






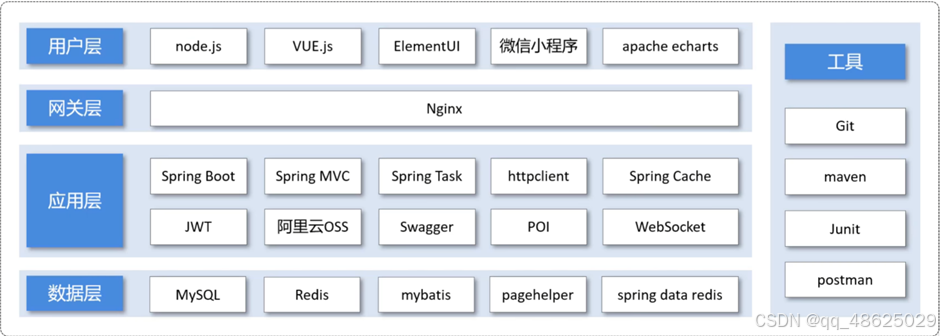
整体架构
redis它在你的项目中作用是什么?
Redis是高性能的,基于键值对的,写入缓存的 内存存储系统。它支持多种数据结构如字符串、哈希表、列表、集合、有序集合等,并提供了丰富的操作命令。
项目中引入Redis的地方是:
查询店铺营业状态,像这种店铺营业状态,本项目无非就两个状态:营业中/打样。而且它属于高频查询。只要用户浏览到这个店铺,前端就要自动发送请求到后端查询店铺状态。Redis把将数据放到缓存中,而不是磁盘,有效缓解了这种高频查询给磁盘带来的压力。
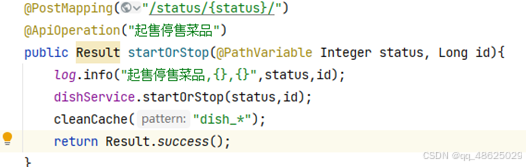
查询店铺营业状态:起售停售都要清理缓存数据
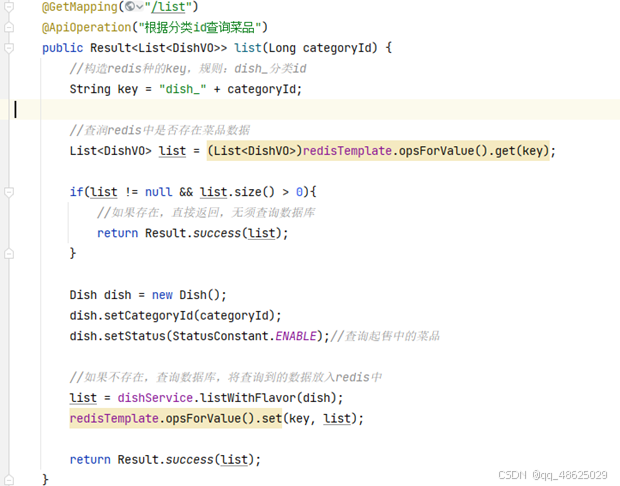
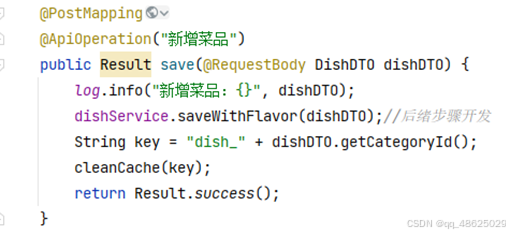
缓存菜品:用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大。用户一旦点进店铺,店铺就需要向用户展示菜品,套餐等等数据。这种通过少量的操作可以调起大量后端操作的行为,是一个很危险的杠杆操作。而在高并发环境下,这无疑又是在拷打服务器。而且这种重复查询的请求,正是我们要优化的目标。

通过Redis来缓存菜品数据,减少数据库查询操作。DishController.java
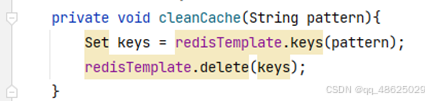
缓存套餐(用到的是Spring Cache)
User\SetmealController.java:加上spring cache的注释cacheable,根据方法的请求参数对其进行缓存。以后查询相同的数据,直接从缓存中取

Admin\SetmealController.java:加上注释cacheEvict用于清空缓存


用springcache解决redis和数据库不一致
用cacheevict清空缓存,修改套餐也要清空全部缓存,因为这个套餐的缓存是按分类缓存的,修改还有可能修改套餐的分类,不能指定删除某一个缓存。
beforeInvocation:是@CacheEvict中特有的一个属性,意为是否在执行对应方法之前删除缓存,默认false(即执行方法之后再删除缓存),先操作数据库再删缓存
项目中redis作为缓存,MySQL的数据如何与redis进行同步(双写一致性)
外卖这个项目中用户在查看店铺状态时,需要让数据库与 redis高度保持一致,因为如果店铺没有营业的话就不能点单了,所以它要求时效性比较高,所以采用的读写锁保证的强一致性。我们采用的是 redisson实现的读写锁,在读的时候添加共享锁,可以保证读读不互斥,读写互斥。当我们更新数据的时候,添加排他锁,它是读写,读读都互斥,这样就能保证在写数据的同时是不会让其他线程读数据的,避免了脏数据。这里面需要注意的是读方法和写方法上需要使用同一把锁才行。
- 引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.17.1</version> <!-- 请根据实际情况选择版本 -->
</dependency>- Redis分布式锁代码
@Service
public class GoodsService {
@Autowired
private RedissonClient redissonClient;
public boolean seckillGoods(long userId, long goodsId) {
String lockKey = "seckill:" + goodsId;
RLock lock = redissonClient.getLock(lockKey);
try {
if (lock.tryLock(500, 10, TimeUnit.MILLISECONDS)) /**
* 尝试获取锁tryLock
* waitTimeout 尝试获取锁的最大等待时间,超过这个值,则认为获取锁失败
* leaseTime 锁的持有时间,超过这个时间锁会自动失效(值应设置为大于业务处理的时间,确保在锁有效期内业务能处理完)
**/
{//成功获得锁,在这里处理业务
Goods goods = goodsDao.getGoodsById(goodsId);
if (goods.getStock() > 0) {
// 秒杀成功,更新库存
goodsDao.reduceStock(goodsId);
// 创建秒杀订单等操作
return true;
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {//无论如何最后都要解锁
lock.unlock();
}
return false;
}
}
因为我们在添加redis作为缓冲区之后,如果缓冲区中存在数据,我们是直接从缓冲区拿数据的,如果我们更改了数据库,可能就会造成数据库与缓冲区数据不一致的情况。
读写双写(Write-through):在更新数据库时,同时更新Redis缓存。这意味着在写入数据库的同时,将相同的数据写入Redis缓存。这种方式确保了数据库和缓存中的数据始终保持一致。但是需要注意的是,双写操作会增加系统的写入负载和延迟,并且需要保证写入操作的原子性。
读写更新(Write-behind):在更新数据库时,延迟更新Redis缓存。这种方式先更新数据库,然后异步地更新Redis缓存,以提高写入的性能和响应速度。在这种情况下,可能会出现一小段时间内数据库和缓存数据的不一致,但后续的读取操作会从数据库中获取最新的数据并更新缓存。
缓存失效策略:通过在缓存中设置适当的过期时间或失效策略,确保缓存中的数据在一定时间后会过期并从数据库中重新加载。这样可以保证在数据更新或过期后,下一次读取操作将从数据库中获取最新的数据,并更新缓存。这种方式适用于数据变化不频繁、对数据实时性要求不高的场景。
发布订阅模式(Pub/Sub):使用Redis的发布订阅功能,当数据库中的数据发生变化时,通过发布消息的方式通知订阅者(Redis缓存)进行更新。这样可以保证在数据发生变化时,及时通知Redis缓存更新,以保持数据的一致性。
通过乐观锁解决超卖问题
-
版本号法实现乐观锁(项目采用)
根据商品id,查询到商品版本号,用查到的这个版本号,尝试update操作。
在商品表中增加一个版本号字段,每次更新库存时,都会携带这个版本号。如果版本号没有发生变化,说明在此期间没有其他线程修改过数据,更新操作可以进行;如果版本号发生了变化,则说明有其他线程已经修改过数据,此时需要重新获取最新的数据并尝试再次更新。
UPDATE goods SET stock = stock - 1, version = version + 1 WHERE id = #{id} AND stock > 0 AND version = #{version}//当商品的库存大于0且版本号与传入的版本号相同时,将库存减1,并将版本号加1。
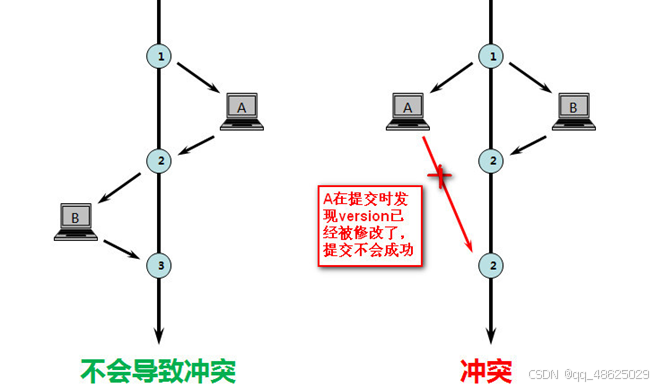
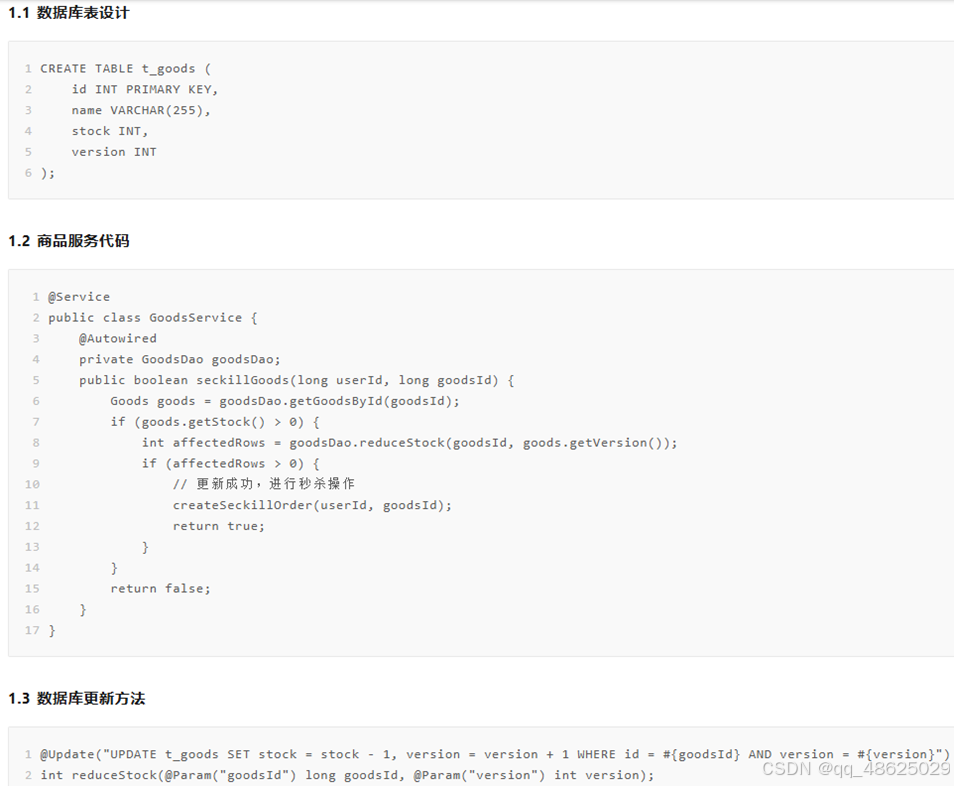
为什么用乐观锁?
乐观锁适合用于读操作多的场景,不加锁可以提升读操作的性能,本项目的超卖问题类似于秒杀场景下的库存问题,这里就借鉴了高并发场景下的乐观锁来解决。
还可以用redis分布式锁
乐观锁特点
优点:
- 无锁机制,不会阻塞其他线程。
- 对于读多写少的场景性能较好。
缺点:
- 需要额外的版本号字段。
- 在高并发写入场景下,容易出现CAS失败,需要重试。
Redis分布式锁
优点:
- 在分布式环境中保证了并发安全。
- 使用简单,不需要修改数据库表结构。
缺点:
- 引入了额外的依赖,可能对性能有一定影响。
- 锁的过期时间需要谨慎设置,过长可能导致死锁,过短可能引起并发问题。
CAS法实现乐观锁
CAS用库存量代替版本号,在执行操作时判断where用的库存量和在最初查询的时候,是否相等。
悲观锁与乐观锁
1.两者的区别
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程。
乐观锁总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证数据是否被其它线程修改。乐观锁最常见的实现就是CAS。
适用场景:
- 悲观锁适合写操作多的场景。
- 乐观锁适合读操作多的场景,不加锁可以提升读操作的性能。
2.什么是CAS
CAS 的全称是 Compare And Swap(比较与交换) ,用于实现乐观锁,被广泛应用于各大框架中。CAS 的思想很简单,就是用一个预期值和要更新的变量值进行比较,两值相等才会进行更新。CAS 是一个原子操作,底层依赖于一条 CPU 的原子指令。
原子操作 即最小不可拆分的操作,也就是说操作一旦开始,就不能被打断,直到操作完成。
CAS 涉及到三个操作数:
- V:要更新的变量值(Var)
- E:预期值(Expected)
- N:拟写入的新值(New)
当且仅当 V 的值等于 E 时,CAS 通过原子方式用新值 N 来更新 V 的值。如果不等,说明已经有其它线程更新了 V,则当前线程放弃更新。
3.CAS的自旋
自旋: 就是不停的判断比较,看能否将值交换
在CAS操作中,自旋的概念指的是当线程发现无法立即完成操作时,不会让出CPU时间片,而是继续循环尝试,直到成功为止。这种机制可以避免线程频繁地挂起和恢复,减少了线程切换的开销,提高了效率。自旋锁通常适用于锁被占用的时间较短的场景,因为长时间的自旋会导致CPU资源的浪费。
总的来说,CAS的自旋是通过不断循环尝试来实现的一种锁优化机制,它在多线程编程中用于保证操作的原子性和提高性能。
4.CAS/乐观锁存在的问题(ABA)?
CAS 三大问题:
- ABA问题。CAS需要在操作值的时候检查内存值是否发生变化,没有发生变化才会更新内存值。但是如果内存值原来是A,后来变成了B,然后又变成了A,那么CAS进行检查时会发现值没有发生变化,但是实际上是有变化的。ABA问题的解决思路就是在变量前面添加版本号,每次变量更新的时候都把版本号加一,这样变化过程就从A-B-A变成了1A-2B-3A。JDK从1.5开始提供了AtomicStampedReference类来解决ABA问题,原子更新带有版本号的引用类型。
- 循环时间长开销大。CAS操作如果长时间不成功,会导致其一直自旋,给CPU带来非常大的开销。
- 只能保证一个共享变量的原子操作。对一个共享变量执行操作时,CAS能够保证原子操作,但是对多个共享变量操作时,CAS是无法保证操作的原子性的。
Theardlocal
1.什么是ThreadLocal
ThreadLocal为每个线程提供单独一份存储空间,具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问。
2. ThreadLocal的实现原理
在ThreadLocal中有一个内部类叫做ThreadLocalMap,类似于HashMap。ThreadLocal使用一个ThreadLocalMap来存储每个线程的变量副本,其中键为ThreadLocal实例,值为对应线程的变量副本。当一个线程创建一个 ThreadLocal变量时,实际上是在当前线程的ThreadLocalMap中存储了一个键值对。当一个线程访问ThreadLocal变量时,实际上是在访问该线程自己的变量副本,而不是共享变量。这样可以保证线程之间的数据隔离,避免了线程安全问题。
3.ThreadLocal内存泄露问题是怎么导致的?
每个线程都有一个ThreadLocalMap的内部属性,map的key是ThreaLocal,定义为弱引用,value是强引用类型。垃圾回收的时候会自动回收key,而value的回收取决于Thread对象的生命周期。一般会通过线程池的方式复用线程节省资源,这也就导致了线程对象的生命周期比较长,这样便一直存在一条强引用链的关系:Thread-->ThreadLocalMap-->Entry-->Value,随着任务的执行,value就有可能越来越多且无法释放,最终导致内存泄漏。
解决方法:每次使用完ThreadLocal就调用它的remove(),手动将对应的键值对删除,从而避免内存泄漏。
Java对象中的四种引用类型:强引用、软引用、弱引用、虚引用
- 强引用:最为普通的引用方式,表示一个对象处于有用且必须的状态,如果一个对象具有强引用,则GC并不会回收它。即便堆中内存不足了,宁可出现OOM,也不会对其进行回收
- 弱引用:表示一个对象处于可能有用且非必须的状态。在GC线程扫描内存区域时,一旦发现弱引用,就会回收到弱引用相关联的对象。对于弱引用的回收,无关内存区域是否足够,一旦发现则会被回收
4.ThreadLocal具体使用流程:
每次执行请求时拦截器将用户信息用set保存在ThreadLocal中,ThreadLocal每次调用set时是一个独立的线程,当另一个用户调用ThreadLocal的set时方法时,就会新建另一个线程,线程之间互不影响,当对应线程在调用get时候,就会请求到set时候的信息。在拦截器执行过后的方法中添加ThreadLocal线程remove()方法,这样每次请求结束后会将ThreadLocal线程中的数据删除,这样可以防止线程过多内存泄露
当用户登录并发起新的HTTP请求时,这个ID会通过以下步骤在请求线程内传递:
- 登录请求: 用户登录并发送登录请求。在登录请求的处理过程中,用户的ID被设置到
ThreadLocal中(BaseContext.setCurrentId(userId))。 - JWT生成: 登录成功后,生成包含用户ID的JWT,并发送给客户端。
- 新的HTTP请求: 用户使用JWT发起新的HTTP请求(例如查询地址信息的请求)。
- JWT验证: 在新的请求中,JWT首先被验证。如果验证成功,可以从JWT中提取用户ID。
- 设置
ThreadLocal: 在请求处理的某个阶段(通常是在拦截器或过滤器中),使用从JWT中提取的用户ID再次设置ThreadLocal(BaseContext.setCurrentId(userId))。 - 使用
ThreadLocal: 在请求的后续处理中(如控制器方法),可以通过BaseContext.getCurrentId()获取当前用户ID。
使用MD5加密方式对员工密码加密
我们项目对员工登录密码进行md5加密存储来保证安全性,食堂员工登陆的时候前端提交的密码进行MD5加密后再跟数据库中密码比对。
md5原理大概是这样的:可以将MD5算法看作一台机器,计算机的任何内容(字符串,图片,视频等)被丢进去都将输出一个长度为128比特的MD5值。
因此在我们这个项目中,会将食堂用户密码进行加密处理(密码末尾加随机的字符串)然后再进行MD5加密存入数据库。
MD5是否可逆:不可逆,原因是MD5是一种散列函数,使用的是hash算法,在计算过程中原文的部分信息是丢失了的。
Nginx负载均衡和反向代理
负载均衡:
Nginx 的负载均衡功能允许将请求分发给多个应用服务器,以均衡负载和提高系统的可扩展性和可靠性。下面是一些常用的 Nginx 负载均衡配置方法:
- 轮询(Round Robin):这是默认的负载均衡策略。Nginx 将请求依次分发给每个后端服务器,确保每个服务器都能获得相同的请求数量。
- IP 哈希(IP Hash):Nginx 使用客户端 IP 地址的哈希值来决定将请求发送给哪个后端服务器。这种方式可以确保同一客户端的请求始终发送到同一个后端服务器,适用于某些需要会话保持的场景。
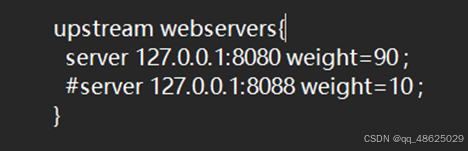
- 加权轮询(Weighted Round Robin):可以为每个后端服务器设置权重,高权重的服务器将获得更多的请求。这种方式可以根据服务器的性能和处理能力来分配负载。
- 最少连接(Least Connections):Nginx 根据当前连接数来选择最空闲的后端服务器,将请求发送给它。这样可以确保负载更均衡,避免某些服务器过载。
Nginx.conf文件中的一部分:通过这个Nginx就可以把请求分发给指定的多台服务器,并且我们也设置了权重。不过因为本次演示的是单机项目,我们只有一台电脑,因此我们把第二个地址注释了起来。
反向代理:
有反向代理就有正向代理,而二者的区别很明显:反向代理隐藏服务器,正向代理隐藏客户端。正向代理是客户端发送请求后通过代理服务器访问目标服务器,代理服务器代表客户端发送请求并将响应返回给客户端。正向代理隐藏了客户端的真实身份和位置信息,为客户端提供代理访问互联网的功能。
反向代理是位于目标服务器和客户端之间的代理服务器,它代表服务器接收客户端的请求并将请求转发到真正的目标服务器上,并将得到的响应返回给客户端。反向代理隐藏了服务器的真实身份和位置信息,客户端只知道与反向代理进行通信,而不知道真正的服务器。
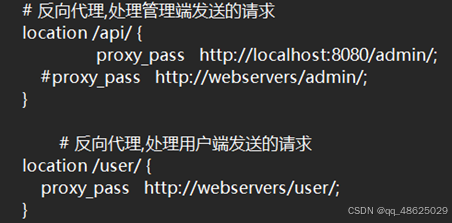
proxy_pass:用于设置反向代理的目标地址。在这个例子中,所有匹配/api/的请求将被转发到http://localhost:8080/admin/。这意味着,如果请求的原始URL是http://yourdomain.com/api/data,那么Nginx将把它转发到http://localhost:8080/admin/data。
指令将匹配/user/的请求转发到http://webservers/user/。例如,如果请求的原始URL是http://yourdomain.com/user/profile,那么Nginx将把它转发到http://webservers/user/profile
生成订单的时候,基于Redis使用Token+lua脚本进行幂等性校验,防止重复提交
1.什么是幂等性问题?
幂等性问题就是同一个接口,多次发出同一个请求,必须保证操作只执行一次。解决幂等性问题有很多方法,比如:用防重token,设置提交按钮一段时间只能提交一次,使用唯一索引防止新增脏数据等方法。
创建订单时,同时往订单表、订单商品表插数据,这些Insert须在同一事务执行。Order服务调用Pay服务,刚好网络超时,然后Order服务开始重试机制,于是Pay服务对同一支付请求,就接收到了两次,而且因为轮询负载均衡算法,落在了不同业务节点!所以一个分布式系统接口,须保证幂等性。
同一个订单号,只能支付一次
2.幂等性校验具体流程
生成订单时,为了防止重复提交,可以通过Redis结合防重Token和Lua脚本来实现幂等性校验。具体流程如下:
- 生成Token:用户发起请求时,服务端生成一个唯一的Token。就是在点完“结算”按钮之后,加载出来提交订单页面的过程中,后端生成一个唯一token,这样就能保证,每次点完结算后出来的页面,标识是唯一的,在同一个订单提交页面发出的请求,带有相同的token。
- 存储Token:将这个Token存入Redis中,以Token为键,可以设置一个过期时间来自动清理旧的Token,防止Redis内存溢出。
- 传递Token:将Token返回给客户端,客户端在后续的请求中需要携带这个Token,可以放在Header或者作为请求参数。
- 校验Token:服务端接收到请求后,从Redis中查询Token。这一步通常通过执行Lua脚本来完成,Lua脚本可以实现原子性的查询并删除操作,确保即使多个请求同时到达,也只有一个请求能够成功删除Token。
- 处理请求:如果Token存在且成功被删除,说明是第一次请求,服务器正常处理业务逻辑,如生成订单。如果Token不存在,说明是重复请求,服务器返回提示信息,如“请勿重复操作”。
- 删除Token:在处理完请求后,无论成功与否,都从Redis中删除该Token,避免后续的重复校验。
3.lua脚本
Lua脚本的具体写法如下:
if redis.call('exists', KEYS[1]) == 1
then return redis.call('del', KEYS[1])
else
return 0
end
这个Lua脚本的作用是检查Redis中是否存在指定的Token,如果存在则删除该Token并返回1,表示校验通过;如果不存在则返回0,表示校验失败。
在Redis中执行Lua脚本可以使用EVAL命令,具体语法如下:
EVAL script numkeys key [key ...] arg [arg ...]
其中,script是要执行的Lua脚本,numkeys是脚本中使用到的键的数量,key是传入的键名,arg是传入的参数。
例如,要执行上述Lua脚本,可以这样调用Redis命令:
EVAL "if redis.call('exists', KEYS[1]) == 1
then return redis.call('del', KEYS[1])
else return 0 end" 1 token_key
其中,token_key是要校验的Token的键名。
布隆过滤器
我们可以把数据库中的数据利用布隆过滤器标记出来,当用户请求缓存未命中时,先基于布隆过滤器判断。如果不存在则直接拒绝请求,存在则去查询数据库。尽管布隆过滤存在误差,但一般都在0.01%左右,可以大大减少数据库压力。
工厂模式和策略模式
- 工厂模式:关注于对象的创建,客户端代码不直接创建对象,而是通过工厂类来创建。在工厂模式中,客户端只需要知道传入工厂类的参数,而不需要关心对象的创建细节。
具体:创建布隆过滤器工厂类:其中包含一个用于创建布隆过滤器对象的工厂方法。工厂方法接受布隆过滤器的大小和哈希策略对象作为参数,并返回一个具体的布隆过滤器对象。使用布隆过滤器工厂:在需要创建布隆过滤器对象的地方,调用布隆过滤器工厂的工厂方法来创建布隆过滤器对象,并传入相应的哈希策略对象。
- 策略模式:关注于定义一系列可互相替换的算法,客户端代码在运行时可以根据需要选择具体的算法。策略模式将算法的选择与算法的实现分离开来,使得算法可以独立于使用它们的客户变化。
具体:创建一个具体的布隆过滤器类,实现布隆过滤器接口中的方法。在这个类中,需要定义布隆过滗器的数据结构(比如位数组)、大小等属性。定义一个哈希策略接口,包含计算哈希值的方法。创建多个具体的哈希策略类,实现哈希策略接口中的方法,每个类对应一种哈希函数的计算方法。
HttpClient微信登陆模块
Httpclient是一个服务器端进行HTTP通信的库,使后端可以发送各种HTTP请求和接收HTTP响应,使用HTTPClient,可发送GET\POST\PUT\DELETE等各种类型的的请求。
在我们的项目中,在进行微信登录开发时,后端在使用登录凭证校验接口的时候就需要发送指定请求到给定的URL中。因此我们使用Httpclient去完成该任务。
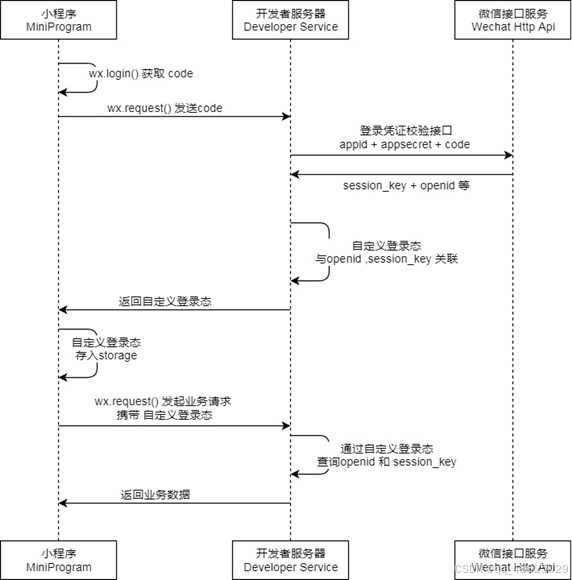
通过微信登录的流程:如果要完成微信登录的话,最终就要获得微信用户的openid。在小程序端获取授权码后,向后端服务发送请求,并携带授权码,这样后端服务在收到授权码后,就可以去请求微信接口服务。最终,后端向小程序返回openid和token等数据。Openid是wx提供的用户唯一标识。
- Login()方法:接收用户的登录信息,调用服务层的方法进行登录验证,然后生成JWT令牌,并将用户信息以及令牌封装在UserLoginVO对象中返回
JWT登录
业务逻辑:我们为已经登录的用户下发JWT令牌,后端拦截除了登录请求之外的所有请求,而前端每一次请求都要携带这个JWT令牌。后端对请求拦截后,要对请求中携带的JWT令牌进行处理,如果可以校验通过就放行请求,如果没有令牌或者解析错误,就返回登录界面
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断当前拦截到的是Controller的方法还是其他资源
if (!(handler instanceof HandlerMethod)) {
//当前拦截到的不是动态方法,直接放行
return true;
}
//1、从请求头中获取令牌
String token = request.getHeader(jwtProperties.getUserTokenName());
//2、校验令牌
try {
log.info("jwt校验:{}", token);
Claims claims = JwtUtil.parseJWT(jwtProperties.getUserSecretKey(), token);
Long userId = Long.valueOf(claims.get(JwtClaimsConstant.USER_ID).toString());
log.info("当前wx用户id:", userId);
BaseContext.setCurrentId(userId);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
}
JWT加密
JWT通常由三部分组成:Header(头部)、Payload(负载)和Signature(签名)。本项目中,Header包含了签名算法,Payload包含了过期时间和自定义声明,Signature是使用HS256算法和密钥生成的,签名用于验证令牌的完整性和可信任性。
/**
* 生成jwt
* 使用Hs256算法, 私匙使用固定秘钥
*
* @param secretKey jwt秘钥
* @param ttlMillis jwt过期时间(毫秒)
* @param claims 设置的信息
* @return
*/
public static String createJWT(String secretKey, long ttlMillis, Map<String, Object> claims) {
// 指定签名的时候使用的签名算法,也就是header那部分
SignatureAlgorithm signatureAlgorithm = SignatureAlgorithm.HS256;
// 生成JWT的时间
long expMillis = System.currentTimeMillis() + ttlMillis;
Date exp = new Date(expMillis);
// 设置jwt的body
JwtBuilder builder = Jwts.builder()
// 如果有私有声明,一定要先设置这个自己创建的私有的声明,这个是给builder的claim赋值,一旦写在标准的声明赋值之后,就是覆盖了那些标准的声明的
.setClaims(claims)
// 设置签名使用的签名算法和签名使用的秘钥
.signWith(signatureAlgorithm, secretKey.getBytes(StandardCharsets.UTF_8))
// 设置过期时间
.setExpiration(exp);
return builder.compact();
}JWT解密
/**
* Token解密
*
* @param secretKey jwt秘钥 此秘钥一定要保留好在服务端, 不能暴露出去, 否则sign就可以被伪造, 如果对接多个客户端建议改造成多个
* @param token 加密后的token
* @return
*/
public static Claims parseJWT(String secretKey, String token) {
// 得到DefaultJwtParser
Claims claims = Jwts.parser()
// 设置签名的秘钥
.setSigningKey(secretKey.getBytes(StandardCharsets.UTF_8))
// 设置需要解析的jwt
.parseClaimsJws(token).getBody();
return claims;
}JwtProperties.java用于存储JWT配置属性的类

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









