






文章目录
项目描述
先通过nginx集群搭建一个静态web界面,搭建两台Nginx做负载均衡,同时利用 keepalived双vip互为主备来做高可用,使用kafka将它的访问日志收集,编写python脚本,通过URL接口解析日志中访问IP所属的省份、运营商、带宽以及访问时间最后将其存入数据库。
项目环境
centos7 kafka2.12 nginx1.21 filebeat zookeeper3.6.3 python3.6 mysql5.7 nfs4
项目步骤
1、设计好项目架构图
2、搭建好nginx集群,在集群中使用nfs将搭建的web静态界面共享,用于产生日志信息。
3、使用两台服务器做双vip的负载均衡器,互为主备,使用加权轮询的调度算法
4、搭建好kafka集群,设置多个partition,broker和replica实现高可用
5、部署zookeeper集群,用来保存kafka的源信息:topic,partition等
6、在nignx集群中安装filebeat,将日志收集到kafka集群中。
7、编写消费者,利用pymsql模块编写python脚本,将kafka的日志消费,存入mysql
8、安装prometheus,在nginx和kafka集群中安装exports,收集数据
9、安装grafana可视化工具,图形化展示监控的集群
设计架构图

下载nginx,搭建nginx集群,使用nfs实现web静态资源共享
1.服务器设置静态ip(注意点:将获取ip的dhcp改为BOOTPROTO=static。并且开启开机自启)
vim /etc/sysconfig/network-scripts/ifcfg-ens33
# 第一台
IPADDR="192.168.157.155"
NETMASK="255.255.255.0"
GATEWAY="192.168.157.2"
DNS1="114.114.114.114"
# 第二台
IPADDR="192.168.157.28"
NETMASK="255.255.255.0"
GATEWAY="192.168.157.2"
DNS1="114.114.114.114"
# 第三台
IPADDR=192.168.157.39
NETMASK=255.255.255.0
GATEWAY=192.168.157.2
DNS1=114.114.114.114
2.三台机器上nginx下载
yum install epel-release -y
yum install nginx -y
systemctl start nginx
systemctl enable nginx # 设置开机自启
3.nginx配置
vim /etc/nginx/nginx.conf
[root@kafka-3 nginx]# cd conf.d/
[root@kafka-3 conf.d]# ls
sc.conf
[root@kafka-3 conf.d]# cat sc.conf
server {
listen 80 default_server;
server_name www.sc.com;
root /usr/share/nginx/html;
access_log /var/log/nginx/sc/access.log main;
location / {
}
}
[root@kafka-3 conf.d]# cd /usr/share/nginx/
[root@kafka-3 nginx]# ls
html modules
[root@kafka-3 nginx]# cd html/
[root@kafka-3 html]# ls
404.html 50x.html en-US from.html icons img index.html lianx.html nginx-logo.png poweredby.png sc.html
[root@kafka-3 html]# cat sc.html
welcome
4.nfs下载及配置
# 将其中一台作为nfs服务器
安装: yum install nfs-utils
启动: systemctl start nfs
[root@kafka-3 nginx]# vim exportfs
/usr/share/nginx/html/ 192.168.157.0/24
[root@kafka-3 nginx]# systemctl restart nfs #重启nfs服务
# 在其他两台机器上进行nfs挂载
[root@kafka-1 ~]# mount 192.168.157.28:/usr/share/nginx/html/ /usr/share/nginx/html/
[root@kafka-2 ~]# mount 192.168.157.39:/usr/share/nginx/html/ /usr/share/nginx/html/
也就是说只要是修改主机的html下的文件,那么其他两台服务器上的也会被修改
使用两台服务器做双vip的负载均衡器
设计双vip
#192.168.157.162的主配置:
! Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.157.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
# vrrp_strict #严格遵守vrrp协议
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_http_port {
script "/opt/check_nginx.sh"
interval 2
weight -60
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 60
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_http_port
}
virtual_ipaddress {
192.168.157.253
}
}
vrrp_instance VI_2 {
state BACKUP #设置为备
interface ens33 #虚拟ip绑定到哪个网卡
virtual_router_id 61 #0-255#虚拟路由id 在同一个局域网内 来区分不同的keepalive集群 ,
#如果在同一个keepalive集群中,那每台主机的router id都是一样的
priority 50 #0-255优先级, 优先越高拿到虚拟ip的概率就会越大
advert_int 1 #隔1s钟发送一次存活检测
authentication { #认证方式
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { #设置虚拟ip
192.168.157.252
}
}
#192.168.157.160的主配置:
Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
# vrrp_strict #严格遵守vrrp协议
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state BACKUP #设置为备
interface ens33 #虚拟ip绑定到哪个网卡
virtual_router_id 60 #0-255#虚拟路由id 在同一个局域网内 来区分不同的keepalive集群 ,
#如果在同一个keepalive集群中,那每台主机的router id都是一样的
priority 50 #0-255优先级, 优先越高拿到虚拟ip的概率就会越大
advert_int 1 #隔1s钟发送一次存活检测
authentication { #认证方式
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { #设置虚拟ip
192.168.157.252
}
}
vrrp_instance VI_2 {
state MASTER #设置为备
interface ens33 #虚拟ip绑定到哪个网卡
virtual_router_id 61 #0-255#虚拟路由id 在同一个局域网内 来区分不同的keepalive集群 ,
#如果在同一个keepalive集群中,那每台主机的router id都是一样的
priority 100 #0-255优先级, 优先越高拿到虚拟ip的概率就会越大
advert_int 1 #隔1s钟发送一次存活检测
authentication { #认证方式
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { #设置虚拟ip
192.168.157.253
}
}
实现效果图:


设计负载均衡和反向代理
在本地的windows机器上添加域名对应的ip解析
C:\Windows\System32\drivers\etc 在这个目录下的hosts文件中,添加
192.168.157.160 www.sc.com
192.168.157.162 www.sc.com
在两台服务器上进行下面的操作(使用yum安装的nginx):
[root@localhost nginx]# vim /etc/nginx/nginx.conf
include stream_conf/*.conf;
http块中:
include conf.d/*.conf;
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
在conf.d文件下新建文件夹nginxproxy.conf
http {
# 定义一个新的变量用于存储客户端的真实IP地址
set_real_ip_from 0.0.0.0/0;
real_ip_header X-Real-IP;
real_ip_recursive on;
upstream sc {
server 192.168.157.160:5000 weight=1;
server 192.168.157.162:5000 weight=1;
}
server {
listen 80;
server_name www.sc.com;
location /sc/ {
# 使用$remote_addr获取客户端的真实IP地址
set $client_ip $remote_addr;
proxy_pass http://sc;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $client_ip; # 传递客户端的真实IP地址给目标服务器
}
}
}
部署kafka和zookeeper
我使用的是kafka2.12和zookeeper3.6.3,如果是kafka高版本的,kafka中已经有zookeeper,不需要下载。在三台机器上都下载kafka和zookeeper。
一些概念:
kafka是一种消息中间件,和其他MQ相比,有着单机10万级高吞吐量,高可用性强,分布式,一个partition多个replica,少数宕机不会丢失数据,一般配合大数据类系统进行实时数据计算,日志分析场景。
broker:kafka的节点。一台服务器相当于一个节点
topic:主题,消息的分类。比如nginx,mysql日志给不同的主题,就是不同的类型。
partition:分区。提高吞吐量,提高并发性。(多个partition会导致消息顺序混乱,如果对消息顺序有要求就只设置一个partition就可以了)
replica: 副本。完整的分区备份。
zookeeper是一种分布式应用协调管理服务,具有配置管理,域名管理,分布式数据存储,集群管理等功能,在本次项目中用于对kafka集群进行配置(topic,partition,replica等)管理。

1.配置kafka
在三台服务器中分别修改config /server.properties:
broker.id=0 #(kafka-1对应的broker.id=0 kafka-2对应的broker.id=1 kafka-2对应的broker.id=2)
listeners=PLAINTEXT://kafka-1:9092
zookeeper.connect=192.168.157.39:2181,192.168.157.28:2181,192.168.157.155:2181
2.配置zookeeper
cd /opt/apache-zookeeper-3.6.3-bin/confs
cp zoo_sample.cfg zoo.cfg
进入/opt/apache-zookeeper-3.6.3-bin/confs
cp zoo_sample.cfg zoo.cfg
修改zoo.cfg, 添加如下三行:
server.1=192.168.157.155:3888:4888
server.2=192.168.157.28:3888:4888
server.3=192.168.157.39:3888:4888
# 3888和4888都是端口 一个用于数据传输,一个用于检验存活性和选举
3.在三台服务器上添加myid
创建/tmp/zookeeper目录 ,在目录中添加myid文件,文件内容就是本机指定的zookeeper id内容
mkdir /tmp/zookeeper
如:在192.168.157.155机器上
echo 1 > /tmp/zookeeper/myid
echo 2 > /tmp/zookeeper/myid
echo 3 > /tmp/zookeeper/myid
4.启动kafka 和zookeeper并查看状态
bin/kafka-server-start.sh -daemon config/server.properties
bin/zkServer.sh start
bin/zkServer.sh status
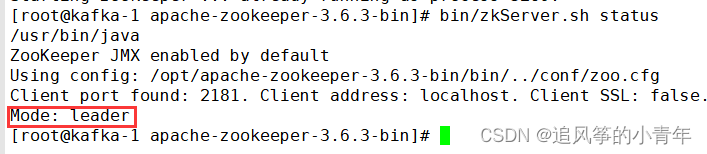

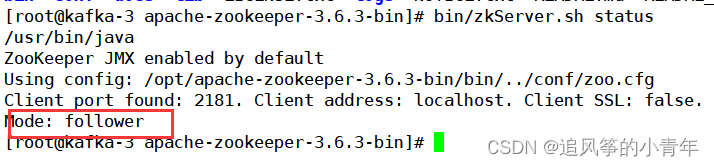
5.查看zookeeper的brokers的ids是否成功

6.测试
#创建生产者
bin/kafka-console-producer.sh --broker-list 192.168.157.39:9092 --topic sc
#创建消费者
bin/kafka-console-consumer.sh --bootstrap-server 192.168.157.155:9092 --topic sc --from-beginning


部署filebeat
Filebeat 是使用 Golang 实现的轻量型日志采集器,也是 Elasticsearch stack 里面的一员。本质上是一个 agent ,可以安装在各个节点上,根据配置读取对应位置的日志,并上报到相应的地方去。Filebeat 由两个主要组件组成:harvester 和 prospector。
采集器 harvester 的主要职责是读取单个文件的内容。读取每个文件,并将内容发送到 the output。 每个文件启动一个 harvester,harvester 负责打开和关闭文件,这意味着在运行时文件描述符保持打开状态。如果文件在读取时被删除或重命名,Filebeat 将继续读取文件。
查找器 prospector 的主要职责是管理 harvester 并找到所有要读取的文件来源。如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个 harvester。每个 prospector 都在自己的 Go 协程中运行。
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch # 安装相关包
# 编辑/etc/yum.repos.d/fb.repo文件
vim /etc/yum.repos.d/fb.repo
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
# yum安装
yum install filebeat -y
# 设置开机自启
systemctl enable filebeat
# 修改配置文件
vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/sc/access.log
#==========------------------------------kafka-----------------------------------
output.kafka:
hosts: ["192.168.157.39:9092","192.168.157.28:9092","192.168.157.155:9092"]
topic: nginxlog
keep_alive: 10s
# -------------------------------------------
#启动服务:
systemctl start filebeat
# 查看filebeat是否启动
ps -ef |grep filebeat

创建主题和消费者来检测数据
#创建主题nginxlog
bin/kafka-topics.sh --create --zookeeper 192.168.157.39:2181 --replication-factor 3 --partitions 1 --topic nginxlog
#创建消费者来检测日志是否生产过来
bin/kafka-console-consumer.sh --bootstrap-server 192.168.157.155:9092 --topic nginxlog --from-beginning
在浏览器中输入www.sc.com/sc.html,查看是否消费到了日志

编写python脚本将数据写入数据库中
import json
import requests
import time
import pymysql
from pykafka import KafkaClient
taobao_url = "https://ip.taobao.com/outGetIpInfo?accessKey=alibaba-inc&ip="
# 查询ip地址的信息(省份和运营商isp),通过taobao网的接口
def resolv_ip(ip):
response = requests.get(taobao_url + ip)
if response.status_code == 200:
tmp_dict = json.loads(response.text)
prov = tmp_dict["data"]["region"]
isp = tmp_dict["data"]["isp"]
return prov, isp
return None, None
# 将日志里读取的格式转换为我们指定的格式
def trans_time(dt):
# 把字符串转成时间格式
timeArray = time.strptime(dt, "%d/%b/%Y:%H:%M:%S")
# 把时间格式转成字符串
new_time = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return new_time
client = KafkaClient(hosts="192.168.157.155:9092,192.168.1.39:9092,192.168.157.28:9092")
topic = client.topics['nginxlog']
balanced_consumer = topic.get_balanced_consumer(
consumer_group='testgroup',
auto_commit_enable=True,
zookeeper_connect='kafka-1:2181,kafka-2:2181,kafka-3:2181'
)
for message in balanced_consumer:
if message is not None:
try:
line = json.loads(message.value.decode("utf-8"))
log = line["message"]
tmp_lst = log.split()
ip = tmp_lst[0]
dt = tmp_lst[3].replace("[", "")
bt = tmp_lst[9]
dt = trans_time(dt)
prov, isp = resolv_ip(ip)
if prov and isp:
print(prov, isp, dt)
db = pymysql.connect(host="192.168.157.39", user="sc", passwd="123456", port=3306, db="consumers",
charset="utf8")
cursor = db.cursor()
try:
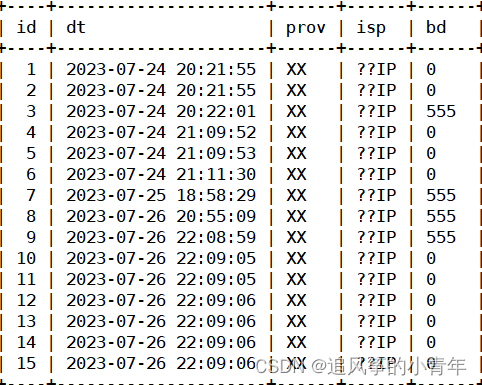
cursor.execute('insert into nginxlog2(dt,prov,isp,bd) values("%s","%s","%s","%s")' % (dt, prov, isp, bt))
db.commit()
print("保存成功")
except Exception as err:
print("修改失败", err)
db.rollback()
db.close()
except:
pass
使用prometheus进行监控
安装prometheus
新增一台服务器用于监控。我使用的版本是2.34.0
tar xf prometheus-2.34.0.linux-amd64.tar.gz # 解压
[root@yin-mysql prom]# ls
prometheus prometheus-2.34.0.linux-amd64.tar.gz
[root@yin-mysql prom]#
# 添加到环境变量
[root@yin-mysql prometheus]# PATH=/prom/prometheus:$PATH
[root@yin-mysql prometheus]# cat /root/.bashrc
# .bashrc
# User specific aliases and functions
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
PATH=/prom/prometheus:$PATH #添加
# 把prometheus做成一个服务来进行管理,非常方便
[root@yin-mysql prometheus]# vim /usr/lib/systemd/system/prometheus.service
[Unit]
Description=prometheus
[Service]
ExecStart=/prom/prometheus/prometheus --config.file=/prom/prometheus/prometheus.yml
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
systemctl daemon-reload # 重新加载systemd相关的服务
service prometheus start
查看prometheus是否启动
 在浏览器中输入192.168.157.164:9090
在浏览器中输入192.168.157.164:9090
在nginx集群和kafka集群中安装exports
我使用的是node_exporter-1.4.0-rc.0.linux-amd64.tar.gz
解压后:

[root@kafka-1 node_exporter]#
修改PATH变量
[root@kafka-1 node_exporter]# PATH=/node_exporter/:$PATH
[root@kafka-1 node_exporter]# vim /root/.bashrc
PATH=/node_exporter/:$PATH #添加
执行node exporter 代理程序agent
[root@kafka-1 node_exporter]#nohup node_exporter --web.listen-address 0.0.0.0:8090 &
查看是否启动:
 访问/metrics
访问/metrics
编辑prometheus.yml文件,添加node节点服务器
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "kafka-1"
static_configs:
- targets: ["192.168.157.155:8090"]
- job_name: "kafka-2"
static_configs:
- targets: ["192.168.157.28:8090"]
- job_name: "kafka-3"
static_configs:
- targets: ["192.168.157.39:8090"]
- job_name: "nginx-1"
static_configs:
- targets: ["192.168.157.163:8090"]
- job_name: "nginx-2"
static_configs:
- targets: ["192.168.157.160:8090"]
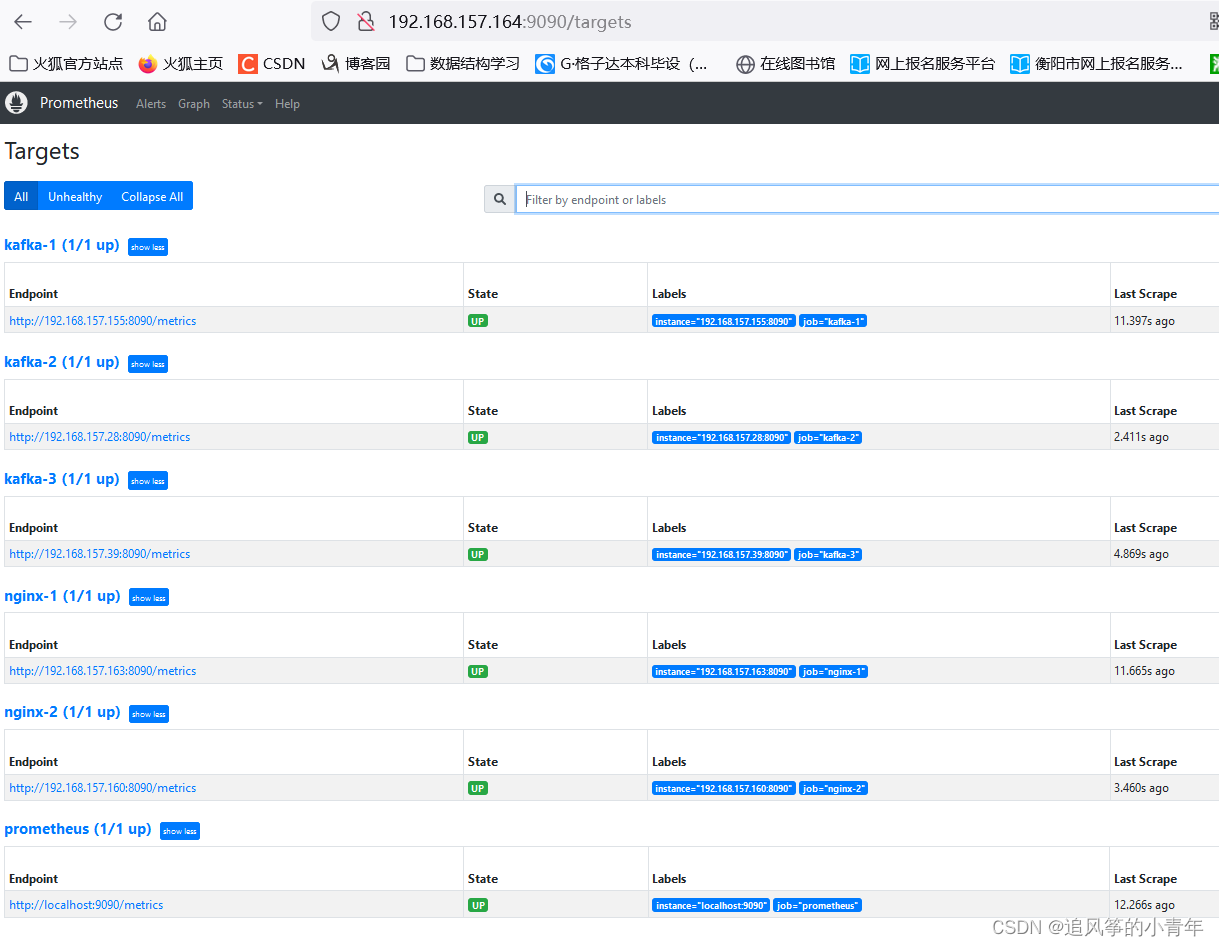
service prometheus restart
访问9090端口
安装grafana可视化工具
我使用的版本是10.1.1
概述–美观、强大的可视化监控指标展示工具。
grafana 是一款采用 go 语言编写的开源应用,主要用于大规模指标数据的可视化展现,是网络架构和应用分析中最流行的时序数据展示工具,目前已经支持绝大部分常用的时序数据库。最好的参考资料就是官网(http://docs.grafana.org/)
在prometheus的主机上安装grafana
使用yum安装grafana(因为使用的是清华源,直接使用yum安装无法安装,需要先获取公钥)
[root@yin-mysql yum.repos.d]# rpm --import https://packages.grafana.com/gpg.key
# 编辑grafana.repo文件在/etc/yum.repos.d目录下
[root@yin-mysql yum.repos.d]# cat grafana.repo
[grafana]
name=grafana
baseurl=https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/RPM-GPG-KEY-grafana
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
[root@yin-mysql yum.repos.d]# yum install grafana
service grafana-server start #启动
systemctl enable grafana-server #开机自启
查看监听端口

监控展示
浏览器中输入监听服务器的ip地址和端口:192.168.157.164:3000
默认的账号密码是:admin admin
添加一个数据

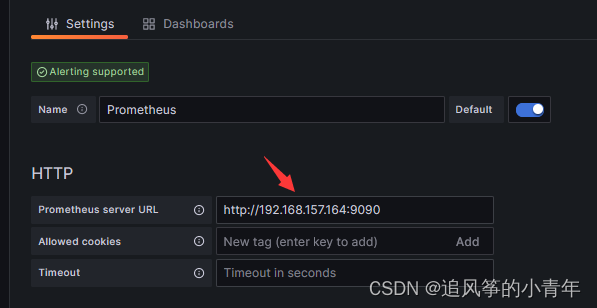
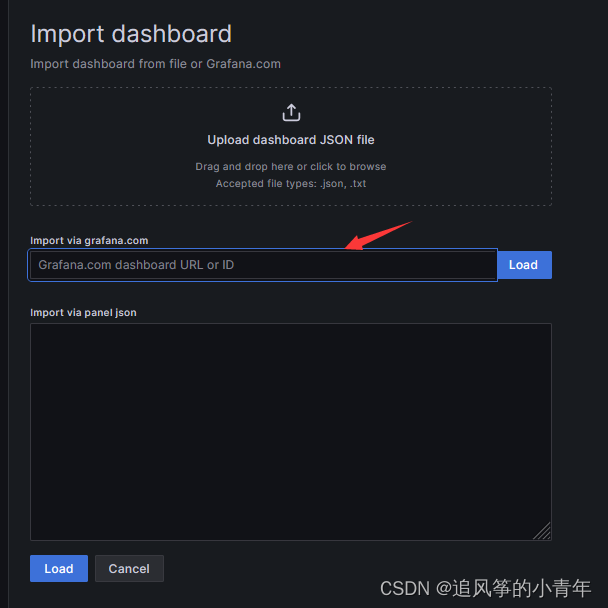
导入并输入一个中文监控的id号 8919,点击load即可加载
也可以选择去官方下载ashboard json file,然后本地上传dashboard json file
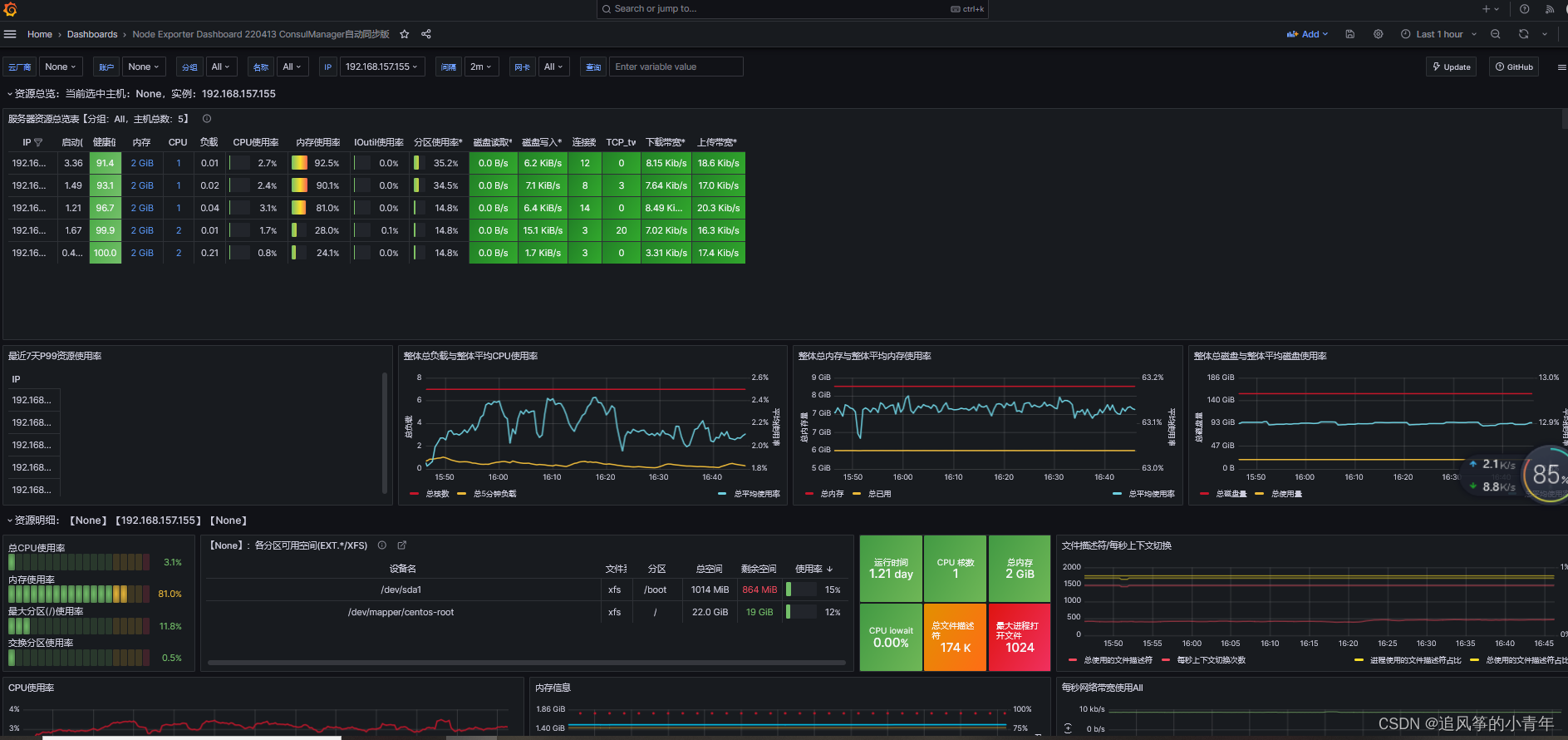
得到监控结果:
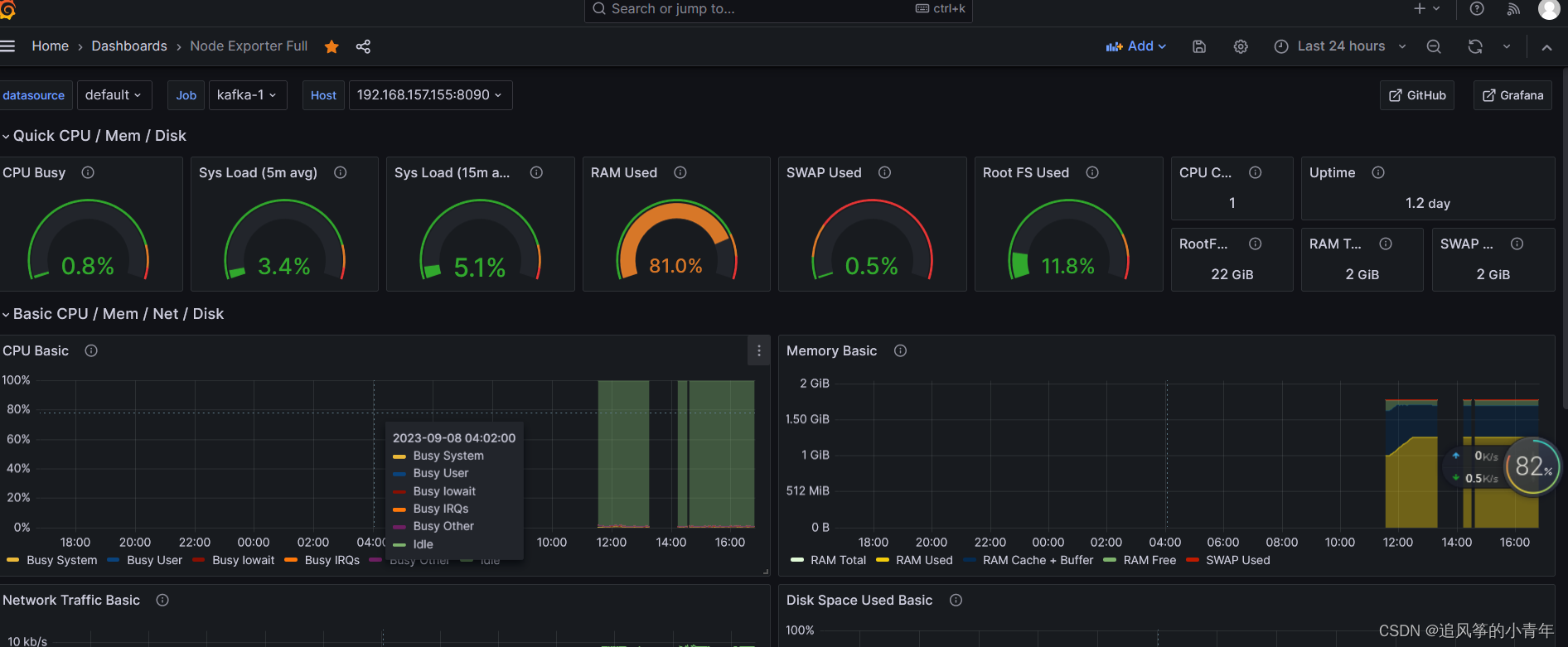
 也有另外一个好用的1860:
也有另外一个好用的1860:















 3818
3818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









