






一、Flink简介
-
1.Flink的引入

大数据的计算引擎的发展过程:
- 第一代计算引擎:Hadoop的MapReduce,批处理
- 第二代计算引擎:支持DAG(有向无环图)的框架,如Tez和Oozie,批处理
- 第三代计算引擎:spark,内存计算,支持批处理和流处理,Job内部的DAG支持(不跨域job),比MR快100倍
- 第四代:Flink批处理、流处理,SQL高层api,自带DAG流式计算性能更高、更可靠什么是
-
2.什么是Flink


Flink是一个框架和分布式处理引擎,用于对无界(流)和有界(批)数据流进行有状态计算。Fink可通过集群以内存进行任意规模的计算。
-
3.Flink的特性
- 高吞吐、低延迟、高性能
- 支持带有事件事件的窗口(window)操作
- 支持有状态的计算
- 内存计算
- 迭代计算
-
4.Flink的基石
- Checkpoint:校验点
- State:状态
- Time:时间
- Window:窗口
-
5.批处理和流处理
- 批处理:有界、持久、大量,Spark SQL,Flink DataSet
- 流处理:无界、实时、持续,Spark Streaming,Flink DataStream
二、Flink架构
1.JobManager
也叫做Master,用于协调分布式执行,它来调度任务(task),协调检查点(checkpoint),协调失败时的恢复。可配置高可用。只有一台是leader,其他的为standby。
2.TaskManage
也叫做Worker,用于执行一个dataflow的task、数据缓冲和data stream的交换,至少得有一个worker。
3.Flink的数据流编程模型

-
三、Flink集群搭建
1.安装模式
- local(本地):单机模式,一般不用
- standalone:独立模式,flink自带集群,开发测试环境使用
- yarn:计算资源统一由Hadoop YARN管理,生产环境
2.基础环境
- jdk 1.8
- ssh免密登录(集群内节点之间免密登录)
3.local模式安装
-
3.1下载安装包
-
3.2解压

-
3.3配置环境变量

source /etc/profile
-
3.4启动Scala shell交互界面


-
3.5命令行示例-单词计数
- 1.准备好数据文件:word.txt,放在/root下

- 2.执行命令

-
3.6启动Flink本地“集群”

-
3.7查看Flink的web ui

-
3.8集群运行测试任务-单词计数

查看结果

-
3.9web ui查看执行情况


-
3.10Flin本地(local)模式的原理

4.standalone模式安装
4.1集群规划
JobManager(master):hadoop01
TaskManager(worker):hadoop01,hadop02,hadoop03
4.2下载安装包

4.3解压

4.4配置环境变量
![]()

4.5环境变量生效
![]()
4.6修改Flink的配置文件

flink-conf.yaml




注意:key和value之间(:后)必须得有一个空格
masters

workers

4.7在环境配置文件中添加
vi /etc/profile

4.8分发

4.9使环境变量起作用
source /etc/profile
4.10启动集群并查看进程

4.11启动历史服务器

4.12Flink UI界面

4.13历史任务web UI界面

4.14测试
启动hadoop集群,如果配置了Hadoop HA,需要先启动zookeeper
flink run examples/batch/WordCount.jar --input hdfs://hadoop01:9000/wordcount/input/word.txt --output hdfs://hadoop01:9000/wordcount/output/result.txt --parallelism 2

4.15查看历史任务
http://hadoop01:50070/explorer.html#/flink/completed-jobs

http://hadoop01:8082/#/overview


4.16停止集群
stop-cluster.sh

4.17工作原理

5.Standalone-HA模式安装
5.1集群规划
- JobManager(master):hadoop01,hadoop02
- TaskManager(worker):hadoop01,hadop02,hadoop03
5.2启动zookeeper

5.3启动hadoop集群
start-dfs.sh
5.4停止flink集群
stop-cluster.sh
5.5修改flink配置文件


最终的配置文件
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
#==============================================================================
# Common
#==============================================================================
# The external address of the host on which the JobManager runs and can be
# reached by the TaskManagers and any clients which want to connect. This setting
# is only used in Standalone mode and may be overwritten on the JobManager side
# by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.
# In high availability mode, if you use the bin/start-cluster.sh script and setup
# the conf/masters file, this will be taken care of automatically. Yarn/Mesos
# automatically configure the host name based on the hostname of the node where the
# JobManager runs.
jobmanager.rpc.address: hadoop01
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The total process memory size for the JobManager.
#
# Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead.
jobmanager.memory.process.size: 1600m
# The total process memory size for the TaskManager.
#
# Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.
taskmanager.memory.process.size: 1728m
# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.
# It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.
#
# taskmanager.memory.flink.size: 1280m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 2
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
# The default file system scheme and authority.
#
# By default file paths without scheme are interpreted relative to the local
# root file system 'file:///'. Use this to override the default and interpret
# relative paths relative to a different file system,
# for example 'hdfs://mynamenode:12345'
#
# fs.default-scheme
#==============================================================================
# High Availability
#==============================================================================
# The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
#
high-availability: zookeeper
# The path where metadata for master recovery is persisted. While ZooKeeper stores
# the small ground truth for checkpoint and leader election, this location stores
# the larger objects, like persisted dataflow graphs.
#
# Must be a durable file system that is accessible from all nodes
# (like HDFS, S3, Ceph, nfs, ...)
#
high-availability.storageDir: hdfs://hadoop01:9000/flink/ha/
# The list of ZooKeeper quorum peers that coordinate the high-availability
# setup. This must be a list of the form:
# "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
#
high-availability.zookeeper.quorum: hadoop01:2181,hadoop02:2181,hadoop03:2181
# ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
# It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
# The default value is "open" and it can be changed to "creator" if ZK security is enabled
#
# high-availability.zookeeper.client.acl: open
#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled.
#
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# <class-name-of-factory>.
#
state.backend: filesystem
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
state.checkpoints.dir: hdfs://hadoop01:9000/flink-checkpoints
# Default target directory for savepoints, optional.
#
state.savepoints.dir: hdfs://hadoop01:9000/flink-savepoints
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#
# state.backend.incremental: false
# The failover strategy, i.e., how the job computation recovers from task failures.
# Only restart tasks that may have been affected by the task failure, which typically includes
# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.
jobmanager.execution.failover-strategy: region
#==============================================================================
# Rest & web frontend
#==============================================================================
# The port to which the REST client connects to. If rest.bind-port has
# not been specified, then the server will bind to this port as well.
#
#rest.port: 8081
# The address to which the REST client will connect to
#
#rest.address: 0.0.0.0
# Port range for the REST and web server to bind to.
#
#rest.bind-port: 8080-8090
# The address that the REST & web server binds to
#
#rest.bind-address: 0.0.0.0
# Flag to specify whether job submission is enabled from the web-based
# runtime monitor. Uncomment to disable.
web.submit.enable: true
#==============================================================================
# Advanced
#==============================================================================
# Override the directories for temporary files. If not specified, the
# system-specific Java temporary directory (java.io.tmpdir property) is taken.
#
# For framework setups on Yarn or Mesos, Flink will automatically pick up the
# containers' temp directories without any need for configuration.
#
# Add a delimited list for multiple directories, using the system directory
# delimiter (colon ':' on unix) or a comma, e.g.:
# /data1/tmp:/data2/tmp:/data3/tmp
#
# Note: Each directory entry is read from and written to by a different I/O
# thread. You can include the same directory multiple times in order to create
# multiple I/O threads against that directory. This is for example relevant for
# high-throughput RAIDs.
#
# io.tmp.dirs: /tmp
# The classloading resolve order. Possible values are 'child-first' (Flink's default)
# and 'parent-first' (Java's default).
#
# Child first classloading allows users to use different dependency/library
# versions in their application than those in the classpath. Switching back
# to 'parent-first' may help with debugging dependency issues.
#
# classloader.resolve-order: child-first
# The amount of memory going to the network stack. These numbers usually need
# no tuning. Adjusting them may be necessary in case of an "Insufficient number
# of network buffers" error. The default min is 64MB, the default max is 1GB.
#
# taskmanager.memory.network.fraction: 0.1
# taskmanager.memory.network.min: 64mb
# taskmanager.memory.network.max: 1gb
#==============================================================================
# Flink Cluster Security Configuration
#==============================================================================
# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
# may be enabled in four steps:
# 1. configure the local krb5.conf file
# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
# 3. make the credentials available to various JAAS login contexts
# 4. configure the connector to use JAAS/SASL
# The below configure how Kerberos credentials are provided. A keytab will be used instead of
# a ticket cache if the keytab path and principal are set.
# security.kerberos.login.use-ticket-cache: true
# security.kerberos.login.keytab: /path/to/kerberos/keytab
# security.kerberos.login.principal: flink-user
# The configuration below defines which JAAS login contexts
# security.kerberos.login.contexts: Client,KafkaClient
#==============================================================================
# ZK Security Configuration
#==============================================================================
# Below configurations are applicable if ZK ensemble is configured for security
# Override below configuration to provide custom ZK service name if configured
# zookeeper.sasl.service-name: zookeeper
# The configuration below must match one of the values set in "security.kerberos.login.contexts"
# zookeeper.sasl.login-context-name: Client
#==============================================================================
# HistoryServer
#==============================================================================
# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
jobmanager.archive.fs.dir: hdfs://hadoop01:9000/flink/completed-jobs/
# The address under which the web-based HistoryServer listens.
historyserver.web.address: hadoop01
# The port under which the web-based HistoryServer listens.
historyserver.web.port: 8082
# Comma separated list of directories to monitor for completed jobs.
historyserver.archive.fs.dir: hdfs://hadoop01:9000/flink/completed-jobs/
# Interval in milliseconds for refreshing the monitored directories.
#historyserver.archive.fs.refresh-interval: 10000
5.6修改master

5.7修改workers
不用修改
分发
5.8同步配置文件

5.9修改hadoop02上的flink-conf.yaml文件


5.10重新启动flink集群

5.11查看进程
1.发现没有相关进程被启动,是因为缺少flink整合hadoop的jar包,需要从flink官网下载

2.放入lib目录

3.分发其他的节点上对应的flink下的lib目录
4.重新启动Flink集群,查看进程



5.12测试
1.访问webui
http://hadoop01:8081/#/overview

http://hadoop02:8081/#/overview

2.执行wc
flink run /export/servers/flink-1.12.2/examples/batch/WordCount.jar

3.kill掉其中一个master

4.重新执行wc,看是否能正常执行

5.13停止集群

5.14工作原理

6 .Flink on yarn安装
6.1 介绍
- 资源可以按需使用,提高集群的资源利用率
- 任务有优先级,可以根据优先级运行作业
- 基于Yarn调度系统,能够自动化的处理各个角色的容错(FailOver)
6.2 集群规划
可以根据standalone保持一致
6.3 配置yarn
关闭yarn的内存检查,需要修改hadoop集群yarn的配置文件yarn-site.xml
<property>
<name>yarn.nodemanager.pmeme-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmeme-check-enabled</name>
<value>false</value>
</property>

分发
scp /export/servers/hadoop/etc/hadoop/yarn-site.xml hadoop02:/export/servers/hadoop/etc/hadoop/
scp /export/servers/hadoop/etc/hadoop/yarn-site.xml hadoop03:/export/servers/hadoop/etc/hadoop/

6.4 启动yarn
start-yarn.sh

6.5 测试
提交任务有两种模式,session模式和per-job模式

(1)Session模式
1.开启会话(资源)

yarn-session.sh -n 2-tm 800 -s 1 –d
说明:-n 表示申请的容器,也就是worker的数量,也即cpu的数量
-tm:表示每个worker(TaskManager)的内存的大小
-s:表示每个worker的slot的数量
-d:表示后台运行

2.查看UI界面

3.提交任务
flink run /export/servers/flink-1.12.2/examples/batch/WordCount.jar




4.再次提交一个任务

Session一直存在

5.关闭yarn-session
yarn application -kill application_1620298469313_0001


(2)Per-Job模式
1.直接提交job
flink run -m yarn-cluster -yjm 1024 -ytm 1024 /export/servers/flink-1.12.2/examples/batch/WordCount.jar
说明:
-m:jobmanager的地址
-yjm:jobmanage的内存大小
-ytm:taskmanager的内存大小
2.查看UI界面

3.再次提交Job
flink run -m yarn-cluster -yjm 1024 -ytm 1024 /export/servers/flink-1.12.2/examples/batch/WordCount.jar
(3)参数总结
flink run –help

四、DataSet开发
进行批处理操作,但是现在不推荐使用了。

1.入门案例
实现wordcount单词计数
1.1 构建工程



1.2 pom文件

1.3 建立包和类

1.4 代码实现
package cn.edu.hgu.flnkl;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.operators.Order;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import scala.Int;
/**
* @desc 使用flink的dataset api实现单词计数(已经不推荐使用)
* @author 007
* @date 2021-5-9 m母亲节
*/
public class WordCount {
public static void main(String args[]) throws Exception {
//System.out.println("hello,flnk!");
//1、准备环境-env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();//单例模式
//2、准备数据-source
DataSet<String> lineDS = env.fromElements("spark sqoop hadoop","spark flink","hadoop fink spark");
//3、处理数据-transformation
//3.1 将每一行数据切分成一个个的单词组成一个集合
DataSet<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
//s就是一行行的数据,再将每一行分割为一个个的单词
String[] words = s.split(" ");
for (String word : words) {
//将切割的单词收集起来并返回
collector.collect(word);
}
}
});
//3.2 对集合中的每个单词记为1
DataSet<Tuple2<String,Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
//s就是进来的一个个单词,再跟1组成一个二元组
return Tuple2.of(s,1);
}
});
//3.3 对数据按照key进行分组
UnsortedGrouping<Tuple2<String,Integer>> groupedDS = wordAndOnesDS.groupBy(0);
//3.4 对各个组内的数据按照value进行聚合也就是求sum
DataSet<Tuple2<String, Integer>> aggResult = groupedDS.sum(1);
//3.4 对结果排序
DataSet<Tuple2<String,Integer>> result = aggResult.sortPartition(1, Order.DESCENDING).setParallelism(1);
//4、输出结果-sink
result.print();
//5、触发执行-execute
//说明:如果有pring那么Dataset不需要调用excute,DataStream需要调用execute
}
}
1.5 运行,查看结果

2.基于DataStream改写代码,执行并查看结果

完整代码
package cn.edu.hgu.flnkl;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.operators.Order;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @desc 用flink的dataStream api实现单词计数
* @author 007
* @date 2021-5-9 母亲节
*/
public class WordCountStream {
public static void main(String args[]) throws Exception {
//1、准备环境-env
//新版本的流批统一api,既支持流处理也指出批处理
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//批处理模式//env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//流处理模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//自动选择处理模式
//2、准备数据-source
DataStream<String> lineDS = env.fromElements("spark sqoop hadoop","spark flink","hadoop fink spark");
//3、处理数据-transformation
//3.1 将每一行数据切分成一个个的单词组成一个集合
DataStream<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
//s就是一行行的数据,再将每一行分割为一个个的单词
String[] words = s.split(" ");
for (String word : words) {
//将切割的单词收集起来并返回
collector.collect(word);
}
}
});
//3.2 对集合中的每个单词记为1
DataStream<Tuple2<String,Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
//s就是进来的一个个单词,再跟1组成一个二元组
return Tuple2.of(s,1);
}
});
//3.3 对数据按照key进行分组
//UnsortedGrouping<Tuple2<String,Integer>> groupedDS = wordAndOnesDS.groupBy(0);
KeyedStream<Tuple2<String,Integer>,String> groupedDS = wordAndOnesDS.keyBy(t->t.f0);
//3.4 对各个组内的数据按照value进行聚合也就是求sum
DataStream<Tuple2<String, Integer>> result = groupedDS.sum(1);
//3.5 对结果排序
//DataSet<Tuple2<String,Integer>> result = aggResult.sortPartition(1, Order.DESCENDING).setParallelism(1);
//4、输出结果-sink
result.print();
//5、触发执行-execute
//说明:如果有print那么Dataset不需要调用execute,DataStream需要调用execute
env.execute();
}
}
执行并查看结果

3.在yarn上运行
3.1 修改代码
package cn.edu.hgu.flnkl;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @desc 用flink的dataStream java api实现单词计数,在yarn上运行
* @author 007
* @date 2021-5-13 母亲节
*/
public class WordCountYarn {
public static void main(String args[]) throws Exception {
//0、获取参数
//获取命令行参数
ParameterTool params = ParameterTool.fromArgs(args);
String output = null;
if (params.has("output")) {//如果命令行中指定了输出文件夹参数,则用这个参数
output = params.get("output");
} else {//如果没有指定输出文件夹参数,则指定默认的输出文件夹
output = "hdfs://hadoop01:9000/wordcount/output_" +System.currentTimeMillis(); //避免输出文件夹重名
}
//1、准备环境-env
//新版本的流批统一api,既支持流处理也指出批处理
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//批处理模式//env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//流处理模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//自动选择处理模式
//2、准备数据-source
DataStream<String> lineDS = env.fromElements("spark sqoop hadoop","spark flink","hadoop fink spark");
//3、处理数据-transformation
//3.1 将每一行数据切分成一个个的单词组成一个集合
DataStream<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
//s就是一行行的数据,再将每一行分割为一个个的单词
String[] words = s.split(" ");
for (String word : words) {
//将切割的单词收集起来并返回
collector.collect(word);
}
}
});
//3.2 对集合中的每个单词记为1
DataStream<Tuple2<String,Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
//s就是进来的一个个单词,再跟1组成一个二元组
return Tuple2.of(s,1);
}
});
//3.3 对数据按照key进行分组
//UnsortedGrouping<Tuple2<String,Integer>> groupedDS = wordAndOnesDS.groupBy(0);
KeyedStream<Tuple2<String,Integer>,String> groupedDS = wordAndOnesDS.keyBy(t->t.f0);
//3.4 对各个组内的数据按照value进行聚合也就是求sum
DataStream<Tuple2<String, Integer>> aggResult = groupedDS.sum(1);
//3.5 对结果排序
// DataStream<Tuple2<String,Integer>> result = aggResult..sortPartition(1, Order.DESCENDING).setParallelism(1);
//4、输出结果-sink
aggResult.print();
aggResult.writeAsText(output).setParallelism(1);
//5、触发执行-execute
//说明:如果有print那么Dataset不需要调用execute,DataStream需要调用execute
env.execute();
}
}
3.2 打jar包,参考博文
可视化方式
Flink实例-Wordcount详细步骤 - 紫轩弦月 - 博客园
修改pom文件,添加构建jar包的插件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<useUniqueVersions>false</useUniqueVersions>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>cn.edu.hgu.flnkl.WordCountYarn</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
3.3 上传集群并改名


3.4 提交执行
不带参数
flink run -Dexecution.runtime-mode=BATCH -m yarn-cluster -yjm 1024 -ytm 1024 -c cn.edu.hgu.flnkl.WordCountYarn /root/wc.jar


3.5 web UI查看进程
-
yarn上

- hadoop上
http://hadoop01:50070/explorer.html#/wordcount

- 在flink上
五、DataStream流批一体API开发
1.编程模型


2.source数据来源
a) 预定义的Source
- 基于集合的Source
- env.fromElements():元素
- env.fromCollection():集合
- env.generateSequence():产生序列
- env.fromSequence():来自于序列
package cn.edu.hgu.flnkl;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* @desc Flink基于集合的Source演示
* @author 007
* @date 2021/5/14
*/
public class FlinkSourceDemo {
public static void main(String args[]) throws Exception {
//1.env
//1、准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.source
//env.fromElements()//:元素
DataStream<String> ds1 = env.fromElements("hadoop","spark","flink","hbase");
//env.fromCollection()//:集合
DataStream<String> ds2 = env.fromCollection(Arrays.asList("hadoop","spark","flink","hbase"));
//env.generateSequence()//:产生序列
DataStream<Long> ds3 = env.generateSequence(1,10);
//env.fromSequence()//:来自于序列
DataStream<Long> ds4 = env.fromSequence(1,10);
//3.transformer
//4.sink
ds1.print();
ds2.print();
ds3.print();
ds4.print();
//5.execute
env.execute();
}
}
b) 基于文件的Source
env.readTextFile(本地/hdfs文件/文件夹/压缩包),如果需要读取hadoop上的文件或文件夹,在pom文件中需要添加hadoop依赖,同时需要把hadoop的配置文件hdfs-site.xml和core-site.xml下载复制到项目resource是文件下
pom文件
dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
resources文件夹

源代码
package cn.edu.hgu.flnkl;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* @desc Flink基于文件的Source演示
* @author 007
* @date 2021/5/14
*/
public class FlinkSourceDemo1 {
public static void main(String args[]) throws Exception {
//1.env
//1、准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.source
//env.fromElements()//:元素
DataStream<String> ds1 = env.readTextFile("D:\\data\\input\\text1.txt");//文件
//env.fromCollection()//:集合
DataStream<String> ds2 = env.readTextFile("D:\\data\\input");//文件夹
//env.generateSequence()//:产生序列
DataStream<String> ds3 = env.readTextFile("hdfs://hadoop01:9000/wordcount/input/word.txt");//hadoop文件
//env.fromSequence()//:来自于序列
DataStream<String> ds4 = env.readTextFile("hdfs://hadoop01:9000/wordcount/input/words.txt.gz");//hadoop上的压缩包
//3.transformer
//4.sink
ds1.print();
ds2.print();
ds3.print();
ds4.print();
//5.execute
env.execute();
}
}
c)基于socket的Source
env.socketTextStream("主机名或ip地址", port)
需在hadoop01上安装nc,nc可以持续的向某一个主机的某个端口发送数据
yum install –y nc
安装好后,执行以下命令
nc -lk 9999
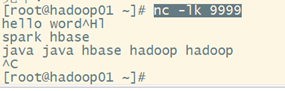
源代码
package cn.edu.hgu.flnkl;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @desc Flink基于socket的Source演示
* @author 007
* @date 2021/5/14
*/
public class FlinkSourceDemo2 {
public static void main(String args[]) throws Exception {
//1、准备环境-env
//新版本的流批统一api,既支持流处理也指出批处理
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//批处理模式//env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//流处理模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//自动选择处理模式
//2、准备数据-source
DataStream<String> lineDS = env.socketTextStream("hadoop01",9999);
//3、处理数据-transformation
//3.1 将每一行数据切分成一个个的单词组成一个集合
DataStream<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
//s就是一行行的数据,再将每一行分割为一个个的单词
String[] words = s.split(" ");
for (String word : words) {
//将切割的单词收集起来并返回
collector.collect(word);
}
}
});
//3.2 对集合中的每个单词记为1
DataStream<Tuple2<String,Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
//s就是进来的一个个单词,再跟1组成一个二元组
return Tuple2.of(s,1);
}
});
//3.3 对数据按照key进行分组
//UnsortedGrouping<Tuple2<String,Integer>> groupedDS = wordAndOnesDS.groupBy(0);
KeyedStream<Tuple2<String,Integer>,String> groupedDS = wordAndOnesDS.keyBy(t->t.f0);
//3.4 对各个组内的数据按照value进行聚合也就是求sum
DataStream<Tuple2<String, Integer>> aggResult = groupedDS.sum(1);
//3.5 对结果排序
// DataStream<Tuple2<String,Integer>> result = aggResult..sortPartition(1, Order.DESCENDING).setParallelism(1);
//4、输出结果-sink
aggResult.print();
//5、触发执行-execute
//说明:如果有print那么Dataset不需要调用execute,DataStream需要调用execute
env.execute();
}
}
启动项目,查看结果

2. 预定义的数据源
- SourceFunction:非并行数据源(并行度=1)
- RichSourceFunction:多功能非并行数据源(并行度=1)
- ParallelSourceFunction:并行数据源(并行度>=1)
- RichParallelSourceFunction:多功能并行数据源(并行度>=1)
a)随机生成数据
b) Mysql
自定义数据源从MySql中读取数据
- idea添加lombok插件

- 在pom文件中,添加lombok和mysql的依赖

- 连接mysql,建表

- 创建学生实体类

- 创建mysql自定义数据源类

以前的代码
package cn.edu.hgu.flink.config;
import cn.edu.hgu.flink.entity.Student;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.concurrent.TimeUnit;
/**
* @desc 自定义数据源连接mysql
*/
public class MySQLSource extends RichParallelSourceFunction<Student> {
private Connection connection = null;
private PreparedStatement preparedStatement = null;
private boolean flag = true;
@Override
public void run(SourceContext sourceContext) throws Exception {
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf-8&serverTimezone=UTC","root","root");
String sql = "select * from student";
preparedStatement = connection.prepareStatement(sql);
while (flag) {
ResultSet rs = preparedStatement.executeQuery();
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
sourceContext.collect(new Student(id,name,age));
}
TimeUnit.SECONDS.sleep(5);
}
}
@Override
public void cancel() {
// preparedStatement.close();
// connection.close();
flag = false;
}
}
新版的:
package cn.edu.hgu.flink.config;
import cn.edu.hgu.flink.entity.Student;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.concurrent.TimeUnit;
/**
* @desc 自定义数据源连接mysql
*/
public class MySQLSource extends RichParallelSourceFunction<Student> {
private Connection connection = null;
private PreparedStatement preparedStatement = null;
private boolean flag = true;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf-8&serverTimezone=UTC","root","root");
String sql = "select * from student";
preparedStatement = connection.prepareStatement(sql);
}
@Override
public void run(SourceContext sourceContext) throws Exception {
while (flag) {
ResultSet rs = preparedStatement.executeQuery();
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
sourceContext.collect(new Student(id,name,age));
}
TimeUnit.SECONDS.sleep(5);
}
}
@Override
public void cancel() {
flag = false;
}
@Override
public void close() throws Exception {
super.close();
preparedStatement.close();
connection.close();
}
}
- 编写主类

- 执行,查看结果

3.Transformation数据的计算
3.1 基本操作
- a )flatmap
将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果
- b) map
将函数作用在集合的每一个元素上,并返回作用后的结果
- c) keyBy
按照指定的key对流中的数据进行分组,注意流处理中没有groupBy,而是keyBy
- d) filter
按照指定的条件对集合中的元素进行过滤,返回符合条件的元素
- e) sum
按照指定的字段对集合中的元素进行求和
- f) reduce
对集合中的元素进行聚合
- g) 案例
对流数据中的单词进行统计,排除敏感词heihei

完整的代码
package cn.edu.hgu.flink;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @desc flink的transformation过滤敏感词
* @author 007
* @date 2021-5-21
*/
public class FlinkTransformationDemo1 {
public static void main(String args[]) throws Exception {
//1、准备环境-env
//新版本的流批统一api,既支持流处理也指出批处理
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//批处理模式//env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//流处理模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//自动选择处理模式
//2、准备数据-source
DataStream<String> lineDS = env.fromElements("spark heihei sqoop hadoop","spark flink","hadoop fink heihei spark");
//3、处理数据-transformation
//3.1 将每一行数据切分成一个个的单词组成一个集合
DataStream<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
//s就是一行行的数据,再将每一行分割为一个个的单词
String[] words = s.split(" ");
for (String word : words) {
//将切割的单词收集起来并返回
collector.collect(word);
}
}
});
//3.1.5 对数据进行敏感词过滤
DataStream<String> filterDS = wordsDS.filter(new FilterFunction<String>() {
@Override
public boolean filter(String s) throws Exception {
return !s.equals("heihei");
}
});
//3.2 对集合中的每个单词记为1
DataStream<Tuple2<String,Integer>> wordAndOnesDS = filterDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
//s就是进来的一个个单词,再跟1组成一个二元组
return Tuple2.of(s,1);
}
});
//3.3 对数据按照key进行分组
//UnsortedGrouping<Tuple2<String,Integer>> groupedDS = wordAndOnesDS.groupBy(0);
KeyedStream<Tuple2<String,Integer>,String> groupedDS = wordAndOnesDS.keyBy(t->t.f0);
//3.4 对各个组内的数据按照value进行聚合也就是求sum
DataStream<Tuple2<String, Integer>> aggResult = groupedDS.sum(1);
//3.5 对结果聚合
DataStream<Tuple2<String,Integer>> redResult = groupedDS.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t2, Tuple2<String, Integer> t1) throws Exception {
return Tuple2.of(t2.f0,t2.f1 + t2.f1);
}
});
//4、输出结果-sink
aggResult.print();
redResult.print();
//5、触发执行-execute
//说明:如果有print那么Dataset不需要调用execute,DataStream需要调用execute
env.execute();
}
}
3.2 拆分-合并
- a)union和connect
union合并多个同类型的数据流,并生成一个同类型的新的数据流,connect连接两个数据流,这两个数据流可以是不同的类型
案例

package cn.edu.hgu.flink;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import java.util.Arrays;
/**
* @desc flink的transformation合并
* @author 007
* @date 2021-5-21
*/
public class FlinkTransformationDemo2 {
public static void main(String args[]) throws Exception {
//1.env
//1、准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.source
//env.fromElements()//:元素
DataStream<String> ds1 = env.fromElements("hadoop","spark","flink","hbase");
//env.fromCollection()//:集合
DataStream<String> ds2 = env.fromCollection(Arrays.asList("hadoop","spark","flink","hbase"));
//env.generateSequence()//:产生序列
DataStream<Long> ds3 = env.generateSequence(1,10);
//env.fromSequence()//:来自于序列
DataStream<Long> ds4 = env.fromSequence(1,10);
//3.transformer
//合并
DataStream<String> union1 = ds1.union(ds2);//合并但不去重
ConnectedStreams<String,Long> connect1 = ds1.connect(ds3);
DataStream<String> connect2 = connect1.map(new CoMapFunction<String, Long, String>() {
@Override
public String map1(String s) throws Exception {
return "String->String" + s;
}
@Override
public String map2(Long aLong) throws Exception {
return "Long->String" + aLong.toString();
}
});
//4.sink
// union1.print();
connect2.print();
//5.execute
env.execute();
}
}
- b)Split、Select和Side Outputs
split将一个流分成多个流(已过期并移除),select是获取分流后对应的数据(已过期并移除),Side Outputs可以使用process方法对流中的数据进行处理,并针对不同的处理结果将数据收集到不同的OutputTag中。
- c)案例

代码
package cn.edu.hgu.flink;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import scala.Int;
import java.util.Arrays;
/**
* @desc flink的transformation拆分
* @author 007
* @date 2021-5-21
*/
public class FlinkTransformationDemo3 {
public static void main(String args[]) throws Exception {
//1.env
//1、准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.source
DataStreamSource<Integer> ds = env.fromElements(1,2,3,4,5,6,7,8,9,10);
//3.transformer
//拆分
//Side Outputs
//定义标签
OutputTag<Integer> tag_even = new OutputTag<Integer>("偶数", TypeInformation.of(Integer.class));
OutputTag<Integer> tag_odd = new OutputTag<Integer>("奇数",TypeInformation.of(Integer.class));
//对ds中的数据按标签进行划分
SingleOutputStreamOperator<Integer> tagResult = ds.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(Integer integer, Context context, Collector<Integer> collector) throws Exception {
if (integer % 2 == 0) {//偶数
context.output(tag_even,integer);
} else {
context.output(tag_odd,integer);
}
}
});
// //取出标记好的数据
DataStream<Integer> evenResult = tagResult.getSideOutput(tag_even);//取出偶数标记的数据
DataStream<Integer> oddResult = tagResult.getSideOutput(tag_odd);//取出奇数标记的数据
//4.sink
evenResult.print();
oddResult.print();
//5.execute
env.execute();
}
}
3.3 分区
- rebalance重平衡分区
类似于spark中的repartition,解决数据倾斜,数据倾斜指的是大量的数据集中于一台节点上,而其他节点的负载较轻
案例:

完整代码
package cn.edu.hgu.flink;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import javax.xml.crypto.Data;
/**
* @desc flink的transformation重平衡
* @author 007
* @date 2021-5-21
*/
public class FlinkTransformationDemo4 {
public static void main(String args[]) throws Exception {
//1.env
//1、准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.source
DataStreamSource<Long> longDS = env.fromSequence(0,10000);
//3.transformer
//将数据随机分配一下,有可能出现数据倾斜
DataStream<Long> filterDS = longDS.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long aLong) throws Exception {
return aLong > 10;
}
});
//直接处理,有可能出现数据倾斜
DataStream<Tuple2<Integer,Integer>> result1 = filterDS.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long aLong) throws Exception {
int id = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(id,1);
}
}).keyBy(t->t.f0).sum(1);
//在数据输出前进行了rebalance重平衡分区,解决数据的倾斜
DataStream<Tuple2<Integer,Integer>> result2 = filterDS.rebalance().map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long aLong) throws Exception {
int id = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(id,1);
}
}).keyBy(t->t.f0).sum(1);
//4.sink
// result1.print();
result2.print();
//5.execute
env.execute();
}
}
- 其他分区
3.4 Sink数据的去处
- 1)预定义的Sink
- ds.print():直接输出到控制台
- ds.printToErr():直接输出到控制台,用红色
- ds.writeAsText(“本地/HDFS”,WriteMode.OVERWRITE).setParallelism(n):输出到本地或者hdfs上,如果n=1,则输出为文件名,如果n>1,则输出为文件夹
代码演示:
项目结构:

代码:
package cn.edu.hgu.flink.sink;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @desc Flink预定义Sink演示
* @author 007
* @date 2021/5/28
*/
public class FlinkSinkDemo1 {
public static void main(String args[]) throws Exception {
//1.env
//1、准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.source
//env.fromElements()//:元素
DataStream<String> ds1 = env.readTextFile("D:\\data\\input\\text1.txt");//文件
//3.transformer
//4.sink
// ds1.print();
// ds1.printToErr();
// ds1.writeAsText("d:/data/output/test", FileSystem.WriteMode.OVERWRITE).setParallelism(1);//输出为一个文件
ds1.writeAsText("d:/data/output/test", FileSystem.WriteMode.OVERWRITE).setParallelism(2);//输出为一个文件夹
//5.execute
env.execute();
}
}
- 2)自定义的Sink
MySQL
自定义sink,把数据存放到mysql中
项目结构:

学生实体类:
package cn.edu.hgu.flink.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* 学生实体类
*/
@Data //生成getter和setter
@NoArgsConstructor //生成无参构造方法
@AllArgsConstructor //生成全参的构造方法
public class Student {
private Integer id;
private String name;
private Integer age;
}
数据存入mysql的sink类
package cn.edu.hgu.flink.config;
import cn.edu.hgu.flink.entity.Student;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
/**
* @desc 自定义Sink连接mysql
*/
public class MySQLSink extends RichSinkFunction<Student> {
private Connection connection = null;
private PreparedStatement preparedStatement = null;
@Override
public void open(Configuration parameters) throws Exception {
//调用父类的构造方法,可删除
super.open(parameters);
//加载mysql驱动,建立连接
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf-8&serverTimezone=UTC","root","root");
String sql = "insert into student(name,age) values(?,?)";
//建立Statement
preparedStatement = connection.prepareStatement(sql);
}
@Override
public void invoke(Student value, Context context) throws Exception {
//给ps中的?设置具体的值
preparedStatement.setString(1,value.getName());//获取姓名
preparedStatement.setInt(2,value.getAge());//获取年龄
//执行sql
preparedStatement.executeUpdate();
}
@Override
public void close() throws Exception {
super.close();
preparedStatement.close();
connection.close();
}
}
主类
package cn.edu.hgu.flink.sink;
import cn.edu.hgu.flink.config.MySQLSink;
import cn.edu.hgu.flink.config.MySQLSource;
import cn.edu.hgu.flink.entity.Student;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @desc Flink自定义Sink把数据写入到Mysql中
* @author 007
* @date 2021-5-28
*/
public class FlinkSinkMysqlDemo {
public static void main(String args[]) throws Exception {
//1.env
//1、准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.source
DataStream<Student> studentDS = env.fromElements(new Student(null,"tony",28));
//3.transformer
//4.sink
studentDS.addSink(new MySQLSink());
//5.execute
env.execute();
}
}
3.5 connectors

六、Table API和SQL开发
1.简介

2.为什么需要Table API和SQL
Flink的Table模块包括Table API和SQL:
Table API是一种类SQL的API,使用它用户可以像操作table一样操作数据,非常直观和方便。
SQL作为一种声明式语言,和关系型数据库比如mysql的sql基本一致,用户可以不用关心底层实现就可进行数据的处理。
特点:
- 声明式-用户只关心做什么,不用关心怎么做
- 高性能-支持查询优化,可以获取更好的性能
- 流批统一
- 标准稳定-遵循sql标准
- 易理解
3. pom文件添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>Flink-dataset-api-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.22</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.12</artifactId>
<version>1.12.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<useUniqueVersions>false</useUniqueVersions>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>cn.edu.hgu.flink.dataset.WordCountYarn</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
4. 案例1-读取csv中的数据进行操作
4.1 准备数据

4.2 新建一个类

完整代码
package cn.edu.hgu.flink.table;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.TableResult;
/**
* @desc flink操作csv的数据
* @author 007
* @date 2021-6-17
*/
public class FlinkTableCSVDemo {
public static void main(String[] args) {
// 1、create a TableEnvironment for batch or streaming execution
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
//.inBatchMode()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
// 2、create an input Table
tEnv.executeSql("CREATE TABLE student (\n" +
" id INT,\n" +
" name STRING,\n" +
" age INT\n" +
") WITH (\n" +
" 'connector' = 'filesystem',\n" +
" 'path' = 'd:\\student.csv',\n" +
" 'format' = 'csv',\n" +
" 'csv.ignore-parse-errors' = 'true',\n" +
" 'csv.allow-comments' = 'true',\n" +
" 'csv.field-delimiter' = ','\n" +
")");
// 3、register an output Table
//tEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH ( 'connector' = ... )");
// 4、create a Table object from a Table API query
Table table = tEnv.from("student");
// create a Table object from a SQL query
//Table table3 = tEnv.sqlQuery("SELECT ... FROM table1 ... ");
// 5、emit a Table API result Table to a TableSink, same for SQL result
TableResult tableResult = table.execute();
tableResult.print();
// table.printSchema();
}
}
4.3 执行结果

5. 案例2-flink读取mysql表的数据进行操作
5.1 准备数据

5.2 新建一个类

完整代码
package cn.edu.hgu.flink.table;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.TableResult;
/**
* @desc flink读取mysql表的数据进行操作
* @author 007
* @date 2021-6-17
*/
public class FlinkTableJDBCDemo {
public static void main(String[] args) {
// 1、create a TableEnvironment for batch or streaming execution
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
//.inBatchMode()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
//2、 create an input Table
tEnv.executeSql("CREATE TABLE student (\n" +
" id INT,\n" +
" name STRING,\n" +
" age INT,\n" +
" PRIMARY KEY (id) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://localhost:3306/test?serverTimezone=UTC',\n" +
" 'table-name' = 'student',\n" +
" 'username' = 'root',\n" +
" 'password' = 'root'\n" +
")");
//3、 register an output Table
//tableEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH ( 'connector' = ... )");
//4、create a Table object from a Table API query
Table table = tEnv.from("student").select("id,name");
// create a Table object from a SQL query
//Table table3 = tableEnv.sqlQuery("SELECT ... FROM table1 ... ");
//5、emit a Table API result Table to a TableSink, same for SQL result
//打印表的结构
table.printSchema();
//输出表的数据
TableResult tableResult = table.execute();
tableResult.print();
}
}
5.3 执行结果
















 1076
1076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









