






 文章探讨了深度学习模型在快速收敛时loss值突然增大的现象,发现这可能与Adam优化器的自适应学习率调整有关。作者观察到使用SGD、RMSprop或Adagrad等优化器时,loss值波动不同。
文章探讨了深度学习模型在快速收敛时loss值突然增大的现象,发现这可能与Adam优化器的自适应学习率调整有关。作者观察到使用SGD、RMSprop或Adagrad等优化器时,loss值波动不同。
深度学习模型训练快收敛时loss值突然暴增现象
自己深度学习模型训练快收敛时loss值突然暴增,我就记录下来了各个参数数值和梯度,并绘制了曲线图,供大家参考
自己用的是图卷积神经网络,3层,总共12个参量,也是特地参量设少点方便观察所有参量的参数
'conv1.w1.weight' 'conv1.w2.weight' 'conv1.w1.bias' 'conv1.w2.bias' 'conv2.w1.weight' 'conv2.w2.weight' 'conv2.w1.bias' 'conv2.w2.bias' 'conv3.w1.weight' 'conv3.w2.weight' 'conv3.w1.bias' 'conv3.w2.bias'
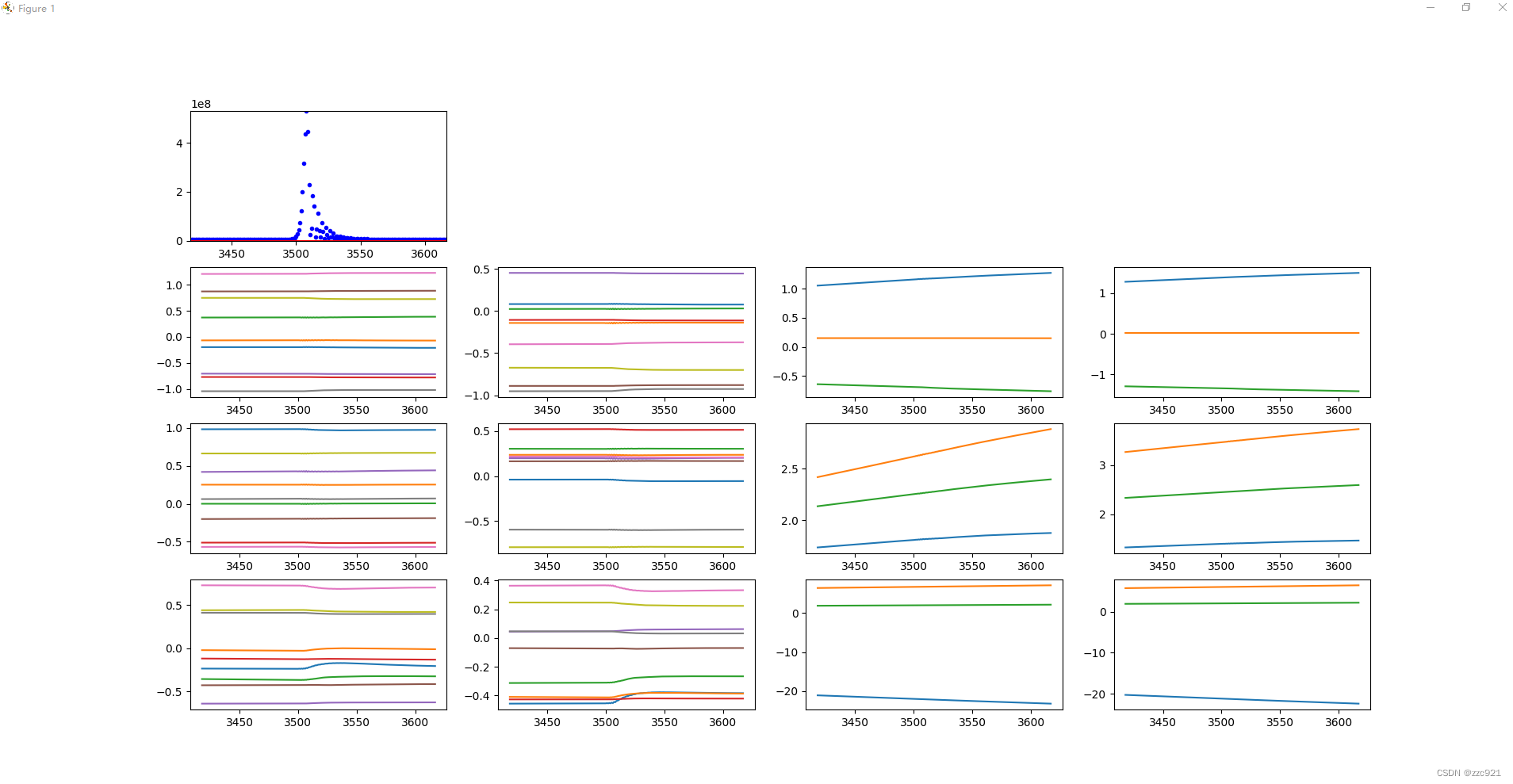
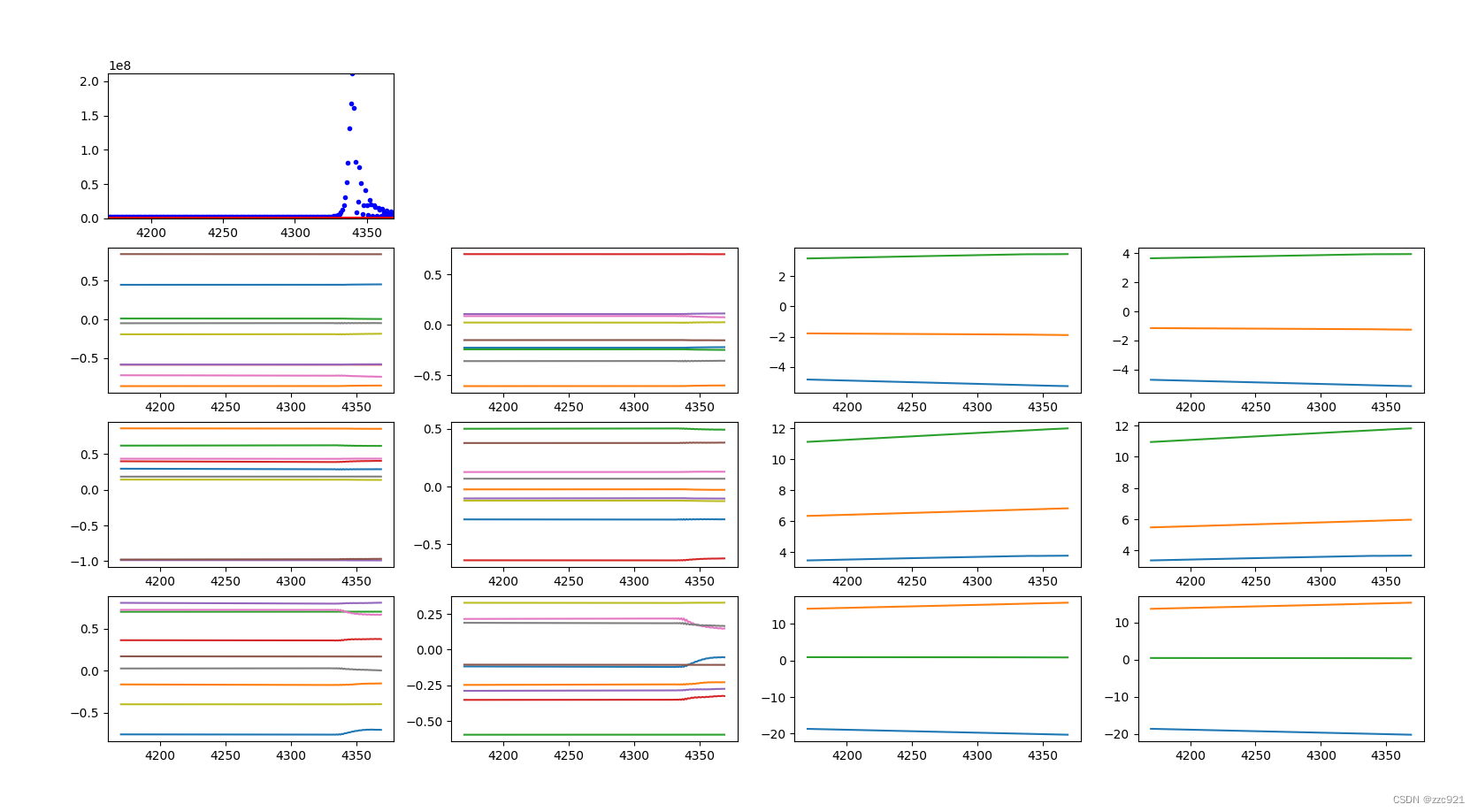
figure中多个子图每一行就是一个卷积层,分别是conv1,conv2,conv3,每一列分别是w1,w2,b1.b2
是和上面参数名称排列对应的
参数获取方式:
model_parameters = model.state_dict()
这样获取参数,然后plot
参数梯度获取方式:
for name, param in model.named_parameters():
if param.grad is not None:
print(f"{name}: {param.grad}")
else:
print(f"{name}: No gradient")
一、参数变化曲线:
1.正常状态:
epoch:0-150
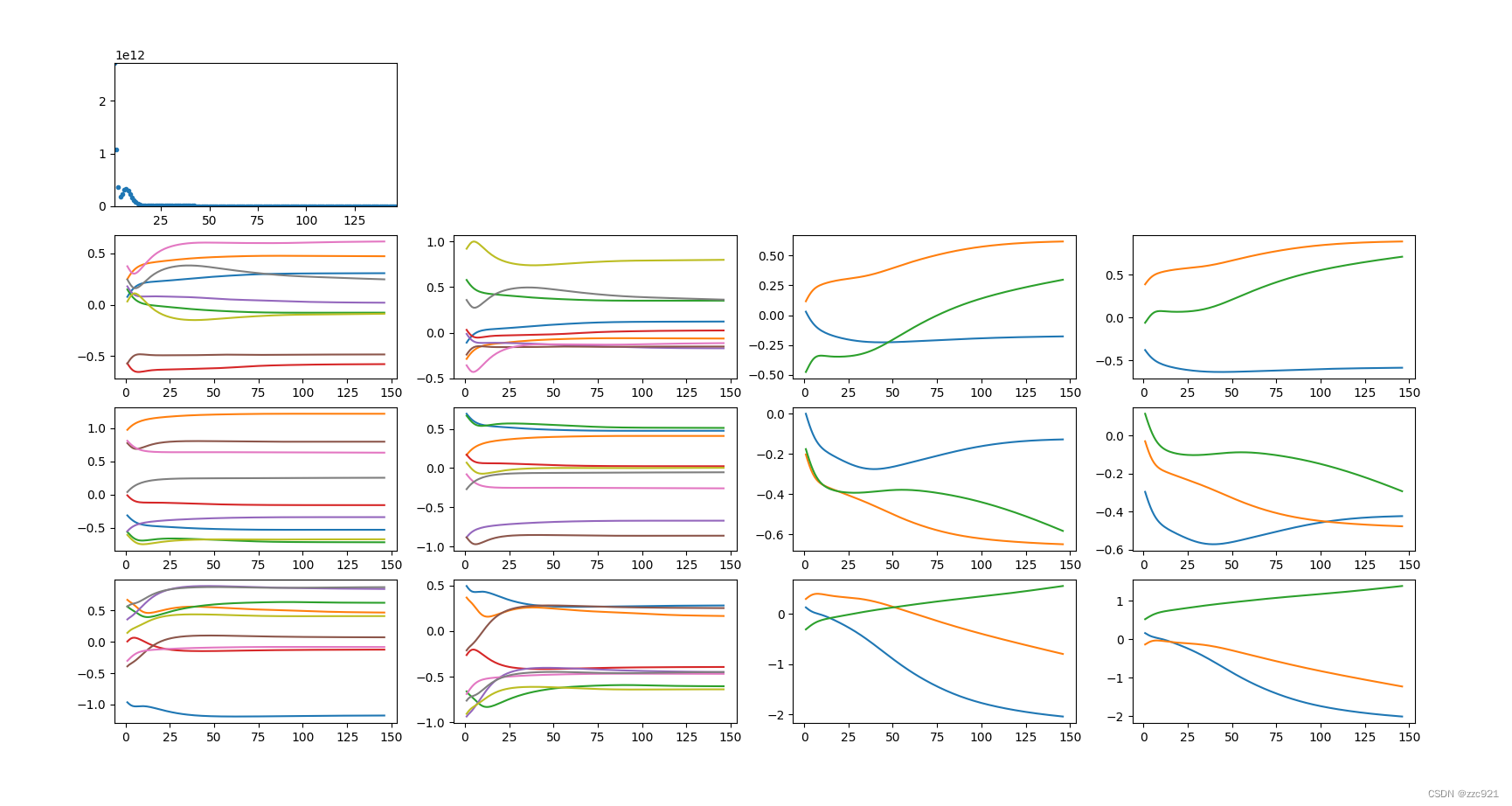
2.loss值突然变大时:
epoch:3400-3600
epoch:4150-4350
二、参数梯度变化曲线:
1.正常状态:
epoch:0-250
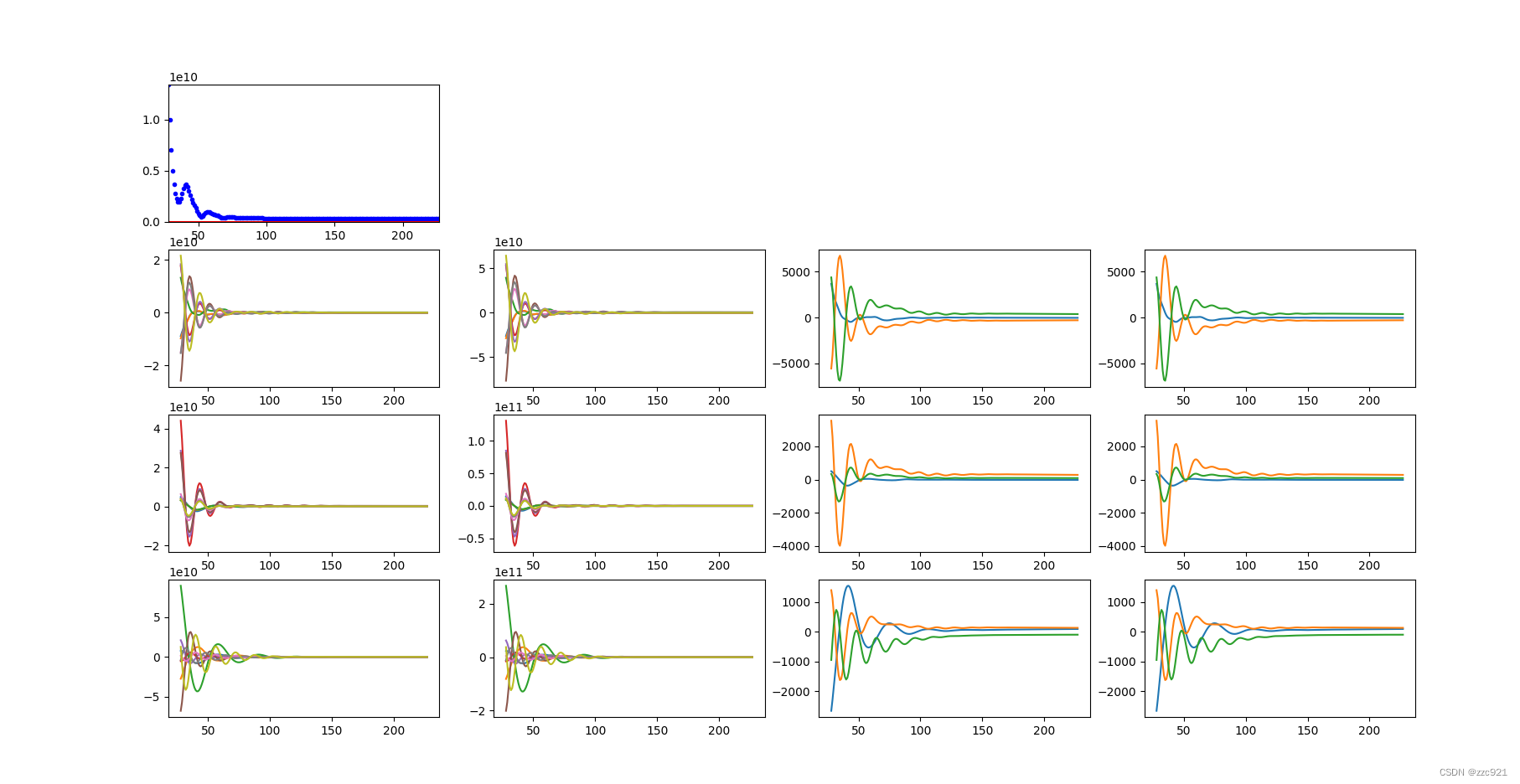
epoch:600-800
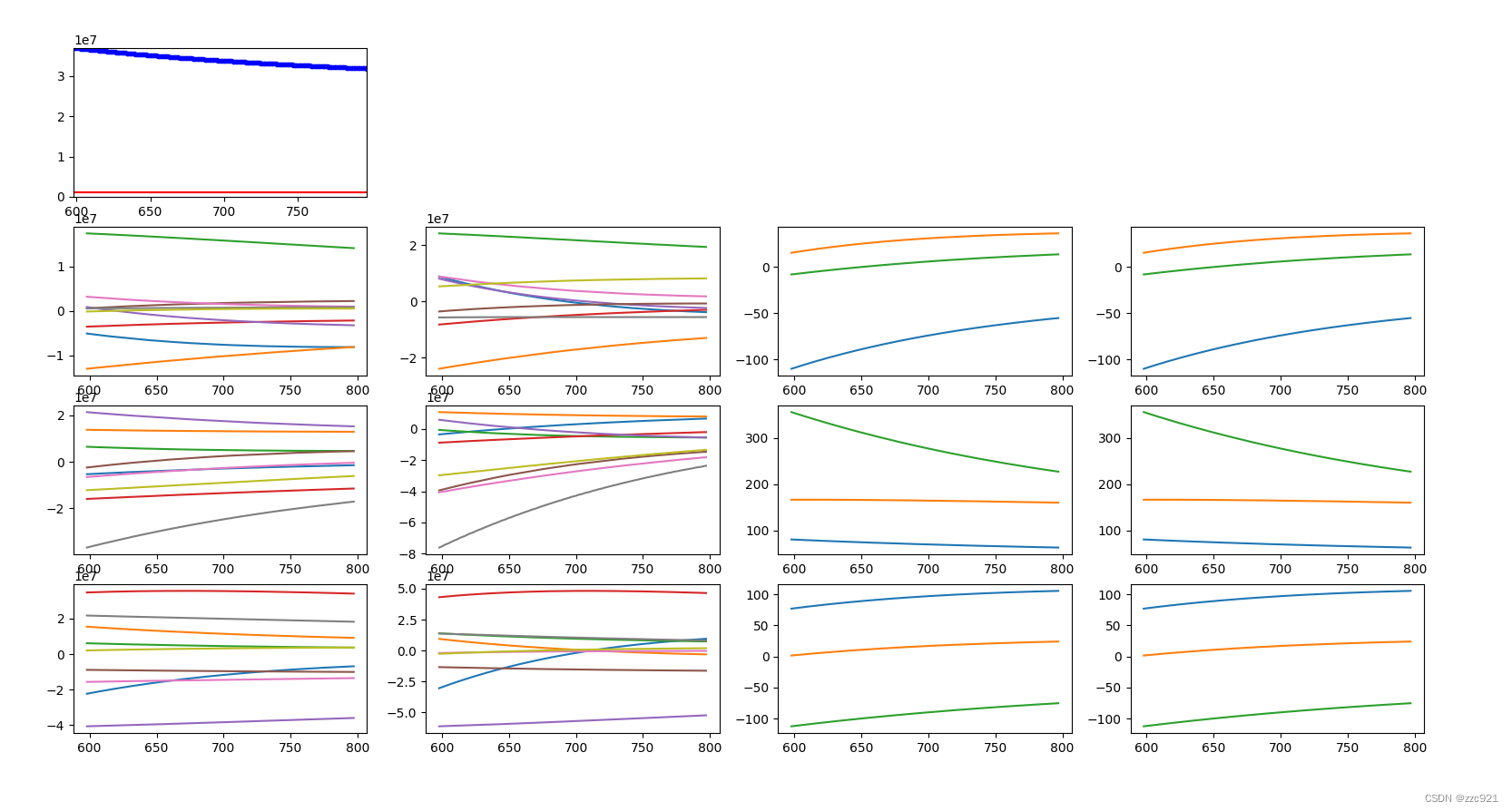
epoch:1000-1200
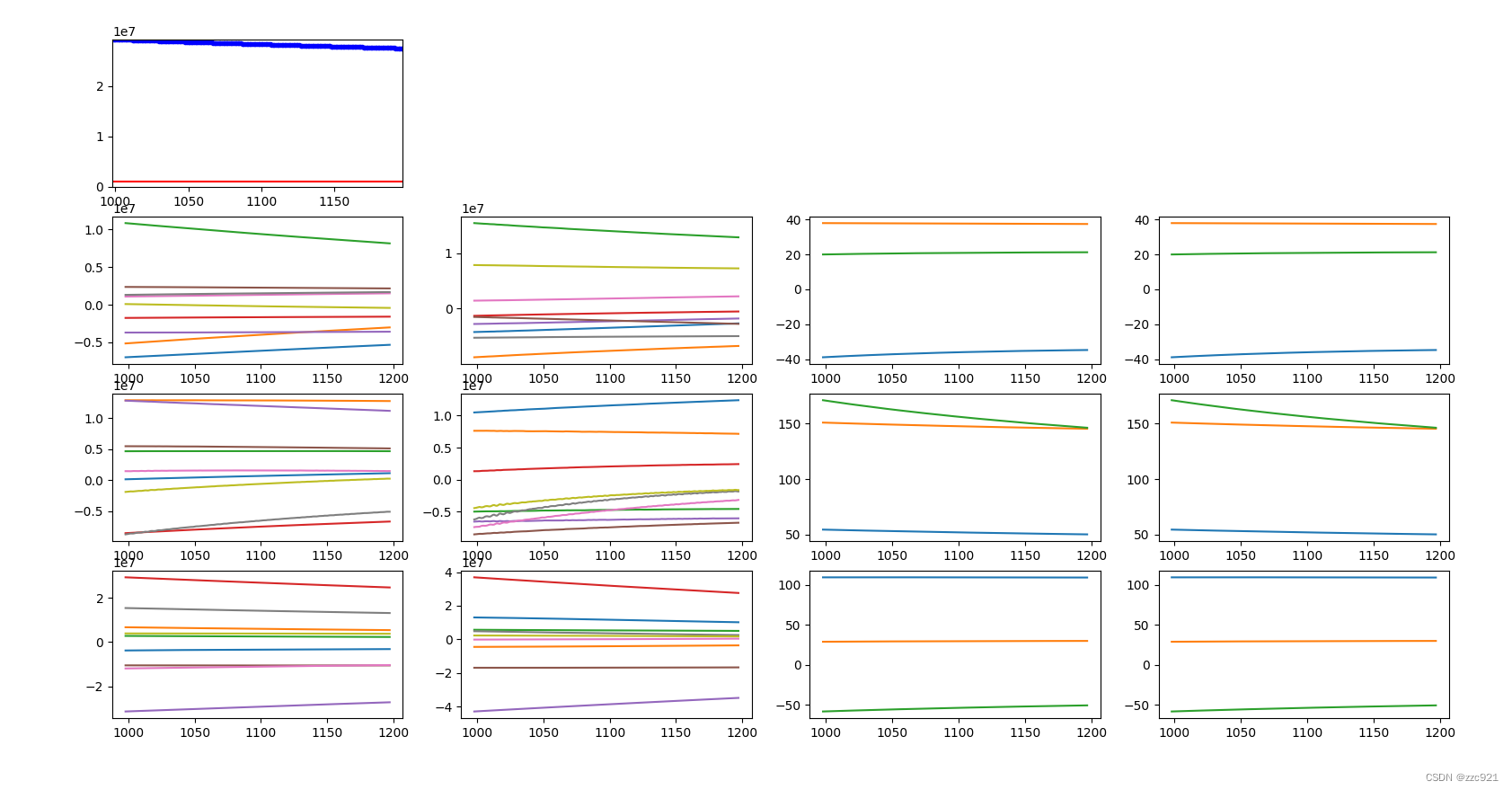
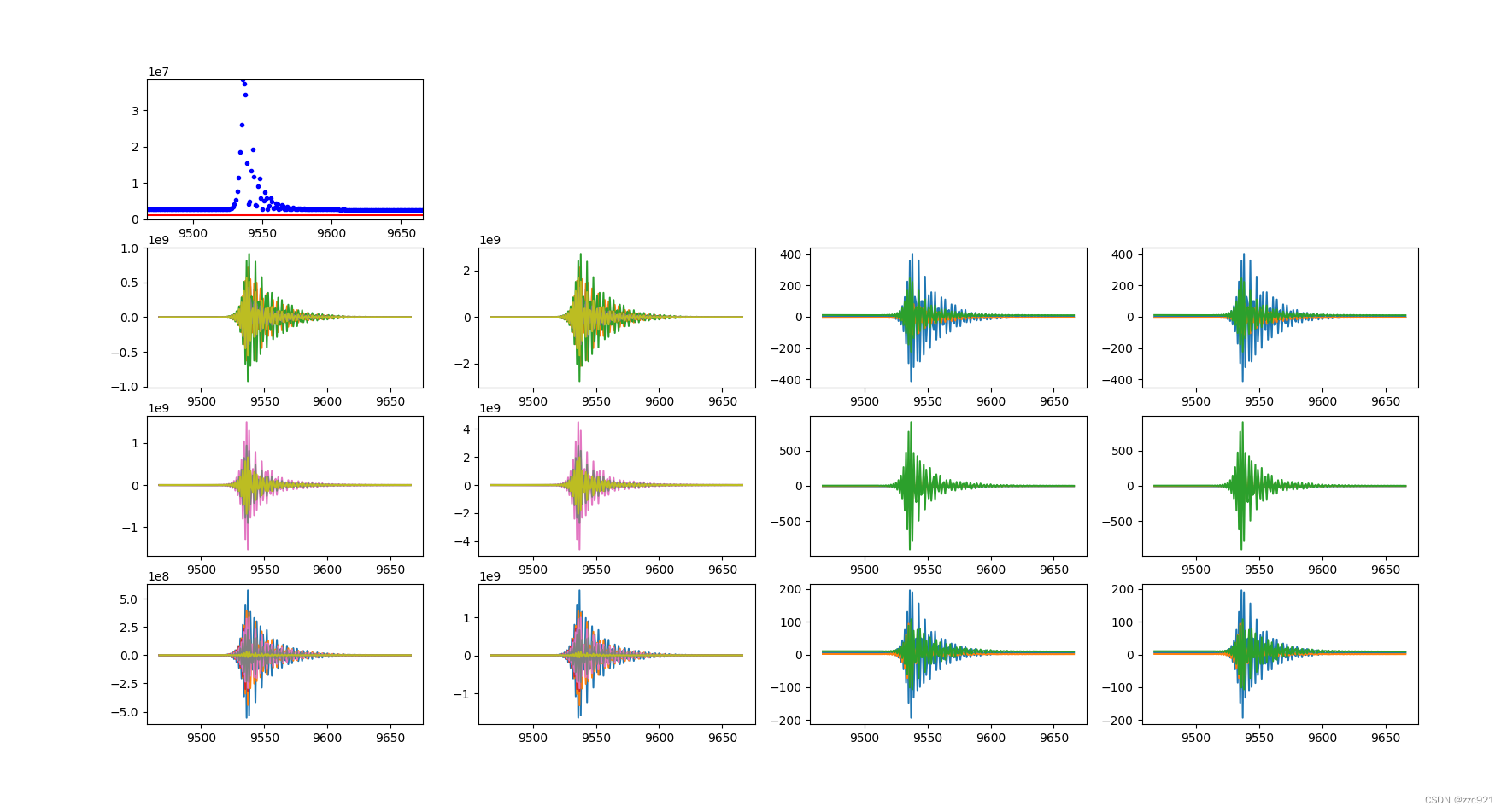
2.loss值突然变大时:
epoch:9450-9650
总结
微观上到底是怎么引起的loss值突然变大还不好说,可以看出相比于参数数值本身,梯度和loss值突然变大是有直接关系的,但是梯度又为什么会突然摆动呢?.........
目前发现这个好想和优化器选择是有关系的,我上面训练用的是Adam优化器,它的特点是会自适应调整每个参数的学习率,如果用其他优化器比如SGD/RMSprop/Adagrad不会出现上面loss值突然增大的现象,出现的是收敛时一直摆动像波浪一样的现象
# optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=0.9) # optimizer = torch.optim.RMSprop(model.parameters(), lr=lr) # optimizer = torch.optim.Adagrad(model.parameters(), lr=lr)
个人分析Adam优化器会自适应调整每个参数的学习率,快收敛时一定有某个参数最先到达一种状态,就是传递到它这的loss值很小了趋近0了,这个时候在Adam优化器作用下这个参数的学习率突然变大,打乱了该参数乃至整个模型的训练,loss值和梯度急剧振荡
这个其实也可以理解成optimizer的自我调整,有的时候loss值暴增后降下来会在暴增前最低值基础上继续降低,当然有的时候loss值暴增后再也不会出现暴增前的最低loss值了
还有待进一步挖掘观察...

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









