







 文章探讨了如何通过将结构化输出转化为代码形式,利用代码LLM如Codex执行信息提取任务。实验表明,代码提示的CodeLLM在NER和RE任务中优于传统模型,尤其是在few-shot学习情况下。编码结构的目标使得输出更精确,展示了代码表示在IE任务中的优势。
文章探讨了如何通过将结构化输出转化为代码形式,利用代码LLM如Codex执行信息提取任务。实验表明,代码提示的CodeLLM在NER和RE任务中优于传统模型,尤其是在few-shot学习情况下。编码结构的目标使得输出更精确,展示了代码表示在IE任务中的优势。
INTRODUCTION
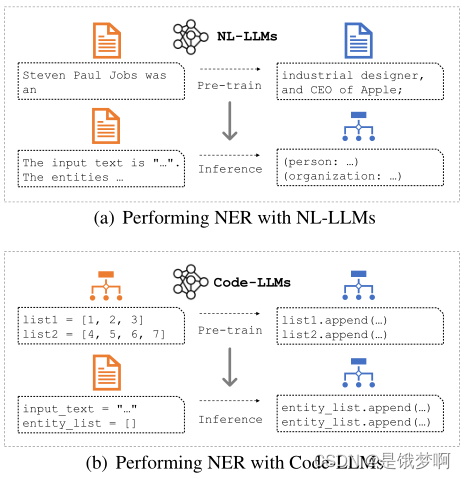
在本文提出将结构化输出转换为代码而不是自然语言的形式,并利用代码的生成法学硕士(code -LLMs),如Codex来执行IE任。与nl - llm相比,我们展示了代码- llm可以通过设计代码样式提示并将这些IE任务制定为代码生成任务来与这些IE任务很好地对齐。
以下图中的示例输入“Steve在1998年成为Apple的CEO”为例,我们将其包装成一段Python代码,并将结构化实体输出制定为带有键“text”和“type”的Python字典。我们将它们组合成一个Python函数,该函数在语义上等同于NER示例:

文中在NER和RE任务的七个基准上进行了实验,并仔细分析了我们的方法(称为CODEIE)的好处。研究结果如下:
1)具有代码样式输入的提示code- llm(Codex) 始终优于微调UIE,这是一种针对IE任务的特别预训练模型,并且在少量设置下提示nl - llm(GPT-3)。
2)对于相同的LLM(无论是NL-LLM还是CodeLLM),代码风格的提示符比线性化的文本提示符表现得更好,展示了用代码表示结构化目标的优势。
3)在相同的提示符(自然语言或代码)下,Code - LLM(即Codex)比NL-LLM(即GPT-3)实现了更好的性能,证明了使用code - llm执行IE任务的优点。
4)与自然语言提示相比,使用代码样式的提示对输出结构的保真度更高,即输出的结构错误率更低
下图总结了IE任务中等规模模型、nl - llm和code - llm之间的层次差异。
CODEIE
Task Formulation
给定一个输入句子x,其中有l个标记,
, . . . ,
, IE任务是从x预测结构化目标y。
NER的目标y是一组(e, t)对,其中e是一个实体跨度(如“Steve”),t是对应的实体类型(如“person”)。实体跨度是来自x的令牌序列,实体类型属于预定义的实体类型集T。
RE的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











