






 本文作者分享了3年来首次通过实际代码实现梯度下降算法的过程,使用PyTorch中的SGD优化器,观察并验证了参数更新和梯度的关系,证实了理论与实践的一致性。
本文作者分享了3年来首次通过实际代码实现梯度下降算法的过程,使用PyTorch中的SGD优化器,观察并验证了参数更新和梯度的关系,证实了理论与实践的一致性。
学深度学习有3年了叭,一直都知道梯度下降算法的公式:
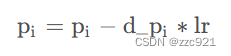
也是一直记着,用来理解和解释模型训练过程中遇到的现象,但是从来没有亲自扒开代码去看去佐证。然而,做科研的我们不是应该秉持科学精神去做实验室,去验证猜想嘛?抱着这个想法尝试去代码中寻找梯度下降算法
实验核心代码
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
用的是SGD优化器,因为这个优化器不是自适应的,对所有参数用的都是全局学习率,不会自适应去改变每个参数的学习率,如果是Adam优化器去验证梯度下降算法会麻烦很多,得找到Adam优化器把每个参数调整后的学习率放在什么地方了
下面实验中的模型用的pytorch搭建的
获取参数数值的方式:
model_parameters = model.state_dict()
c1_w1 = model_parameters.get('conv1.w1.weight').view(1, -1).tolist()[0]
c1_w1_list.append(c1_w1)
获取参数梯度的方式:
for name, param in model.named_parameters():
if name == 'conv1.w1.weight':
c1_w1_grad_list.append(param.grad.view(1, -1).tolist()[0])
实验结果

c1_w1是conv1的w1参数即卷积层1的卷积参数的意思
可以看到卷积层1的第一个卷积参数数值为:-0.5770044326782227(第一行,最左边)
卷积层1的第一个卷积参数数值更新后为:-3.125734390366208e+16(第二行,最左边)
loss值反向传播后,该参数的梯度为:1.0419115121316987e+18
学习率我设的是lr=0.03
刚好满足:
-3.125734390366208e+16 = -0.5770044326782227-0.03*1.0419115121316987e+18

欣慰,第一次在代码里实打实的看到梯度下降过程
与正在学习神经学习的各位分享~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









