






消息传递机制的提出背景
消息传递机制是在一篇名为《Neural Message Passing for Quantum Chemistry》的论文里被正式提出(2017年)。这篇论文讲了GNN在化学上的一些应用,根据原子的性质和分子结构,预测了13种物质的化学性质。然而相较于应用,更重要的是,作者总结并系统化了之前的GNN方法并提出了消息传递神经网络(Message Passing Neural Networks, MPNNs)的通用框架。MPNN框架明确了以下几个关键步骤:
- 消息传递:定义消息函数来从邻居节点生成消息。
- 状态更新:使用接收到的消息来更新节点状态。
- 读出功能:从节点状态中提取总体图的特征。
DGL(Deep Graph Library)和 PyG(PyTorch Geometric)是两个主流的用于图神经网络(GNN)构建的工具库,它们都实现了消息传递机制,但方式有所不同。
DGL中的消息传递
在DGL中,消息传递过程通常由以下步骤组成:
1. 定义消息函数(Message Function):
需要定义一个消息函数,用于描述如何从源节点生成消息,并发送到所有相邻节点。例如:
def message_func(edges):
return {'msg': edges.src['h'] + edges.data['w']}消息函数接受一个参数 edges,在消息传递时,它被 DGL 在内部生成以表示一批边。edges 有 src、dst 和 data共3个成员属性,分别用于访问源节点、目标节点和边的特征。
2. 定义聚合函数(Reduce Function):
需要定义一个聚合函数,用于描述如何聚合接收到的消息。例如:
def reduce_func(nodes):
return {'h': torch.sum(nodes.mailbox['msg'], dim=1)}聚合函数接受一个参数 nodes 在消息传递时,它被 DGL 在内部生成以表示一批节点。nodes 的成员属性 mailbox 可以用来访问节点收到的消息。一些最常见的聚合操作包括sum、max、min等。
3. 实现消息传递:
可以用(1)send、recv(2)send_and_recv(3)update_all实现
(1)DGL 提供了 send 和 recv 方法来分开控制消息传递和聚合过程。send 方法用于让源节点向目标节点发送消息,recv 方法用于接收来自相邻节点的消息并对其进行聚合。
g.send(g.edges(), message_func)
g.recv(g.nodes(), reduce_func)(2)send_and_recv 是 send 和 recv 方法的组合,用于在一次操作中完成消息发送和接收。这个方法适合不需要分开控制发送和接收过程的情况,因此简化了操作。
g.send_and_recv(g.edges(), message_func, reduce_func)(3)update_all 方法是对 send 和 recv 组合的进一步简化。它封装了消息传递(send)和聚合(recv)的所有步骤,在一步操作内实现了消息传递机制。它适用于需要在图的所有节点上进行消息传递和聚合的情况。
g.update_all(message_func, reduce_func)具体可以参考dgl官方文档提供的信息。
PyG中的消息传递
PyG 通过 MessagePassing 类来实现消息传递机制。通过继承该类并重写message、aggregate 和 update 方法,用户可以实现几乎所有类型的消息传递机制。具体可以参考
MessagePassing类的主要方法
__init__方法构造函数,用于初始化消息传递的聚合方式,例如 add(加和)、mean(平均)、max(最大值)等。
forward方法这是消息传递层的主要接口,用户需要在这里定义调用 propagate 方法的逻辑。该方法接受节点特征和边索引,用户根据需要添加额外的参数。
propagate方法内部方法,不需要用户显式调用。该方法根据边索引(edge_index)确定消息传递的顺序,并自动调用以下几个方法(message、aggregate 和 update)。
message方法定义如何从源节点生成消息。message 方法的参数通常包括目标节点的索引和源节点的特征。用户可以在这里实现自定义的消息生成逻辑。
aggregate方法定义如何聚合收到的消息。该方法在 propagate 中自动调用,默认使用在 __init__ 中指定的聚合方式(如 add)。然而,用户也可以在这里覆盖默认的聚合逻辑。
update方法可选方法,用于根据聚合结果更新节点特征。默认情况下,该方法直接返回聚合结果,但用户可以覆盖它以实现更多自定义的特征更新逻辑。
具体可以参考pyg官方文档提供的信息。
基于DGL和PyG简单实现消息传递
为了方便大家进一步理解,这里画了一个简单的图,我们用数字0,1,2,3去编号每个节点,X0~X5分别代表每个节点的特征。我们用DGL和PyG来实现一次简单的消息传递过程。
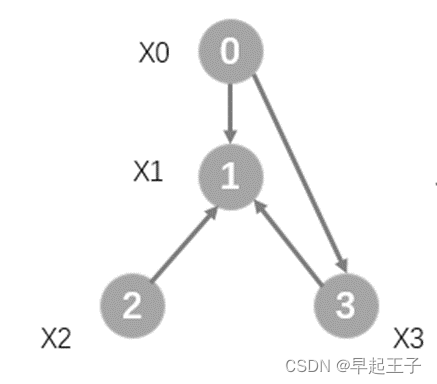
基于DGL的实现:
import dgl
import torch
g = dgl.DGLGraph()
g.add_nodes(4)
# 使用COO格式创建DGL图
edges_src = [0, 0, 2, 3]
edges_dst = [1, 3, 1, 1]
g.add_edges(edges_src, edges_dst)
# 初始化节点特征值为1,2,3,4
g.ndata['h'] = torch.tensor([[1.], [2.], [3.], [4.]])
# 定义消息函数
def message_func(edges):
return {'m': edges.src['h']}
# 定义聚合函数
def reduce_func(nodes):
return {'h_new': torch.sum(nodes.mailbox['m'], dim=1)}
# 使用 update_all 进行消息传递和聚合操作
g.update_all(message_func, reduce_func)
# 打印更新后每个节点的聚合特征
print(g.ndata['h_new'])基于PyG的实现:
import torch
from torch_geometric.data import Data
from torch_geometric.nn import MessagePassing
# 使用COO格式定义边的连接关系
edges_src = [0, 0, 2, 3]
edges_dst = [1, 3, 1, 1]
edge_index = torch.tensor([edges_src, edges_dst], dtype=torch.long)
# 初始化节点特征值为1,2,3,4
x = torch.tensor([[1.], [2.], [3.], [4.]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)
# 定义一个SimpleGCNLayer层,并继承自MessagePassing
class SimpleGCNLayer(MessagePassing):
def __init__(self):
super(SimpleGCNLayer, self).__init__(aggr='add')
def forward(self, x, edge_index):
return self.propagate(edge_index=edge_index, x=x)
def message(self, x_j):
return x_j
# 实例化SimpleGCNLayer层
simple_gcn_layer = SimpleGCNLayer()
# 执行消息传递和聚合操作
new_x = simple_gcn_layer(data.x, data.edge_index)
# 打印更新后每个节点的聚合特征
print("Updated Node Features:\n", new_x)
回到刚刚的这张图,我们可以看到,节点1接收到来自节点0,2,3的消息,使用加法聚合,最后得到的结果应该为8,节点3收到了来自节点0的消息,结果应该为1,同理,节点0,2聚合后的结果应该为0。运行上面两段代码,我们得到了一致的输出结果:
tensor([[0.],
[8.],
[0.],
[1.]])
比较DGL和PyG中的消息传播机制
DGL 的消息传递理念
模块化与灵活性:
DGL 将消息传递流程分为独立的几个步骤:消息生成(Message Generation)、消息发送(Message Sending)、消息接收(Message Receiving)和消息聚合(Message Aggregation)。这种分步设计使得每个阶段都可以进行高度定制,以满足不同的应用需求。
DGL 提供了一系列内置的消息函数和聚合函数,同时支持用户自定义函数,从而增强了灵活性和扩展性。
抽象与泛化:
DGL 的设计更加抽象,任何图结构都可以通过统一的接口进行操作。无论是大型图网络还是小型图,都可以用相同的接口进行处理。
支持多种底层深度学习框架(如 PyTorch、TensorFlow),更加通用。
规模与性能:
DGL 更加注重处理大规模图的效率,提供了分布式计算等优化机制,能够处理超大规模的图数据。
PyG 的消息传递理念
简洁性与集成性:
PyG 将消息传递的各个子过程(消息生成、发送、接收和聚合)通过 MessagePassing 类进行封装,这使得实际编码过程中更为简洁直观。
这种设计使得 PyG 在 PyTorch 环境下更加自然,符合 PyTorch 用户的使用习惯。
数据驱动与效率:
PyG 采用数据驱动的设计理念,直接将图数据集成到 PyTorch 的数据处理管道中,方便进行批处理和训练。
聚合操作与消息传递步骤被简化并高效实现,适合快速实验和模型验证。
易用性与灵活扩展:
提供了大量的预定义层和模型,如常见的图卷积层,便于快速搭建图神经网络。
尽管 PyG 的消息传递过程被高度封装,但也提供了足够的钩子函数让用户去定制消息传递的细节。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









