







最近在学习离线数据仓库建设,学习资源: 尚硅谷之数仓5.0(不得不说,太强了),开此帖只为记录学习笔记,以便日后查看
目录
概念
数据仓库是一个为数据分析而设计的企业级数据管理系统。
与数据库的对比
-
用途
数据库:主要用于事务处理,即OLTP(Transaction),也就是我们常用的面向业务的增删改查操作。常用的数据库有Mysql,Oracle,PostgreSQL。
数据仓库:主要用于数据分析,即OLAP(Analytics),供上层决策,常见于一些查询性的统计数据。常见的数仓有Greenplum,Hive。基于MYISAM存储引擎的MySQL也是可以用来做数据仓库的。
-
优化
- 数据库:因为是事务性操作,所以一般是读写优化的
- 数据仓库:因为是数据分析,需要对大量数据进行查询,所以一般仅仅是读优化的
-
数据量
-
数据库:读写相对简单,一次只是对少量数据进行操作
-
数据仓库:查询相对复杂,一次要对大量数据进行操作
-
数据仓库建模方法论
ER模型
用实体关系模型来描述企业业务,并用规范化的方式表示出来,在范式理论上符合3NF
-
实体关系模型
实体关系模型将复杂的数据抽象为两个概念----实体和关系。实体表示一个对象,例如学生,班级,关系是指两个实体之间的关系,例如学生和班级之间的从属关系
-
数据库规范化
-
数据库规范化是使用一系列范式设计关系型数据库时,需要遵从的不同的规范。关系型数据库的范式一共有六种,分别是第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF)。遵循的范式级别越高,数据冗余性就越低。
-
三范式
-
第一范式:属性不可切割
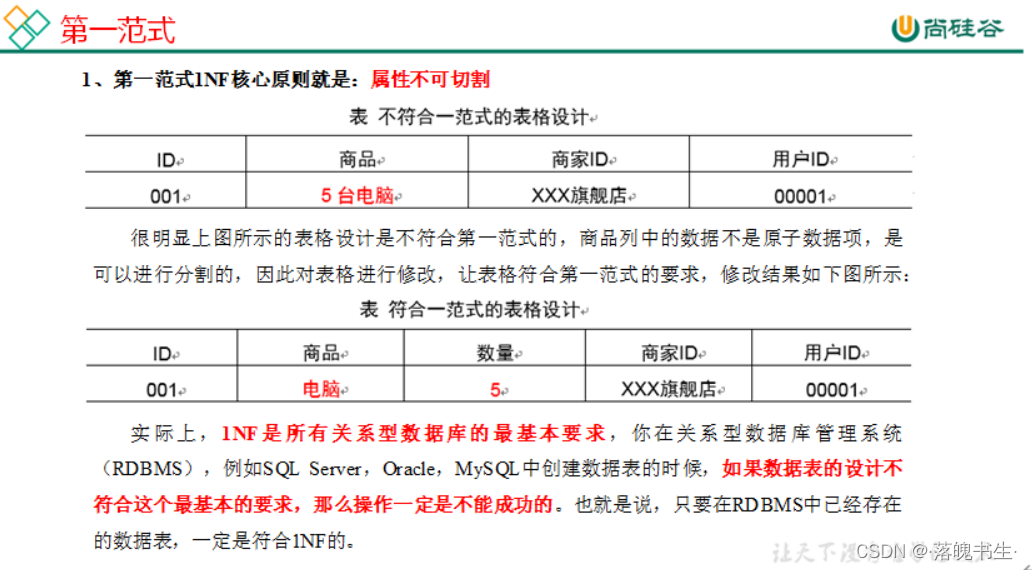
-
第二范式:不能存在部分函数依赖
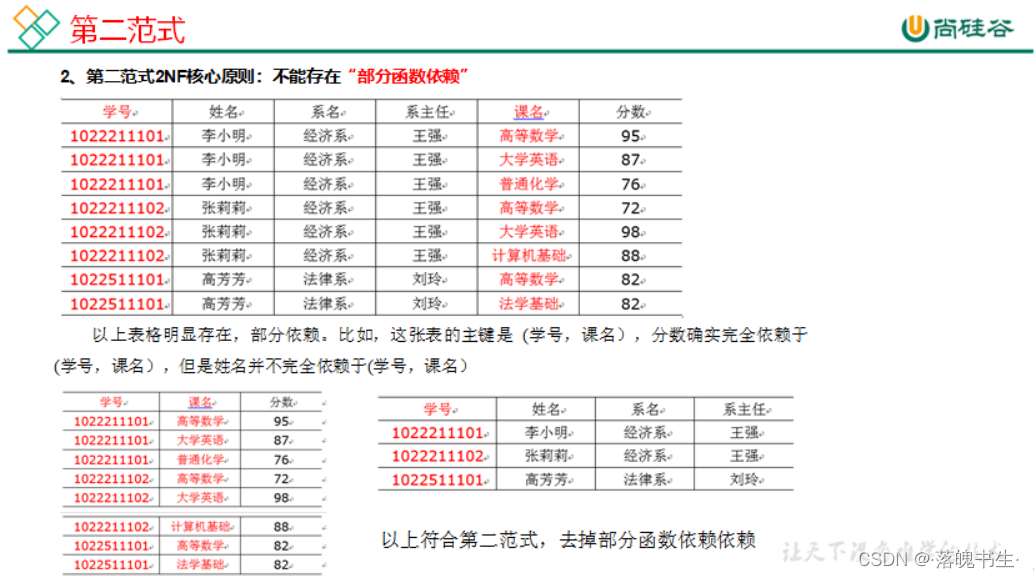
-
第三范式:不能存在传递函数依赖

-
维度模型
维度模型将复杂的业务通过事实和维度两个概念进行呈现。事实通常对应业务过程,而维度通常对应业务过程发生时所处的环境
注:业务过程可以概括为一个个不可拆分的行为事件,例如电商交易中的下单,取消订单,付款,退单等,都是业务过程。
比如:何人、何时、在何地下单了何种产品。这个是业务过程,是事实表
然后它所处的环境 何人、何时、在何地、何种产品,是维度表
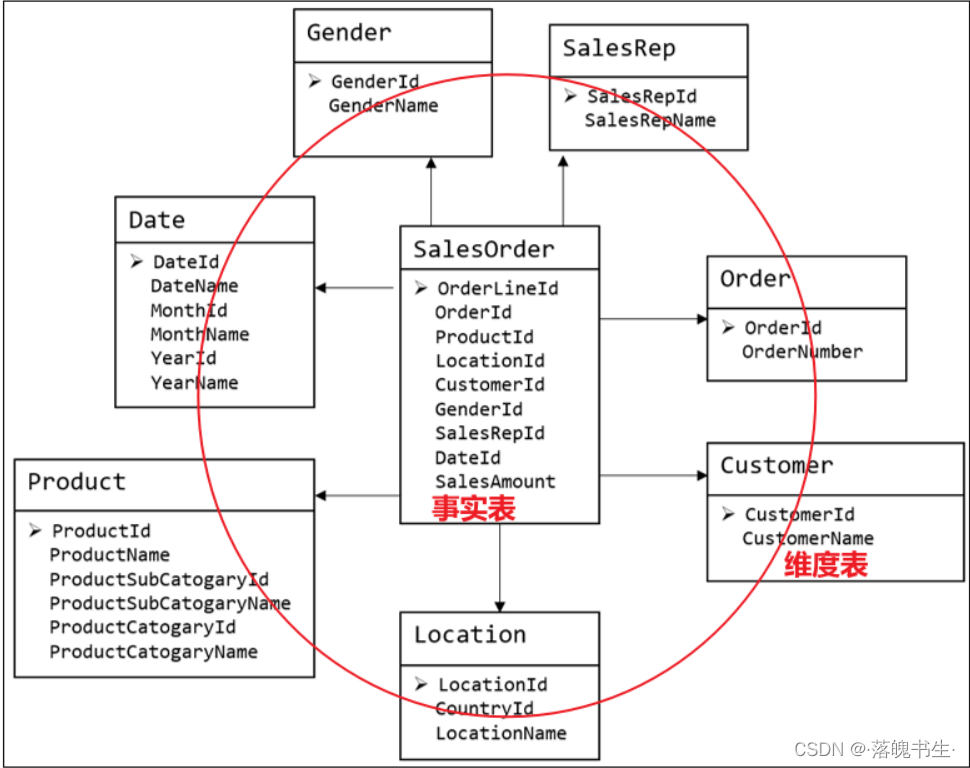
维度建模理论之事实表
概述
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计。其包含与该业务过程有关的维度引用(维度表外键)以及该业务过程的度量(通常是可累加的数字类型字段)。
特点
事实表通常比较“细长”,即列较少,但行较多,且行的增速快。
分类
事实表有三种类型:分别是事务事实表、周期快照事实表和累积快照事实表
-
事务事实表
- 事务事实表用来记录各业务过程,它保存的是各业务过程的原子操作事件,即最细粒度的操作事件。粒度是指事实表中一行数据所表达的业务细节程度。
- 不能用于存量型数据,由周期型快照事实表顶上。
-
周期型快照事实表
- 周期快照事实表以具有规律性的,可预见的时间间隔来记录事实,主要用于分析一些存量型(例如商品库存,账户余额)或者状态型(空气温度,行驶速度)指标。
-
累积型快照事实表
-
累积快照事实表是基于一个业务流程中的多个关键业务过程联合处理而构建的事实表,如交易流程中的下单、支付、发货、确认收货业务过程。
-
累积快照事实表通常具有多个日期字段,每个日期对应业务流程中的一个关键业务过程。

-
维度建模理论之维度表
事实表围绕业务过程进行设计,而维度表则围绕业务过程所处的环境进行设计。维度表主要包含一个主键和各种维度字段,维度字段称为维度属性。
维度设计要点
-
规范化与反规范化
-
规范化是指使用一系列范式设计数据库的过程,其目的是减少数据冗余,增强数据的一致性。通常情况下,规范化之后,一张表的字段会拆分到多张表。规范化后得到的维度模型称为雪花模型。
-
反规范化是指将多张表的数据冗余到一张表,其目的是减少join操作,提高查询性能。反规范化后得到的模型称为星型模型。
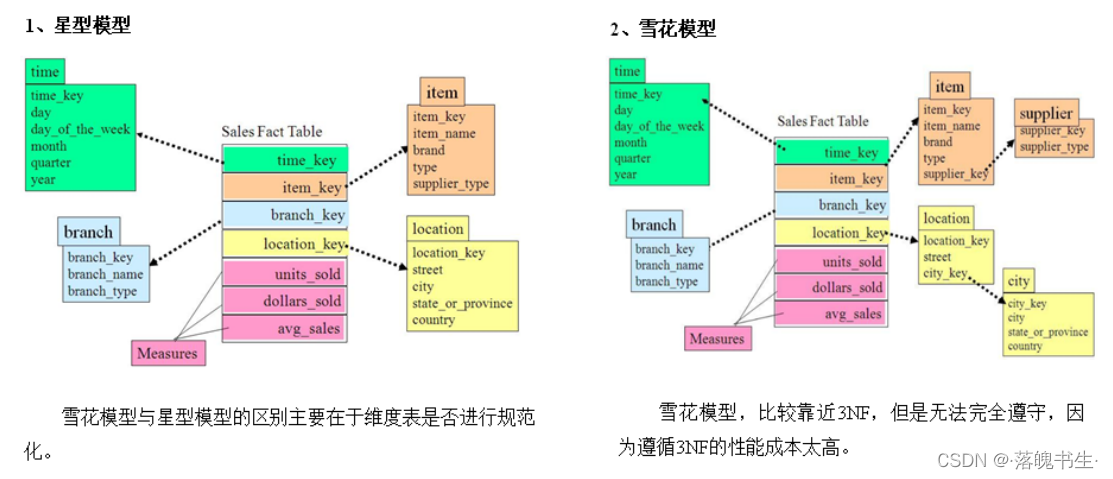
-
-
维度变化
-
全量快照表
离线数据仓库的计算周期通常为每天一次,所以可以每天保存一份全量的维度数据。
- 优点:简单而有效,开发和维护成本低,且方便理解和使用。
- 缺点:浪费存储空间,尤其是当数据的变化比例低时。
-
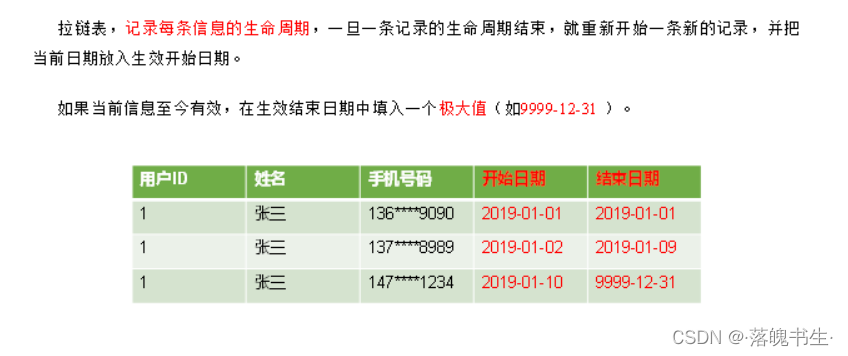
拉链表
记录每条信息的生命周期

-
-
维度退化
如果某些维度表的维度属性很少,例如只有一个**名称,则可不创建该维度表,而把该表的维度属性直接增加到与之相关的事实表中,这个操作称为维度退化。
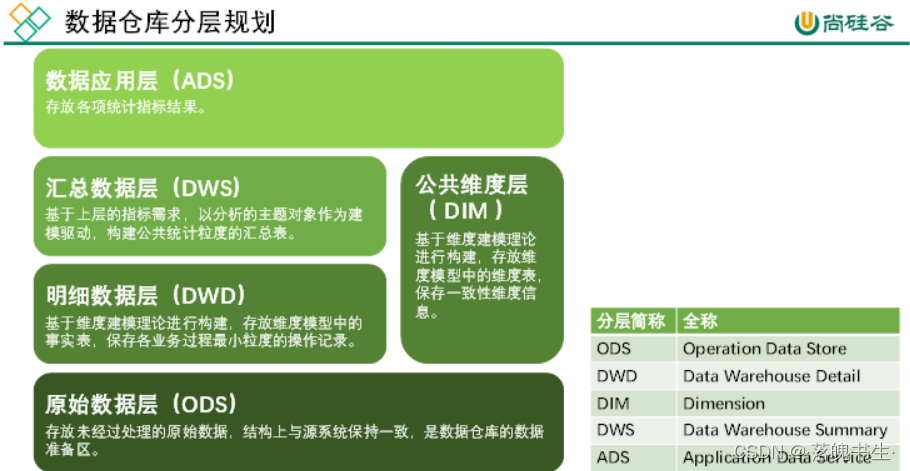
数据仓库分层















 2341
2341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









