







我的服务器配置之旅:从小白到成功运行深度学习模型
引言
作为一名对服务器配置一无所知的纯小白,我最近踏上了一段充满挑战的旅程。在这篇文章中,我将分享我如何克服重重困难,最终成功在服务器上运行深度学习模型的经历。
1. 初识服务器环境
我开始时对服务器的使用一窍不通,于是在网上寻找教程,但都未能满足我的需求。在一番摸索后,我总算让服务器跑了起来。
2. 环境检查与Anaconda的替代
第一步,也是至关重要的一步,是检查服务器预装的环境。我使用了module avail命令,发现缺少了Anaconda。这对于我而言无疑是个打击。尝试自行安装Anaconda失败后,我求助于客服,被告知需要使用Miniforge,这与Anaconda类似,于是我的问题解决了一半。
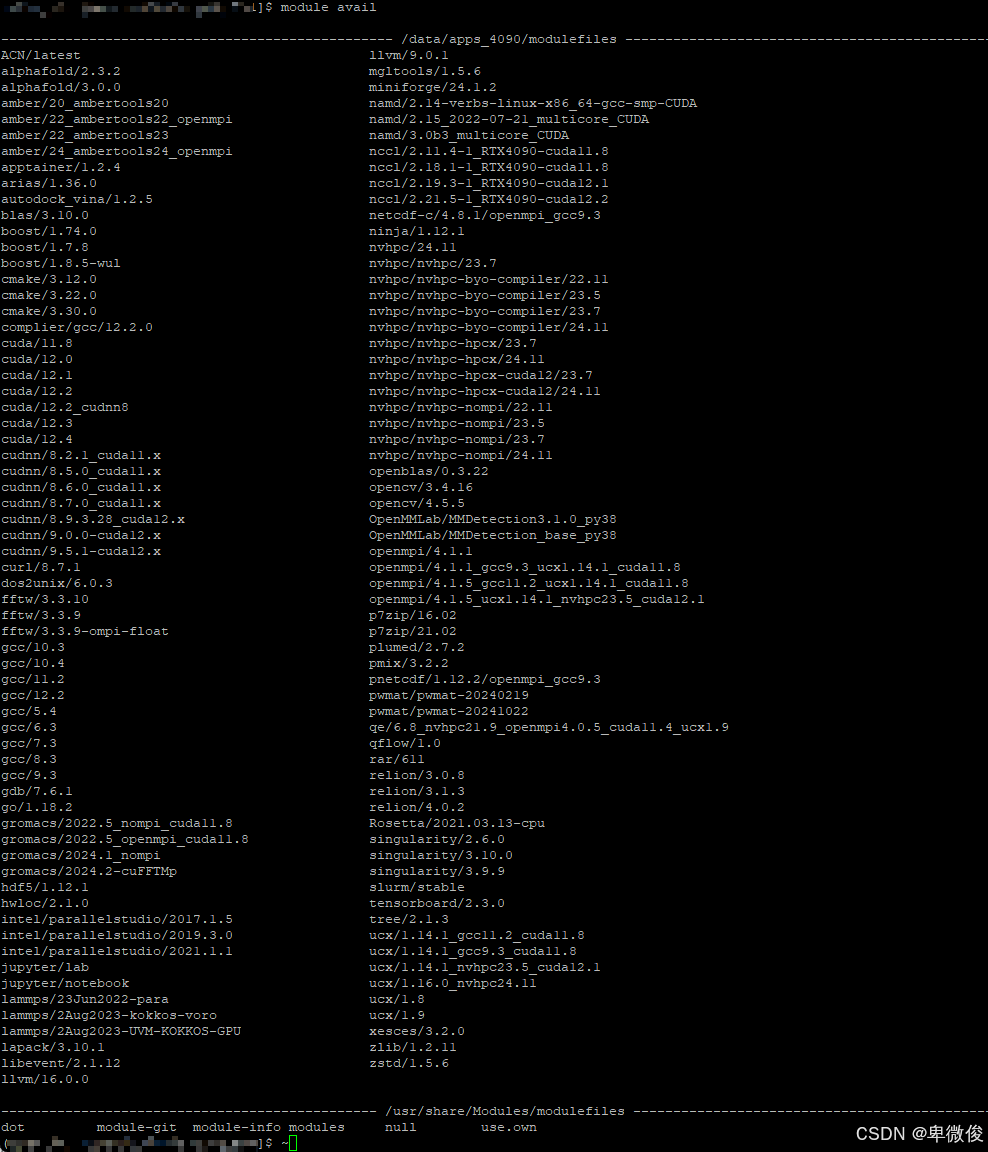
3. 加载环境模块
接下来,我需要加载预装的环境模块,如Miniforge、CUDA和GCC。根据需要加载相应版本的模块。
module load miniforge/24.1.2
module load cuda/11.8
注意:版本号需要根据实际情况调整。
4. 创建虚拟环境
创建虚拟环境时,我遇到了不少坑。首先需要初始化Conda,然后创建环境。在激活虚拟环境后,我尽量使用Conda命令安装包,如Torch。由于服务器无法访问外网,我不得不更换为国内的镜像源,最终选择了阿里云的镜像。
conda init
conda create -n 环境名字 python=python版本
5. 验证Torch安装
安装完Torch后,我通过torch.cuda.is_available()来验证安装是否成功。结果却是false,让我一度怀疑是否安装错误。经过多次尝试后,我决定先运行代码。
6. 提交作业与运行代码
最让我头疼的是编写Shell脚本。我编写了两个脚本:submit.sh用于提交作业,run.sh用于运行代码。这两个脚本分别负责提交任务和执行训练。
submit.sh
#!/bin/bash
SBATCH --job-name=qwen_ft
SBATCH --nodes=1
SBATCH --ntasks-per-node=8
SBATCH --gres=gpu:8
SBATCH --mem=60G
SBATCH --tmp=10G
SBATCH --cpus-per-task=4
SBATCH --time=72:00:00
SBATCH --partition=n30
SBATCH --output=%j.out
SBATCH --error=%j.err
# 加载环境变量,这句话不能省,用来申请GPU
source ~/.bashrc
# 检查GPU是否可用
echo "Checking GPU availability..."
nvidia-smi
which nvidia-smi
nvidia-smi
bash run.sh
run.sh文件
#!/bin/bash
# 加载必要的环境模块(根据你的超算环境可能需要调整)
module load gcc/10.3
module load miniforge/24.1.2
module load cuda/11.8
# 激活conda环境
conda activate qwen_ft
# 切换到工作目录
cd /home/ft_ssh
# 设置CUDA可见设备
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
# 运行训练脚本
python ./train.py \
--num_nodes=1 \
--num_processes_per_node=8 \
--master_port=29500
7. 数据与模型上传
我原本打算直接在服务器上下载代码和数据集,但由于无法访问外网,我不得不将它们上传到服务器。数据集的下载尤为耗时,尤其是从Hugging Face平台。
8. 运行与监控
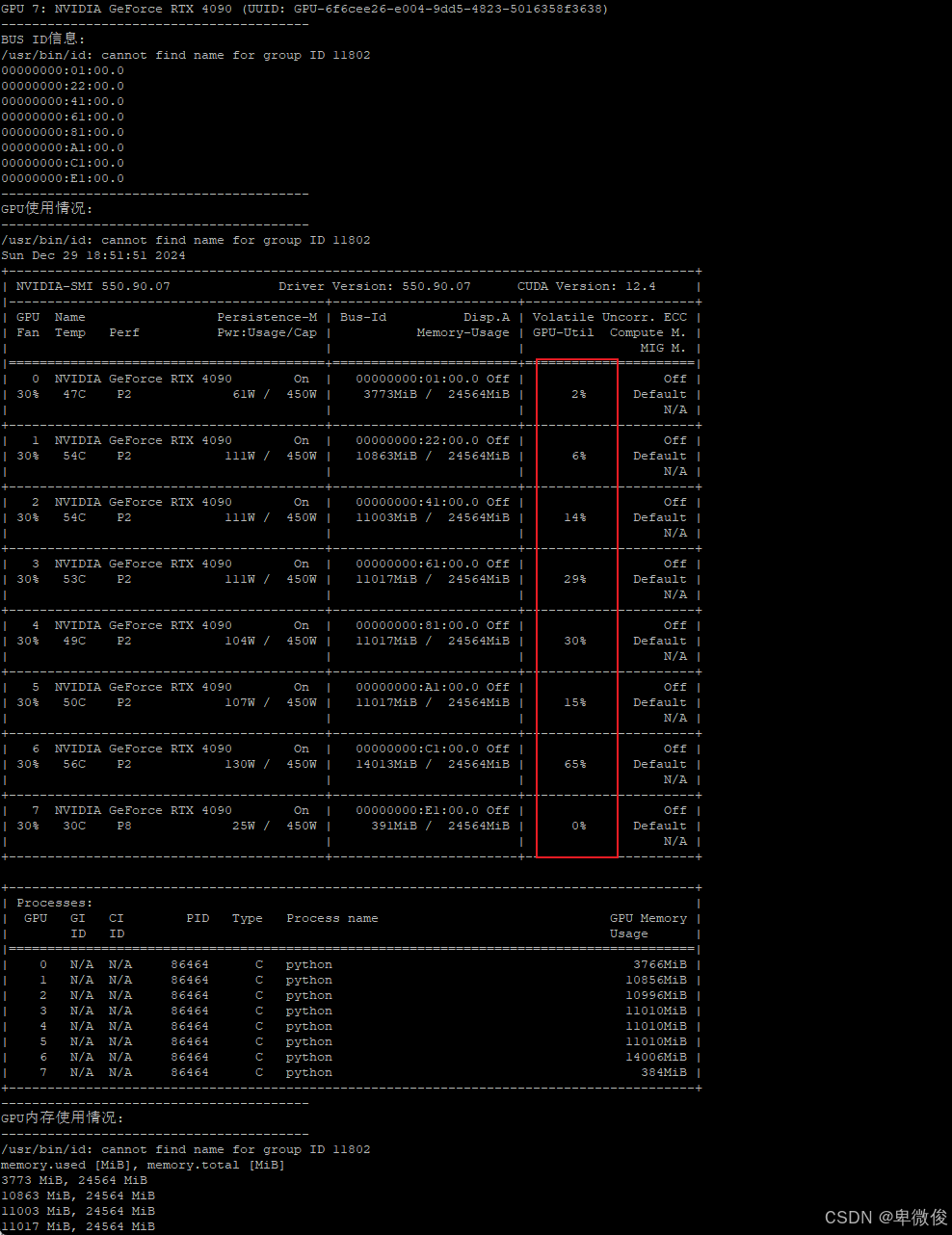
使用sbatch命令提交作业后,我通过作业ID监控输出。我还编写了一个脚本check_gpu.sh来检查GPU的使用情况,发现GPU并未完全利用。
关于如何找到对应的文件,这是cd和ls命令的使用,可以借鉴一下。

进入该文件夹下,之后直接用sbatch -p gpu_4090 --gpus=8 submit.sh运行就行了。运行之后会输出这个作业的id了,记住这个id,非常有用。比如用tail -f slurm-作业id.out就能查看输出了。一般提交成功都会有.out文件输出,就在当前路径下。

#!/bin/bash
# 检查是否提供了作业ID
if [ -z "$1" ]; then
echo "请提供作业ID"
echo "使用方法: ./check_gpu.sh <作业ID>"
exit 1
fi
# 获取作业信息
JOBID=$1
GPUNUMS=`scontrol show jobs ${JOBID}|grep "gres:gpu" |awk -F ':' '{print $3}'`
GPUHOST=`scontrol show jobs ${JOBID}|grep "NodeList="|sed -n '2p'|awk -F '=' '{print $2}'`
# 打印基本信息
echo "作业信息:"
echo "----------------------------------------"
echo "作业ID: ${JOBID}"
echo "节点主机: ${GPUHOST}"
echo "GPU数量: ${GPUNUMS}"
echo "----------------------------------------"
# 打印GPU详细信息
echo "GPU详细信息:"
echo "----------------------------------------"
echo "UUID信息:"
ssh ${GPUHOST} "nvidia-smi -L"
echo "----------------------------------------"
echo "BUS ID信息:"
ssh ${GPUHOST} "nvidia-smi -q|grep 'Bus Id'|sed -e 's/^.*: //' -e 's/ $//'"
echo "----------------------------------------"
# 打印GPU使用情况
echo "GPU使用情况:"
echo "----------------------------------------"
ssh ${GPUHOST} "nvidia-smi"
echo "----------------------------------------"
# 打印GPU内存使用情况
echo "GPU内存使用情况:"
echo "----------------------------------------"
ssh ${GPUHOST} "nvidia-smi --query-gpu=memory.used,memory.total --format=csv"
使用方法是,bash check_gpu.sh 作业id
然后果然,gpu没跑满,
结语
好了,我也就到这了,后面怎么优化,我是实在搞不下去了。就让他这么跑吧,其实我是尝试了一下,但是失败了。如果有人尝试成功了,记得分享一下。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









