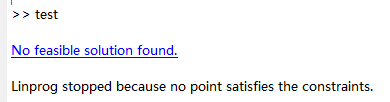
【2】非线性规划模型
1.有约束的一元函数的最小值

函数fminbnd格式:
[x, fval, exitflag, output] = fminbnd('fun',x1,x2,options)
参数说明:
fun为目标函数的表达式字符串或 MATLAB自定义函数炳;
返回自变量x在区间[x1,x2]中
函数fun取最小值时x值;
options为指定优化参数;
fval为目标函数的最小值;
exitflag为终止迭代条件;
output为优化信息;
举个栗子:
计算下面函数在区间(-5,5)内的最小值和函数取最小值时x的值。
f
(
x
)
=
x
3
+
x
2
−
1
e
x
+
e
x
f(x)=\frac{x^{3}+x^{2}-1}{e^{x}+e^{x}}
f(x)=ex+exx3+x2−1
[x,fval,exitflag,output]=fminbnd('(x^3+x^2-1)/exp(x)+ exp(-x)',-5,5)
输出结果:

2.无约束多元函数问题
多元函数最小值的标准形式为 m i n x f ( x ) \underset{x}{min}f(x) xminf(x)其中x为向量,如 x = [ x 1 , x 2 , x 3 , ⋯ , x n ] x=[x_{1},x_{2},x_{3},\cdots,x_{n}] x=[x1,x2,x3,⋯,xn]
函数fminsearch格式:
[x, fval, exitflag, output] = fminsearch('fun', x0, options)
参数说明:
x0为初始点 ,
fun为目标函数的表达式字符串或MATLAB自定义函数炳
options查optimset
fval为最优点的函数值
exitflag与单变量情形一致
output 与单变量情形一致
举个栗子:
求
y
=
s
i
n
x
1
+
c
o
s
2
y=sinx_{1}+cos_{2}
y=sinx1+cos2的最小值点。
第一种方式,在命令行中直接输入下面语句:
X=fminsearch('sin(x(1))+cos(x(2))', [0,0])
输出结果:

第二种方式,先建立函数文件
function f=myfun(x)
f= sin(x(1))+cos(x(2);
在命令行中输入下面任意一个语句调用:
X=fminsearch ('myfun', [0,0])
X=fminsearch(@myfun, [0,0])
3.约束非线性规划问题
fmincon函数格式:
[x,fval,exitflag,output,lambda,grad,hessian] =fmincon('fun',x0,A,b,Aeq,beq,lb,ub,nonlcon,options)
参数说明:
左边:
fun为目标函数;
x0为初始值;
A,b满足线性不等式约束
Aeq,beq满足等式约束
lb,ub为x的下界和上界
nonlcon,options不常用!
若没有参数,则用[]代替占位
右边:
lambda是Lagrange乘子,它体现哪一个约束有效;
output输出优化信息;
grad表示目标函数在x处的梯度;
hessian表示目标函数在x处的黑塞值。
举个栗子:
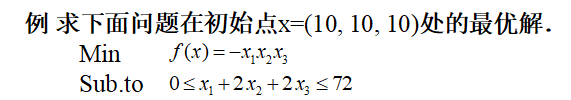
- 先化为标准型:
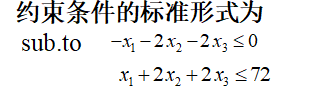
- 编写m文件:
fun= '-x(1)*x(2)*x(3)';
x0=[10,10,10];
A=[-1 -2 -2;1 2 2];
b=[0;72];
[x,fval]=fmincon(fun,x0,A,b)
- 输出结果:

【3】多目标规划matlab求解
函数fgoalattain格式[x,fval,attainfactor,exitflag,output,lambda] =
fgoalattain('fun',x0,goal,weight,A,b,Aeq,beq,lb,ub,nonlcon,options)
参数说明:
x0为初始解向量;
fun为多目标函数的文件名字符串,其定义方式与之前fun的定义方式相同;
goal为用户设计的目标函数值向量;
weight为权值系数向量,用于控制目标函数与用户自定义目标值的接近程度;
C=… %计算x处的非线性不等约束的函数值;
Ceq=… %计算x处的非线性等式约束的函数值;
options为指定的优化参数;
fval为多目标函数在x处的值;
attainfactor为解x处的目标规划因子;
exitflag为终止迭代的条件;
output为输出的优化信息;
lambda为解x处的lagrange乘子。
举个栗子:

M函数文件:
function f=fun(x)
f(1)=15.4*x(1)+13.0*x(2)+13.6*x(3)+20.6*x(4);
f(2)=-(36.4*x(1)+43.1*x(2)+41.2*x(3)+28.2*x(4));
f(3)=2.75*x(1)+2.32*x(2)+2.42*x(3)+3.68*x(4);
f(4)=2.20*x(1)+1.80*x(2)+1.20*x(3)+9.60*x(4);
测试文件调用函数:
clear;clc;
x0=[0 0 0 0];%x的初值
goal=[1 1 1 1]; %目标值
weight=[1 1 1 1]; %权重值
A=[-1 0 0 0;0 -1 0 0; 0 0 -1 0;0 0 0 -1]; %xi>0 (i=1,2,3,4) 化成标准形xi<=0
B=[0;0;0;0];
Aeq=[1 1 1 1]; %∑xi=1;
Beq=1;
[X,FVAL,ATTAINFACTOR,EXITFLAG]=fgoalattain(@fun,x0,goal,weight,A,B,Aeq,Beq)
输出结果:

【4】0-1规划的matlab求解
#intlinprog是matlab中用于求解混合整数线性规划函数,用法基本和linprog差不多
函数intlinprog格式:
[x,fval,exitflag,output]=linprog(f,intcon,A,b,Aeq,beq,lb,ub,x0,options)
参数说明:
f :目标函数的系数矩阵
intcon :整数所在位置
A :不等式约束的变量系数矩阵
b :不等式约束的资源数
Aeq :等式约束的变量系数矩阵
beq :等式约束的资源数
lb :变量约束下限
ub :变量约束上限
x0,options不常用!
举个栗子:
求解
m
i
n
z
=
7
x
1
+
5
x
2
+
9
x
3
+
6
x
4
+
3
x
5
min\quad z=7x_{1}+5x_{2}+9x_{3}+6x_{4}+3x_{5}
minz=7x1+5x2+9x3+6x4+3x5
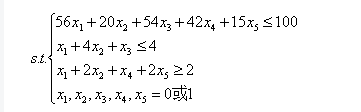
该问题是个0-1规划问题,加上限制条件即可,代码如下:
f = [7 5 9 6 3];
ic = [1,2,3,4,5];
A = [56,20,54,42,15;1,4,1,0,0;-1,-2,0,-1,-2];
b = [100;4;-2];
lb = zeros(5,1); % 生成5×1的 0 矩阵
ub = ones(5,1); % 生成5×1的 1 矩阵
[x,fval]=intlinprog(f,ic,A,b,[],[],lb,ub)
输出结果:

综合应用
某学校规定,运筹学专业的学生毕业时必须至少学习过两门数学课三门运筹学课和两门计算机课.这些课程的编号名称、学分、 所属类别和先修课要求如下表所示. 那么毕业时学生最少可以学习这些课程中的哪些课程 ? 如果某个学生既希望选修课程的数少,又希望所获得的学分多,他可以选修哪些课程?

模型的建立与求解:

 则除了目标(1)之外,还应根据表2中的学分要求写出另一个目标函数
则除了目标(1)之外,还应根据表2中的学分要求写出另一个目标函数
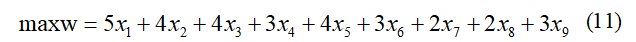
要得到多目标规划问题的解,通常需要知道决策者对每个目标的重视程度,称为偏好程度。
- 同学甲只考虑获得尽可能多的学分,而不管所修课程的多少,那么他可以以 (11) 为目标,不用考虑(1) , 这就变成了一个单目标优化问题显然,这个问题不必计算就知道最优解是选修所有 9 门课程 .
- 同学乙认为选修课程数最少是基本的前提,那么他可以只考虑目标 (1) 而不管(11)。这就是前面得到的,最少为 6 门如果这个解是惟一的,则他已别无选择,只能选修上面的 6 门课,总学分为 21 . 但他还可能在选修6门课的条件下,使总学分多于21.为探索这种可能,应在上面的规划问题中增加约束(12)

将乙同学得到的模型输入MATLAB求解:
f=[-5,-4,-4,-3,-4,-3,-2,-2,-3];
a=[-1,-1,-1,-1,-1,0,0,0,0;0,0,-1,0,-1,-1,0,-1,-1;0,0,0,-1,0,-1,-1,0,-1;-1,-1,2,0,0,0,0,0,0;0,0,0,1,0,0,-1,0,0;-1,-1,0,0,2,0,0,0,0;0,0,0,0,0,1,-1,0,0;0,0,0,0,-1,0,0,1,0;-1,-1,0,0,0,0,0,0,2];
b=[-2;-3;-2;0;0;0;0;0;0];%由约束条件列出矩阵系数
intcon=1:9;%变量总数
aeq=ones(1,9);%每一课程都可以选,系数全为1
beq=6;%只要求选其中6门课,总数为6
ib=zeros(9,1);%变量范围0、1
ub=ones(9,1);
[x,y]=intlinprog(f,intcon,a,b,aeq,beq,ib,ub);
x=reshape(x,1,9),-y %输出结果
输出结果:

综上,此情况下的最优解
x
1
+
x
2
+
x
3
+
x
5
+
x
7
+
x
9
=
1
x_{1}+x_{2}+x_{3}+x_{5}+x_{7}+x_{9}=1
x1+x2+x3+x5+x7+x9=1,其他变量为0 ,共22个学分。
- 同学丙不像甲、乙那样,只考虑学分最多或以课程最少为前提,而是觉得学分数和课程数这两个目标大致上应该三七开,这时有
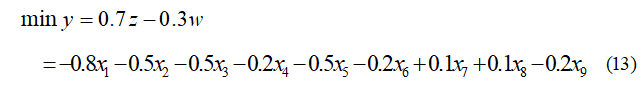
将丙同学得到的模型输入MATLAB求解:
f=[-0.8,-0.5,-0.5,-0.2,-0.5,-0.2,0.1,0.1,-0.2];%对2个目标函数加权后等效为一个目标函数
a=[-1,-1,-1,-1,-1,0,0,0,0;0,0,-1,0,-1,-1,0,-1,-1;0,0,0,-1,0,-1,-1,0,-1;-1,-1,2,0,0,0,0,0,0;0,0,0,1,0,0,-1,0,0;-1,-1,0,0,2,0,0,0,0;0,0,0,0,0,1,-1,0,0;0,0,0,0,-1,0,0,1,0;-1,-1,0,0,0,0,0,0,2];
b=[-2;-3;-2;0;0;0;0;0;0];%约束条件得出矩阵系数
intcon=1:9;%整数变量总数
ib=zeros(9,1);%变量范围
ub=ones(9,1);
[x,y]=intlinprog(f,intcon,a,b,[],[],ib,ub);
x=reshape(x,1,9);
disp(x);
disp(-y*10);
输出结果:

此种情况下的最优解为
x
1
+
x
2
+
x
3
+
x
4
+
x
5
+
x
6
+
x
7
+
x
9
=
1
x_{1}+x_{2}+x_{3}+x_{4}+x_{5}+x_{6}+x_{7}+x_{9}=1
x1+x2+x3+x4+x5+x6+x7+x9=1,只有预测理论不需选修,共28个学分.
【5】主成分分析法
举个栗子
下表是我国 1984—2000 年宏观投资的一些数据,试利用主成分分析对投资效益进行分析和排序
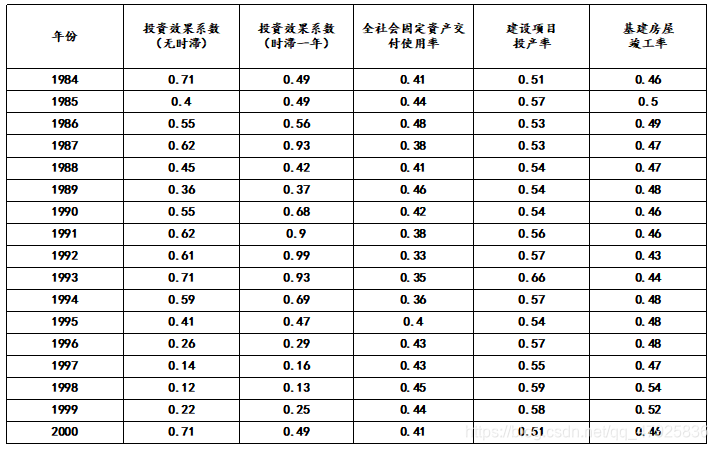
利用Matlab求得相关系数矩阵的前五个特征根及其贡献率如下表所示
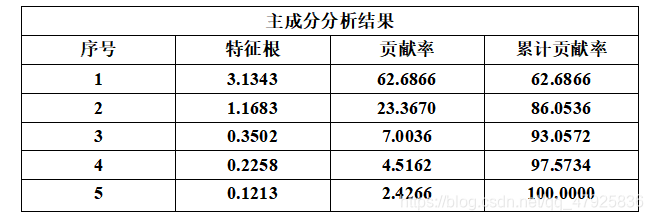
可以看出,前三个特征根的累计贡献率已经达到93%以上,主成分分析效果很好。下面选取前三个主成分进行综合评价,前三个特征根对应的特征向量,如表所示
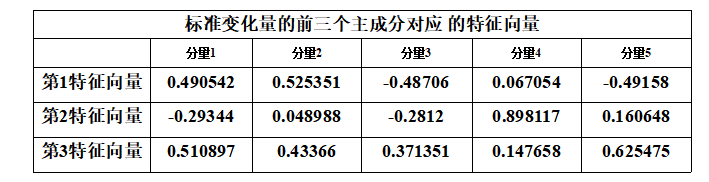
由此可得三个主成分分别为
{
y
1
=
0.491
x
1
+
0.525
x
2
−
0.487
x
3
+
0.067
x
4
−
0.492
x
5
y
2
=
−
0.293
x
1
+
0.049
x
2
−
0.487
x
3
−
0.281
x
4
+
0.161
x
5
y
3
=
0.511
x
1
+
0.434
x
2
+
0.371
x
3
+
0.148
x
4
+
0.625
x
5
\left\{\begin{array}{l}y_{1}=0.491 x_{1}+0.525 x_{2}-0.487 x_{3}+0.067 x_{4}-0.492 x_{5} \\ y_{2}=-0.293 x_{1}+0.049 x_{2}-0.487 x_{3}-0.281 x_{4}+0.161 x_{5} \\ y_{3}=0.511 x_{1}+0.434 x_{2}+0.371 x_{3}+0.148 x_{4}+0.625 x_{5}\end{array}\right.
⎩⎨⎧y1=0.491x1+0.525x2−0.487x3+0.067x4−0.492x5y2=−0.293x1+0.049x2−0.487x3−0.281x4+0.161x5y3=0.511x1+0.434x2+0.371x3+0.148x4+0.625x5
分别以三个主成分的贡献率为权重,构建主成分综合评价模型为
Z
=
0.6269
y
1
+
0.2337
y
2
+
0.076
y
3
Z=0.6269y_{1}+0.2337y_{2}+0.076y_{3}
Z=0.6269y1+0.2337y2+0.076y3
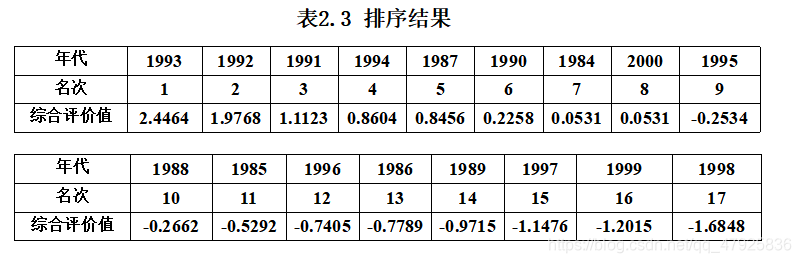
各年度的三个主成分值代入上式,可以得到各年度的综合评价值以及排序结果如表2.3所示.
MATLAB程序如下:
clear;
clc;
close all;
data=importdata('data.csv');%导入数据
X=zscore(data); %标准化数据
R=corrcoef(X);%求相关系数矩阵
[vec,lamba,rate]=pcacov(R); %主成分分析,vec为R特征向量,lamba为R特征值,rate为各个主成分贡献率
vec=vec.*sign(sum(vec));%使特征向量和为正
disp(vec);
contr=cumsum(rate)/sum(rate);%求贡献率,对所有主成分操作
disp(contr');
num=input('Please select the number of principal components:');%交互式选取主成分
df=X*vec(:,1:num);%计算各主成的得分
tf=df*rate(1:num);%计算综合得分
[stf,ind]=sort(tf,'descend');%得分降序排列
disp([ind,stf]);%显示排名得分情况
【6】因子分析法
举个栗子
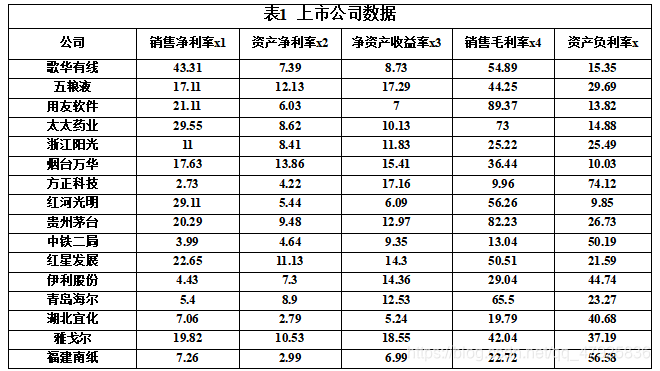
我国上市公司赢利能力与资本结构的实证分析已知上市公司的数据见表1。试用因子分析法对该企业进行综合评价。
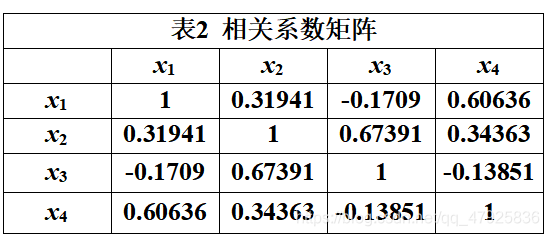
此处不具体展示原始数据标准化处理过程。利用MATLAB软件求得相关系数矩阵,见下表2。
由相关系数矩阵求得特征值及特征向量,见下表3。进而求得初等载荷矩阵
A
1
A_1
A1。
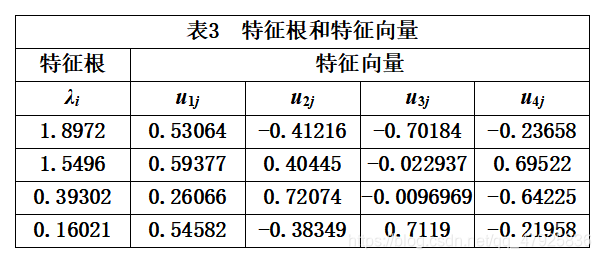
本例中,我们选取2个主因子。利用MATLAB程序对提取的因子载荷矩阵进行旋转,得到旋转后的因子贡献和贡献率见表4、载荷矩阵B见表5。
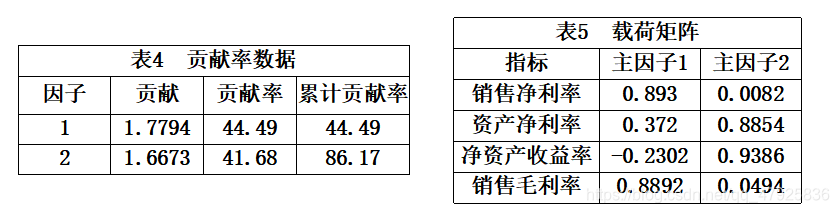
利用回归方法计算各因子得分函数如下:
F
1
=
0.531
x
1
+
0.1615
x
2
−
0.1831
x
3
+
0.5015
x
4
F_{1}=0.531 x_{1}+0.1615 x_{2}-0.1831 x_{3}+0.5015 x_{4}
F1=0.531x1+0.1615x2−0.1831x3+0.5015x4
F
2
=
−
0.045
x
1
+
0.5151
x
2
+
0.581
x
3
−
0.0199
x
4
F_{2}=-0.045 x_{1}+0.5151 x_{2}+0.581 x_{3}-0.0199 x_{4}
F2=−0.045x1+0.5151x2+0.581x3−0.0199x4
利用综合因子得分公式:
F
=
44.49
F
1
+
41.68
F
2
86.17
F=\frac{44.49 F_{1}+41.68 F_{2}}{86.17}
F=86.1744.49F1+41.68F2
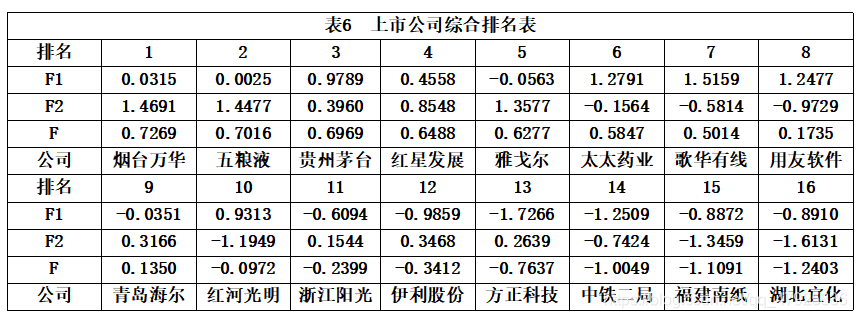
MATLAB程序如下:
data=importdata('data2.csv'); %读取数据
X=zscore(data(:,1:4)); %数据标准化
R=corrcoef(X);%计算相关系数矩阵
disp(R);
[vec,val,con]=pcacov(R); %主成分分析计算
vec=vec.*sign(sum(vec)); %特征向量正负转换
a=vec.*sqrt(val)'; %计算初等载荷矩阵
num=2; %提取两个因子
am=a(:,1:num); %提取主因子载荷矩阵
[b,t]=rotatefactors(am,'Method','varimax');%旋转变换,返回值b是旋转后的载荷矩阵,t是正交矩阵
bt=[b,a(:,num+1:end)];%全部因子的载荷矩阵
disp(bt);
degree=sum(b.^2,2);%计算共同度,对行求和
disp(degree);
contr=sum(bt.^2); %计算因子贡献,对列求和
disp(contr);
rate=contr(1:num)/sum(contr); %计算因子贡献率
disp(rate);
coef=R\b; %计算得分函数的系数
disp(coef);
weight=rate/sum(rate); %计算得分权重
disp(weight);
F1_F2=X*coef; %计算综合得分
disp(F1_F2);
score=F1_F2*weight'; %加权求和
[score,ind]=sort(score,'descend');%排序
disp([ind,score]); %显示排名
【7】聚类常用分析
举个栗子
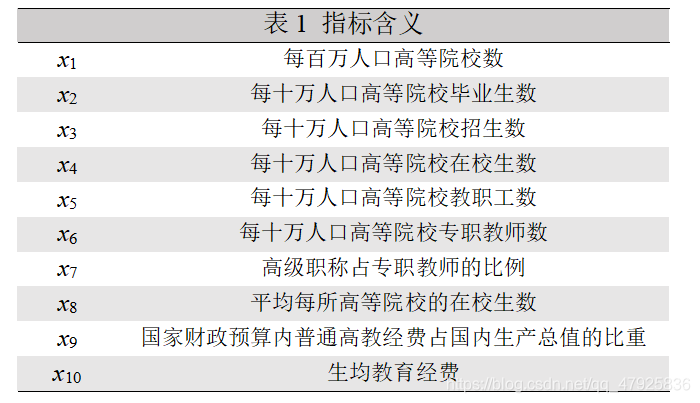
1、我国各地区普通高等教育发展水平综合评价由于我国各地区经济发展水平不均衡, 加之高等院校原有布局使各地区高等教育发展的起点不一致,因而各地区普通高等教育的发展水平存在一定的差异,不同的地区具有不同的特点。请对我国各地区普通高等教育的发展状况进行综合评价。参与评价的十个指标各自含义见表1,指标的原始数据取自《中国统计年鉴, 1995》和《中国教育统计年鉴, 1995》除以各地区相应的人口数得到十项指标值见表 2。
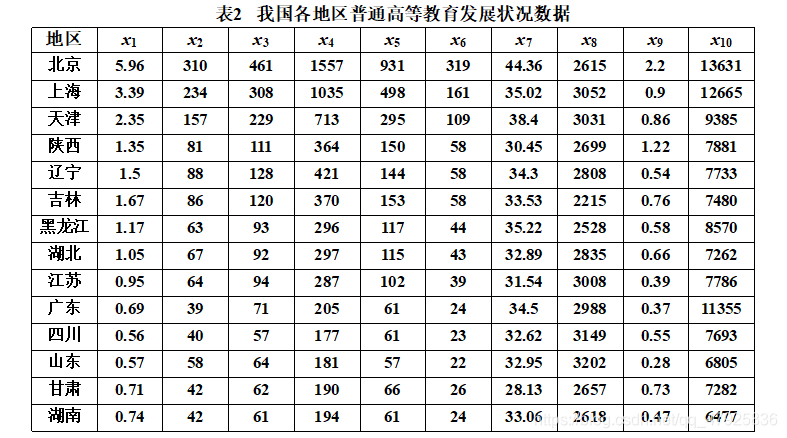
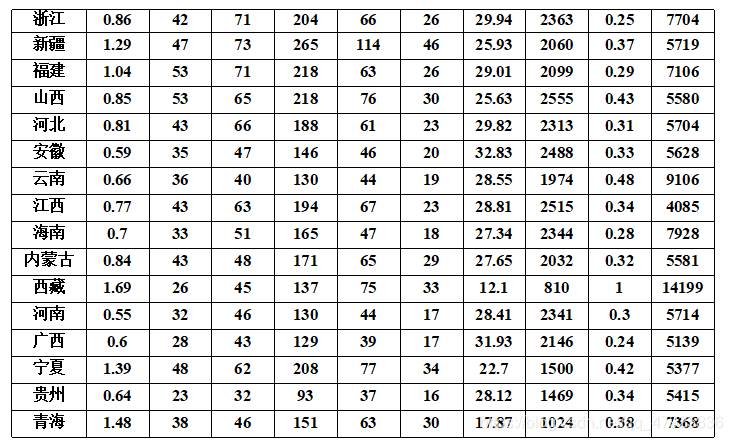
R型聚类分析
定性考察反映高等教育发展状况的5个方面10项评价指标。
可以看出,某些指标可能存在较强的相关性。比如每10万人口高等院校毕业生数、每10万人口高等院校招生数与每10万人口高等院校在校生数之间可能存在较强的相关性,为验证这种想法,运用Matlab软件计算10个指标之间的相关系数,相关系数表如表3所示。

可以看出某些指标之前确实存在很强的相关性,因此可以考虑从这些指标中选取几个有代表性的指标进行聚类分析。为此,把10个指标根据其相关性进行R型聚类,再从每个类中选取代表性的指标。首先对每个变量(指标)的数据分别进行标准化处理。变量间相近性度量采用相关系数,类间相似性度量的计算选用类平均法。聚类树型图如下图所示。
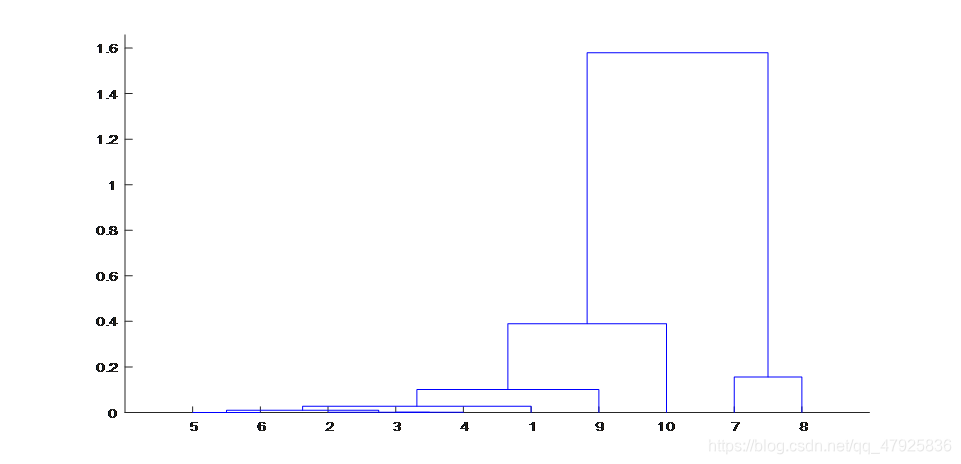
从聚类图中可以看出,每10万人口高等院校招生数、每10万人口高等院校在校生数、每10万人口高等院校教职工数、每10万人口高等院校专职教师数、每10万人口高等院校毕业生数5个指标之间有较大的相关性,最先被聚到一起。如果将10个指标分为6类,其他5个指标各自为一类。这样就从10个指标中选定了6个分析指标。
- x 1 x_{1} x1 为每百万人口高等院校数;
- x 2 x_{2} x2 为每10万人口高等院校毕业生数;
- x 3 x_{3} x3 为高级职称占专职教师比例;
- x 4 x_{4} x4 为平均每所高等院校的在校生数;
- x 5 x_{5} x5 为国家财政预算内普通高等教育经费占国内生产总值的比例;
- x 6 x_{6} x6 为生均教育经费。
可以根据这6个指标对30个地区进行聚类分析。
MATLAB程序如下:
data=importdata('data3.csv');
d=pdist(data,'correlation'); %计算相关系数导出的距离
z=linkage(d,'average'); %产生聚类等级树
[h,t]=dendrogram(z); %画聚类图
num=input('Enter the number of categories:');
T=cluster(z,'maxclust',num); %把对象划分为num类
%%%%%%%%%%输出分类%%%%%%%%%%
for i=1:num
t=find(T==i);
t=reshape(t,1,length(t));
fprintf('Class %d contains:%s\n',i,int2str(t));
end
Q型聚类分析
根据这6个指标对30个地区进行聚类分析。首先对每个变量的数据分别进行标准化处理,样本间相似性采用欧氏距离度量,类间距离的计算选用类平均法。聚类树型图如图5所示。
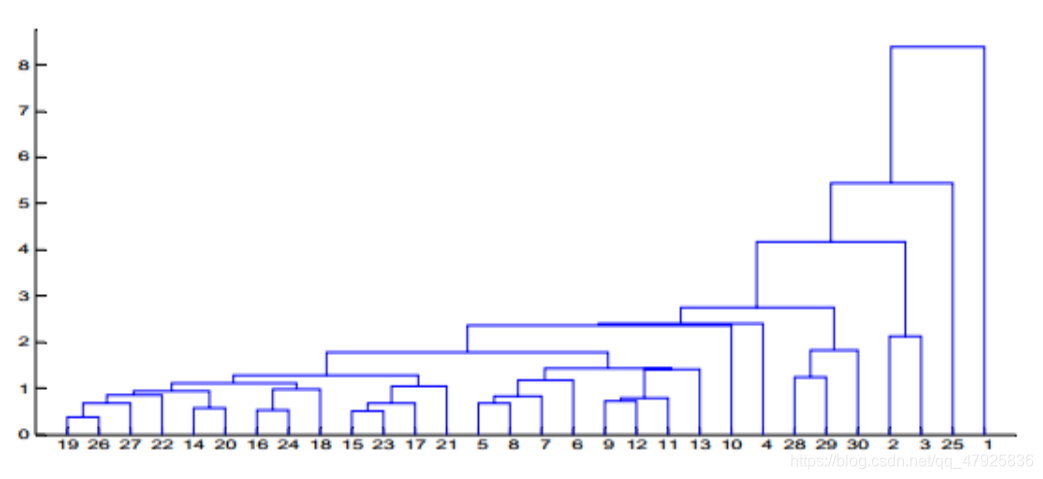
MATLAB程序如下:
clc,clear
a=importdata('data3.csv');
b=zscore(a);%标准化数据
d=pdist(b);%计算两两之间的欧氏距离
z=linkage(d);%生成具有层次结构的聚类图
dendrogram(z);%画聚类图
k=input('Enter the number of categories:');
T=cluster(z,'maxclust',k);%把对象划分为k类
%%%%%%%%%%输出分类%%%%%%%%%%
for i=1:k
t=find(T==i);
t=reshape(t,1,length(t));
fprintf('Class %d contains:%s\n',i,int2str(t));
end
k_均值聚类分析方法
例题
2、已知有20个样本,每个样本有两个特征,数据分布如下表所示,试采用k_均值聚类分析方法对这些数据进行分类。
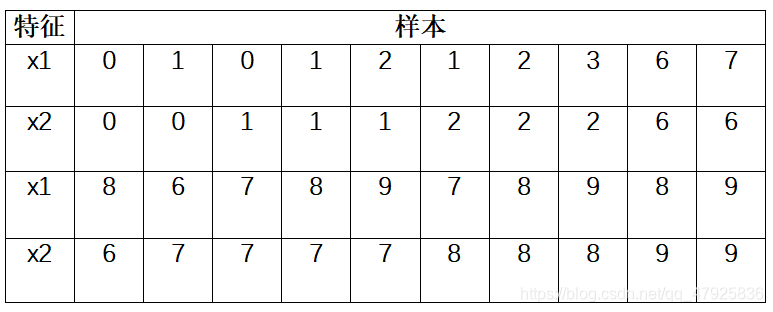
MATLAB程序如下:【代码还有些问题,稍后修改】
X=[0 1 0 1 2 1 2 3 6 7 8 6 7 8 9 7 8 9 8 9
0 0 1 1 1 2 2 2 6 6 6 7 7 7 7 8 8 8 9 9]';
figure;%绘制数据点分布图
plot(X(:,1),X(:,2),'.');
xlabel('X1');ylabel('X2');
opts = statset('Display','final');
K=input('Please enter the number of clusters K:');%根据数据点分布图判断分类数目
[idx,C] = kmeans(X,K,'Distance','cityblock', 'Replicates',10,'Options',opts);
[idx,C] = kmeans(X,K,'Distance','cityblock', ...
'Replicates',10,'Options',opts);
%X为样本,K为聚类数目,'Distance','cityblock'表示使用绝对误差和作为测量距离,
%'Replicates',10表示迭代重复次数为10,'Options',opts表示迭代算法最小化拟合准则
figure;
plot(X(idx==1,1),X(idx==1,2),'r.','MarkerSize',12)
%绘制第一类样本坐标点
hold on
plot(X(idx==2,1),X(idx==2,2),'b.','MarkerSize',12)
%绘制第二类样本坐标点
xlabel('X1');
ylabel('X2');
plot(C(:,1),C(:,2),'kx',...
'MarkerSize',15,'LineWidth',3)%绘制聚类中心
legend('Cluster 1','Cluster 2','Centroids',... 'Location','NW')
title 'Cluster Assignments and Centroids'%添加标题
hold off
%%%%%%%%%%输出分类%%%%%%%%%%
for i=1:K
t=find(idx==i);
t=reshape(t,1,length(t));
fprintf('Class %d contains:%s\n',i,int2str(t));
end
【8】匈牙利算法
定理2 将系数矩阵 C = ( C i j ) C=(C_{ij}) C=(Cij) 中的第i行中的每一个元素都减去常数 p i p_{i} pi,第j列中的每一个元素都减去常数 q j q_{j} qj得到一个新矩阵 ( b i j ) (b_{ij}) (bij) ,若 b i j ≥ 0 b_{ij}\geq0 bij≥0 且 ( b i j ) (b_{ij}) (bij) 中有n个不同行不同列的零元素,则以 ( b i j ) (b_{ij}) (bij)为系数矩阵的指派问题的最优解为 ( x ˉ i j ) (\bar{x}_{ij}) (xˉij),原指派问题的最优解也为 ( x ˉ i j ) (\bar{x}_{ij}) (xˉij)















 2636
2636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











