







 本文详细介绍了Hadoop和Spark的启动与管理命令,包括HDFS和YARN服务的启动与停止,Spark的本地、独立集群和Spark-on-Yarn模式的启动,以及Hive的启动和服务。此外,还提到了Hive的两种客户端工具,第一代Hive和第二代Beeline的使用方法。
本文详细介绍了Hadoop和Spark的启动与管理命令,包括HDFS和YARN服务的启动与停止,Spark的本地、独立集群和Spark-on-Yarn模式的启动,以及Hive的启动和服务。此外,还提到了Hive的两种客户端工具,第一代Hive和第二代Beeline的使用方法。
Hadoop和Spark命令
Hadoop启动命令
启动HDFS服务
start-dfs.sh
stop-dfs.sh
启动YARN服务
start-yarn.sh
stop-yarn.sh
启动同时启动
start-all.sh
stop-yarn.sh
Spark模式
Local本地模式
先启动hdfs服务
start-all.sh
或者
start-dfs.sh
启动交互式服务
/export/server/spark-3.0.1-bin-hadoop2.7/bin/spark-shell
独立集群模式
先启动hadoop的hdfs服务
start-all.sh
或者
start-dfs.sh
启动集群
/export/server/spark-3.0.1-bin-hadoop2.7/sbin/start-all.sh
启动交互式服务
/export/server/spark-3.0.1-bin-hadoop2.7/bin/spark-shell --master spark://node1:7077
完成上面两个命令就可以了
在主节点上单独启动和停止Master:
/export/server/spark-3.0.1-bin-hadoop2.7/sbin/start-master.sh
/export/server/spark-3.0.1-bin-hadoop2.7/sbin/stop-master.sh
在从节点上单独启动和停止Worker(Worker指的是slaves配置文件中的主机名)
/export/server/spark-3.0.1-bin-hadoop2.7/sbin/start-slaves.sh
/export/server/spark-3.0.1-bin-hadoop2.7/sbin/stop-slaves.sh
在主节点上停止服务
/export/server/spark-3.0.1-bin-hadoop2.7/sbin/stop-all.sh
Spark-On-Yarn模式
- 启动HDFS和YARN
start-dfs.sh
start-yarn.sh
或
start-all.sh
- 启动MRHistoryServer服务,在node1执行命令
mr-jobhistory-daemon.sh start historyserver
- 启动Spark HistoryServer服务,在node1执行命令
/export/server/spark-3.0.1-bin-hadoop2.7/sbin/start-history-server.sh
Hive启动
启动Hive前先启动hadoop服务
启动Hive服务有两种方式,前台启动和后台启动
服务端
前台启动
/export/server/apache-hive-3.1.2-bin/bin/hive --service metastore
前台启动开启debug日志
/export/server/apache-hive-3.1.2-bin/bin/hive --service metastore --hiveconf
hive.root.logger=DEBUG,console
后台启动
- 启动metastore服务
输出日志信息在/root目录下nohup.out
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &
- 启动hiveserver2服务
输出日志信息在/root目录下nohup.out
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
当metastore和hiveserver2同时启动时,应该有两个RunJar进程分别对应这两个服务,可以使用jps命令查看
客户端
客户端启动一般是在另一台主机上,比如服务端在node1上启动,客户端在node3上启动
Hive发展至今,总共历经了两代客户端工具。
- 第一代客户端(deprecated不推荐使用):
$HIVE_HOME/bin/hive
是一个 shellUtil。主要功能:一是可用于以交互或批处理模式运行Hive查询;二是用于Hive相关服务的启动,比如metastore服务
- 第二代客户端(recommended 推荐使用):
$HIVE_HOME/bin/beeline
是一个JDBC客户端,是官方强烈推
荐使用的Hive命令行工具,和第一代客户端相比,性能加强安全性提高
两代客户端的关系及其启动
第一代和第二代的关系如下
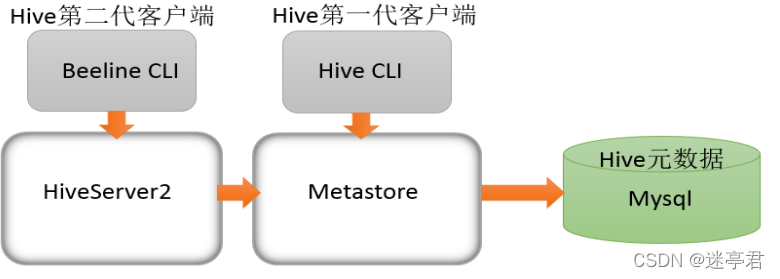
可见,想要启动第二代客户端必须先启动第一代
想要启动,必须满足如下条件
- hadoop已启动
start-all.sh
- hive服务器已启动
在hive安装的服务器上(node1),首先启动metastore服务,然后启动hiveserver2服务
# 先启动metastore服务 然后启动hiveserver2服务
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
- 在另一台安装了hive的服务器上(node3)使用beeline客户端进行连接访问,需要注意hiveserver2服务启动之后需要稍等一会才可以对外提供服务
[root@node3 ~]# /export/server/apache-hive-3.1.2-bin/beeline
之后输入连接url即可连接
! connect jdbc:hive2://node1:10000
完整显示如下
# 输入连接url
beeline> ! connect jdbc:hive2://node1:10000
Connecting to jdbc:hive2://node1:10000
# 输入连接用户名,这里为root
Enter username for jdbc:hive2://node1:10000: root
# 输入连接密码,这里没有设置密码
Enter password for jdbc:hive2://node1:10000:
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node1:10000>

















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









