







文章目录
1.extend()函数
The extend() method adds all the elements of an iterable (list, tuple, string etc.) to the end of the list.
# create a list
prime_numbers = [2, 3, 5]
# create another list
numbers = [1, 4]
# create another string
name = "zsq"
# create another tuple
age = (22,24)
# add all elements of prime_numbers to numbers
numbers.extend(prime_numbers)
numbers.extend(name)
numbers.extend(age)
print('List after extend():', numbers)
# List after extend(): [1, 4, 2, 3, 5, 'z', 's', 'q', 22, 24]
2.*list
prime_numbers = [2, 3, 5]
print(*prime_numbers)
2 3 5
3.getattr() 函数
作用:返回一个对象属性值。
getattr 语法:
getattr(object, name[, default])
[, default]意思是方框中内容可有可无
如果有name属性,则放回属性值,否则给name属性值赋值defalut。
参数:
object – 对象。
name – 字符串,对象属性。
default – 默认返回值,如果不提供该参数,在没有对应属性时,将触发 AttributeError。
例子:
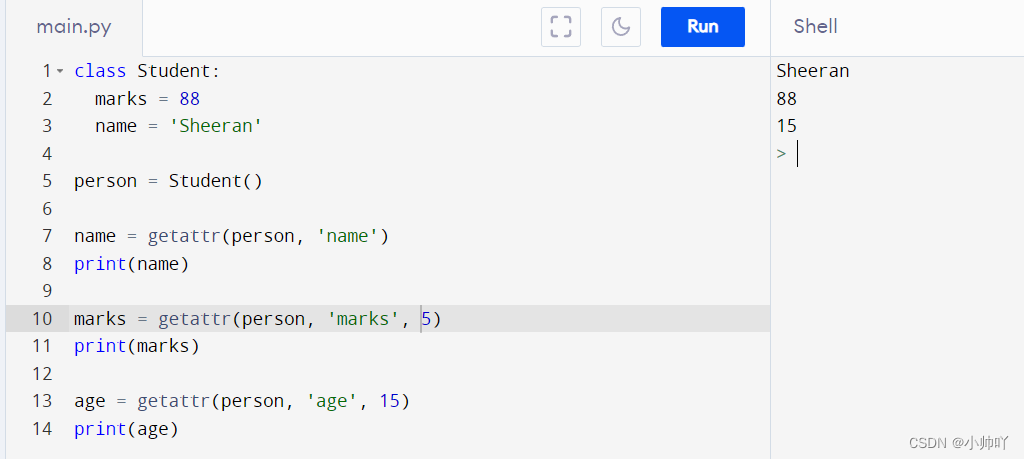
class Student:
marks = 88
name = 'Sheeran'
person = Student()
name = getattr(person, 'name')
print(name)
marks = getattr(person, 'marks', 5)
print(marks)
age = getattr(person, 'age', 15)
print(age)
output:
Sheeran
88
15
4.pandas.DataFrame.agg
import pandas as pd
import numpy as np
df = pd.DataFrame([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[np.nan, np.nan, np.nan]],
columns=['A', 'B', 'C'])
print(df)
print("**************")
print(df.agg(['sum', 'min']))
print("**************")
print(df.agg({'A' : ['sum', 'min'], 'B' : ['min', 'max']}))
print("**************")
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.agg.html
5.pandas.DataFrame.merge
# Online Python compiler (interpreter) to run Python online.
# Write Python 3 code in this online editor and run it.
# how代表合并的方式,on代表索引的列,默认为None
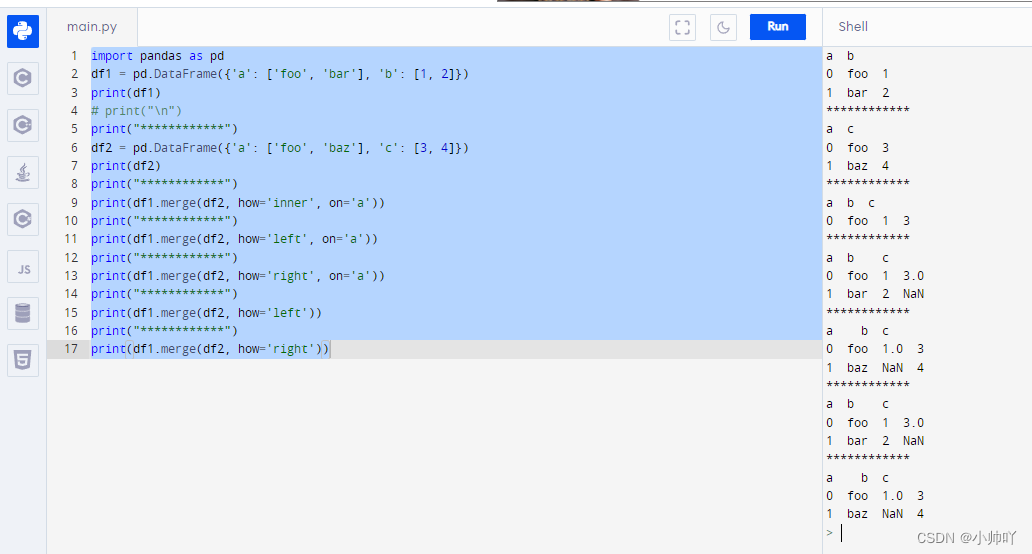
import pandas as pd
df1 = pd.DataFrame({'a': ['foo', 'bar'], 'b': [1, 2]})
print(df1)
# print("\n")
print("************")
df2 = pd.DataFrame({'a': ['foo', 'baz'], 'c': [3, 4]})
print(df2)
print("************")
print(df1.merge(df2, how='inner', on='a'))
print("************")
print(df1.merge(df2, how='left', on='a'))
print("************")
print(df1.merge(df2, how='right', on='a'))
print("************")
print(df1.merge(df2, how='left'))
print("************")
print(df1.merge(df2, how='right'))
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.merge.html
6.pandas.DataFrame.duplicated
判断重复
DataFrame.duplicated(subset=None, keep='first')
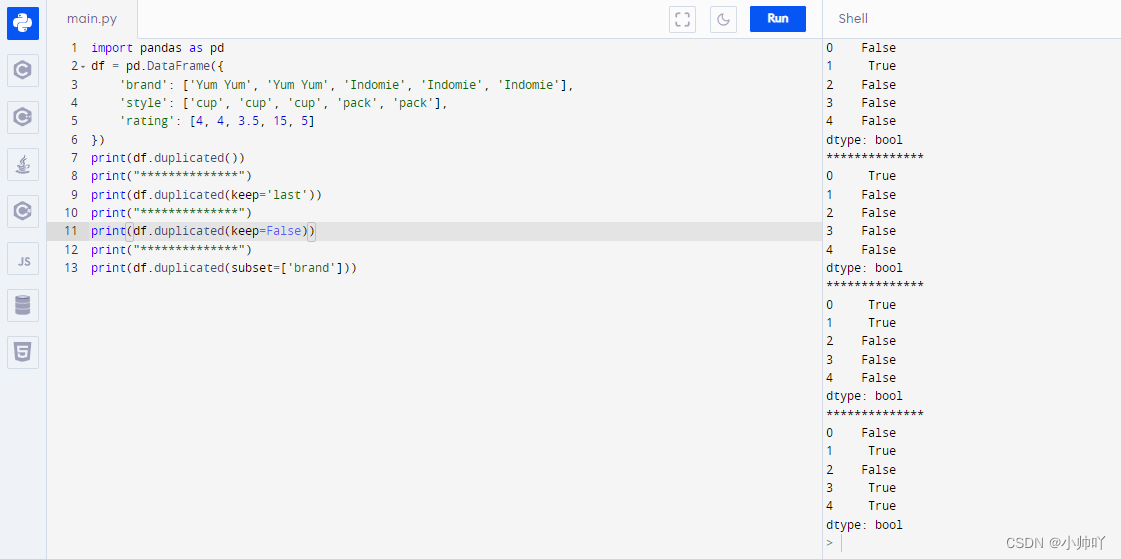
import pandas as pd
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
print(df.duplicated())
print("**************")
print(df.duplicated(keep='last'))
print("**************")
print(df.duplicated(keep=False))
print("**************")
print(df.duplicated(subset=['brand']))
6.pandas中的dropna函数
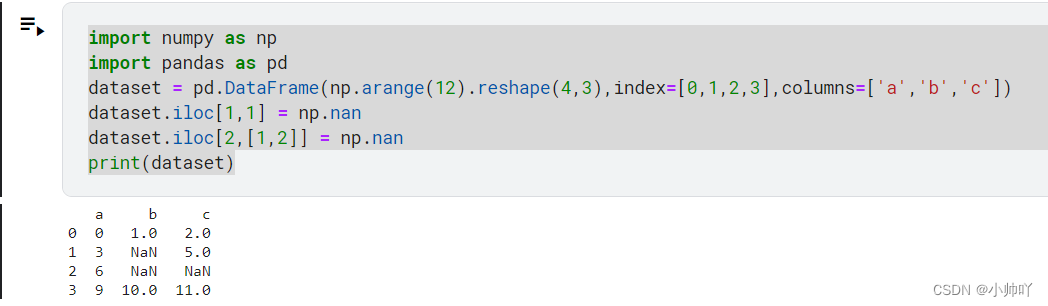
import numpy as np
import pandas as pd
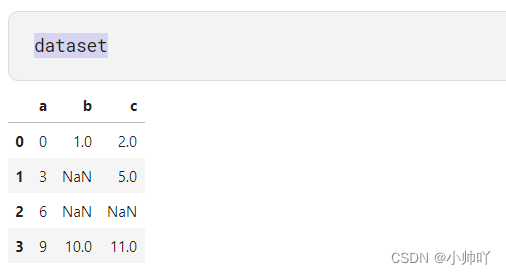
dataset = pd.DataFrame(np.arange(12).reshape(4,3),index=[0,1,2,3],columns=['a','b','c'])
dataset.iloc[1,1] = np.nan
dataset.iloc[2,[1,2]] = np.nan
print(dataset)
dataset.dropna()
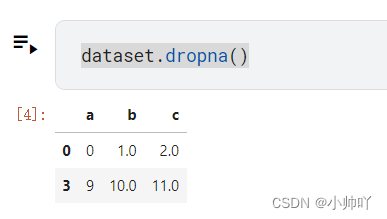
dataset.dropna(axis=0)
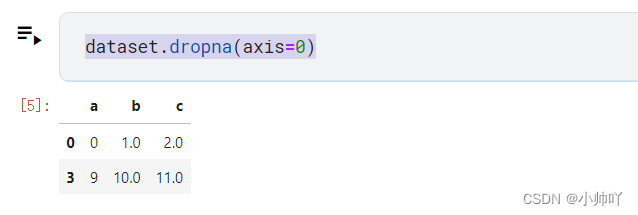
dataset.dropna(axis=1)

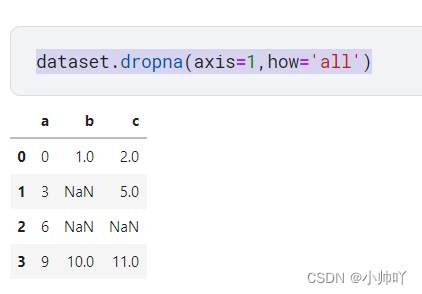
dataset.dropna(axis=1,how='all')
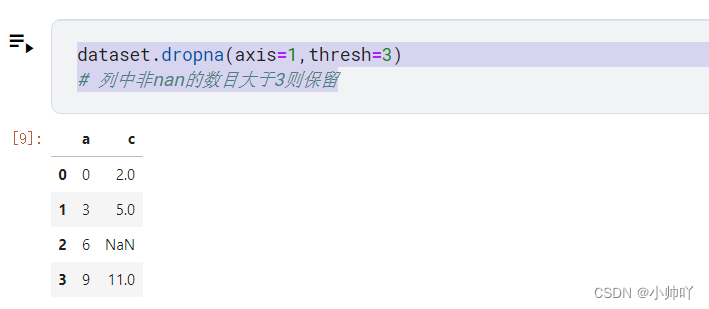
dataset.dropna(axis=1,thresh=3)
# 列中非nan的数目大于3则保留
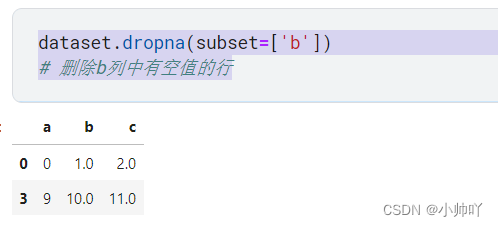
dataset.dropna(subset=['b'])
# 删除b列中有空值的行
dataset
dataset.dropna(subset=['b'],inplace=True)
dataset

统计哪些列有缺失值
cols_with_missing = [col for col in X_train.columns
if X_train[col].isnull().any()]
# df.isnull().any()则会判断哪些”列”存在缺失值















 1112
1112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









