







题目来源:《多元统计分析—基于R》(第2版) 费宇
目的:分析两向量组的相关性。
做法:用CCA,构造两个组别是原始变量的线性组合,该两组别相关程度最大。典型向量对内相关性最 大,向量对与向量对之间不相关。
解题步骤:
①求协方差矩阵并分区R11,R12,R21,R22;
②计算典型相关系数和典型变量;
②计算典型相关变量与原始变量的线性组合表达式;
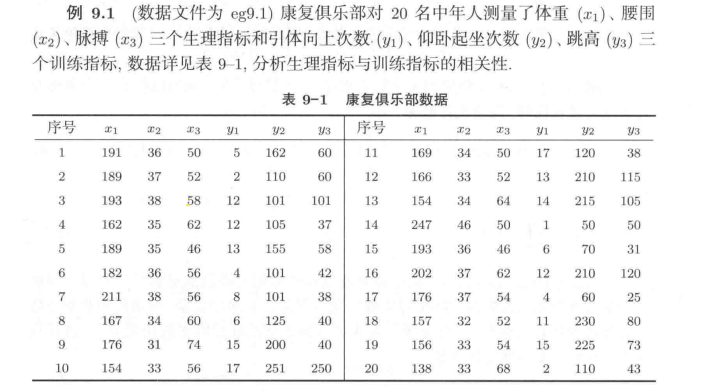
%例题9.1
clc;
clear;
%%计算协方差矩阵
G=eg9;
% G_mean=mean(G); %求每一列均值
% G_std=std(G); %求标准差
% E=(G-repmat(G_mean,20,1))./repmat(G_std,20,1); %规范化后
% Q = cov(E); %求协方差矩阵,由于已规范化,所有也相当于系数矩阵
%数据分组,前3列是生理指标,剩下的训练指标
R = cov(G); %没有规范的,注意!!算协方差矩阵的时候是原变量做的协方差!
[row,col]=size(R);
H=G;
X=H(:,1:3);
Y=H(:,4:col);
R_X=cov(X);
R11=R_X;
R22=cov(Y);
[r1,c1]=size(R11);
[r,c]=size(R);
R12=R(1:r1,c1+1:c);
R21=R12';
%%计算典型相关系数和典型变量
m=rank(R)-rank(R_X); %计算典型相关系数的个数m=3
M1= (inv(R11)) * R12 * inv(R22) * R21;
[v_1,feature_value_1]=eig(M1);
[v1,value1]=sorted(M1,'descend');
D1=value1.^0.5;
A=v1;
M2=inv(R22) * R21 * inv(R11) * R12;
[v_2,feature_value_2]=eig(M2);
[v2,value2]=sorted(M2,'descend');
D2=value2.^0.5; %典型相关系数,跟D1一样
B=v2;
%贡献率
Dg=D1./sum(D1) ; %特征值的贡献度,方差贡献率
Dleiji=cumsum(Dg) ; %累计贡献度
num = 1;
while sum(D1(1:num))/sum(D1) < 0.65 %若累计贡献率小于65%则增加典型变量个数.
num = num +1;
end %num=1,只需要取前1个典型变量U1,V1就行
%%计算典型相关变量与原始变量的线性组合系数U,V
%计算典型变量u的得分
U_score=[];
for i=1:1:3
A1=A(:,i);
u_score=A1'*X';
U_score=[U_score ; u_score]
end
%计算典型变量u得分的标准差
u_std=std(U_score');
%典型变量U与原始变量的线性组合表达式
U=A./u_std
%计算V的得分
V_score=[];
for i=1:1:3
B1=B(:,i); %B的列
v_score=B1'*Y';
V_score=[V_score ; v_score]
end
%计算V的标准差
v_std=std(V_score');
%典型变量v与原始变量的线性组合表达式
V=B./v_std;
%绘制两个典型变量u1,V1,第一对典型相关变量的的得分的散点图
scatter(U_score(1,:),V_score(1,:))
%计算原始变量与典型变量的相关系数
cov_xu=corr(X,(A'*X')') %典型变量u1与X组原始变量:A*X,对原来的变量做线性变换
cov_xv=corr(X,(B'*Y')') %典型变量v1与X组原始变量
cov_yu=corr(Y,(A'*X')')
cov_yv=corr(Y,(B'*Y')')
%下面这个函数是将特征值从大到小排,对应的特征向量也相对应
% 来源链接:https://blog.csdn.net/qq_45814396/article/details/124739641
function [sorted_X,sorted_D]=sorted(X,direction)
[X1,D]=eig(X); %对矩阵求特征值和特征向量
col_vector=diag(D); %将特征值矩阵转换为只有一列的向量
X1=[X1',col_vector]; %将特征值整列追加到特征向量最后
[row,col]=size(X1);
sorted_result=sortrows(X1,col,direction); %按照最后一列排序
sorted_X=sorted_result(:,1:end-1)'; %返回排序后特征向量
sorted_D=sorted_result(:,end); %返回排序后的特征值
end结果:
输出典型相关系数:
D1 or D2:
0.795608154419991
0.200556041107123
0.0725702862103671
典型相关变量与原始变量的线性组合表达式:
U =
0.0314
-0.4932
0.0082
V =
-0.0661
-0.0168
0.0140


绘制两个典型变量u1,V1在上的得分的散点图:

可见他们U1,V1的相关程度很大.
#输出第1组典型变量与X组原始变量之间的相关系数
cov_xu = u1 u2 u3
X1 -0.6206 -0.7724 -0.1350
X2 -0.9254 -0.3777 -0.0310
X3 0.3328 0.0415 0.9421
#输出第1组典型变量与Y组原始变量之间的相关系数
cov_xv =
0.4938 -0.1549 -0.0098
0.7363 -0.0757 -0.0022
-0.2648 0.0083 0.0684
#输出第2组典型变量与X组原始变量之间的相关系数
cov_yu =
0.5789 0.0475 -0.0467
0.6506 0.1149 0.0040
0.1290 0.1923 -0.0170
#输出第2组典型变量与Y组原始变量之间的相关系数
cov_yv =
-0.7276 0.2370 -0.6438
-0.8177 0.5730 0.0544
-0.1622 0.9586 -0.2339
整理后,咱们只看U1,V1

结果分析:上表格可知
本人菜鸟一枚,matlab新手一位,若有错误,请求指正,肯定有更精简的程序,请求指教,谢谢大家。















 6322
6322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









