







(1)使用pd.read_csv()读csv文件时,出现如下错误:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x82 in position 743: invalid start byte
错误原因:文件不是 UTF8 编码的,而系统默认采用 UTF8 解码。
解决方法是改为对应的解码方式。可以直接打开CSV文件,另存为UTF-8格式。
原文链接:https://blog.csdn.net/Andy_shenzl/article/details/90443299

import pandas as pd
import numpy as np
# 导入数据
data = pd.read_csv(r"F:/Python file/lrdata.csv")
data.head()
# 分析数据
print(type(data))
data_array = np.array(data)
print(type(data_array))
print(data_array)
x = data.loc[:,'x']
y = data.loc[:,'y']
print(x)
print(y)
print(type(x))
c = data.loc[:,'x'][y>6]
data_new = data + 10
print(data_new)
data_new.to_csv('data_new.csv')
# 建立线性回归模型
import sklearn
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()
# 处理x 转换为array 二维
x = np.array(x)
x = x.reshape(-1,1)
print(x.shape,type(x))
print(x)
# 处理y 转换为array 二维
y= np.array(y)
y = y.reshape(-1,1)
print(y.shape,type(y))
print(y)
# 进行模型训练,x,y都要是二维的数据
lr_model.fit(x,y)
# 模型拟合完之后,进行预测
y_predict = lr_model.predict(x)
print('\n y_predict')
print(y_predict)
# 可视化拟合效果 比较预测值和实际值的偏差
from matplotlib import pyplot as plt
fig = plt.figure(figsize = (3,3))
plt.scatter(x,y,color='r',label='x-y') #实际值线,或画成散点,用plt.scatter(x,y)
plt.plot(x,y_predict,label='x-y_predict') #预测值线
plt.title('show the x vs y')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.show()由图示可以发现原数据(红点标记)和预测直线函数(蓝色直线)是有很大误差的,只有第一个点差不多。
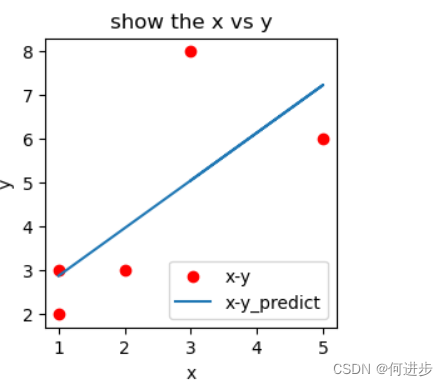
输出原数据x=3时,y和y_predict的值进行对比,发现有误差



链接:https://pan.baidu.com/s/19y5Ve2g7G3ZA45bwBeqLxw?pwd=hhhh
提取码:hhhh















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









