





- 爬取网站动漫 - 腾讯动漫官方网站 - 首页
- 漫画强势推荐
- 初步分析
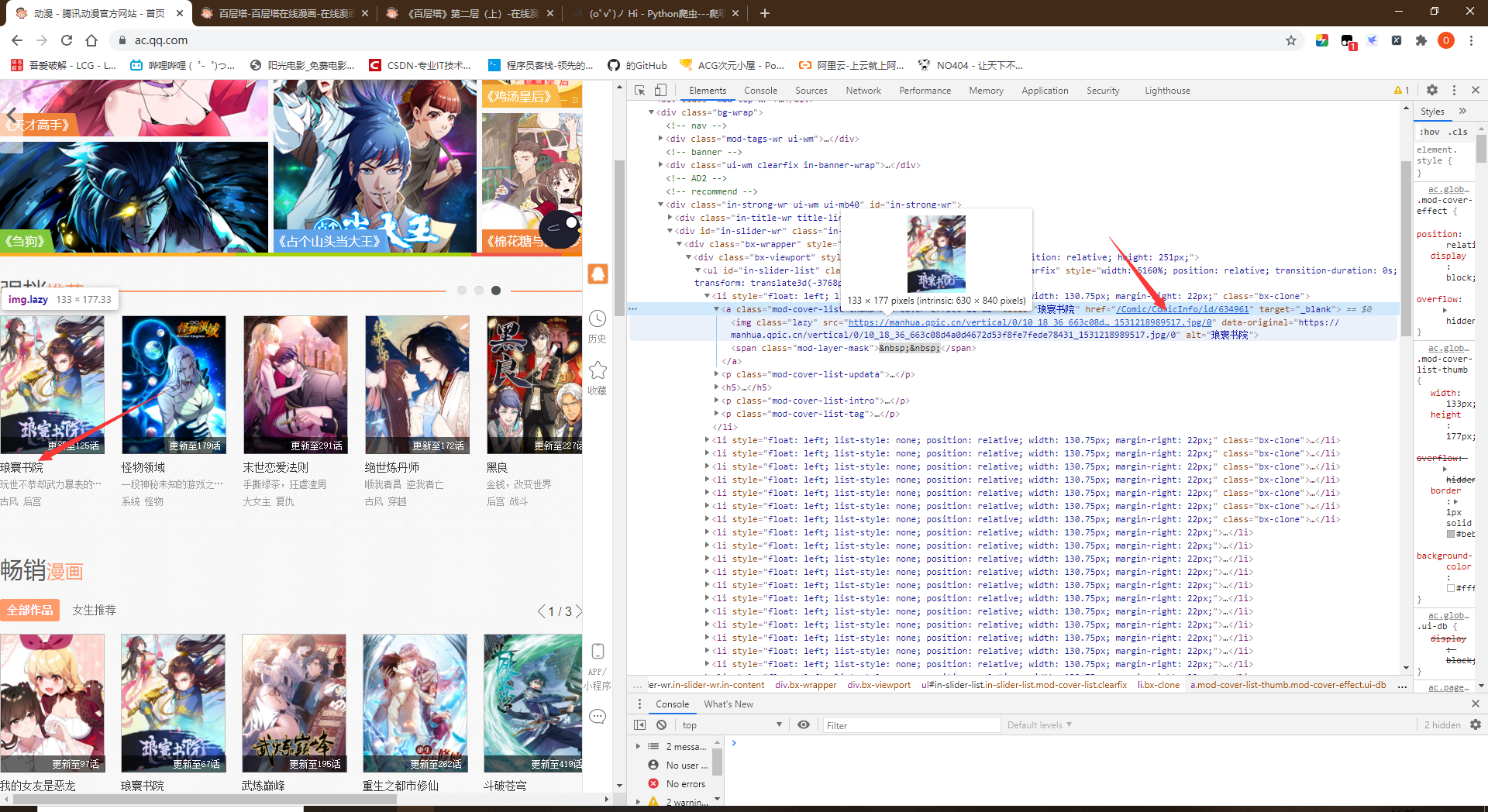
- 所有漫画的链接都在<li>中,链接都为错误提示 - 腾讯动漫"编码"
- 进入漫画,分析页面

- 所有的漫画章节链接都在一个页面中全部被包含。1个<li>包含5个<pi>,1个<pi>包含4个<span>,1个<span>中存储一个章节。所以1个<li>对应腾讯漫画每20个一组的分组
- 漫画强势推荐
- 目前已经获取了单个漫画的每个章节的链接地址,下一步是分析保存图片
- 进入某一章节中,分析图片的地址
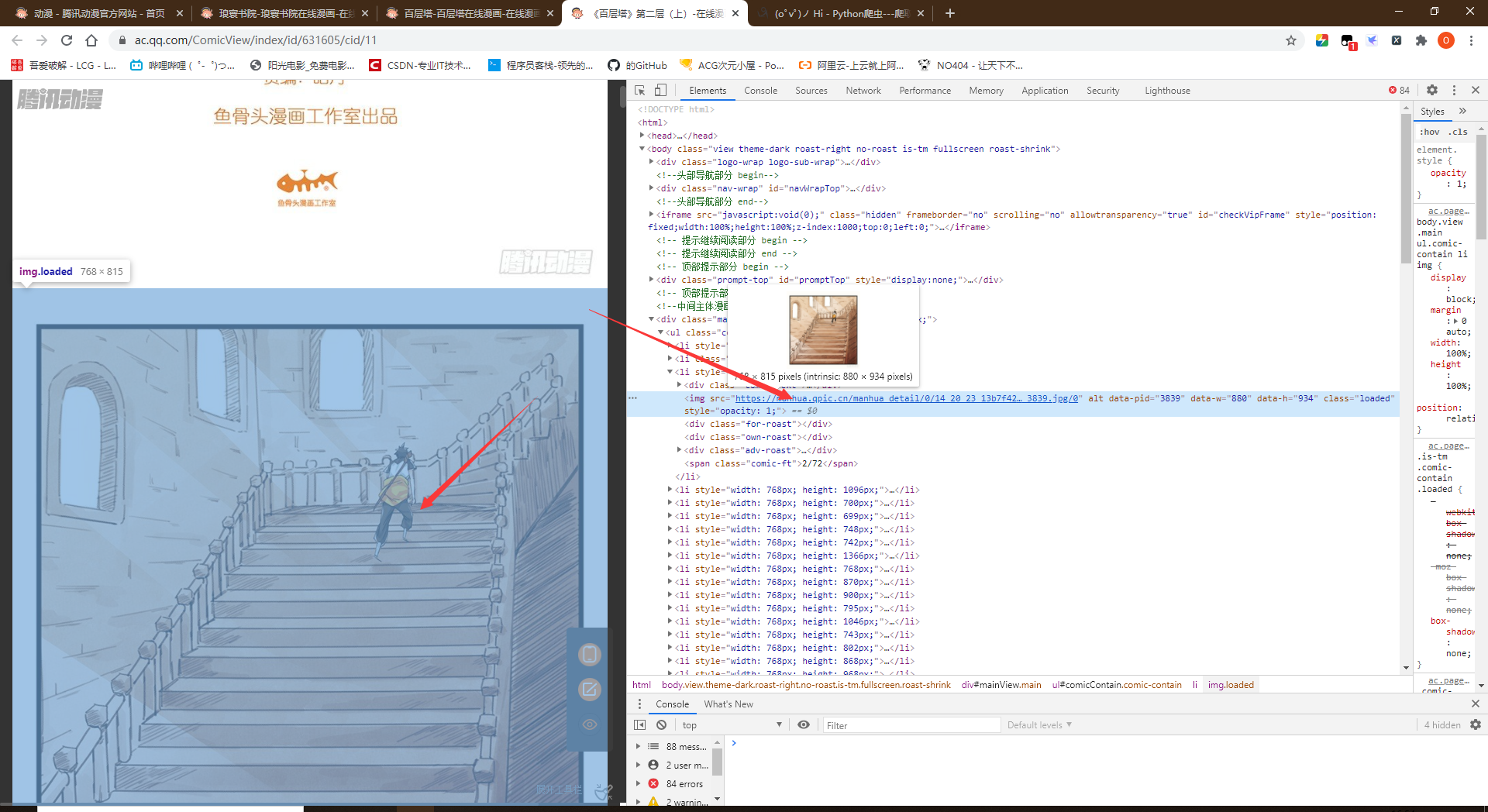
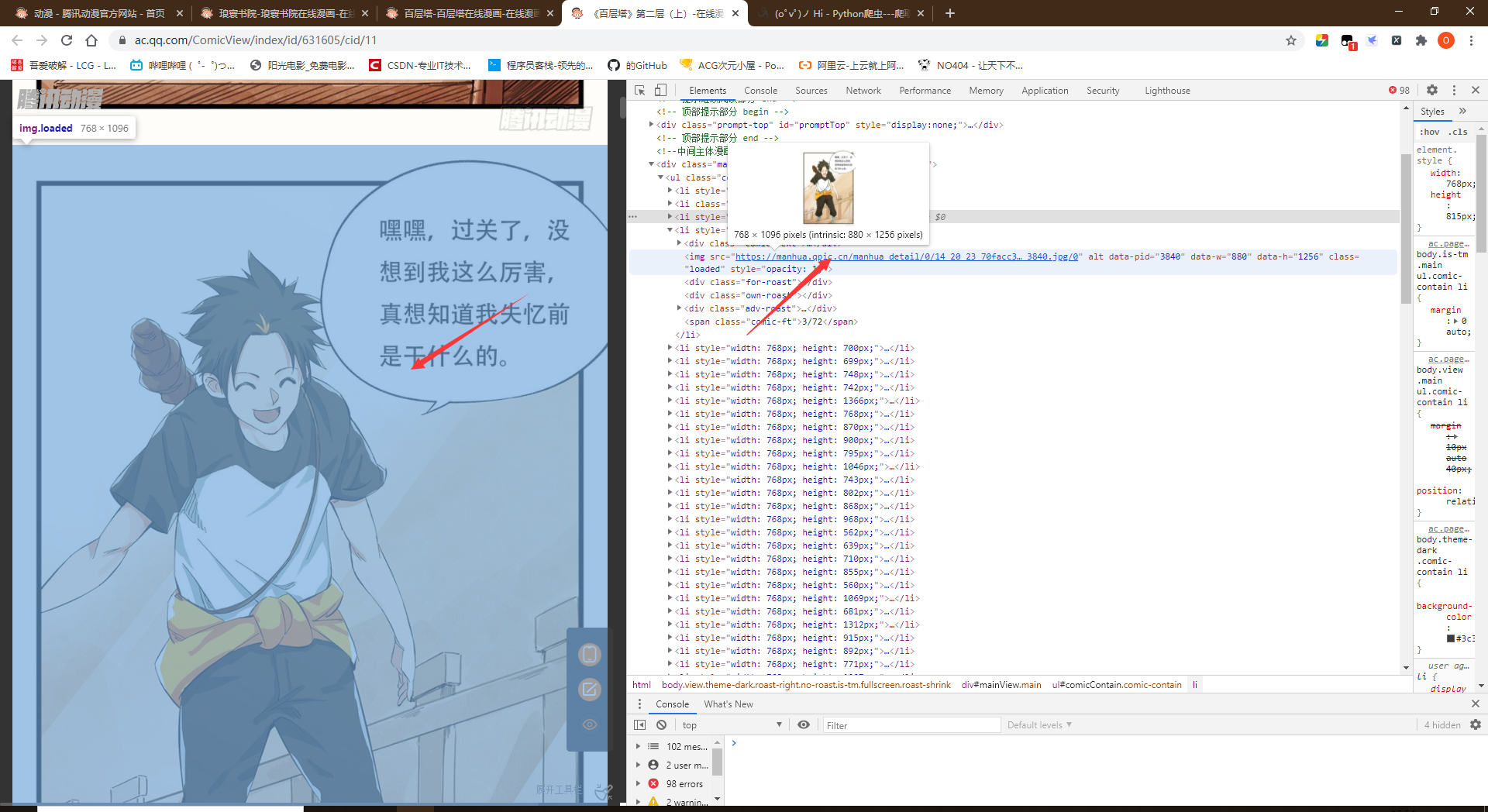
- 由此可以发现图片是直接可以爬取下来的,但是只有前几章是这样,后面全是后缀为.gif的文件,这些GIF文件就是加载动画,在滑动进度条到该图片的位置后就会加载出来图片地址
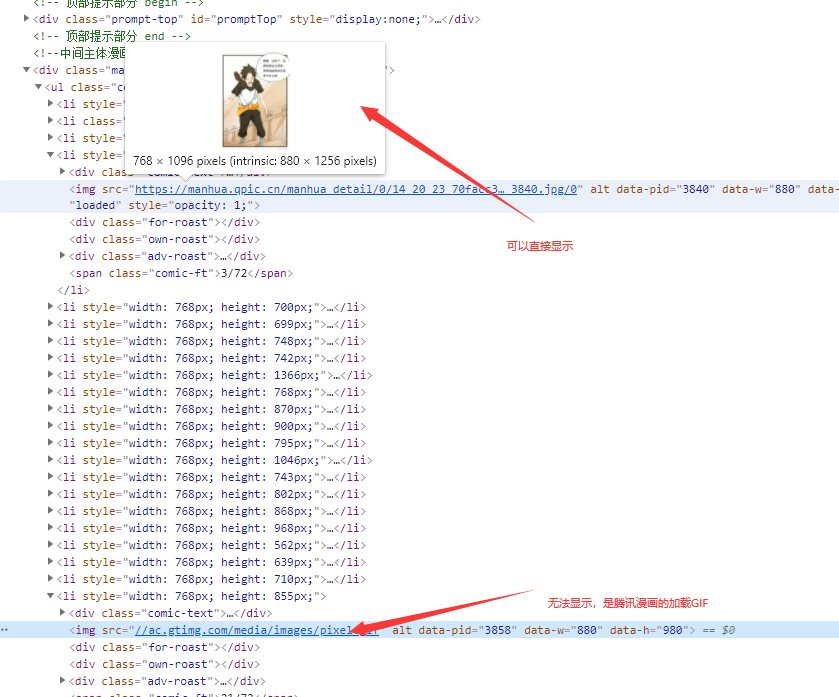
- 滑动进度条,现在全部显示出来了
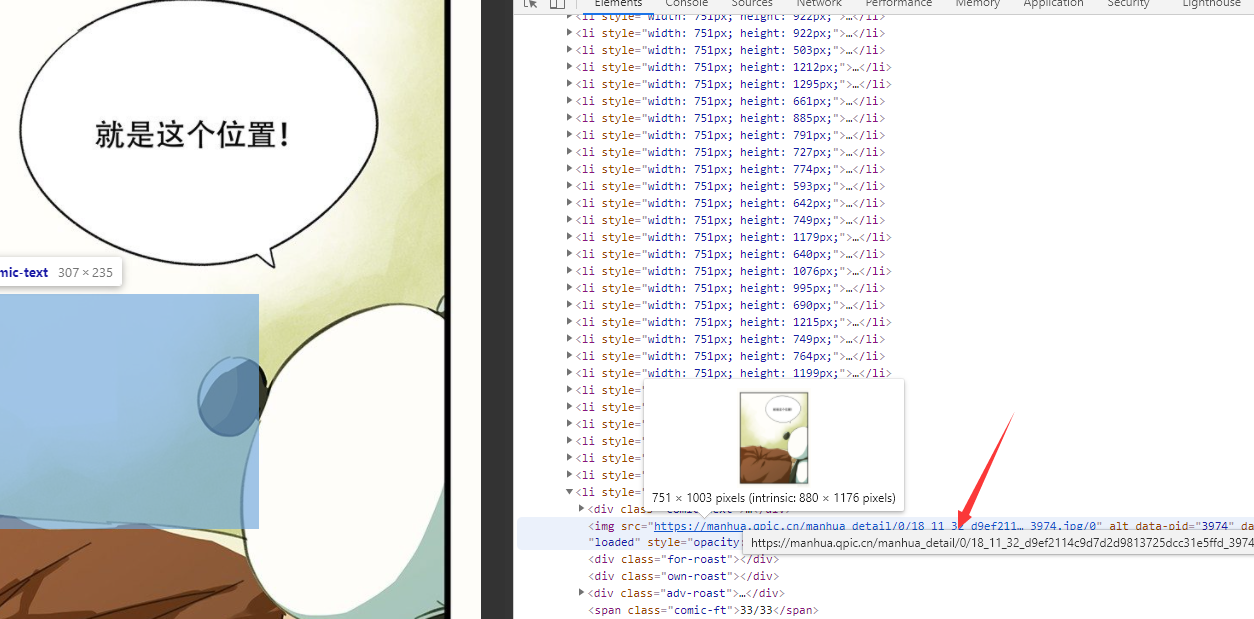
- 滑动进度条,现在全部显示出来了
- 进入某一章节中,分析图片的地址
- 代码编写
- 导入python模块
- import requestsfrom lxml import etreefrom selenium import webdriver from time import sleepfrom bs4 import BeautifulSoupfrom selenium.webdriver.chrome.options import Options import os
- 获取漫画的地址
- 采用xpath的方式查看

- python代码实现
#打开腾讯动漫首页url = 'https://ac.qq.com/'#给网页发送请求data = requests.get(url).text#将网页信息转换成xpath可识别的类型html = etree.HTML(data)#提取到每个漫画的目录页地址comic_list = html.xpath('//a[@class="in-rank-name"]/@href')print(comic_list)- 结果
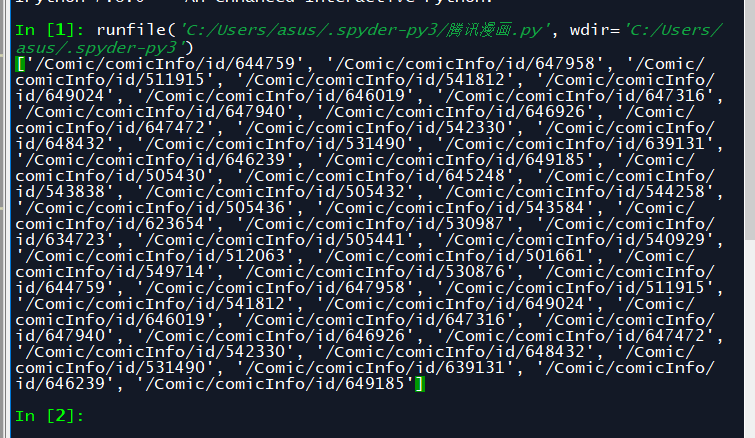
- 结果
- 提取漫画的内容
- 漫画的名字//h2[@class='works-intro-title ui-left']/strong/text()
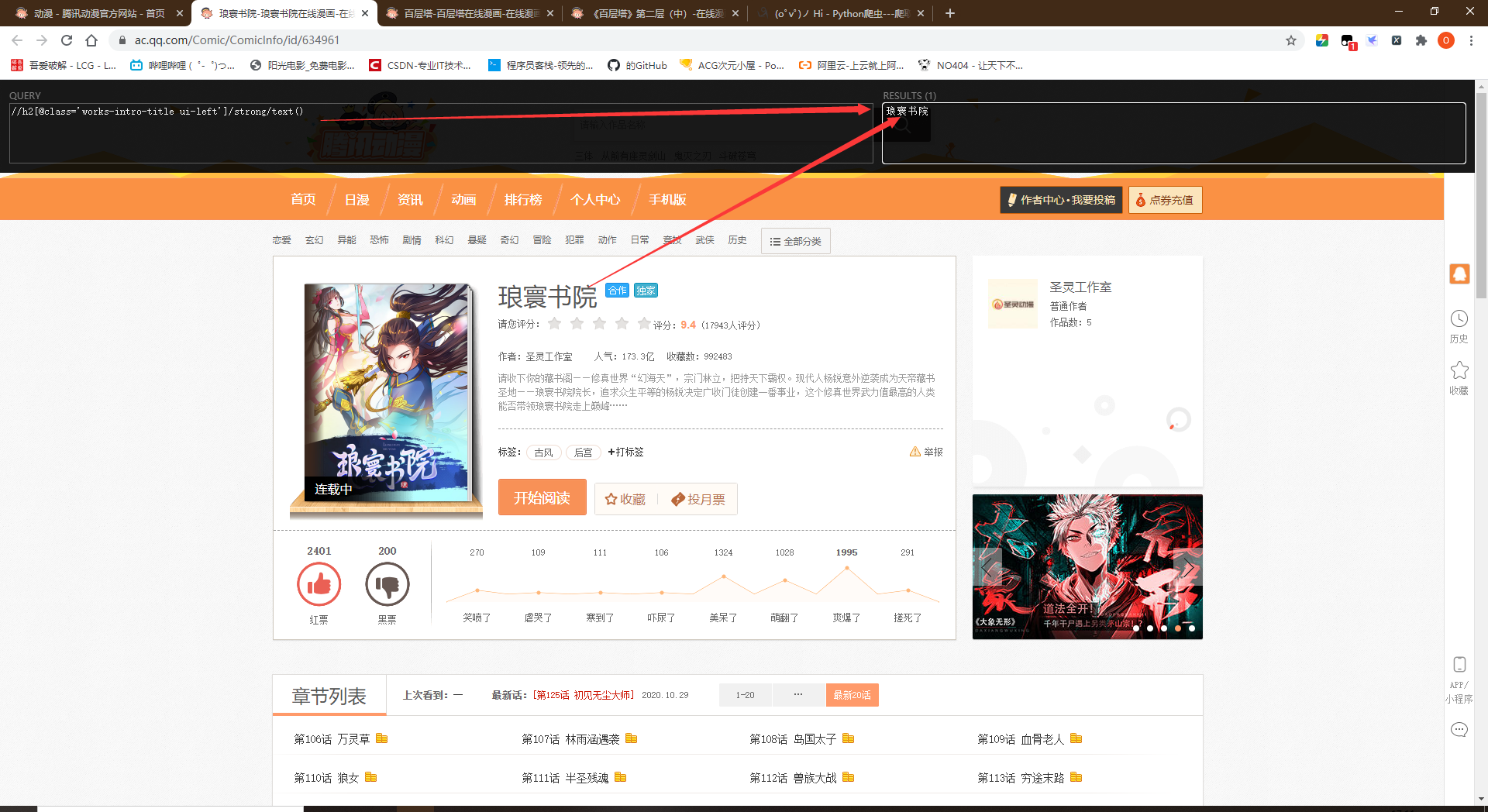
- 漫画的章节地址//span[@class='works-chapter-item']/a/@href

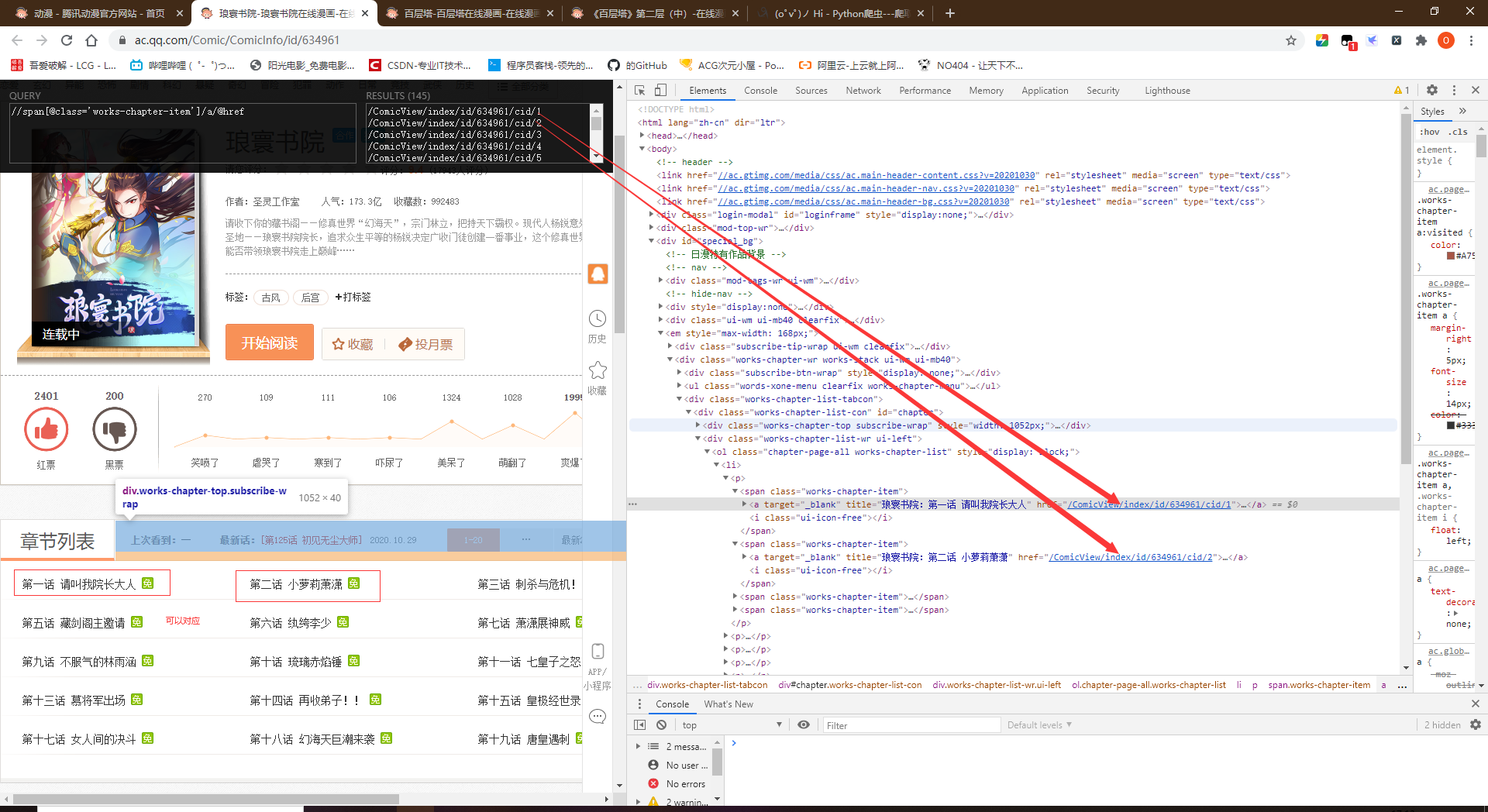
- 漫画的名字//h2[@class='works-intro-title ui-left']/strong/text()
- python代码实现
#遍历提取到的信息for comic in comic_list: #拼接成为漫画目录页的网址 comic_url = url + str(comic) #从漫画目录页提取信息 url_data = requests.get(comic_url).text #准备用xpath语法提取信息 data_comic = etree.HTML(url_data) #提取漫画名--text()为提取文本内容 name_comic = data_comic.xpath("//h2[@class='works-intro-title ui-left']/strong/text()") #提取该漫画每一页的地址 item_list = data_comic.xpath("//span[@class='works-chapter-item']/a/@href") print(name_comic) print(item_list)
- 结果

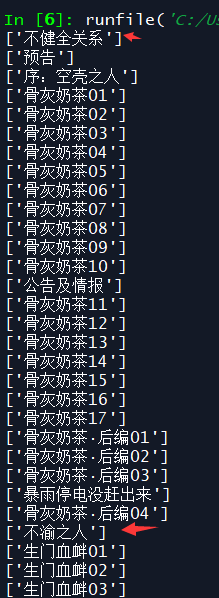
- 提取章节名//span[@class="works-chapter-item"]/a/@title

- 可以在漫画名的文件夹下再为每一个章节创建一个文件夹保存本章漫画图片,更加的规整
- 代码实现
- for item in item_list: #拼接每一章节的地址 item_url = url + str(item) #print(item_url) #请求每一章节的信息 page_mes = requests.get(item_url).text #准备使用xpath提取内容 page_ming = etree.HTML(page_mes) #提取章节名 page_name = page_ming.xpath('//span[@class="title-comicHeading"]/text()') print(page_name)
- 结果
- 获取漫画网页代码,爬取漫画的图片
#webdriver位置
path = r'/home/jmhao/chromedriver'
#浏览器参数设置
browser = webdriver.Chrome(executable_path=path)
#开始请求第一个章节的网址
browser.get(item_url)
#设置延时,为后续做缓冲
sleep(2)
#尝试执行下列代码
try:
#设置自动下滑滚动条操作
for i in range(1, 100):
#滑动距离设置
js = 'var q=document.getElementById("mainView").scrollTop = ' + str(i * 1000)
#执行滑动选项
browser.execute_script(js)
#延时,使图片充分加载
sleep(2)
sleep(2)
#将打开的界面截图保存,证明无界面浏览器确实打开了网页 browser.get_screenshot_as_file(str(page_name) + ".png")
#获取当前页面源码 data = browser.page_source #在当前文件夹下创建html文件,并将网页源码写入 fh = open("dongman.html", "w", encoding="utf-8") #写入操作 fh.write(data) #关掉浏览器 fh.close() # 若上述代码执行报错(大概率是由于付费漫画),则执行此部分代码 except Exception as err: #跳过错误代码 pass- 模拟浏览器滑动的方法来获得图片的地址信息
#设置自动下滑滚动条操作for i in range(1, 100):
#滑动距离设置 js = 'var q=document.getElementById("mainView").scrollTop = ' + str(i * 1000)
#执行滑动选项 browser.execute_script(js)
#延时,使图片充分加载 sleep(2)
- 跳过付费章节,防止界面报错
except Exception as err:
#跳过错误代码 pass
- 模拟浏览器滑动的方法来获得图片的地址信息
- 下载漫画图片
for items in soup.find_all("img"):
#提取图片地址信息 item = items.get("src")
#请求图片地址 comic_pic = requests.get(item).content
#print(comic_pic) #尝试提取图片,若发生错误则跳过 try:
#打开文件夹,将图片存入 with open('G:/comic/' + str(name_comic) + '/' + str(page_name) + '/' + str(i + 1) + '.jpg', 'wb') as f:
#print('正在下载第 ', (i + 1), ' 张图片中') print('正在下载' , str(name_comic) , '-' , str(page_name) , '- 第' , (i+1) , '张图片')
#写入操作 f.write(comic_pic)
#更改图片名,防止新下载的图片覆盖原图片 i += 1 #若上述代码执行报错,则执行此部分代码 except Exception as err:
#跳过错误代码 pass
- 采用xpath的方式查看
- 导入python模块
- 代码时间久远找不到了
Python爬取腾讯动漫(仅限免费部分)
最新推荐文章于 2024-03-18 15:54:29 发布
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









