






前注:本文是强化学习的梳理归纳,之前有一定的强化学习入门基础,非纯小白。
参考资料主要为:
-
西湖大学赵世钰老师编写的《Mathematical Foundation of Reinforcement Learning》即《强化学习的数学原理》这本书籍,比较偏向于数学底层原理部分。
-
莫烦python的部分强化学习代码。
-
网上其他一些查阅到的资料及文献。
-
本人自己的理解与总结归纳。
下面进入正题:
一、什么是强化学习?
强化学习是智能体(Agent)与环境互动的过程中,通过获得的奖赏作为指导,目标是使智能体获得最大奖赏,从而完成任务。(强化学习、有监督学习、无监督学习都是机器学习的一种)
强化学习所学习的东西:一个好的价值函数(一个好的价值函数决定一个好的策略)
二、为什么要研究和引入强化学习?
1.在监督学习和无监督学习中,都是通过大量数据去学习背后的规律。而在强化学习中,我们拥有的不是数据而是环境,可以从环境中产生数据,最终目标不是学习背后的规律,而是要智能体能够在环境中能够表现的优秀,获得尽可能多的奖励。
2.强化学习的思想与人类学习的过程有很大的相似性,被认为是迈向通用人工智能的重要途径。
3.可以用来解决网络与通信领域的问题。由于网络与通信领域存在多种组合优化问题,如资源分配、路由拓扑优化、计算迁移等,因此基于深度强化学习的组合优化在网络与通信领域存在较多且有待挖掘的应用。(由于本人专业是信息与通信工程,所以会倾向于关注一些强化学习在通信以及网络资源分配中的应用。)
三、强化学习的三层结构与主要元素梳理
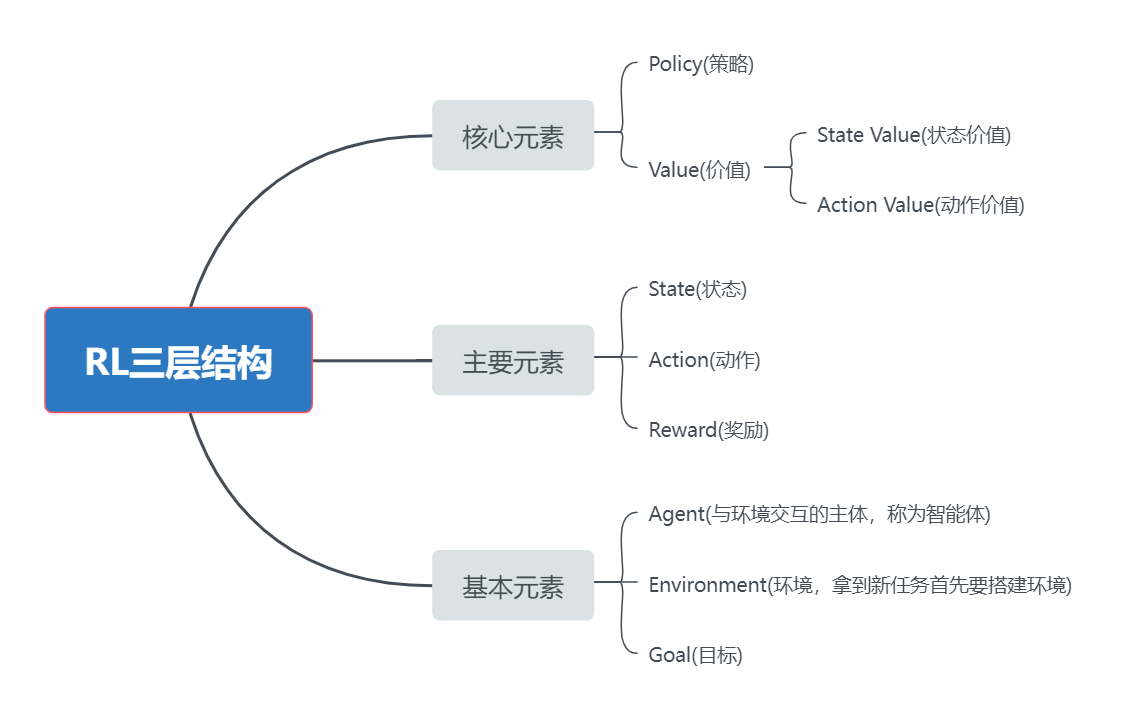
图1 RL的三层结构与主要元素
个别元素解释:
(1)State:描述的是Agent相对于环境的的一个状态,如s1、s2、……sn。S={Si}表示所有状态的集合,即状态空间。
(2)Action:在每一个状态s上有一系列可以采取的行动a1、a2、……an。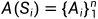 ,表示动作空间,它和状态是有依赖关系的。
,表示动作空间,它和状态是有依赖关系的。
由此定义了一个Agent与环境交互的行为State Transition: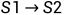 (在动作a2的作用下),用条件概率,从数学的角度来描述:
(在动作a2的作用下),用条件概率,从数学的角度来描述:
P(s2|s1,a2)=1
P(si|s1,a2)=0
(3)Policy:在每个状态下,Agent有很多动作可选,称为策略,用条件概率来表示(指定了在一个状态下,采取不同动作的概率是多少)。特殊的,对于状态s1下的策略:
Π(a1|s1)=0.2
Π(a2|s1)=0.3
Π(a3|s1)=0.5
(4)Reward:奖励是在强化学习中具有独特性的概念,它是一个标量,用于对Agent的行为进行打分,可分为鼓励与惩罚。我们通过设置奖励来引导Agent达到一定的理想目标,去适应环境。例如,在状态s1时,选择动作a1,奖励为-1,用数学语言来描述:
P(r=-1|s1,a1)=1
P(r≠-1|s1,a1)=0
(注:每一步都有Reward,将完整运行一次之后的Reward的总和称为Return,Return可用来衡量整个策略的好坏,而不是某一步的好坏。状态、动作、奖励、状态、动作、奖励将一直进行下去,称为state-action-reward链,又叫做trajectory)
四、一些常用概念及方法的引入
(1)Discounted Return(折扣回报):为了使Return收敛,且近期回报的权重高于远期回报,引入了Discounted Return。
我们通常把t时刻的Return叫做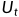 (含义是把t时刻的所有奖励reward全部累加起来,一直加到任务结束时的最后一个奖励):
(含义是把t时刻的所有奖励reward全部累加起来,一直加到任务结束时的最后一个奖励):
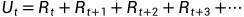
引入折扣率γ后,可得到Discounted Return(折扣回报),折扣率γ∈[0,1),γ越大,未来奖励的比重会越大,反之越小。将Discounted Return定义为新的:

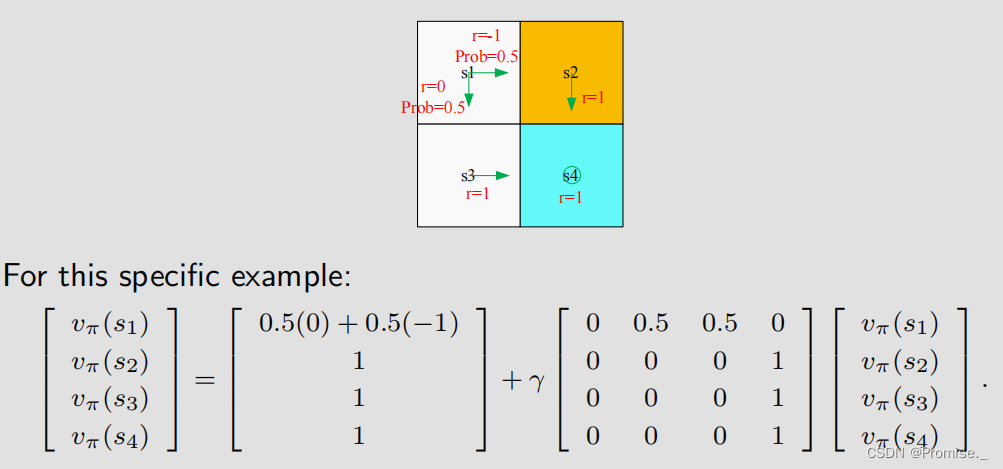
(2)State Value(状态价值):状态价值是的期望,由于策略选择具有随机性,状态也具有随机性,所以需要对求期望,将其定义为状态价值Vπ(s):
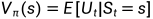
注:
(i)Vπ(s)又叫状态价值函数,是状态s的一个函数。从不同的状态s出发,得到的轨迹不同,则得到的也不同,求期望后也不同。
(ii)Vπ(s)也是策略π的函数,其又可写为V(S,π)。显然不同的策略会得到不同的轨迹,则得到的也不同,求期望后也不同。
(iii)State Value与的区别:是对于单个的trajectory,而State Value是对多个trajectory得到的再求期望。
(iv)贝尔曼公式:
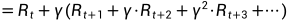

注意:在上式中,此处的也可以写成
,一般来说,应该写成
。从数学上来说他们没有什么本质上的区别,这只是一个习惯,不过写成
,有助于后面推导贝尔曼公式的理解。
该公式表明等于该时刻得到的reward加上下一个时刻从那个状态出发得到的折扣回报。
进一步地,
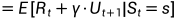

该式子将状态价值函数由原来的一个期望分解为两个期望,下面分别求两个期望。
第一个期望:
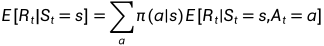

该式子就是得到的immediate reward的一个平均值。
该式子表示在状态s下有多个action可以执行,对这些action下的状态价值求期望。这里将写成
较为容易理解。
第二个期望:



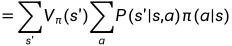
第一个期望是当前奖励的期望,第二个期望是对未来所有奖励的期望。
将上面两个期望相加后,可以得到贝尔曼公式

也许从上面这个式子来看,贝尔曼公式十分复杂,但其实十分简单,给出向量形式:
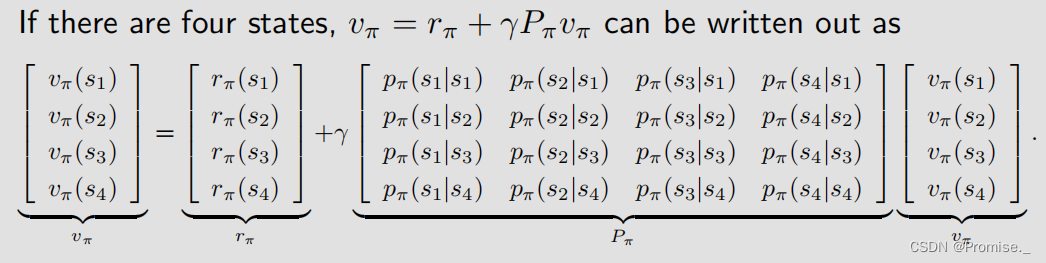
例如:
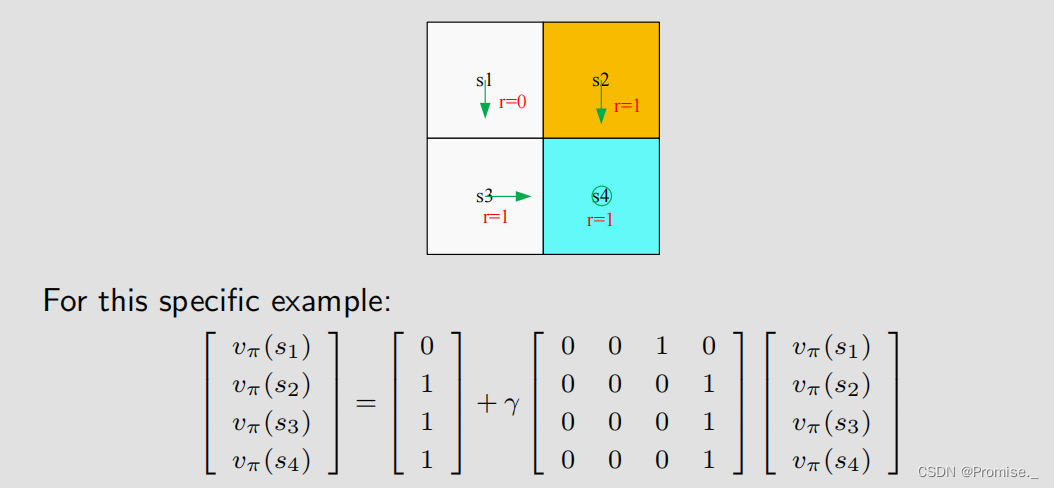
稍微复杂一点点的情况例如:
(3)Action Value(动作价值):
在引入动作价值前,首先理清楚状态价值与动作价值的概念。
状态价值:Agent从一个状态出发,得到的平均奖励。
动作价值:Agent从一个状态出发并采取动作,得到的平均奖励。
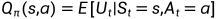
①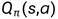 是一个 状态动作对儿 (s,a)的函数。
是一个 状态动作对儿 (s,a)的函数。
②依赖于策略函数π。
状态价值与动作价值的关系:
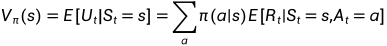
由上式可以得到状态价值与动作价值的关系:

(4)Optimal policy(最优策略):
定义:对于任意状态下的任意策略来说,有一个策略π*是最优的,即:
(5)贝尔曼最优公式:
对贝尔曼公式做一个小的改动后(引入最优问题),即可得到贝尔曼最优公式。
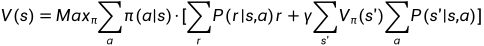
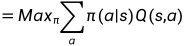
最优项的处理: 是一个向量,在每个状态下都有很多不同的策略,是找出每个状态下的最优策略。
是一个向量,在每个状态下都有很多不同的策略,是找出每个状态下的最优策略。
在贝尔曼(最优)公式中,需要明白的是,有一些量是已知的,一些量是未知的:
系统模型: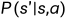 、
、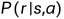 (已知)
(已知)
折扣率:γ (已知)
奖励:r (已知)
v(s)、v(s')、π(a|s) (待求)
五、强化学习中的算法
5-1蒙特卡洛算法:
1.MC Basic
2.MC Exploring Starts
3.MC -Greedy
这三个算法是层层递进的,上一个算法是下一个算法的基础。其中MC Basic算法是最简单的,简单到在实际中是没有办法使用的,因为他的效率等各方面都是比较差的。
蒙特卡洛算法是Model Free的算法,即不基于模型的算法。
如何在没有模型的情况下去估计一些量呢?这里有一个重要的方法或思想是蒙特卡洛近似:即通过大数定律,以多次试验求均值的方法去近似期望。
5-1-1 MC Basic算法
MC Basic算法是基于Policy iteration算法的,Policy iteration算法有两个步骤:
在Policy evaluation步骤中:有一个策略,然后通过步骤一这个贝尔曼公式,求解出出它的状态价值
在Policy evaluation步骤中:得到步骤一的之后,就可以做出改进,即通过最优化的问题,得到
,这个式子写的是向量形式,如果写成基本形式,其实主要是求解
,不断选择最优的
是如何计算的呢?如果采用基于模型的方式,则是:
但是蒙特卡洛方法是采用不基于模型的方式,因此不使用上面这个计算式,而是使用动作价值最原始的定义:
下面我们梳理一下Monte Carlo estimation(蒙特卡洛估计)的具体步骤:
1.从(s,a)出发,根据策略,产生一个episode
2.这个episode的discounted return是u(s,a)
3.u(s,a)是这个式子中的采样:
4.如果我们有很多这样的采样,有一个集合,就可以用这些采样求一个平均值:
总的来说,没有模型的时候得有数据,没有数据的时候得有模型,总得有一个。这些数据在强化学习中叫作经验(experience)
综上所述,MC Basic算法的伪代码如下:
| 初始化:初始化策略 |
| 目标:寻找一个最优的策略 |
| while the value estimate has not converged,for the For every state For every action Collect sufficiently many episodes starting from (s,a) following MC-based policy evaluation step: Policy improvment step:(选择action value最大的action作为新的策略) 令 |
5-1-2 MC Exploring Starts算法
MC Basic算法可以帮助我们很好地去理解怎么用蒙特卡洛方法来实现不需要模型的强化学习,但是它的效率非常低,在实际中并不实用。















 1007
1007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









