







1.检视网页 爬虫 要看是否允许爬取
- 进入页面,输入python进行搜索,查看源码
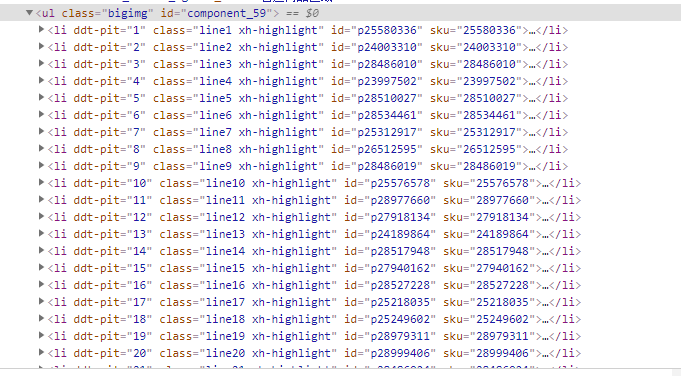
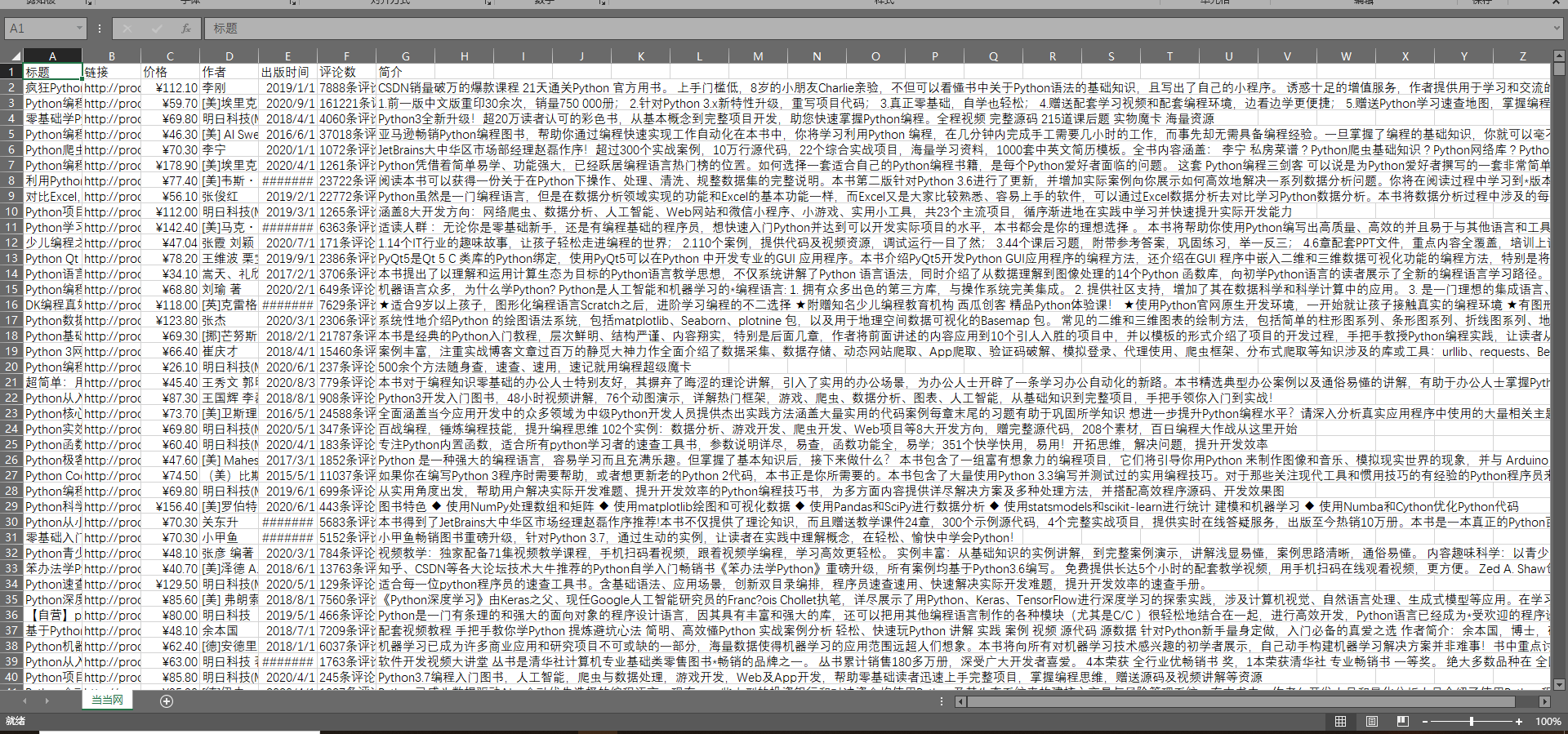
- xpth查看,//ul[@class="bigimg"]/li,里面包含的是全部的信息,我们需要将标题'链接,价格,作者,出版时间,评论数,简介全部分类爬取

- 标题 尝试2页
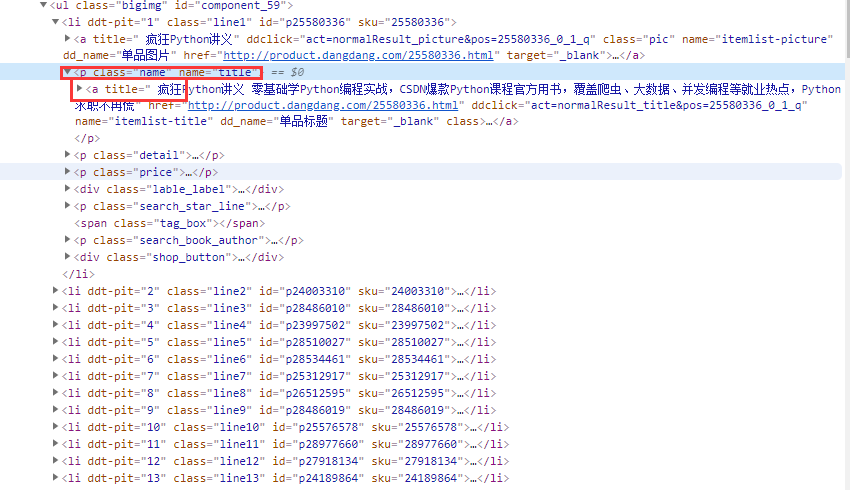

def parse_page(response):
tree = etree.HTML(response.text)
li_list = tree.xpath('//ul[@class="bigimg"]/li')
# print(len(li_list)) # 测试
for li in li_list:
data = []
time.sleep(.5)
# 获取书的标题,并添加到列表中
title = li.xpath('./p[@class="name"]/a/@title')[0].strip()
data.append(title)
print(title)
- 同理,爬取价格,作者,出版时间,评论数
for li in li_list:
data = []
# 获取书的标题,并添加到列表中 title = li.xpath('./p[@class="name"]/a/@title')[0].strip()
data.append(title)
# 获取商品链接,并添加到列表中 commodity_url = li.xpath('./p[@class="name"]/a/@href')[0]
data.append(commodity_url)
# 获取价格,并添加到列表中 price = li.xpath('./p[@class="price"]/span[1]/text()')[0]
data.append(price)
# 获取作者,并添加到列表中 author = ''.join(li.xpath('./p[@class="search_book_author"]/span[1]//text()')).strip()
data.append(author)
# 获取出版时间,并添加到列表中 time = li.xpath('./p[@class="search_book_author"]/span[2]/text()')[0]
pub_time = re.sub('/','',time).strip()
data.append(pub_time)
# 获取评论数,并添加到列表中 comment_count = li.xpath('./p[@class="search_star_line"]/a/text()')[0]
# 获取书本的简介,并添加到列表中.由于有些书本没有简介,所以要用try commodity_detail = '' commodity_detail = li.xpath('./p[@class="detail"]/text()')[0]
data.append(commodity_detail)
- 标题 尝试2页
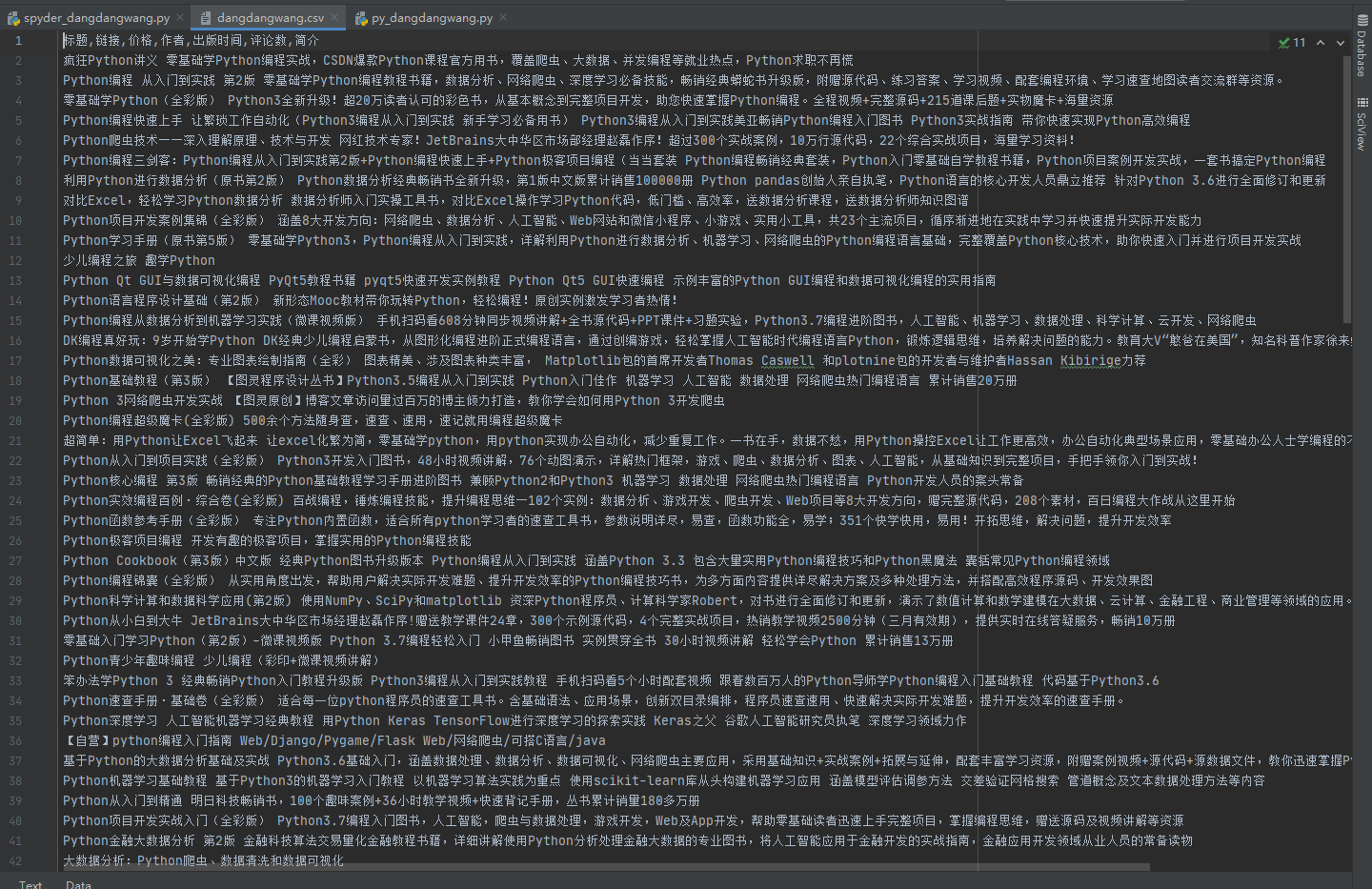
- 查看csv文件
-
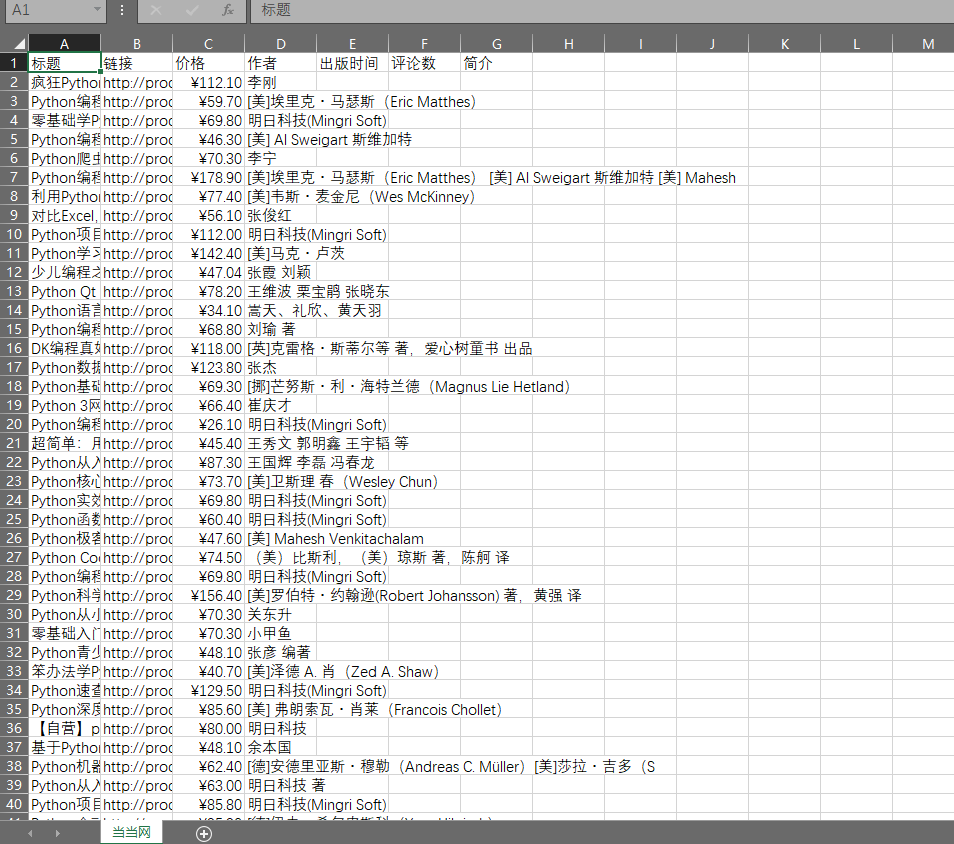
- xpth查看,//ul[@class="bigimg"]/li,里面包含的是全部的信息,我们需要将标题'链接,价格,作者,出版时间,评论数,简介全部分类爬取
- 全部爬取
- 最终简化代码
import requests
from lxml import etree
import csv
import re
def get_page(key):
for page in range(1,101):
url = '%s-当当网 % (key,page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' }
response = requests.get(url = url,headers = headers)
parse_page(response)
print('page %s over!!!' % page)
def parse_page(response):
tree = etree.HTML(response.text)
li_list = tree.xpath('//ul[@class="bigimg"]/li')
# print(len(li_list)) # 测试 for li in li_list:
data = []
try:
# 获取书的标题,并添加到列表中 title = li.xpath('./p[@class="name"]/a/@title')[0].strip()
data.append(title)
# 获取商品链接,并添加到列表中 commodity_url = li.xpath('./p[@class="name"]/a/@href')[0]
data.append(commodity_url)
- 最终简化代码
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2364
2364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









