







这总结与彭东老师的《操作系统45讲》,强烈推荐去看
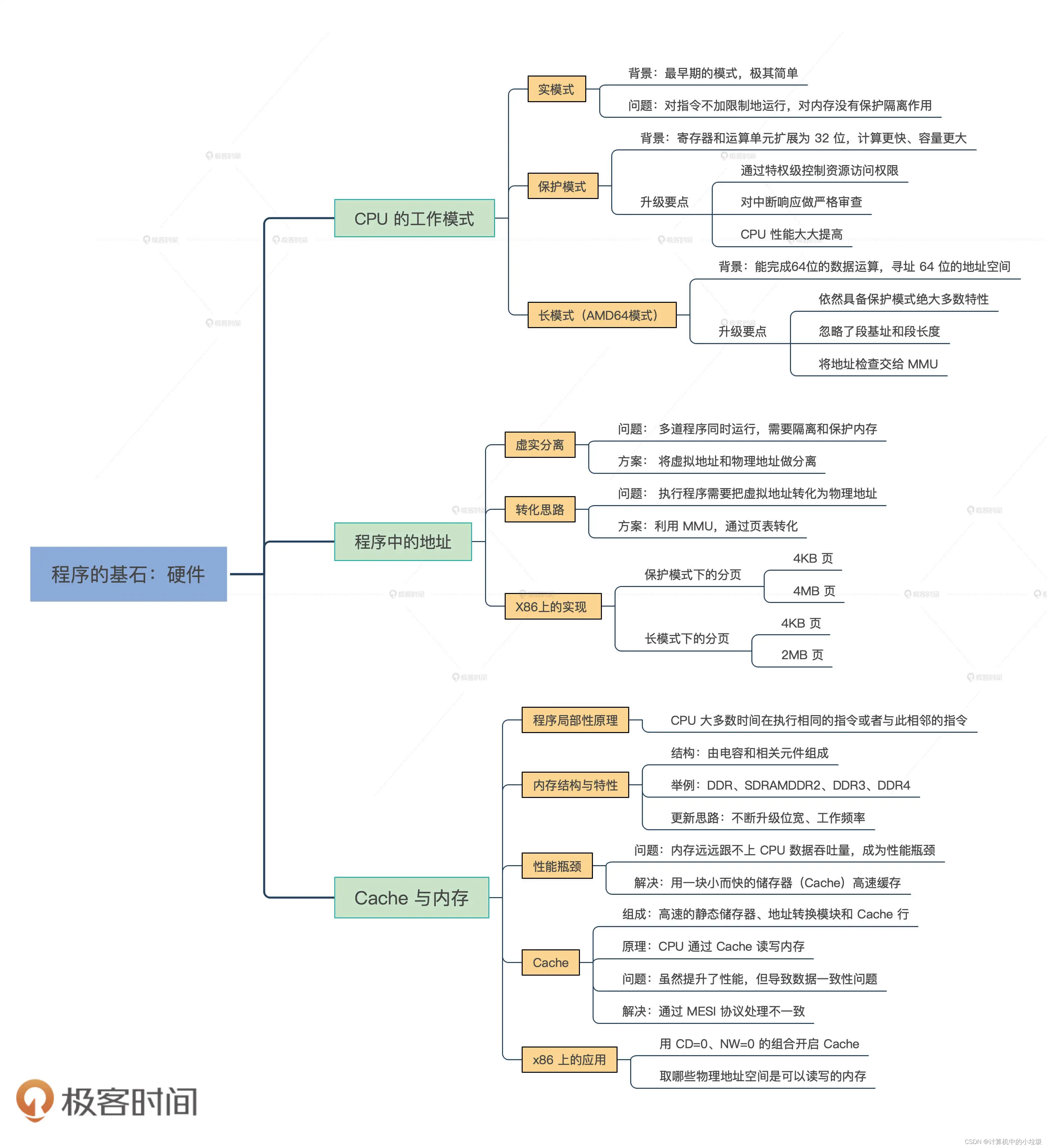
1,Cpu的工作的三种模式
自从cpu迭代而来,产生了三种模式,
- 实模式
- 保护模式
- 长模式
1、x86 CPU的位数越来越高,从16到32到64,每次进步都尽量的去兼容了
之前的CPU架构,所以:
A、16位时寻址能力不足,所以要借助额外的寄存器进行1M空间的寻 址;32位时,
每个程序都有自己独立的4G寻址空间,操作系统用低位的1G-2G,其余留给用户程
序;64位后,暂时就遇不到寻址能力不足的事情了;
B、前一代的寄存器尽量保留,不够用就扩展新的
C、寄存器的长度升级后,其低位可以兼容上一代的寄存器
2、CPU同时在安全性上也要提升,从只有实模式【可以随意执行全部CPU指令,内存可以直接通过物理地址访问,随意访问随意读写】,到了32的保护模式【将指令划分为ring0到ring3,CPU指令不是你想调用就能调用;内存不是你想访问就能访问,首先CPU要允许,而且操作系统允许】,而64的长模式在安全方面与32并没有本至区别;
3、从实模式到保护模式,访问内存时,需要访问的地址变大了,需要控制的内容变多了,于是引入了段描述符,所有的段描述符组成了描述符表,包括唯一的全局描述符GDT和多个局部描述符号LDT。GDT是操作系统特供,要重点关注。CPU寻址的时候,要通过段寄存器+GDTR寄存器定位到的内存中的描述符,判断是否允许访问。然后,再根据段描述符中地址进行访问。
4、同时内存中内存管理有段、页、段页三种常用模式。一般在应用层,程序员感受不太到,操作系统全给咱们做完了。
5、中断,其实是通过硬件或软件方式告诉CPU,来执行一段特殊的代码。比如咱们键盘输入,就是通过硬件中断的方式,告知操作系统的。在实模式下,中断是直接执行的。但到了保护模式和长模式下,就要特权级别校验通过才能执行,所以引入了中断门进行控制。在ring3调用中断一般是要通过操作系统切换到内核态ring0进行的,与内存类似,要通过中断向量表,确认中断门中权限是否允许,然后定位到指定代码执行。
6、BIOS引导后,系统直接进入最简单、特权最大的实模式;而后告知CPU,切换到保护模式,并运行在ring0。后续的用户进程,一般就在ring3,想执行特权指令要通过操作系统来执行。
2,虚拟地址和物理地址的转换
每一个进程都会有一个属于自己的虚拟地址。而真正执行的又是需要物理地址,而这两者转换时依靠MMU来执行的。

为什么需要虚拟地址:
实模式中如果运行多道程序有一些问题需要解决:
地址冲突
控制互相访问
代码占用的空间大到物理内存放不下怎么办
不同计算机的容量各不相同,方案如何全部支持
给每个程序一个私有的连续的独立的虚拟的地址空间,和计算机无关,和其它程序无关.
解决思路:
将虚拟地址与物理地址分离,让应用程序从实际的物理内存中解耦出来,增加中间层
MMU去做地址转换,对程序透明.
MMU:
设计思路:
虚拟地址到物理地址直接做映射,则映射关系大到无法接收,维护成本太高.
虚拟段基址映射到物理段基址,看似可以,但是段长度各不相同,并且粒度可能会很大.
因此把虚拟地址和物理地址空间都分成同等大小的块,按照虚拟页和物理页进行映射
和转换,地址转换表中存放虚拟页地址对应的物理页地址即可.
实现思路:
纯硬件实现没有灵活性,用软件实现太低效,因此使用软硬件结合的方式.
用硬件电路逻辑实现地址转换器件,接受虚拟地址和地址关系转换表,输出物理地址.
为什么需要多级页表:
每个进程都有自己的页表,多级页表可以省掉大量未映射页表占用的空间,为null则说明
后面的页都没有使用.
虚拟地址由虚拟页号和虚拟页号偏移组成,多级页表查找时可以使用索引.
cache和内存的关系

为了弥补cpu和内存之间巨大的速度差异,就引入了内存。内存分为三级
- 一级时有两个cache,分别是指令和数据,大小是16kb
- 二级cache不拆分,,但是每个cpu享用一个单独的cache
- 三级cache是多个cpu所共享的。
局部性原理
CPU 大多数时间在访问相同或者与此相邻的地址,执行相同的指令或者与此
相邻的指令。这种现象就是程序局部性原理。
cache的组成
Cache 主要由高速的静态储存器、地址转换模块和 Cache 行替换模块组成。
cache引发的一致性失误的解决办法
Cache一致性协议 MESI。这个协议由 Cache 硬件执行,对软件透明。
MESI分别代表了高速缓存行的四种状态:
最开始只有一个核读取了A数据,此时状态为E独占,数据是干净的,
后来另一个核又读取了A数据,此时状态为S共享,数据还是干净的,
接着其中一个核修改了数据A,此时会向其他核广播数据已被修改,让其他核的
数据状态变为I失效,而本核的数据还没回写内存,状态则变为M已修改,等待
后续刷新缓存后,数据变回E独占,其他核由于数据已失效,读数据A时需要重
新从内存读到高速缓存,此时数据又共享了
三节课的脑图















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









