







声明
本文章基于哔哩哔哩付费课程《小白也能听懂的人工智能原理》。仅供学习记录、分享,严禁他用!!如有侵权,请联系删除
目录
二、编程实验--keras搭建全连接神经网络尝试mnist数据集
一、知识引入
(一)mnist手写体识别
1、灰度值
mnist数据集的图片采用的是28*28的灰度图(一行有28个像素点,一共有28行,每一个像素用1字节的无符号数表示它的等级,0为最暗-纯黑色;最大值255为最亮-纯白色;中间值就是介于纯白和纯黑之间的灰色)通过不同像素点的灰度值,来显示图像。

2、如何将图片数据送入神经网络
神经网络的输入是一个多维数组,即一个向量。
图片是方形灰度值的集合。
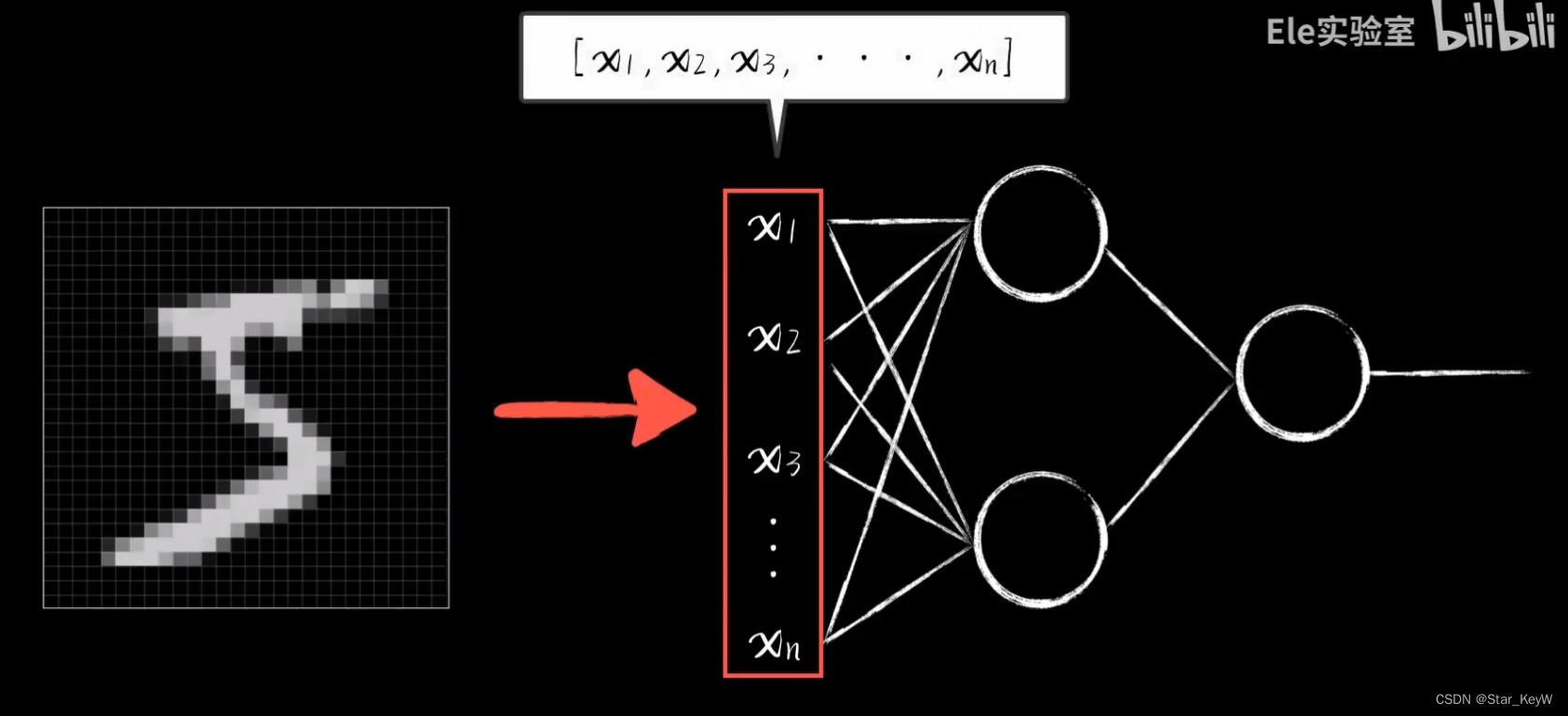
我们将像素从头到尾一行一行一次拉出来,拉出784个像素,每个像素都是一个灰度值,形成一个784维的向量,即一个有784个元素的数组。
3、训练集
在训练时使用的数据集。
4、测试集
在训练集数据之外,拿出一些新的数据进行预测。考验模型是否具有足够的“泛化能力”。
5、机器学习中的3种常见现象
(1)欠拟合:在训练集上的准确率过低。
(2)过拟合:在训练集上的准确率很高,在测试集上的准确率出现了明显的下降。说明模型的泛化能力较差,很难推而广之。
- 用了过分复杂的模型,去拟合实则比较简单的问题,在训练集上追求过分精确的拟合,导致模型在新问题中的表现反而没有那么好
- 类比人类,在学习中死记硬背,而不是理解问题。
(二)卷积神经网络
1、卷积是怎么工作的?
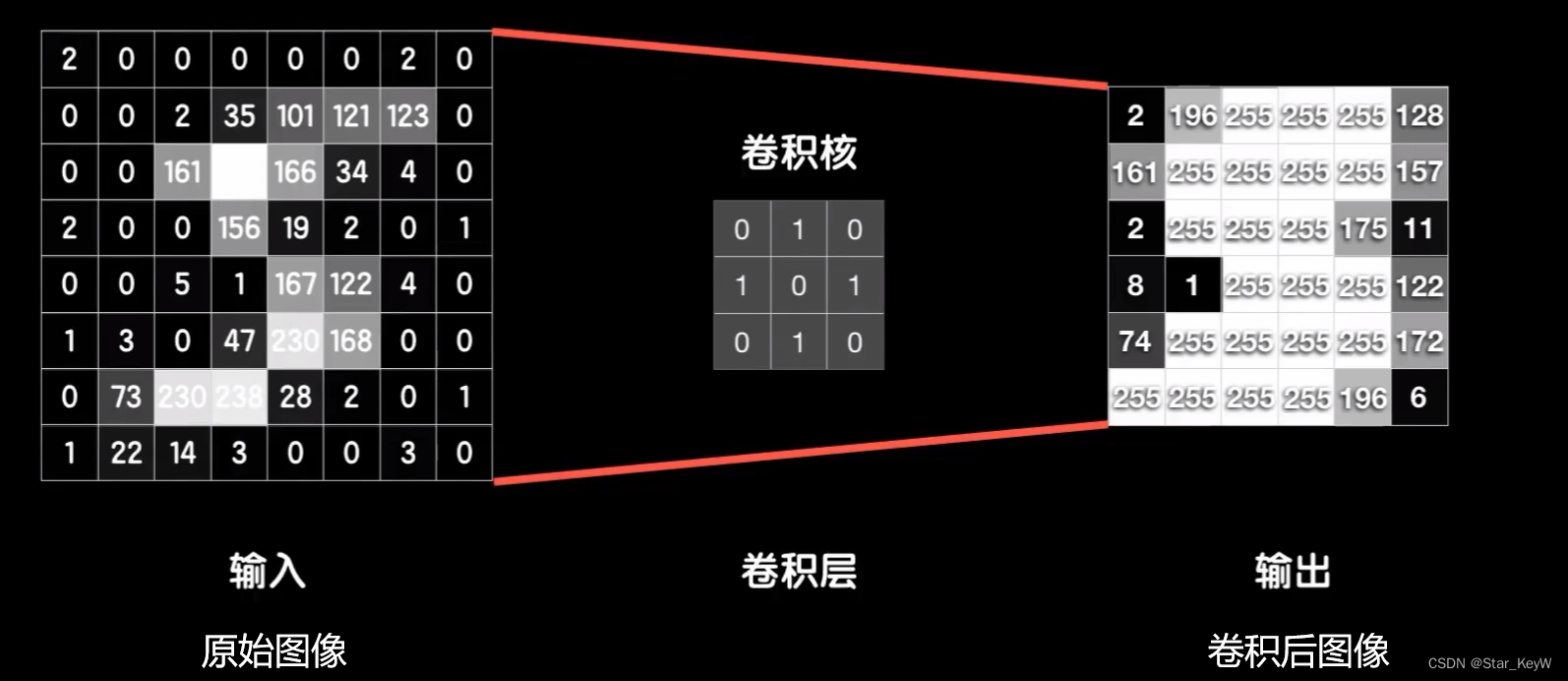
利用一个8*8的灰度图举例,总共有64个像素点,每一个像素点就是0-255之间不同数字,所以我们可以看做是一个8*8的矩阵,即一个二维数组。
手动构建一个3*3的小矩阵,从左上角开始,对应元素相乘。

再把结果相加,得到一个新的值。

完成以后再把这个小的向右挪动一个,同样和大的对应元素相乘,再相加,又得到一个值。

再向右挪动。

重复这个过程,直至到达最右端。然后回到最左段,并且向下挪动一个,从左到右,再来一遍。

顶到头后,再回到最左边,继续向下挪动一个。按照这个模式,直到顶到最下方、最右方为止。

新值按照位置排列后,得到一个6*6的新图片。
而这个3*3的小矩阵,也就是“卷积核”,有时也被称为“过滤器”。
2、卷积核的作用
实际上是用来做轮廓、纹理等特征提取
卷积核的值应该取多少?
其实,随机初始化卷积核内部的值,卷积核的值也是通过训练学习而来的,通过训练找到合适的卷积核去提取不同的特征。
3、卷积层
做卷积运算的一层,称之为卷积层
4、卷积核的反向传播
误差代价如何传到卷积层?
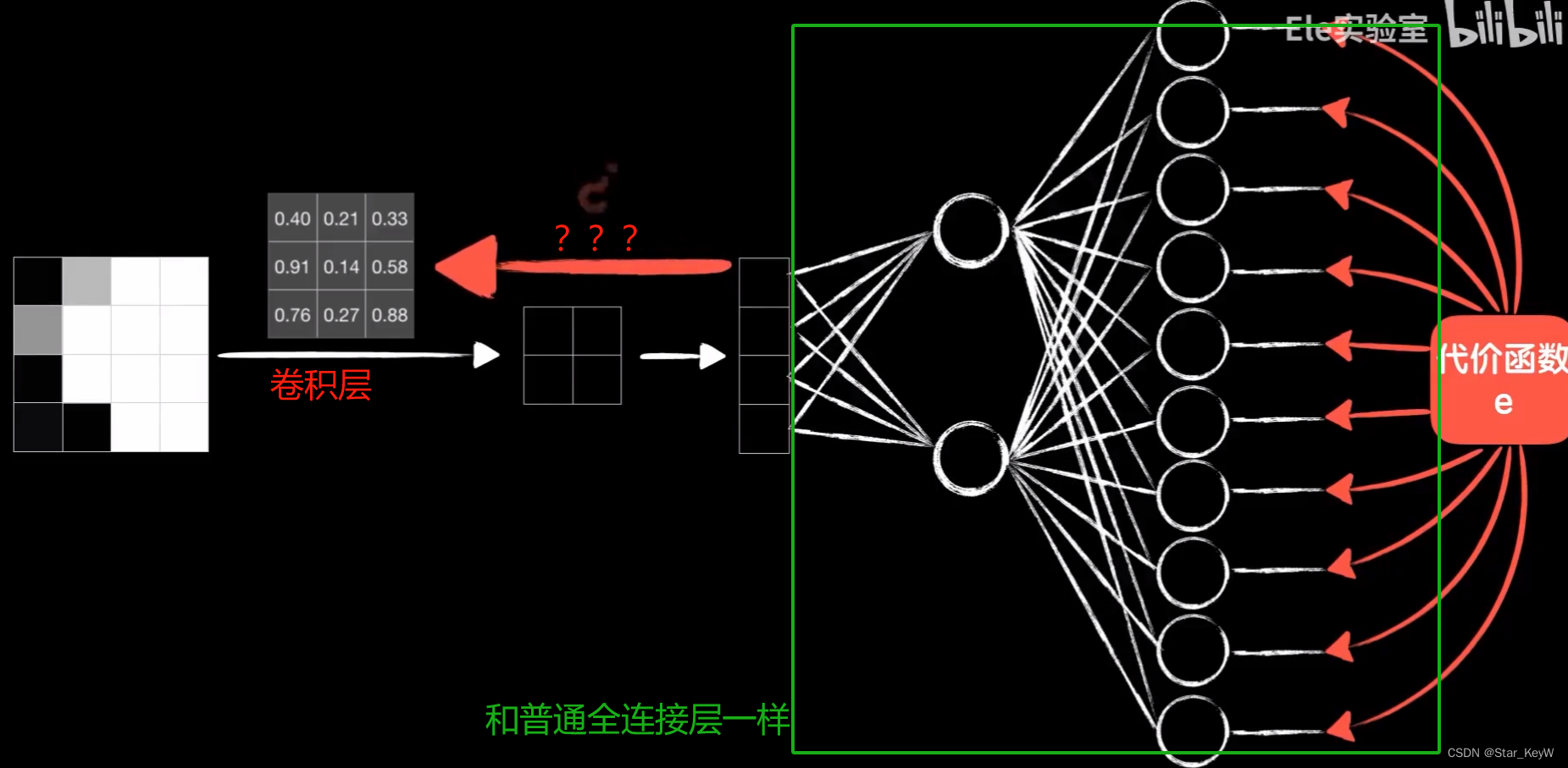
(1)参数共享
如下图,一个4*4的图像,使用3*3的卷积核,卷积的过程就是卷积核依次和局部数据对应元素相乘再相加,得到一个值。
类比普通神经元的工作模式:局部数据时输入数据x,卷积核上的值看做是对应输入数据的权值参数w,对应元素相乘再相加。
正是一个9个输入+1个输出的普通神经元线性运算部分。


加入偏置项b
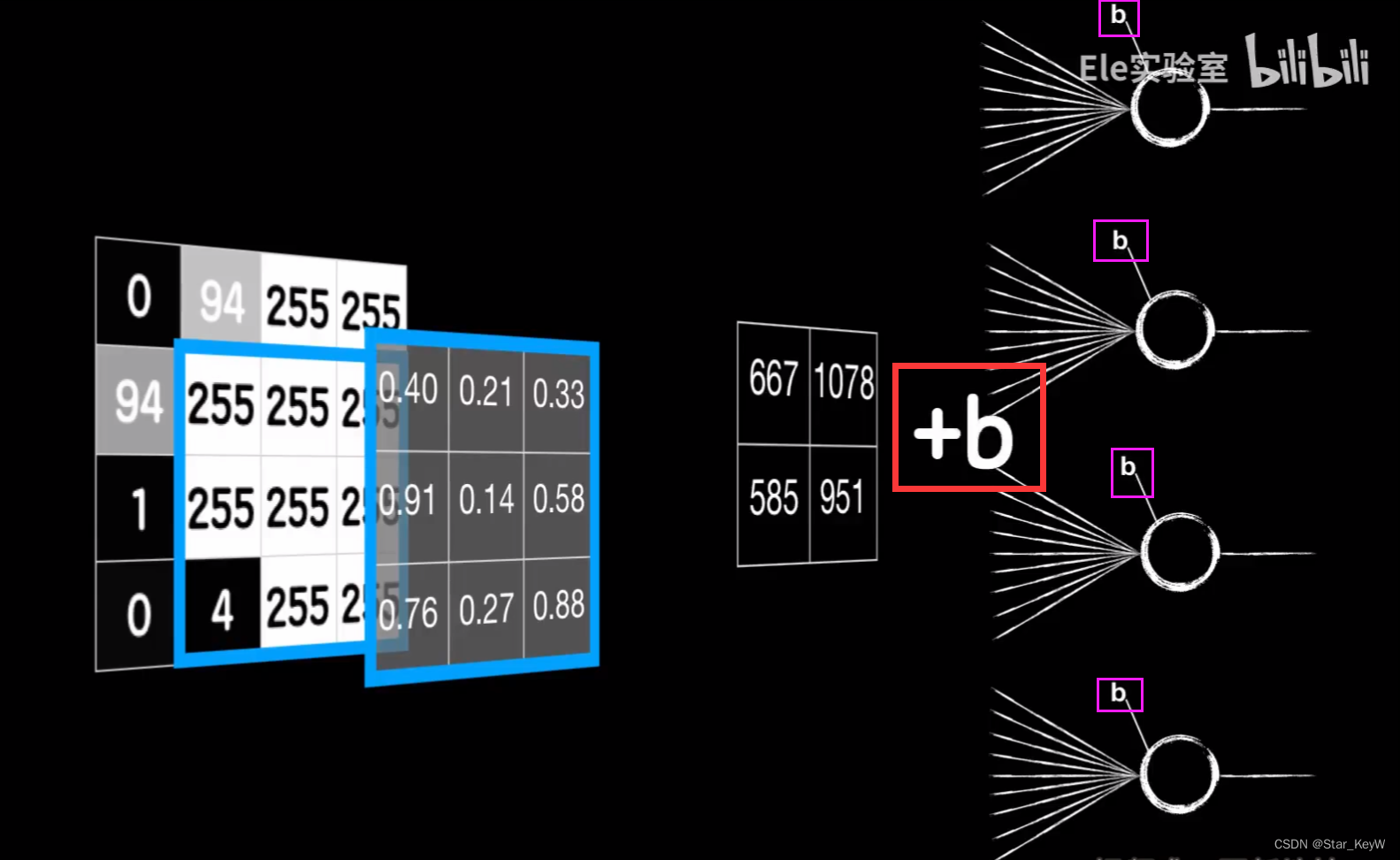
在线性运算之后,通过激活函数,进行非线性预算,就彻底和普通神经元的线性运算部分一样,这才是卷积核的最终输出。

将一个卷积层,拆分成4个普通的神经元。
还有细节不同:这四个神经元的输出是根据卷积的过程排列而成的二维结构,在送入之后的全连接层时,需要手动将其平铺开。

四个神经元的输入并不相同,实际上是同一个图片的不同区域。
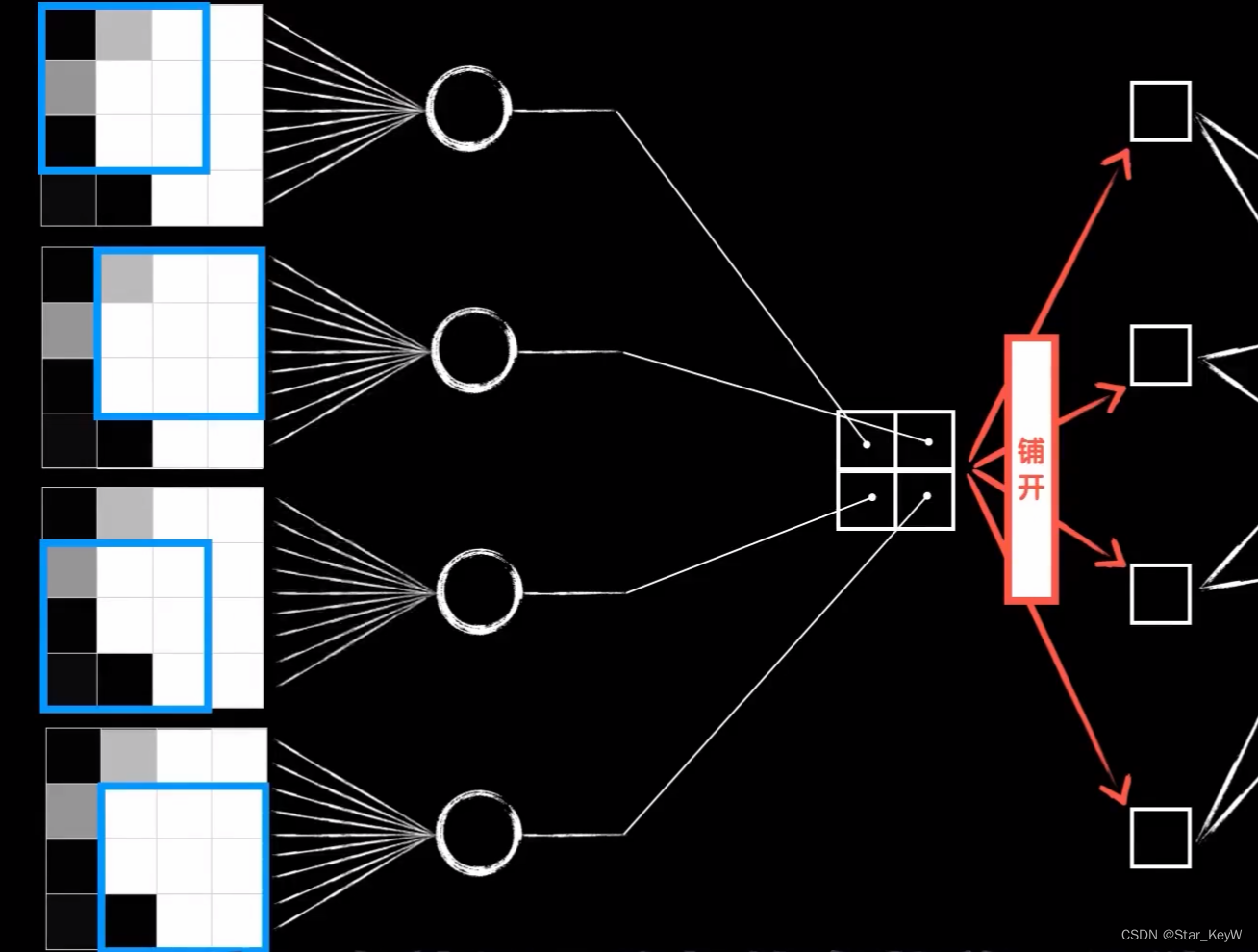
这四个神经元的权值参数并不是独立的,因为我们将卷积核的值,看做是权值参数。而这四个神经元的权值参数都来自同一个卷积核,所以实际上他们的权值参数w(包括偏置项b)是一样的。
我们只是把一个东西,强行拆开,平铺成了4个。这四个神经元,复用了同一套权重参数。
这就是“参数共享”,是卷积层的优势之一。相比于全连接层,大大减小了参数数量(参数数量 = 卷积核的的长度n*卷积核的宽度m+偏置项b,即m*n+1 )

5、提取多个特征
一个卷积核训练得来的结果,是提取图像的一种特征;我们需要提取图像更多的特征,即再搞一个卷积核,提取第二种特征。

想提取多少种特征,就搞多少个卷积核。
而这3个卷积核卷出的3个结果,就是一个三维的张量,将三维张量中的数据铺开,形成一个一维的向量,然后在后面构造全连接神经网络。把铺平的向量作为输入数据,输入其中。

6、多次卷积后再送入全连接
在二维数据上使用的是一个二维的卷积核,自然,在三维数据上使用三维的卷积核。
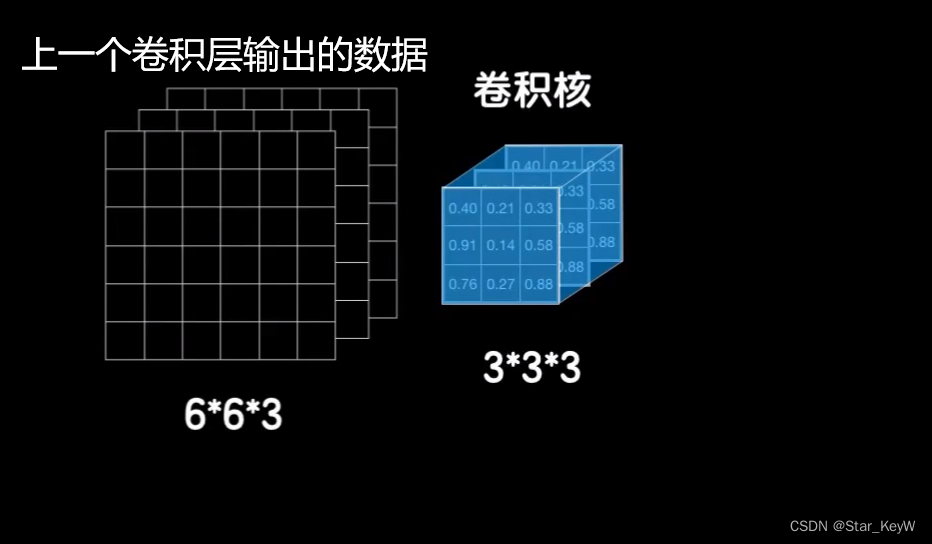
找到数据和卷积核立方块对应的元素位置相乘,相加得到结果。
再加上偏置和激活函数,做非线性运算,得到最后的输出。

同样,二层卷积核也可以使用多个。

被卷积核卷积的数据的第3个维度值,也就是所谓的通道数。
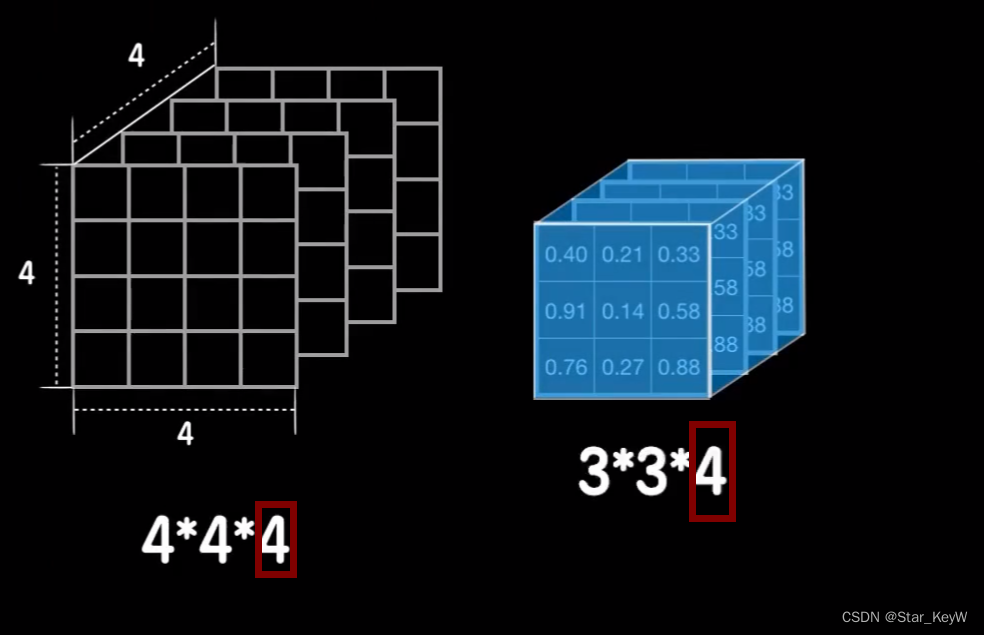
第一次卷积,彩色图片由RGB三个通道,输入是一个三通道的图像:

第二次卷积:
为了让卷积核可以罩得住数据,卷积核的第三个维度值需要和数据的通道数一样。
7、池化层
以单个卷积核卷二维数据为例,经过第一层卷积,8*8的数据被3*3的卷积核卷成了6*6的输出,这个卷积输出接下来就进入池化层进行池化操作。
(1)流程(平均池化)
从数据的左上角开始,框出一个比如2*2的区域,然后求出这2*2数据的平均值,得到一个结果。
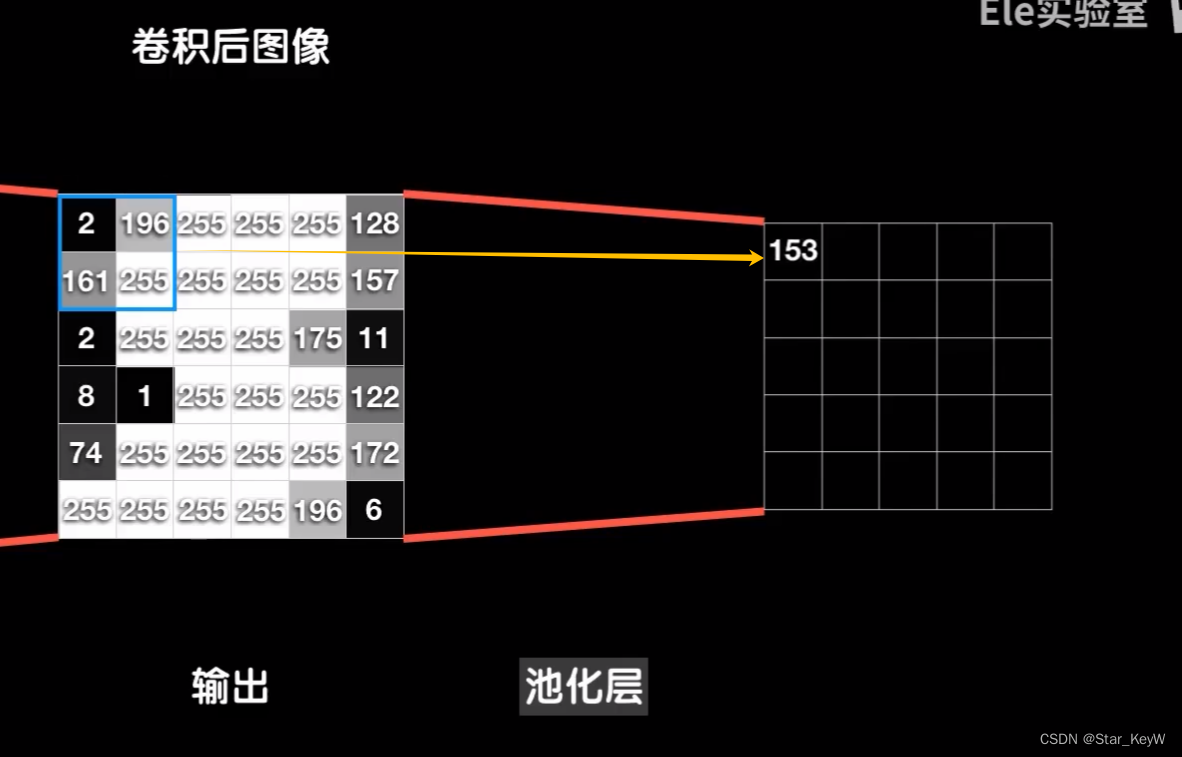
然后像卷积操作那样,向右移动一步,再求出这个2*2的平均值,得到第二个结果。一直顶到最右边,再向下移动一步。

直到最后一行的最右端。

(2)最大池化
取每个小区域的最大值,作为池化结果

(3)多通道的三维数据
跟二维的操作流程一样,结果还是和卷积层输出通道数一样的立方块。



(4)注意
人们发现加入池化层往往效果不错,往往都会在卷积层之后加上池化层,但这并不是必须的。
池化操作是固定套路,所以在反向传播中并没有任何需要学习的参数。
二、编程实验--keras搭建全连接神经网络尝试mnist数据集
(一)导入mnist数据集

from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
# 导入mnist数据集
# 若电脑中不存在mnist数据集,keras会帮助下载到本地,C:\Users\用户名\.keras\datasets
from keras.datasets import mnist(二)导入训练集和测试集模块

# keras封装mnist模块中有一个load_data函数
# X:图像数据,Y:分类标签数据
# 4个数据都是ndarray类型
from keras.src.utils import to_categorical
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()(三)数据归一化操作

输入数据的灰度值范围在0~255之间,这意味着某项黑暗的像素的值很小,比如只有1~5之间,而某些明亮的像素值很大,比如200+,这样的数据导致代价函数很不友好,所以将其变为0-1之间这种差距不大的情况,代价函数就会变得很均匀,有利于梯度下降的进行。
# mnist数据集中,训练数据有60000张,测试数据有10000张
# 把28*28的二维数组,变成长度为784的一维数组
# 输入数据进行归一化操作
X_train = X_train.reshape(60000, 784)/255
X_test = X_test.reshape(10000, 784)/255(四)将分类标签转化为one-hot编码
使用one-hot编码形式:用1个十位数:若第一位是1,其他位是0,就表示第一类;第二位是1,其他位是0,就表示第二类;第十位是1,其他位是0,就表示第十类。
# 将分类标签中的0-9数字,转换成one-hot编码
Y_train = to_categorical(Y_train, 10)
Y_test = to_categorical(Y_test, 10)
# eg:0 --》 [1,0,0,0,0,0,0,0,0,0]
# eg:4 --》 [0,0,0,0,1,0,0,0,0,0]
# eg:9 --》 [0,0,0,0,1,0,0,0,0,1](五)模型搭建
model = Sequential()
model.add(Dense(units=256, activation='relu', input_dim=784))
model.add(Dense(units=256, activation='relu'))
model.add(Dense(units=256, activation='relu'))
# 输出层改为10个神经元,因为包含0-9个数字,共10个类别
# 原sigmoid函数,适合于二分类任务,大于阈值为1类,小于阈值为2类
# 需要一种激活函数将这10个输出的概率相加为1,最大意味着属于这个类别
model.add(Dense(units=10, activation='softmax'))(六)配置模型
多分类问题 --》 多分类交叉熵代价函数
# 配置模型
# 多分类交叉熵代价函数
model.compile(loss='categorical_crossentropy',
# 优化器:用来优化 or 调整参数的算法,sgd:随机梯度下降算法
# SGD优化器默认学习率为0.01,我们使用创建对象的方式,设定其学习率为0.05
optimizer=SGD(learning_rate=0.05),
# metrics:训练时希望得到的评估标准,accuracy准确度
metrics=['accuracy'])
model.fit(X_train, Y_train, epochs=500, batch_size=128)(七)评估模型
# 评估函数,传入测试数据做参数
loss, accuracy = model.evaluate(X_test, Y_test)
print("loss" + str(loss))
print("accuracy" + str(accuracy))
三、编程实验--复现LeNet-5网络预测mnist数据集

(一)导入卷积和池化库函数
# 导入keras实现卷积的库
# Conv2D二维卷积层
from keras.layers import Conv2D
# 导入二维平均池化层
from keras.layers import AveragePooling2D
# 将池化层的输出平铺成一个数组
from keras.layers import Flatten(二)按照卷积要求,导入测试和训练数据
# 卷积神经网络,数据直接送入卷积层,卷积核直接在这个图像上做数据提取,所以不需要将数据扯平
# 灰度图像有3个通道,而RGB彩色图有3个通道,卷积核的第三个维度值必须和它所卷的数据的通道数一样,所以必须明确数据的通道数
# Keras才能根据通道数构建合适的卷积核
# 输入数据进行归一化操作
X_train = X_train.reshape(60000, 28, 28, 1)/255
X_test = X_test.reshape(10000, 28, 28, 1)/255
# 将分类标签中的0-9数字,转换成one-hot编码
# 使用one-hot编码形式,用1个十位数:若第一位是1,其他位是0,就表示第一类
# 第二位是1,其他位是0,就表示第二类
# 第十位是1,其他位是0,就表示第十类
Y_train = to_categorical(Y_train, 10)
Y_test = to_categorical(Y_test, 10)
# eg:0 --》 [1,0,0,0,0,0,0,0,0,0]
# eg:4 --》 [0,0,0,0,1,0,0,0,0,0]
# eg:9 --》 [0,0,0,0,1,0,0,0,0,1](三)搭建LeNet-5网络模型
1、卷积层参数
-
filters表示卷积核的数量
-
kernel_size表示卷积核的尺寸
-
strides表示步长(向右依次挪动1步,到最右边后到左边再向下挪动1步)
-
input_shape表示输入形状
-
padding表示填充模式(原始图像经过卷积操作后,越卷越小,随之而来就是信息损失越来越多)
-
“Same”模式:卷积前,根据核的大小,先在原始图像四周填充几圈全是0的像素点,保证卷积后的大小,与卷积前保持不变 -
“Vaild”模式:不加填充
-
- 卷积中的尺寸变化公式(步长为1,无填充):
m = n - f + 1
- n是原始正方形数据的边长
- f是卷积核的边长
- m是卷积结果数据的边长
2、池化层参数

-
pool_size表示指定池化的时候窗口的大小 -
注:keras中池化操作的步长如果不指定默认和pool_size一样,这里的步长也就默认是(2,2) -
平铺池化层的输出:model.add(Flatten()),后接全连接层
model = Sequential()
# filters表示卷积核的数量
# kernel_size表示卷积核的尺寸
# strides表示步长(向右依次挪动1步,到最右边后到左边再向下挪动1步
# input_shape表示输入形状,
# padding表示填充模式(原始图像经过卷积操作后,越卷越小,随之而来就是信息损失越来越多。
# 卷积前,根据核的大小,先在原始图像四周填充几圈全是0的像素点,保证卷积后的大小,与卷积前保持不变
# 称为“Same”模式
# activation卷积层使用的激活函数
model.add(Conv2D(filters=6, kernel_size=(5, 5), strides=(1, 1),
input_shape=(28, 28, 1), padding='valid', # 不加填充
activation='relu'))
# 堆叠池化层
# pool_size表示指定池化的时候窗口的大小
# 注:keras中池化操作的步长如果不指定默认和pool_size一样,这里的步长也就默认是(2,2)
# 堆叠卷积层
model.add(AveragePooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=16, kernel_size=(5, 5), strides=(1, 1),
padding='valid', # 不加填充
activation='relu'))
# 堆叠池化层
model.add(AveragePooling2D(pool_size=(2, 2)))
# 平铺池化层的输出
model.add(Flatten())
# 全连接层
model.add(Dense(units=120, activation='relu'))
model.add(Dense(units=84, activation='relu'))
# 输出层
model.add(Dense(units=10, activation='softmax'))(四)配置模型
# 配置模型
# 多分类交叉熵代价函数
model.compile(loss='categorical_crossentropy',
# 优化器:用来优化 or 调整参数的算法,sgd:随机梯度下降算法
# SGD优化器默认学习率为0.01,我们使用创建对象的方式,设定其学习率为0.05
optimizer=SGD(learning_rate=0.05),
# metrics:训练时希望得到的评估标准,accuracy准确度
metrics=['accuracy'])
model.fit(X_train, Y_train, epochs=200, batch_size=128)(五)评估模型
# 评估函数,传入测试数据做参数
loss, accuracy = model.evaluate(X_test, Y_test)
print("loss" + str(loss))
print("accuracy" + str(accuracy))
















 928
928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











