







前言
在企业级应用中,导入导出 Excel 文件是很常见的需求。通过使用自定义注解不仅可以实现灵活的 Excel 数据导入导出还可以减少手动配置的麻烦,提高代码的可读性和可维护性。本文记录了如何通过自定义注解来实现将实体类数据导出为 Excel 文件的过程,适合所有有相同需求的开发者学习和参考✍✍✍
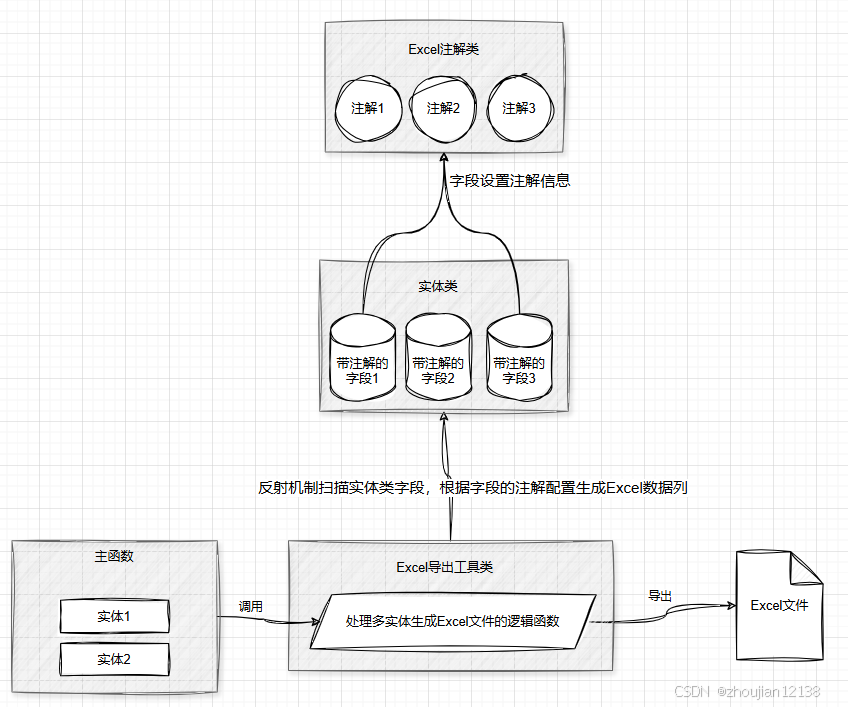
结构组成
自定义导出Excel注解编写类时,博主建议以模块化的思路来构建结构,博主以如下结构来组织,仅供大家参考
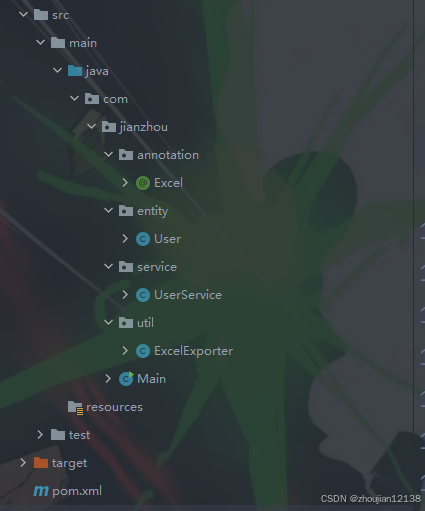
annotation用于存放自定义的注解,所有自定义的注解可以放在这里,其中创建一个Excel.java文件专门用于定义导出Excel的元数据entity用于存放实体类, 用于描述业务模型或数据结构。每个实体类可以和数据库表或导出的Excel表格列对应,创建一个User.java文件来加上@Excel注解util用于存放工具类,通常用于处理具体的操作逻辑,比如生成 Excel 文件、处理文件流等。这种工具类可以重复使用并且与具体业务逻辑分离,这里创建一个ExcelExporter.java用来实现 Excel 导出逻辑service用于存放服务类,负责核心业务逻辑,如从数据库获取数据或者对外提供 API 的功能。这里我们创建一个UserService.java负责定义用户数据并提供导出功能
定义自定义注解
我们首先创建一个自定义的注解 @Excel,用于标注需要导出到 Excel 文件中的字段。这个注解可以为每个字段提供额外的元数据,例如列名、列顺序、日期格式等。
小贴士:将
@Excel注解直接作用在实体类的字段上,用于指定字段的导出行为和格式 🤔
package com.jianzhou.annotation;
import org.apache.poi.ss.usermodel.HorizontalAlignment;
import org.apache.poi.ss.usermodel.IndexedColors;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* @BelongsProject: pmhub-learn
* @BelongsPackage: com.jianzhou.annotation
* @Author: ZJ
* @CreateTime: 2024-10-19 22:16
* @Description: 自定义导出Excel数据注解
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface Excel {
//Excel 列名
String name() default "";
//列的顺序
int sort() default Integer.MAX_VALUE;
//日期格式
String dateFormat() default "";
//列的宽度(单位是字符)
double width() default 16;
//是否需要合并单元格
boolean needMerge() default false;
// 单元格对齐方式
HorizontalAlignment align() default HorizontalAlignment.CENTER;
// 列头颜色
IndexedColors headerColor() default IndexedColors.WHITE;
// 单元格颜色
IndexedColors cellColor() default IndexedColors.BLACK;
}
在这个注解中博主定义了几个关键属性
| 属性 | 含义 |
|---|---|
| name | 导出的 Excel 列名 |
| sort | 列的顺序 |
| dateFormat | 日期格式化,适用于 Date 类型字段 |
| width | 列的宽度 |
| needMerge | 是否需要合并单元格 |
| align | 单元格的对齐方式 |
| headerColor | 列头的颜色 |
| cellColor | 单元格的颜色 |
@Retention(RetentionPolicy.RUNTIME) 和 @Target(ElementType.FIELD) 是两个元注解,它们分别控制自定义注解的生命周期和适用位置。
@Retention用于指定注解的 保留策略,即在代码的哪一个阶段能够获取到注解。RetentionPolicy是一个枚举类型,它定义了注解的三种保留策略,这里的@Retention(RetentionPolicy.RUNTIME)表示@Excel注解会保留到运行时,并且可以通过反射机制获取注解信息。在导出 Excel 时,我们正是通过反射读取这些注解的。
| RetentionPolicy保留策略 | 含义 | 用途 |
|---|---|---|
RetentionPolicy.SOURCE | 注解只会保留在源代码中,编译时就会被丢弃 | 注解@Override只用于代码检查或提高可读性,不会进入字节码文件 |
RetentionPolicy.CLASS | 注解会保留到编译后的 .class 文件中,但在运行时无法通过反射获取到它 | 常见于框架内部处理,这种注解仅在编译期间使用,不在运行时被访问 |
RetentionPolicy.RUNTIME | 注解不仅会保留到 .class 文件中,还能在运行时通过反射获取到 | 这种注解常用于需要在运行时动态获取注解信息的场景,例如 Spring、Hibernate 等框架广泛使用的注解 |
@Target用于指定注解可以作用在程序的哪些位置。ElementType是一个枚举,定义了注解可以应用的不同代码元素。这里的@Target(ElementType.FIELD)表示@Excel注解只能应用于 类的字段(Field) 上。也就是说,这个注解只能用在属性(字段)上,不能用在类、方法或构造函数等其他地方。
| 注解的可应用代码元素 | 含义 |
|---|---|
ElementType.TYPE | 类、接口(包括注解类型)或枚举声明 |
ElementType.FIELD | 字段声明(包括枚举常量) |
ElementType.METHOD | 方法声明 |
ElementType.PARAMETER | 参数声明 |
ElementType.CONSTRUCTOR | 构造函数声明 |
ElementType.LOCAL_VARIABLE | 局部变量声明 |
ElementType.ANNOTATION_TYPE | 注解类型声明 |
ElementType.PACKAGE | 包声明 |
ElementType.TYPE_PARAMETER | 类型参数(如泛型) |
ElementType.TYPE_USE | 可以用于所有的类型声明(如泛型、类声明、异常声明等) |
@interface 是 Java 中用来定义自定义注解的关键字。注解是一种特殊的接口,它允许我们为程序中的元素(如类、方法、字段等)添加元数据(metadata)。通过 @interface,我们可以自定义自己的注解,并使用这些注解来描述代码中的某些行为或特性。其中这样是定义注解的属性,default表示带有默认值的注解值,若没有定义默认值则使用注解时必须提供。
String name() default "";//带有默认值的属性
定义导出数据的实体
然后我们定义一个测试的用户实体类,代表需要导出数据的对象。在这个例子中,我们定义了一个 User 实体类,并在每个字段上加上 @Excel 注解来指定导出的配置。
提示:大家可以根据业务需求在实体类上加上自定义的
@Excel注解,来控制导出的格式
package com.jianzhou.entity;
import com.jianzhou.annotation.Excel;
import java.util.Date;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @BelongsProject: pmhub-learn
* @BelongsPackage: com.jianzhou.entity
* @Author: ZJ
* @CreateTime: 2024-10-19 22:16
* @Description: 定义用户实体数据
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
@Excel(name = "用户ID", sort = 1)
private Long userId;
@Excel(name = "用户名", sort = 2)
private String userName;
@Excel(name = "创建时间", dateFormat = "yyyy-MM-dd HH:mm:ss", sort = 3)
private Date createTime;
}
定义Excel导出逻辑
为了实现将实体类数据导出为 Excel 文件的功能,博主编写了 ExcelExporter 工具类。这个类使用反射机制获取实体类中 @Excel 注解的字段,并根据注解配置生成 Excel 文件🤔
package com.jianzhou.util;
import java.io.FileOutputStream;
import java.lang.reflect.Field;
import java.util.List;
import com.jianzhou.annotation.Excel;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
/**
* @BelongsProject: pmhub-learn
* @BelongsPackage: com.jianzhou.service
* @Author: ZJ
* @CreateTime: 2024-10-19 22:16
* @Description: 定义Excel导出逻辑
*/
public class ExcelExporter {
public static void exportExcel(List<?> data, Class<?> clazz, String filePath) throws Exception{
Workbook workbook = new XSSFWorkbook();
Sheet sheet = workbook.createSheet("Sheet1");
Row headerRow = sheet.createRow(0);
// 通过反射机制获取实体类clazz的所有字段信息并存储在Field数组中
Field[] fields = clazz.getDeclaredFields();
int colIdx = 0;
for (Field field : fields) {
if (field.isAnnotationPresent(Excel.class)) {//检查字段是否有 @Excel 注解
Excel excel = field.getAnnotation(Excel.class);//获取 @Excel 注解的实例以便访问注解的属性
Cell cell = headerRow.createCell(colIdx);//在表头行中创建一个单元格,colIdx 表示列的索引
cell.setCellValue(excel.name());//设置该列的名称为注解中的 name 属性值
/*
*设置该列的宽度,宽度基于注解中的 width 属性。256 是单位转换系数,因为 Apache POI 中宽度单位是 1/256 个字符
*/
sheet.setColumnWidth(colIdx, (int) (excel.width() * 256));
colIdx++;
}
}
// 填充数据
int rowIdx = 1;//从第二行开始填充数据,第一行是表头
for (Object obj : data) {//通过遍历每个对象,将其数据填充到对应的 Excel 行中
Row dataRow = sheet.createRow(rowIdx++);
colIdx = 0;
for (Field field : fields) {
if (field.isAnnotationPresent(Excel.class)) {
field.setAccessible(true); // 允许访问私有字段
Object value = field.get(obj);//通过反射获取该对象的字段值
Cell cell = dataRow.createCell(colIdx++);
if (value != null) {
cell.setCellValue(value.toString()); // 将字段值转换为字符串写入单元格
}
}
}
}
// 输出 Excel 文件
try (FileOutputStream fileOut = new FileOutputStream(filePath)) {
workbook.write(fileOut);
}
workbook.close();
}
}
定义导出服务
为了模拟数据,博主在 UserService 中定义了用户数据生成逻辑,并调用 ExcelExporter 工具类将用户数据导出为 Excel 文件🤔🤔🤔
package com.jianzhou.service;
import com.jianzhou.entity.User;
import com.jianzhou.util.ExcelExporter;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* @BelongsProject: pmhub-learn
* @BelongsPackage: com.jianzhou.service
* @Author: ZJ
* @CreateTime: 2024-10-19 22:16
* @Description: 定义导出服务
*/
public class UserService {
public List<User> getUsers() {
List<User> users = new ArrayList<>();
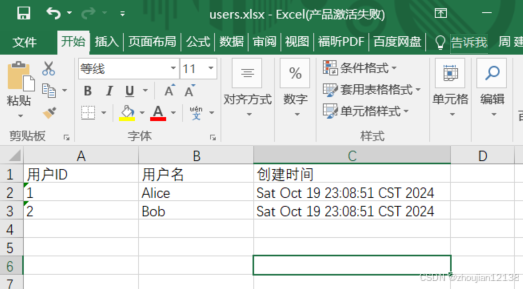
users.add(new User(1L, "Alice", new Date()));
users.add(new User(2L, "Bob", new Date()));
return users;
}
public void exportUsersToExcel(String filePath) throws Exception {
List<User> users = getUsers();
ExcelExporter.exportExcel(users, User.class, filePath);
}
}
注解验证
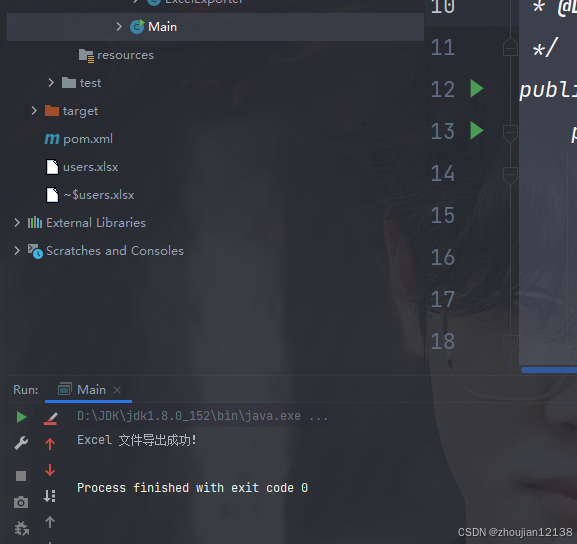
最后我们可以通过 Main 类验证整个注解和导出逻辑是否工作正常🤔🤔🤔
package com.jianzhou;
import com.jianzhou.service.UserService;
/**
* @BelongsProject: pmhub-learn
* @BelongsPackage: com.jianzhou
* @Author: ZJ
* @CreateTime: 2024-10-19 23:08
* @Description: 注解验证
*/
public class Main {
public static void main(String[] args) {
try {
UserService userService = new UserService();
userService.exportUsersToExcel("users.xlsx");
System.out.println("Excel 文件导出成功!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
总结
博主通过这篇文章展示了如何通过自定义注解简化 Excel 导出的开发过程。自定义注解不仅能让代码更加简洁,还能使代码具备高度的灵活性。在日常开发中,这种注解机制可以大大减少重复代码,同时让 Excel 导出操作更加直观和可控。希望这篇文章对大家有所帮助✊✊✊

















 2545
2545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









