






爬取练习:
案例:表情包网站
先查看具体网页进行分析:
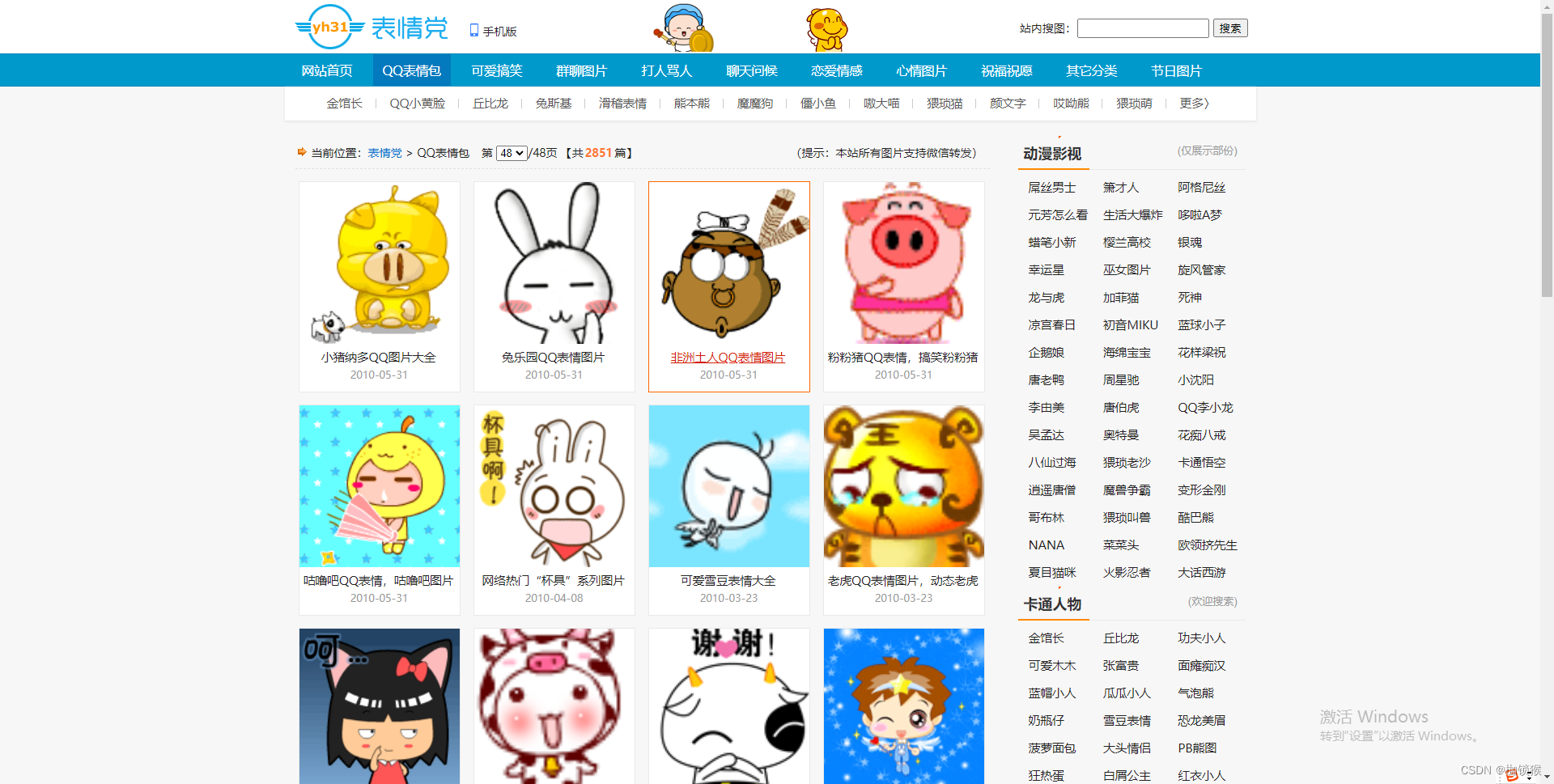

可以看到表情包下还有具体的页面,也就是我们想要爬取的表情了
爬取思路:1.爬取具体表情包下的图片——》2.进行封装后在爬取整个页面——》3.再次封装后爬取所有页面
下面展示一些 代码:
import os
import requests
from fake_useragent import UserAgent
from lxml import etree
#随机请求头
ua = UserAgent()
head = {
'user-agent': ua.chrome
}
#具体表情包页面爬取,进行封装,后面爬取整个页面
def xiangqing(url,mulu):
#地址
url = url
#请求
response = requests.get(url, headers=head).content.decode('utf-8')
#解析
html1 = etree.HTML(response)
#定位,定位的照片地址为:src="/tp/Photo7/ZJBQ/20105/201005311507104129.gif",后面需要进行处理一下
imgs = html1.xpath("//p//img/@src")
#创建空列表,后面处理照片地址和照片名称用
img = []
numbeers = []
#保存的目录
mulu =mulu
#创建文件夹,进行判断一下是否存在
if not os.path.exists(mulu):
os.mkdir(mulu)
#对定位的表情包进行处理
for i in imgs:
img.append('https://qq.yh31.com' + i)
#对表情包的名称进行处理
for i in range(1, len(img) + 1):
numbeers.append(i)
print('+++++++++++++++++++++++++++++地址:' + str(url) + '开始下载+++++++++++++++++++++++++++++')
#循环爬取表情包
for a, b in zip(img, numbeers):
responses = requests.get(a, headers=head)#请求下载
name = str(b) + '.gif'#表情包名称加后缀
with open(mulu + "/" + name, 'wb') as f:#保存到对应的文件夹
f.write(responses.content)
print('正在下载第' + str(b) + '张图片----------------')
print('+++++++++++++++++++++++++++++地址:' + str(url) + '下载完成+++++++++++++++++++++++++++++')
#表情包第一页爬取所有,进行封装,后面爬取所有页面用
def QQbiaoqing(number):
#地址
url = 'https://qq.yh31.com/zjbq/List_'+str(number)+'.html'
#发起请求
response = requests.get(url, headers=head).content.decode('utf-8')
html = etree.HTML(response)
#定位表情包地址,后面左右具体表情包的请求url
href = html.xpath("//div[@class='zj_tp']/a/@href")
#表情包的名称,后面作为文件夹名称使用
name = html.xpath("//div[@class='zj_tp']/a/img/@alt")
#一级和二级文件夹
mulu = 'QQ表情图片'
mulu1 = []
# 创建一级目录
if not os.path.exists(mulu):
os.mkdir(mulu)
# 创建二级目录
for i in name:
mulu1.append(mulu + '/' + i)
if not os.path.exists(mulu + '/' + i):
os.mkdir(mulu + '/' + i)
#调用xiangqing()进行循环请求保存,保存到各自的文件夹中
for a, b in zip(href, mulu1):
xiangqing(a,b)
#下载一页的所有表情
for i in range(1,2):
print('第'+str(i)+'页开始下载------------------------------------')
QQbiaoqing(i)
print('第'+str(i)+'页下载完成------------------------------------')
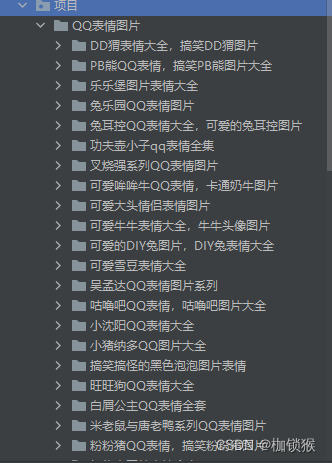
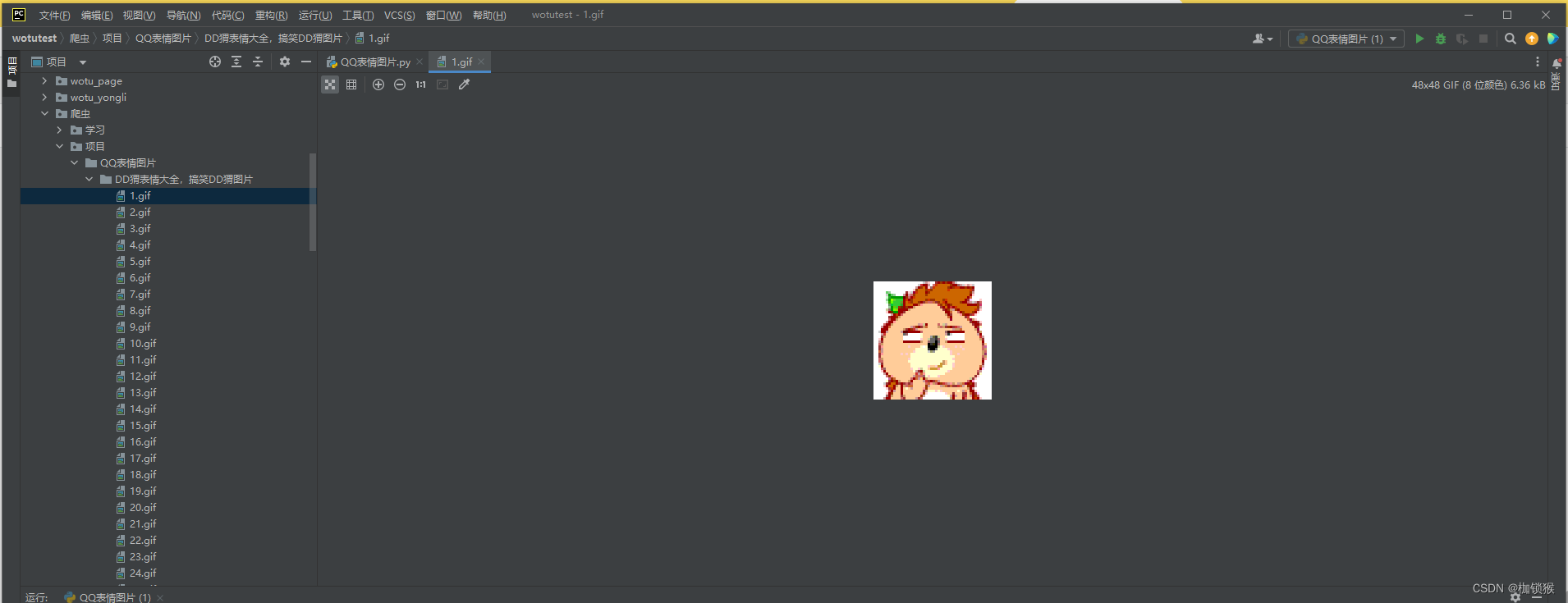
效果图:















 4579
4579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









