







海量Web日志分析(MR实现)
海量Web日志分析(MR实现)
代码需求
实现PV,IP,访问时间,浏览器类型等常用的Web日志分析功能。
笔者配置
Hadoop3.1.3,有空再用spark实现
IDEA本地测试运行,可以打jar包上传集群跑数据
数据类型
222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] \"GET /images/my.jpg HTTP/1.1\" 200 19939 \"http://www.chinasofti.com\" \"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.1547.66 Safari/537.36\"

146190行数据,其中包含脏数据,以空格为分割符
需求具体实现思路
- KPI.java: 对数据的处理,还有一些功能类
- KPIPV.java: 统计特定页面的访问数量\
- KPIIP.java: 统计特定页面的访问独立ip数量(存在相同IP访问多次)\
- KPITime.java:每个时间段的访问数量\
- KPIBrowser.java: 统计每种浏览器的访问数量\
代码结构

KPI.java
package com.lmr;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashSet;
import java.util.Locale;
import java.util.Set;
public class KPI {
private String remote_addr; // 记录客户端的ip地址
private String remote_user; // 记录客户端用户名称,忽略属性"-"
private String time_local; // 记录访问时间与时区
private String request; // 记录请求的url与http协议
private String status; // 记录请求状态;成功是200
private String body_bytes_sent; // 记录发送给客户端文件主体内容大小
private String http_referer; // 用来记录从哪个页面链接访问过来的
private String http_user_agent; // 记录客户浏览器的相关信息
private boolean valid = true; // 判断数据是否合法
private static KPI parser(String line){
KPI kpi = new KPI();
String[] arr = line.split(" ");
if (arr.length > 11){
kpi.setRemote_addr(arr[0]);
kpi.setRemote_user(arr[1]);
kpi.setTime_local(arr[3].substring(1));
kpi.setRequest(arr[6]);
kpi.setStatus(arr[8]);
kpi.setBody_bytes_sent(arr[9]);
kpi.setHttp_referer(arr[10]);
if (arr.length > 12){
kpi.setHttp_user_agent(arr[11] + " " + arr[12]);
}else {
kpi.setHttp_user_agent(arr[11]);
}
if (Integer.parseInt(kpi.getStatus()) >= 400){
kpi.setValid(false);
}
}else {
kpi.setValid(false);
}
return kpi;
}
/**
*按page的pv分类
* 只计算以下页面
*/
public static KPI filterPVs(String line){
KPI kpi = parser(line);
Set<String> pages = new HashSet<String>();
pages.add("/about");
pages.add("/black-ip-list/");
pages.add("/cassandra-clustor/");
pages.add("/finance-rhive-repurchase/");
pages.add("/hadoop-family-roadmap/");
pages.add("/hadoop-hive-intro/");
pages.add("/hadoop-zookeeper-intro/");
pages.add("/hadoop-mahout-roadmap/");
if (!pages.contains(kpi.getRequest())){
kpi.setValid(false);
}
return kpi;
}
/**
*
*按page的独立ip分类
*/
public static KPI filterIPs(String line){
KPI kpi = parser(line);
Set<String> pages = new HashSet<>();
pages.add("/about");
pages.add("/black-ip-list/");
pages.add("/cassandra-clustor/");
pages.add("/finance-rhive-repurchase/");
pages.add("/hadoop-family-roadmap/");
pages.add("/hadoop-hive-intro/");
pages.add("/hadoop-zookeeper-intro/");
pages.add("/hadoop-mahout-roadmap/");
if (!pages.contains(kpi.getRequest())){
kpi.setValid(false);
}
return kpi;
}
/**
* PV按浏览器分类
*/
public static KPI filterBroswer(String line){
return parser(line);
}
/**
* PV按小时分类
*/
public static KPI filterTime(String line){
return parser(line);
}
/**
* PV按访问域名分类
*/
public static KPI filerDomain(String line){
return parser(line);
}
/**
* 重写toString方法
*/
public String toString(){
StringBuilder sb = new StringBuilder();
sb.append("valid:" + this.valid);
sb.append("--remote_addr:" + this.remote_addr);
sb.append("--remote_user:" + this.remote_user);
sb.append("--time_local:" + this.time_local);
sb.append("--request:" + this.request);
sb.append("--status:" + this.status);
sb.append("--body_bytes_sent:" + this.body_bytes_sent);
sb.append("--http_referer:" + this.http_referer);
sb.append("--http_user_agent:" + this.http_user_agent);
return sb.toString();
}
public Date getTime_local_Date() throws ParseException {
SimpleDateFormat df = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss", Locale.US);
return df.parse(this.time_local);
}
public String getTime_local_Date_hour() throws ParseException {
SimpleDateFormat df = new SimpleDateFormat("yyyyMMddHH");
return df.format(this.getTime_local_Date());
}
public String getHttp_referer_domain() {
if (http_referer.length() < 8) {
return http_referer;
}
String str = this.http_referer.replace("\"", "").replace("http://", "").replace("https://", "");
return str.indexOf("/") > 0 ? str.substring(0, str.indexOf("/")) : str;
}
public String getRemote_addr() {
return remote_addr;
}
public void setRemote_addr(String remote_addr) {
this.remote_addr = remote_addr;
}
public String getRemote_user() {
return remote_user;
}
public void setRemote_user(String remote_user) {
this.remote_user = remote_user;
}
public String getTime_local() {
return time_local;
}
public void setTime_local(String time_local) {
this.time_local = time_local;
}
public String getRequest() {
return request;
}
public void setRequest(String request) {
this.request = request;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getBody_bytes_sent() {
return body_bytes_sent;
}
public void setBody_bytes_sent(String body_bytes_sent) {
this.body_bytes_sent = body_bytes_sent;
}
public String getHttp_referer() {
return http_referer;
}
public void setHttp_referer(String http_referer) {
this.http_referer = http_referer;
}
public String getHttp_user_agent() {
return http_user_agent;
}
public void setHttp_user_agent(String http_user_agent) {
this.http_user_agent = http_user_agent;
}
public boolean isValid() {
return valid;
}
public void setValid(boolean valid) {
this.valid = valid;
}
/**
* 测试
*/
public static void main(String[] args) {
String line = "222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] \"GET /images/my.jpg HTTP/1.1\" 200 19939 \"http://www.chinasofti.com\" \"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.1547.66 Safari/537.36\"";
System.out.println(line);
KPI kpi = parser(line);
System.out.println(kpi);
try {
SimpleDateFormat df = new SimpleDateFormat("yyyy.MM.dd:HH:mm:ss", Locale.US);
System.out.println(df.format(kpi.getTime_local_Date()));
System.out.println(kpi.getTime_local_Date_hour());
System.out.println(kpi.getHttp_referer_domain());
} catch (ParseException e) {
e.printStackTrace();
}
}
}
KPIPV.java
package com.lmr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class KPIPV {
public static class KPIPVMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
KPI kpi = KPI.filterPVs(value.toString());
if (kpi.isValid()){
outK.set(kpi.getRequest());
System.out.println(kpi);
context.write(outK, outV);
}
}
}
public static class KPIPVReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
context.write(key, outV);
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
String input = "海量Web日志分析系统/src/datas/input";
String output = "海量Web日志分析系统/src/datas/output/pv1";
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "KPIPV");
job.setJarByClass(KPIPV.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(KPIPVMapper.class);
job.setReducerClass(KPIPVReducer.class);
FileInputFormat.addInputPath(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output));
if (!job.waitForCompletion(true)){
return;
}
}
}
代码结果截图

KPIIP.java
package com.lmr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
public class KPIIP {
public static class KPIIPMapper extends Mapper<LongWritable, Text, Text, Text> {
private Text outK = new Text();
private Text outV = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
KPI kpi = KPI.filterIPs(value.toString());
if (kpi.isValid()){
outK.set(kpi.getRequest());
outV.set(kpi.getRemote_addr());
context.write(outK, outV);
}
}
}
public static class KPIIPReducer extends Reducer<Text, Text, Text, Text> {
private Text outV = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 放在set里面,集合元素不会重复
Set<String> count = new HashSet<String>();
for (Text value : values) {
count.add(value.toString());
}
outV.set(String.valueOf(count.size()));
context.write(key, outV);
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
String input = "海量Web日志分析系统/src/datas/input";
String output = "海量Web日志分析系统/src/datas/output/ip";
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "KPIip");
job.setJarByClass(KPIIP.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(KPIIPMapper.class);
job.setReducerClass(KPIIPReducer.class);
FileInputFormat.addInputPath(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output));
if (!job.waitForCompletion(true)){
return;
}
}
}
代码结果截图

KPITime.java
package com.lmr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.text.ParseException;
public class KPITime {
public static class KPITimeMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
KPI kpi = KPI.filterTime(value.toString());
if (kpi.isValid()){
try {
outK.set(kpi.getTime_local_Date_hour());
context.write(outK, outV);
} catch (ParseException e) {
e.printStackTrace();
}
}
}
}
public static class KPITimeReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
context.write(key, outV);
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
String input = "海量Web日志分析系统/src/datas/input";
String output = "海量Web日志分析系统/src/datas/output/time";
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "KPITime");
job.setJarByClass(KPITime.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(KPITimeMapper.class);
job.setReducerClass(KPITimeReducer.class);
FileInputFormat.addInputPath(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output));
if (!job.waitForCompletion(true)){
return;
}
}
}
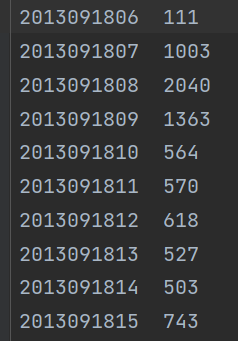
代码结果截图(部分)
KPIBrowser.java
package com.lmr;
import com.sun.xml.internal.txw2.TxwException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class KPIBrowser {
public static class KPIBrowserMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
KPI kpi = KPI.filterBroswer(value.toString());
if (kpi.isValid()){
outK.set(kpi.getHttp_user_agent());
// System.out.println(kpi.getHttp_user_agent());
context.write(outK, outV);
}
}
}
public static class KPIBrowserReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
context.write(key, outV);
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
String input = "海量Web日志分析系统/src/datas/input";
String output = "海量Web日志分析系统/src/datas/output/browser1";
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "KPIBrowser");
job.setJarByClass(KPIBrowser.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(KPIBrowserMapper.class);
job.setReducerClass(KPIBrowserReducer.class);
FileInputFormat.addInputPath(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output));
if (!job.waitForCompletion(true)){
return;
}
}
}
代码结果截图(部分)
















 1380
1380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









