







系列文章:
第一章 Hadoop集群搭建的准备
第二章 Hadoop集群搭建
第三章 Zookeeper分布式集群部署(2n+1台虚拟机)
第四章 Hadoop高可用集群搭建(HA)
待更新
第九章 spark独立模式部署(Standalone)
第十章 spark配置历史服务
第十一章 搭建Spark高可用(HA)
第十二章 spark配置Yarn模式(混合部署模式)
待更新
文章目录
前言
博客推荐系统是向用户推荐可能感兴趣的博客的系统。分为游客状态和登录状态(功能:展示最新的博客、推荐热度最高的博客、按分类推荐博客、登录注册、点赞收藏、修改个人资料、发表管理博客、管理收藏的博客以及针对用户喜好推荐博客。)。效果预览
- 游客状态访问时的状态


- 游客状态可以注册账号并登录成为用户状态


- 登录后是用户空间,用户可以修改自己的昵称、密码、联系方式等信息

- 发表博客

- 管理个人发表过的博客

- 管理收藏的博客

- 浏览系统针对用户喜好个性化推荐博客

- 用户状态的首页,右上角由之前的“登录”变为“我的”,点击“我的”即可进入用户空间

一、设计环境
语言:Java、Shell、HTML、CSS、JavaScript、SQL
环境:jdk1.8.0、CentOS6.9、MySQL8.0.21、Apache Tomcat v8.5、Hadoop
二、设计思想
先在Linux服务器上部署Apache Tomcat环境,并搭建Hadoop集群,然后上传JavaWeb项目以及MapReduce实现的推荐算法。最后编写推荐算法自动化脚本定时执行推荐算法,将结果上传到MySQL数据库中,整个项目的设计流程如图所示。
三、推荐算法
1、推荐算法简述
推荐算法使用了基于物品的协同过滤算法,该算法是基于物品与物品的关联程度以及用户对一些物品的评分来预测该用户对其它物品的评分,然后将预测评分较高的物品推荐给用户。
课程设计中则是需要根据用户行为表中的点赞和收藏行为按照不同的权重计算用户对浏览过的博客的评分,然后将用户ID、博客ID以及用户对该博客的评分三种字段的数据采集到文本文件中,用作算法的原始输入数据。
算法需要从原始数据中提取出博客的同现矩阵(即博客与博客之间的关联度,关联程度是同时对两个博客评过分数的总人数)以及每个用户的评分矩阵(即某用户对所有物品的评分),然后将两个矩阵相乘。
算法借鉴了Thinkgamer的CSDN博客,通过他的博客我了解到了该算法如何通过MapReduce实现,并试着看懂代码后进行了复现。
2、MapReduse实现基于物品的协同过滤算法
通过MapReduse实现该算法需要三部分,分别是生成同现矩阵C1、生成评分矩阵C2和C2_1以及矩阵计算C4和C4_1。
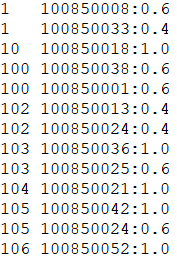
第一步生成评分矩阵,输入是原始数据,输出为“<博客ID 用户ID:评分>”格式。
/*
* <0 用户ID 博客ID 评分>
*/
//map阶段
public static class C1Mapper extends Mapper<LongWritable,Text,Text,Text>{
static Text k1 = new Text(); //key
static Text v1 = new Text();//value
@Override
protected void map(LongWritable key,Text value,Context context)
throws IOException, InterruptedException {
String line=value.toString();
String[] ones=line.split("\t");
k1.set(ones[1]);
v1.set(ones[0]+":"+ones[2]);
context.write(k1,v1);
System.out.println(k1+" "+v1);
}
}
/*
* <博客ID 用户ID:评分>
*/
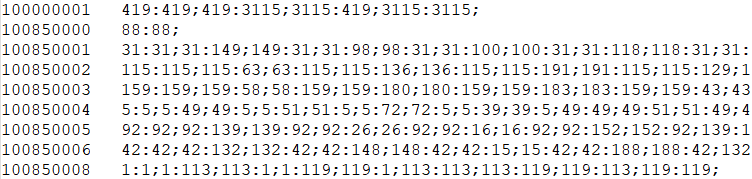
第二步生成博客的同现矩阵,该步骤由两组MapReduce程序实现,C2和C2_1。
第一组的输入是原始数据,输出是“<用户ID 博客ID:博客ID;博客ID:博客ID;>”格式为初步数据处理格式。
/*
* <0 用户ID 博客ID 评分>
*/
//map阶段
public static class C2Mapper extends Mapper<LongWritable,Text,Text,Text>{
static Text k1 = new Text();
static Text v1 = new Text();
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] list = line.split("\t");
k1.set(list[0]);
v1.set(list[1]);
context.write(k1, v1);
System.out.println(k1+":"+v1);
}
}
/*
* <用户ID 博客ID>
*/
//reduce阶段,键相同的数据作为一个集合传入
public static class C2Reducer extends Reducer<Text,Text,Text,Text>{
static Text result = new Text();
protected void reduce(Text key,Iterable<Text> values,Context context) throws IOException, InterruptedException {
ArrayList<String> c2List = new ArrayList<String>();
for (Text value:values) {
String value1 = value.toString();
c2List.add(value1);
}
String one = new String();
while (true) {
for (String c2one:c2List) {
if (c2List.get(0)!=c2one)
one+=c2List.get(0)+":"+c2one+";"+c2one+":"+c2List.get(0)+";";
else
one+=c2List.get(0)+":"+c2one+";";
}
if (c2List!=null)
c2List.remove(0);
if (c2List.size()==0)
break;
}
// System.out.println(one);
result.set(one);
context.write(key, result);
System.out.println(key+"\t"+result);
}
}
/*
* <用户ID 博客ID:博客ID;博客ID:博客ID;博客ID:博客ID>
*/
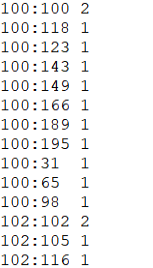
第二组的输入是C2中同现矩阵初步处理结果,输出是“<博客ID:博客ID 同时对两个博客打过分的总人数>”格式,此为同现矩阵的最终处理结果。
/*
* <0 用户ID 博客ID:博客ID;博客ID:博客ID;博客ID:博客ID>
*/
//map阶段
public static class C2Mapper extends Mapper<LongWritable,Text,Text,Text>{
static Text k1 = new Text();
static Text v1 = new Text();
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] list = line.split("\t");
// System.out.println(list[0]+" "+list[1]);
String[] list1 = list[1].split(";");
for (String one:list1) {
k1.set(one);
v1.set("1");
// System.out.println(one+"_"+v1);
context.write(k1, v1);
System.out.println(k1+" "+v1);
}
}
}
/*
* <博客ID:博客ID 1>
*/
//reduce阶段
public static class C2Reducer extends Reducer<Text,Text,Text,IntWritable>{
static Text result = new Text();
protected void reduce(Text key,Iterable<Text> values,Context context) throws IOException, InterruptedException {
int count = 0;
for (@SuppressWarnings("unused") Text value:values) {
count += 1;
}
context.write(key, new IntWritable(count));
System.out.println(key+"\t"+new IntWritable(count));
}
}
/*
* <博客ID:博客ID 同时对两个博客发生行为的总人数>
*/
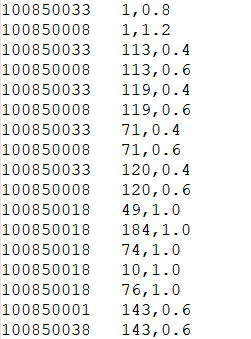
第三步由两组MapReduce程序实现,C4和C4_1。
第一组的输入是C1和C2_1的输出结果,输出是“<用户ID 推荐的博客ID,推荐分数>”格式为初步数据处理格式(C4的输出结果是<用户ID 推荐的博客ID,推荐分数>,这里的分数并不是最终的推荐分数,而是某一用户对各个博客的评分乘以被该用户评分的博客与被推荐博客的关联度。),需要做进一步的汇总。
public static class C4Mapper extends Mapper< LongWritable, Text, Text, Text>{
String filename;
@Override
protected void setup(Context context) throws IOException,InterruptedException {
// TODO Auto-generated method stub
InputSplit input = context.getInputSplit();
filename = ((FileSplit) input).getPath().getParent().getName();
// System.out.println("FileName:" +filename);
}
/*
* C2_1:<0 博客ID:博客ID 同时对两个博客发生行为的总人数>
* C1:<0 博客ID 用户ID:评分>
*/
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
if (filename.equals("c2_1output")) {
String line1 = value.toString();
String[] list1 = line1.split("\t");
//list1[0] 101:101
//list1[1] 5
String[] one1 = list1[0].split(":");
//one1[0] 101
//one1[1] 101
Text key1 = new Text(one1[0]);
Text value1 = new Text("A:" + one1[1] +"," +list1[1]);
context.write(key1,value1);
System.out.println(key1+" "+value1);
}
else {
String line = value.toString();
String[] list = line.split("\t");
//list[0] 101
//list[1] 1:5.0
// System.out.println(list[0]);
String[] one = list[1].split(":");
//one[0] 100850003
//one[1] 5.0
Text key2 = new Text(list[0]);
Text value2 = new Text("B:" + one[0] + "," + one[1]);
context.write(key2,value2);
System.out.println(key2+" "+value2);
}
}
}
/*
* <博客ID A:博客ID,同时对两个博客发生行为的总人数>
* <博客ID B:用户ID,评分>
*/
//reduce阶段,键相同的数据作为一个集合传入
public static class C4Reducer extends Reducer<Text,Text,Text,Text>{
static Text result = new Text();
protected void reduce(Text key,Iterable<Text> values,Context context) throws IOException, InterruptedException {
Map<String, String> mapA = new HashMap<String, String>();
Map<String, String> mapB = new HashMap<String, String>();
for(Text line : values){
String val = line.toString();
if(val.startsWith("A")){
String[] kv = val.substring(2).split(",");
mapA.put(kv[0], kv[1]); //ItemID, num
}else if(val.startsWith("B")){
String[] kv = val.substring(2).split(",");
mapB.put(kv[0], kv[1]); //userID, score
}
}
double result = 0;
// Iterator是迭代器类
Iterator<String> iterA = mapA.keySet().iterator();
while(iterA.hasNext()){
String mapkA = (String) iterA.next(); //itemID
int num = Integer.parseInt((String) mapA.get(mapkA)); // num
Iterator<String> iterB = mapB.keySet().iterator();
while(iterB.hasNext()){
String mapkB = (String)iterB.next(); //UserID
double score = Double.parseDouble((String) mapB.get(mapkB)); //score
result = num * score; //矩阵乘法结果
Text key2 = new Text(mapkB);
Text value2 = new Text(mapkA + "," +result);
context.write(key2,value2); //userID \t itemID,result
System.out.println(key2+ "\t" + value2);
}
}
}
}
/*
* <用户ID 推荐的博客ID,推荐分数>
*/
第二组是将C4中矩阵相乘的输出结果进行汇总,输出是“<用户ID 推荐的博客ID 推荐分数>”格式,此为推荐算法的最终处理结果。
public static class C4_1Mapper extends Mapper<LongWritable, Text, Text, Text>{
/*
* <0 用户ID 推荐的博客ID,推荐分数>
*/
@Override
protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
// TODO Auto-generated method stub
String line1 = value.toString();
String[] list = line1.split("\t");
//list[1] 101,25.0
String[] list1 = list[1].split(",");
Text key1 = new Text(list1[0]+ "," +list[0]);//userID
Text value1 = new Text(list1[1]);
context.write(key1, value1); //itemID,result
System.out.println(key1+"\t"+value1);
}
}
/*
* <推荐的博客ID,用户ID 推荐分数>
*/
public static class C4_1Reducer extends Reducer< Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException {
// TODO Auto-generated method stub
float num = 0;
for (Text value:values) {
Double result = Double.parseDouble(value.toString());
num += result;
// System.out.println(key+":"+value);
}
String[] oneList = key.toString().split(",");
//oneList[0] 101
//oneList[1] 1
Text k1 = new Text(oneList[1]);
Text v1 = new Text(oneList[0]+"\t"+String.valueOf(num));
context.write(k1, v1);
System.out.println(k1+"\t"+v1);
}
}
/*
* <用户ID 推荐的博客ID 推荐分数>
*/
3、推荐算法自动化Shell脚本
考虑到用户的行为以及数据库中的博客是实时变化的,因此对于针对用户所推荐的博客也应该是实时更新变化的。而实现这种功能,就需要编写执行协同过滤推荐算法的Shell脚本,并在Linux服务器中设置定时任务,定时执行Shell脚本。
Shell脚本主要分为三部分,数据采集上传、执行推荐算法jar包下载推荐结果、创建推荐表并将推荐结果保存到推荐表。
首先需要导入环境变量并在服务器与HDFS上创建所需的工作路径。
#!/bin/bash
#必须导入环境变量,否则Hadoop命令无法执行
source /etc/profile
#Hadoop大作业在HDFS中的工作路径
work_dir=/hadoopbigwork/
#打分表存放地址
score_dir=/hadoopwork/score/
score_file=scoredata.txt
#待上传文件HDFS路径
score_dfs_dir=/hadoopbigwork/score/
#mapreduce的jar包执行结果输出路径本地
maybe_text=/hadoopworkmybe/maybe/
#jar包保存路径
jarpath=/hadoopwork/jars/
#判断打分目录是否存在,不存在创建
if [ ! -d $score_dir ]
then
mkdir -p $score_dir
echo -e "this is $score_dir success ! "
else
echo -e "directory already exists !"
#清空/export/score/下的打分文件
rm -rf $score_dir
mkdir -p $score_dir
fi
从behavior表采集用户ID、博客ID、打分(点赞0.4+收藏0.6)的数据,并将数据上传到HDFS上作为算法的输入的原始数据。
# behavior表提取用户id、博客id、打分(点赞*0.4+收藏*0.6)
mysql -uroot -p123456 boke -N -e "select user_id,text_id,text_good*0.4+text_save*0.6 score from behavior;">$score_dir$score_file
#删除HDFS下的/score/目录,创建空白的/score/
#Hadoop离开安全状态
hdfs dfsadmin -safemode leave
hdfs dfs -rm -r -f $work_dir
hdfs dfs -mkdir -p $score_dfs_dir
#将打分表上传到HDFS下的/score/路径
hdfs dfs -put $score_dir$score_file $score_dfs_dir
执行算法jar包,将推荐结果下载到服务器本地。
#执行协同过滤的jar包
hadoop jar $jarpath"ItemCF.jar" com.work.test.C1 $score_dfs_dir $work_dir"c1output"
hadoop jar $jarpath"ItemCF.jar" com.work.test.C2 $score_dfs_dir $work_dir"c2output"
hadoop jar $jarpath"ItemCF.jar" com.work.test.C2_1 $work_dir"c2output" $work_dir"c2_1output"
hadoop jar $jarpath"ItemCF.jar" com.work.test.C3 $work_dir"c1output" $work_dir"c3output"
hadoop jar $jarpath"ItemCF.jar" com.work.test.C4 $work_dir"c2_1output" $work_dir"c3output" $work_dir"c4output"
hadoop jar $jarpath"ItemCF.jar" com.work.test.C4_1 $work_dir"c4output" $work_dir"resultoutput"
#判断是否存在本地的/hadoopwork/maybe/目录,没有则创,有则清空目录下的文件
if [ ! -d $maybe_text ]
then
mkdir -p $maybe_text
echo -e "this is $maybe_text success ! "
else
echo -e "directory already exists !"
#清空/export/score/下的打分文件
rm -rf $maybe_text
mkdir -p $maybe_text
fi
#将结果文件从HDFS中导出到本地
hdfs dfs -get $work_dir"resultoutput/part-r-00000" $maybe_text
创建博客推荐表,将算法推荐结果上传到博客推荐表中。
#如果表不存在,则创建
mysql -uroot -p123456 --local-infile boke -N -e "
CREATE TABLE if not exists item_cf (user_id varchar(20) NOT NULL COMMENT '用户ID',
text_id varchar(20) NOT NULL COMMENT '博文ID',
score float NOT NULL COMMENT '分数')
DEFAULT CHARSET=utf8;"
#清空推荐表
mysql -uroot -p123456 --local-infile boke -N -e "truncate table item_cf;"
#将结果汇总到MySQL中
mysql -uroot -p123456 --local-infile boke -N -e "set global local_infile=1;load data local infile'$maybe_text"part-r-00000"'
into table item_cf fields terminated by '\t'
lines terminated by '\n';"
四、创建JavaWeb项目编写博客推荐系统的动态网页
JavaWeb项目包含游客状态(即未登录状态)和用户状态(即登录状态)。当处于游客状态时,可以浏览首页中全网近期发布的博客,热榜中热度较高的博客,以及可以按照不同的类别查看热度较高的博客,还可以对喜欢的博客进行点赞,但是不可以收藏。游客状态可以通过注册账号登录网站变成用户状态,用户状态除了拥有游客状态的所有功能外还可以收藏喜欢的博客、发表管理自己的博客、更改自己的用户资料,此外系统还会根据用户在网站上的一些行为(目前为点赞、收藏)对用户推荐其可能感兴趣的博客。
五、将整个项目搭建到Linux服务器上
第一步,先在CentOS系统的服务器上安装jdk1.8.0、MySQL8.0.21、Apache Tomcat v8.5、Hadoop然后配置相关的配置文件完成基础设置,保证项目环境处于正常状态。
第二步,创建所需的数据库,并创建博客表、用户表、用户行为表,将采集到的数据分别上传到三张表中。
第三步,将JavaWeb项目打包成war包,部署到/home/apache-tomcat-8.5.72/webapps目录下,然后执行/home/apache-tomcat-8.5.72/bin/startup.sh,开启apache-tomcat环境。
第四步,将推荐算法打包成jar包上传到服务器中/hadoopwork/jars目录下,然后将推荐算法自动化Shell脚本上传到服务器的/hadoopwork/run_itemCF_jar目录下,最后在服务器终端上输入“crontab -e”命令打开定时任务配置文件,写入每三分钟执行一次推荐算法自动化Shell脚本的定时任务,并启动Hadoop集群和定时服务,定时任务如图所示。

第五步,关闭服务器的防火墙,使客户端即本机与服务器能够相互访问,在客户端上打开浏览器输入http://192.168.121.134/Hadoopbigwork/recommend.html,检验是否能成功可访问部署的博客网站。
六、项目文件下载
项目文件下载:https://download.csdn.net/download/qq_49101550/75671450
















 1050
1050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











