







1.2模型评估
选取70%作为训练集,30%作为测试集。为了训练模型并对其进行评估,使用有平方误差成本的线性回归。首先通过最小化w和b的成本函数j来拟合参数。然后为了说明这个模型表现如何,计算测试集误差以及训练集误差。

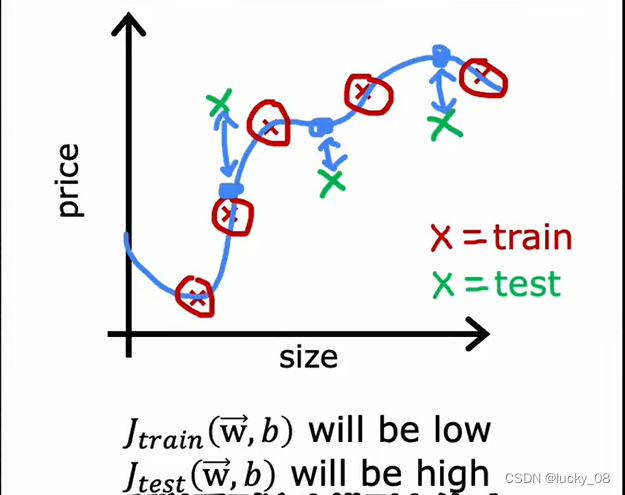
训练集的平均误差是0或接近0,所以训练集的J将会很接近0;测试集里可能有没训练过的示例,那么测试集的J会很高。
模型选择:

发现d=5时,j最低,但可能会导致过拟合。
问题是d=5时,Jtest像是泛化误差的乐观估计。
原因:此处通过不同的d也就是不同个数的w来寻找最小的Jtest来拟合模型,从本质上和前面的方法一样,因为数据集是无穷的,在我们给定的有限数据之外还有更多的数据。
训练集/交叉验证集/测试集:6:2:2
交叉验证集(验证集/开发集):用于检查不同模型的有效性和真实性
vali用于选模型(选Jcv最低的),test用于检查模型的泛化能力(机器学习算法对新鲜样本的适应能力)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









