






深度强化学习基础
文章目录
本文是我自己学习强化学习的一个记录,可能会有一些不全面,建议观看视频学习,up主讲的还是很好的。学习的视频是b站上王老师的视频,深度学习强化基础
一、概率论相关知识
1.概念
X代表随机变量,x代表观测值。
2.概率密度函数
1)连续性概率密度函数,正态分布的概率密度函数:
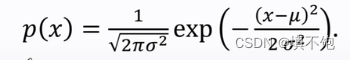
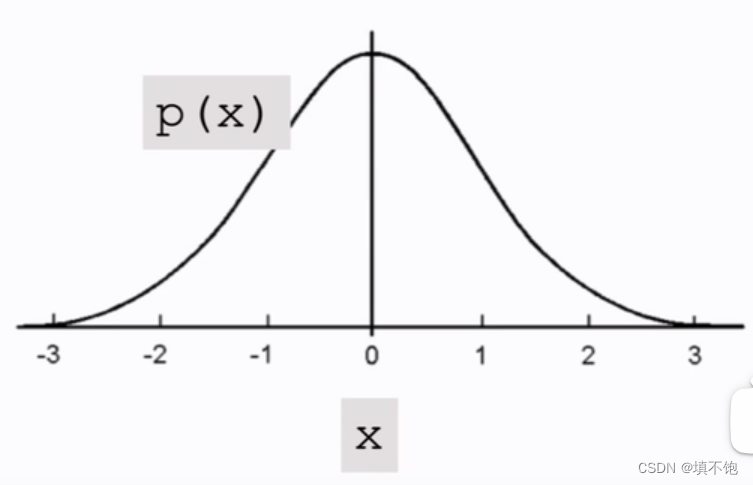
纵轴表示概念密度,曲线表示高斯分布曲线。
2)离散型概率密度函数:x取离散的值,每一个值对应一个概率。如X={1,5,7},概率密度函数p(1)=0.3,p(5)=0.4,p(7)=0.3。
3)性质:
(1)连续:
∫
x
g
(
x
)
d
x
=
1
\int_x^{}g\left(x\right)dx=1
∫xg(x)dx=1 ,离散:
∑
x
∈
X
g
(
x
)
=
1
{\sum}_{x\in X}^{}g\left(x\right)=1
∑x∈Xg(x)=1
(2)期望,连续:
E
[
f
(
X
)
]
=
∫
x
f
(
x
)
⋅
g
(
x
)
d
(
x
)
E\left\lbrack f\left(X\right)\right\rbrack=\int_x^{}f\left(x\right)\cdot g\left(x\right)d\left(x\right)
E[f(X)]=∫xf(x)⋅g(x)d(x),离散:
E
[
f
(
X
)
]
=
∑
x
∈
X
∫
x
f
(
x
)
⋅
g
(
x
)
d
(
x
)
E\left\lbrack f\left(X\right)\right\rbrack={\sum}_{x\in X}^{}\int_x^{}f\left(x\right)\cdot g\left(x\right)d\left(x\right)
E[f(X)]=∑x∈X∫xf(x)⋅g(x)d(x)
3.随机抽样
如:一个袋子里共10个球,3黑2白5红,随机从袋子里拿一个球,问是红球的概率多大?
二、强化学习专业术语
1.基本知识
1)state:状态,action:行为,动作,agent:智能体
游戏为例:超级玛丽,不严谨的说法,游戏画面的一帧可以当作一个状态。而玛丽向上向下向左向右,就是一个个动作。动作发出的主体就叫做agent。

2)policy:策略

Π为概率密度函数,意思是在给定状态下,进行动作a的概率大小,agent动作是随机的,根据policy的概率密度决定下一个action。简而言之,玛丽在当前情况下,向左走向右走向上跳的可能性。policy是随机抽样得到的,随机抽样得到的概率密度函数的值。
3)Reward:奖励。超级玛丽的奖励机制:
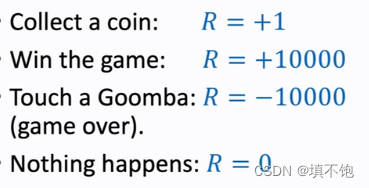
强化学习的目标是获得的奖励总和尽量要高。
4)state transition:状态转移,agent进行一个动作后,状态就会改变,进入到下一个状态。状态转移函数可以是随机的,由环境决定。环境用状态转移函数计算出下一个状态的p,然后随机抽样,得到下一个状态。超级玛丽中的环境是游戏程序,由游戏程序决定下一个状态是什么。超级玛丽向上跳,攻击者向左的概率是0.8,向右的概率是0.2,但是我们不知道,在当前状态,当前动作下,攻击者会向哪个方向走,下一个状态是未知的。状态转移函数,用户是未知的。

5)学习流程
通过强化学习学习policy函数Π,AI用policy函数控制agent。
当前状态s→通过policy函数计算概念后随机抽样确定action→环境生成下一个状态,并给agent一个奖励r→AI用新的状态作为输入重复操作。
2.reward和return
1)return:回报,累计未来回报,从当前到游戏结束的每一步的回报累加起来。
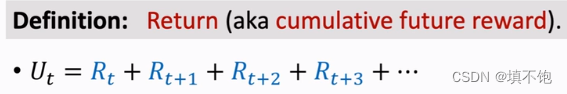

当前reward与当前状态、动作相关。
当前return与当前及之后的所有状态、动作相关。
3.Action-Value Function 动作价值函数
return是个随机变量,对U求期望,即是动作价值函数,将后续的状态和动作进行积分,剩下当前状态和动作(观测值),Q与积分函数即policy Π相关,所以policy函数不同,Q不同,为去除policy函数的影响,对Q求最大化,Q最大时的policy函数就是最好的。意义:根据Qmax评估每一个动作的好坏,从而选出Q值最高的动作。

4.State-Value Function 状态价值函数
对动作求期望,V与Π和s相关,V显示当前局势。

三、各种强化学习方式
1.Value-Based Reinforcement Learning基于价值的强化学习(价值学习)
1)Qmax,基于动作价值函数。
价值函数的目标是用神经网络近似Qmax函数,神经网络为DQN(Deep Q Network),使用DQN来操纵,确定下一步动作。
Q(s,a,w),w是神经网络的输入,s是神经网络的输入,每一个动作的打分是神经网络的输出,每一个动作一个分数,n个动作n个分数,输出为n×1的向量。
2)训练DQN,使用TD算法(Temporal Difference)。

不断迭代,更新参数,使训练的越来越好。
2.Policy-Based Reinforcement Learning基于策略的强化学习(策略学习)
基于状态价值函数,Π越好,V越大,胜算越大。用策略神经网络近似策略函数,参数θ,改进参数θ,使V越大。

目标函数J(θ),只关于θ,是对策略网络的评价,策略函数越好,J(θ)越大。

随机梯度,θ的更新。

策略梯度:

From 1用于离散型,Form 2用于连续型。
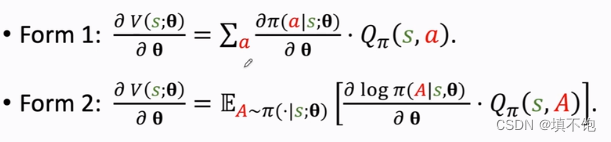
算法过程:

对qt的两种解决办法:


3.Actor-Critic Methods(以上两种的结合)

目的:actor的分数越来越高,critic的打分越来越精准。
训练神经网络:更新策略网络参数θ,提高V的值,为了使V函数增加,V是对策略Π和状态s的评价,V越大,策略越好。更新价值网络参数w,更好的估计回报。
算法流程:观察状态st,用策略网络Π来计算概率分布,根据计算出的概念随机抽样得到动作at;agent执行动作,环境提供新的状态s(t+1)和奖励rt;新的状态s(t+1)作为网络输入,使用策略网络计算新的概率,然后随机抽样得到动作a(t+1),但不执行这个动作;计算两次价值网络的输出,用st和at作为输入,算出裁判打分qt,使用s(t+1)和a(t+1)作为输入,算出裁判打分q(t+1);计算TD error,即为当前预测与TD target的差值;对价值网络求导,再更新价值网络;对策略网络求导,再更新策略网络。
α:学习率

附:这是视频中的一个代码,但是我没有实现成功
import gym
env=gym.make('CartPole-v0')
state=env.reset() ##初始状态记为state
for t in range(100):
env.render() ##渲染
print(state)
action=env.action_space.sample() ##随机均匀抽样
state,reward,done,info=env.step(action) ##agent做动作
if done:##游戏是否结束,1为解释
print('Finished')
break
env.close()















 2659
2659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









