







前三组参赛选手:
👉第一组:插入排序,希尔排序
👉第二组:选择排序,堆排序
👉第三组:冒泡排序,快速排序(划重点)
1️⃣必备排序常识
稳定性:在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求能在内存和硬盘(外部存储器)之间移动数据的排序。
时间复杂度:一个排序算法在执行过程中所耗费的时间量级的度量。
空间复杂度:一个排序算法在运行过程中临时占用存储空间大小的度量。
归并排序可以实现内排序和外排序。
2️⃣归并排序
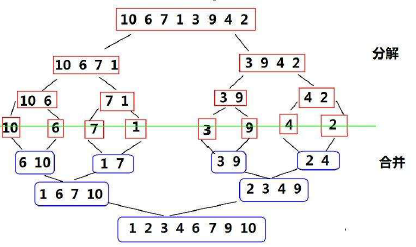
1.排序原理和过程
排序原理:
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
过程展示:

2.递归实现
在排序的过程中,只依靠原数组进行排序显然是不现实的,所以需要开辟额外的空间将每次排好的值写回原数组中,最后一次写入时数组就已经排好顺序了。
写法一:每次归并开辟空间
在每次归并排序数组元素的时候,额外开辟一个和待排序元素一样大的空间辅助排序。
代码实现:
/**
* 归并排序,写法一
* 每次归并时开辟临时数组
* @param arr
*/
public static void mergeSortVersion1(int[] arr){
mergerSort2(arr,0,arr.length - 1);
}
private static void mergerSort2(int[] arr, int left, int right) {
if(right - left <= 15){
// 小区间直接使用插入排序
insertSortRange(arr,left,right);
return;
}
int mid = left + ((right - left) >> 1);
// 将原数组拆分为左右两个小区间,分别递归进行归并排序
// 走完这个函数之后 arr[l..mid]已经有序
mergerSort2(arr,left,mid);
// 走完这个函数之后 arr[mid + 1..r]已经有序
mergerSort2(arr,mid + 1,right);
if(arr[mid] > arr[mid + 1]) {
//只有左右两个子区间还有先后顺序不同时才merge
merge1(arr, left, mid, right);
}
}
private static void merge1(int[] arr, int left, int mid, int right) {
// 先创建一个新的临时数组tmp
int[] tmp = new int[right - left + 1];
// 将arr元素值拷贝到tmp上
for (int i = 0; i < tmp.length; i++) {
tmp[i] = arr[left + i];
}
// l1就是左侧小数组的开始索引
int l1 = left;
// l2就是右侧小数组的开始索引
int l2 = mid + 1;
// i表示当前正在合并的原数组的索引下标
for(int i = left;i <= right; i++){
if(l1 > mid){
// 左侧区间已经被处理完毕,只需要将右侧区间的值拷贝原数组即可
arr[i] = tmp[l2 - left];
l2++;
}else if(l2 > right){
// 右侧区间已经被处理完毕,只需要将左侧区间的值拷贝到原数组即可
arr[i] = tmp[l1 - left];
l1++;
}else if(tmp[l1 - left] <= tmp[l2 - left]){
// 此时左侧区间的元素值较小,相等元素放在左区间,保证稳定性
arr[i] = tmp[l1 - left];
l1++;
}else{
// 右侧区间的元素值较小
arr[i] = tmp[l2 - left];
l2++;
}
}
}
private static void insertSortRange(int[] arr, int left, int right) {
for (int i = left; i < right; i++) {
//比较如果不需要插入则直接进入下次循环
if(arr[i] > arr[i + 1]){
int j = i;
//将需要插入的元素保存
int tmp = arr[i + 1];
//寻找合适的位置,这里的j指向需要插入的前一个元素
for (; j >= left && arr[j] > tmp; j--);
//将该位置和后面已经排好序的元素一次往后移动
for (int k = i;k > j; k--) {
arr[k + 1] = arr[k];
}
//将该元素放在该位置上
arr[j + 1] = tmp;
}
}
}
写法二:直接开辟一样大的空间
在一开始就开辟一个和数据一样的空间,不用像写法一需要改变下标,因为辅助空间和原数组是一样大的,所以可以将下标直接对应。而且一次性开辟数组,会比每次归并排序都开辟一个辅助空间要节省时间。
/**
* 归并排序,写法二
* 在一开始就定义和原数组一样大的空间
* @param arr
*/
public static void mergeSortVersion2(int[] arr) {
int[] temp = new int[arr.length];//额外的辅助空间
mergeSortHelper2(arr, 0, arr.length - 1, temp);
}
private static void mergeSortHelper2(int[] arr, int left, int right, int[] temp) {
if(right - left <= 15) {
insertSortRange(arr,left,right);
return;
}
int mid = left + ((right - left) >> 1);
mergeSortHelper2(arr,left,mid,temp);
mergeSortHelper2(arr,mid + 1,right,temp);
//当arr[mid]<arr[mid + 1]时,这个小区间已经有序了,就不需要再排序了
if(arr[mid] > arr[mid + 1]) {
merge2(arr, left, mid, right, temp);
}
}
private static void merge2(int[] arr, int left, int mid, int right, int[] temp) {
int l1 = left;
int l2 = mid + 1;
int index = left;
//循环比较数组元素,将其写到辅助数组对应空间上
//当左右区间有一边元素完成排序就跳出循环
while(l1 <= mid && l2 <= right){
if(arr[l1] <= arr[l2]){
temp[index++] = arr[l1++];
}else{
temp[index++] = arr[l2++];
}
}
//左区间还有元素,而且不需要排序,直接写到辅助空间上
while(l1 <= mid){
temp[index++] = arr[l1++];
}
//右区间还有元素
while(l2 <= right){
temp[index++] = arr[l2++];
}
//将排序完的元素写回原数组中
for (int i = left; i <= right; i++) {
arr[i] = temp[i];
}
}
3.非递归实现
非递归实现排序时,就不能依靠递归帮助实现分治了。这里需要自己设置控制间隔,合理控制循环,从小到大将其排好顺序写入原数组。非递归也是需要额外的空间来帮助排序的。
不过,在非递归实现算法时,需要自己考虑边界控制。例如当gap == 4的时候,按理来说是两个四个元素的数组进行排序,但是当元素只有7个或9个的时候,就要对边界进行控制了。如果是左区间有值,而右半区间不存在,就可以跳过留给后面,当循环进行到后面的时候就会进行排序;或者右半区间算多了的情况,就要对区间进行修正。
代码实现:
public static void mergeSortNonRecursion(int[] arr){
int[] tmp = new int[arr.length];
for (int gap = 1; gap < arr.length; gap <<= 1) {
// 内层循环的变量i表示每次合并的开始索引
// i + gap 就是右区间的开始索引,i + gap < arr.length说明还存在右区间
for (int i = 0; i + gap< arr.length; i += gap * 2) {
merge2(arr,i,i + gap - 1,Math.min(i + 2 * gap - 1,arr.length - 1),tmp);
}
}
}
4.特性总结
- 归并的缺点在于需要O(n)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(n*logn)
- 空间复杂度:O(n)
- 稳定性:稳定
5.用归并排序实现外排序
上面介绍的其他排序算法均是在内存中进行的,对于数据量庞大的序列,上面介绍的排序算法都束手无策,而归并排序却能胜任这种海量数据的排序。
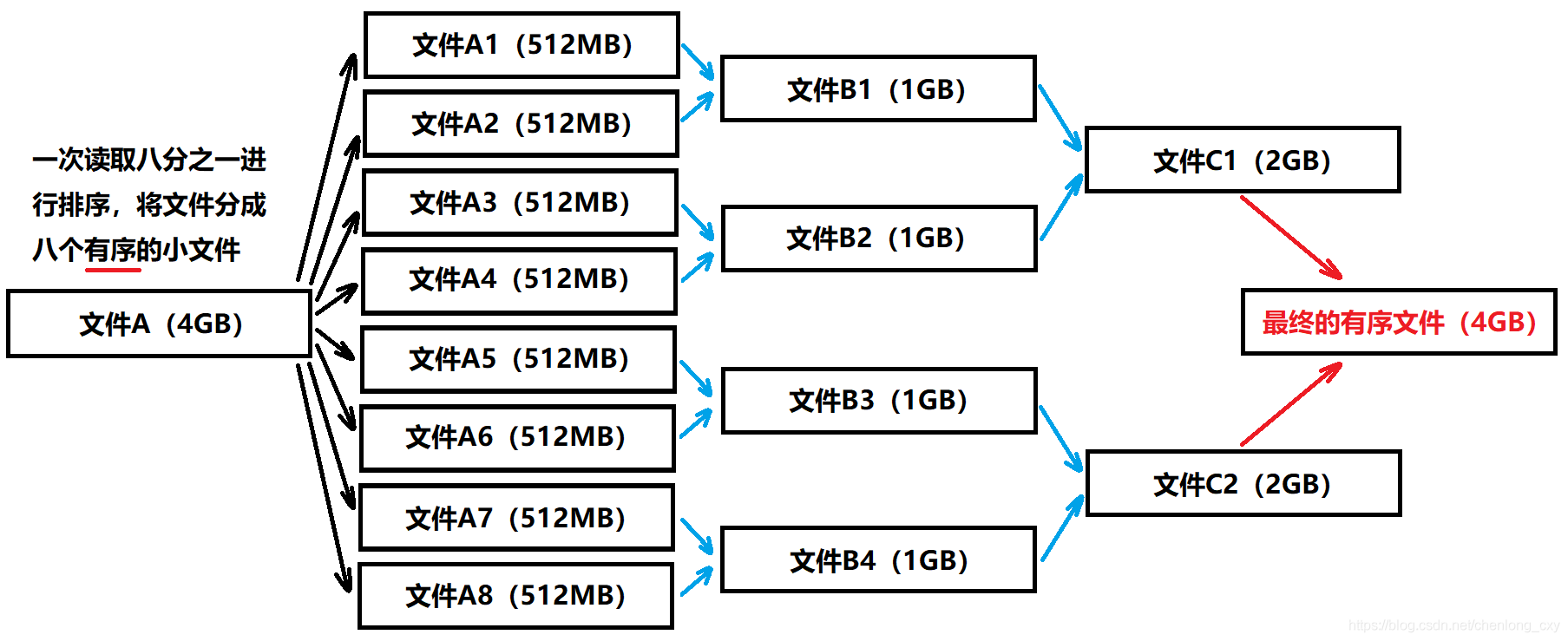
假设现在有10亿个整数(4GB)存放在文件A中,需要我们进行排序,而内存一次只能提供512MB空间,归并排序解决该问题的基本思路如下:
1、每次从文件A中读取八分之一,即512MB到内存中进行排序(内排序),并将排序结果写入到一个文件中,然后再读取八分之一,重复这个过程。那么最终会生成8个各自有序的小文件(A1~A8)。
2、对生成的8个小文件进行一一合并,最终8个文件被合成为4个,然后再一一合并,就变成2个文件了,最后再进行一次合并,就变成1个有序文件了。
注意:这里将两个文件进行一一合并,并不是先将两个文件读入内存然后进行合并,因为内存装不下。这里的一一合并是利用文件输入输出函数,从两个文件中各自读取一个数据,然后进行比较,将较小的数据写入到一个新文件中去,然后再读取,再比较,再写入,最终将两个文件中的数据全部写入到另一个文件中去,那么此时这个文件又是一个有序的文件了。
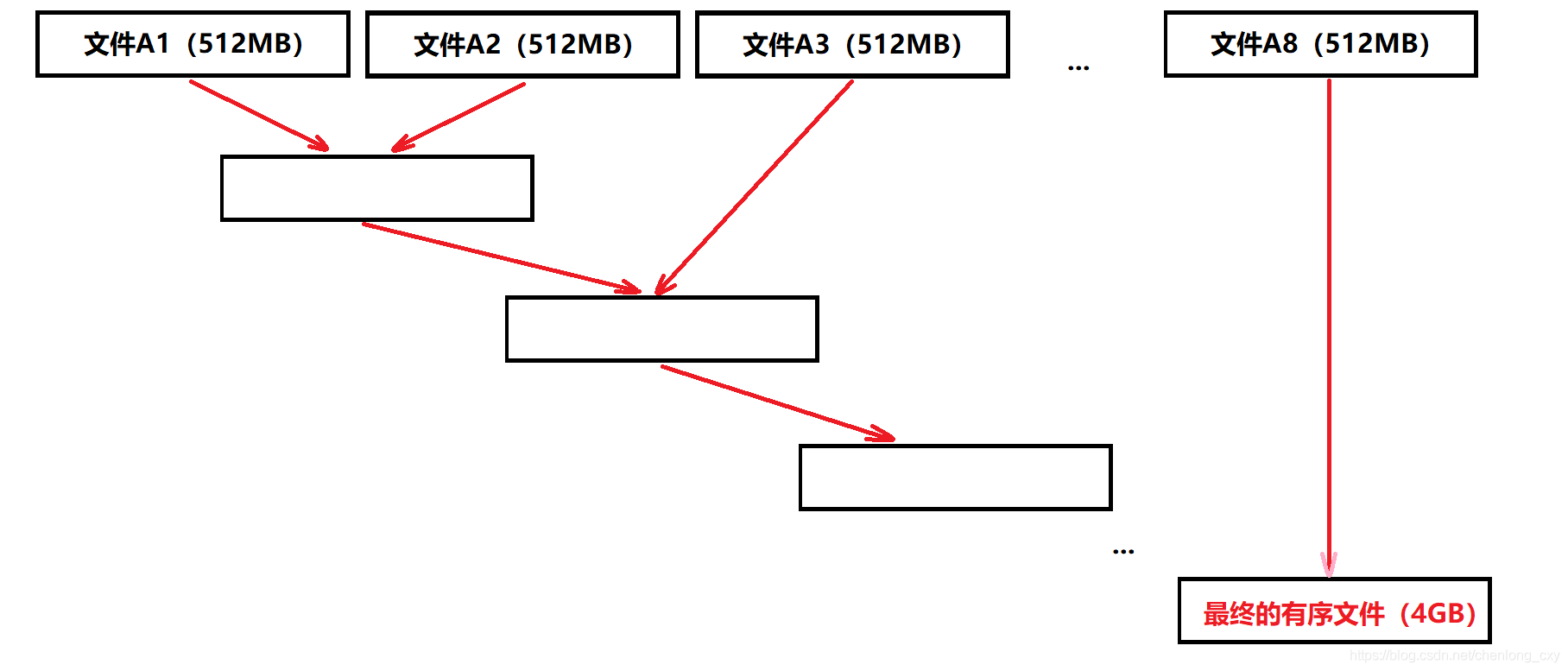
还可以每次从八个文件中各读取一个值,将这八个值排序完直接放入一个大文件中,重复这个过程,直到把八个文件的内容全部写入大文件中。
6.性能比较
归并排序不像快排那样排序接近有序的数组或有大量重复值的数组性能会衰减,它的性能是很稳定的。
一千万个随机数据
public static void main(String[] args) {
int n = 10000000;
int[] arr = SortHelper.generateRandomArray(n, 0, Integer.MAX_VALUE);
int[] arrCopy5 = SortHelper.arrCopy(arr);
int[] arrCopy6 = SortHelper.arrCopy(arr);
int[] arrCopy7 = SortHelper.arrCopy(arr);
SortHelper.testSort("mergeSortVersion1", arrCopy5);
SortHelper.testSort("mergeSortVersion2", arrCopy6);
SortHelper.testSort("mergeSortNonRecursion", arrCopy7);
}
运行结果:
可以看出第二种写法的归并排序,由于没有大量开辟临时数组,性能得以很大的提升。 非递归的写法性能也是很好,因为少去大量递归消耗栈桢的情况。 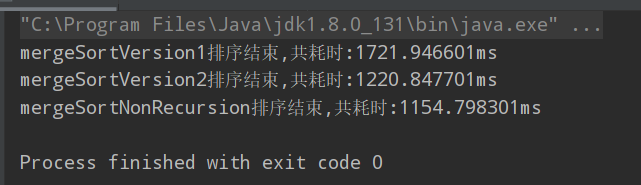
一千万个大量重复数据
int n = 10000000;
int[] arr = SortHelper.generateRandomArray(n,0, 1000);
运行结果:
在排序有大量重复元素的数组时,性能甚至更好。 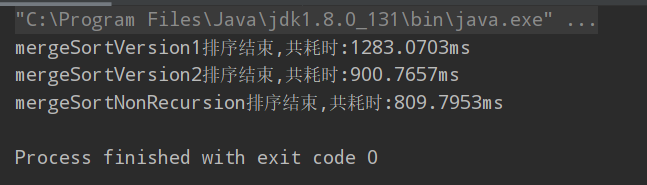
一千万个接近有序数据
int[] arr = SortHelper.generateSoredArray(n,1000);
运行结果:
得益于在小区间上使用插入排序,以及比较中点左右两个值判断两个区间是否需要排序。性能有很大提升。 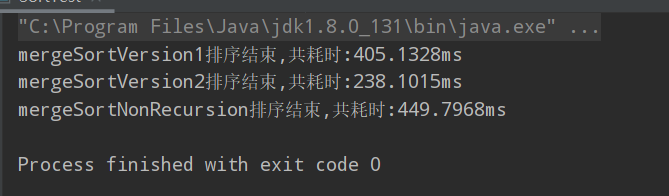
















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











