






最简单的线性分类器
公式
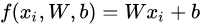
每个图像由32×32×3个像素,上述公式中把图像拉伸为一个3072×1的向量。W和b是参数,其中W是一个k×3072的矩阵(k表示类别数),被称为权重,b是一个k×1的偏执向量。
1,一个单独的矩阵乘法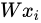 就高效地并行评估10个不同的分类器,其中每个类的分类器就是W的一个行向量。
就高效地并行评估10个不同的分类器,其中每个类的分类器就是W的一个行向量。
2,其中的参数是可以控制的,目的就是找到最合适的参数使得准确率做高。
3,数据驱动方式,就是利用训练集进行训练,找到做合适的参数,然后训练集就可以丢弃,只留下训练得到的参数。
理解线性分类器图例

图中是一个简单的例子,只有三个类别,并且图像也是简单的2×2×3的图片。把图片拉伸得到4×1的向量。W是3(对应的类别数)×4(对应的一张图片的像素),最后加上偏执向量得到这张图片对应的不同类别得到的分数。根据分数的大小对这个图片进行分类。上图分类器就有错误,把猫当成了狗。
**将图像看做高维度的点:**既然图像被伸展成为了一个高维度的列向量,那么我们可以把图像看做这个高维度空间中的一个点(即每张图像是3072维空间中的一个点)。整个数据集就是一个点的集合,每个点都带有1个分类标签。

既然定义每个分类类别的分值是权重和图像的矩阵乘,那么每个分类类别的分数就是这个空间中的一个线性函数的函数值。我们没办法可视化3072维空间中的线性函数,但假设把这些维度挤压到二维,那么就可以看看这些分类器在做什么了:
从上面可以看到,W的每一行都是一个分类类别的分类器。对于这些数字的几何解释是:如果改变其中一行的数字,会看见分类器在空间中对应的直线开始向着不同方向旋转。而偏差b,则允许分类器对应的直线平移。需要注意的是,如果没有偏差,无论权重如何,在Xi = 0时分类分值始终为0。这样所有分类器的线都不得不穿过原点,显然是不应该的。
权重和偏执是可以合并的

损失函数 Loss function
利用损失函数来衡量结果的好坏,损失函数的结果取指范伟是0~无穷大损失函数得到的结果越大说明结果不够好,结果为0表示好。
SVM的损失函数
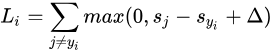
公式的具体用法

例子中▲取值是1,这个值也是一个超参数,可以根据不同的实验自己取值。取值为1 的含义就是,分类正确的分数要比分类错误得到的分数高1,这样得到的损失值才能最好。
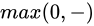
这个函数它常被称为折叶损失(hinge loss)。有时候会听到人们使用平方折叶损失SVM(即L2-SVM),它使用的是
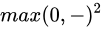
将更强烈(平方地而不是线性地)地惩罚过界的边界值。
正则化(Regularization):
还不太理解
Softmax分类器
公式如下:
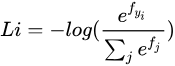
例子:

SVM和Softmax的比较

两个分类器都计算了同样的分值向量f(本节中是通过矩阵乘来实现)。不同之处在于对f中分值的解释:SVM分类器将它们看做是分类评分,它的损失函数鼓励正确的分类(本例中是蓝色的类别2)的分值比其他分类的分值高出至少一个边界值。Softmax分类器将这些数值看做是每个分类没有归一化的对数概率,鼓励正确分类的归一化的对数概率变高,其余的变低。SVM的最终的损失值是1.58,Softmax的最终的损失值是0.452,但要注意这两个数值没有可比性。只在给定同样数据,在同样的分类器的损失值计算中,它们才有意义。















 2373
2373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









