






一、逻辑回归基础认知
1. 什么是逻辑回归?
1). 逻辑回归(Logistic Regression):
逻辑回归是一种用于解决分类问题的统计方法,尤其适用于二分类任务(如判断“是/否”)。虽然名称中包含“回归”,但它通过拟合概率而非直接预测连续值,属于广义线性模型(GLM)的一种。
注意: 尽管名称中有"回归"二字,但它实际上是一种分类算法。
2). 核心原理:
逻辑回归通过将线性回归的输出映射到(0,1)区间,使用Sigmoid函数将连续值转换为概率值,然后根据概率值进行分类预测。
2.1 基本思想:
1.利用线性模型 f(x) = w^Tx + b 根据特征的重要性计算出一个值;
2.再使用 sigmoid 函数将 f(x) 的输出值映射为概率值:
1.设置阈值(eg:0.5);
2.输出概率值大于 0.5,则将未知样本输出为 1 类;
3.否则输出为 0 类。
2.2 逻辑回归的假设函数

***线性回归的输出,作为逻辑回归的输入
3). 举个栗子逻辑回归预测过程(阈值为0.6)

2. 逻辑回归应用场景

二、逻辑回归核心原理剖析
1. Sigmoid函数(逻辑函数):
1). 公式:
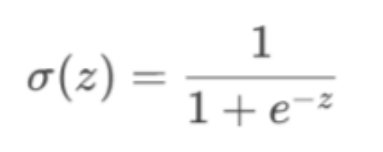

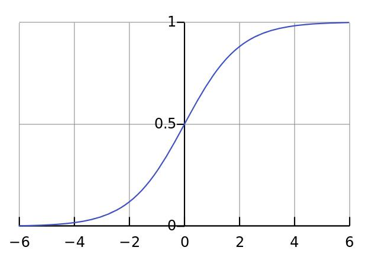
2). 作用:
从线性到概率的桥梁,它可以将任何的实数(线性回归的值)映射到(0,1)区间,可以解释为概率值。
3). 决策边界:
设定阈值(通常为0.5):
若 σ(z)≥ 0.5,预测为类别1;
若 σ(z)< 0.5,预测为类别0。
决策边界是线性超平面(在二维空间中是直线),由z = 0定义(拐点在z = 0时,y = 0.5的位置,此时斜率最大)。
2. 模型优化的手段
1). 极大似然估计-MLE(Maximum Likelihood Estimation)
1.1 定义:
极大似然估计是一种统计方法,用于从观测数据中估计概率分布的参数。
1.2 核心思想:
在已知观测数据的情况下,选择使得这些数据出现概率最大的参数值。
1.3 二分类公式:

2). 伯努利分布(Bernoulli Distribution):

2.1 伯努利分布函数(Bernoulli Likelihood):
假设:有样本[(x_1, y_1), (x_1, y_2) …, (x_n, y_n) ],n个样本都预测正确的概率就是伯努利分布的似然函数。
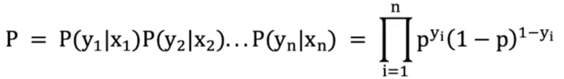
pi 表示每个样本被分类正确时的概率
yi 表示每个样本的真实类别(0或1)
问题转化为:让联合概率事件最大时,估计w、b的权重参数,这就是极大似然估计。
关键结论
最大似然函数 ≠ 伯努利函数,但逻辑回归的似然函数基于伯努利分布构建。
更准确的说法:
逻辑回归通过最大化伯努利似然函数(或等价地最小化交叉熵损失)来估计参数;
最大似然是参数估计方法,伯努利是分布假设;逻辑回归的似然函数基于伯努利分布,但其他模型(如高斯分布)的似然函数形式完全不同;
最大似然估计是通用方法,而伯努利分布是特定概率模型。在逻辑回归中,二者通过伯努利似然函数结合,但术语不可混用。
3). 最小化交叉熵-交叉熵损失函数(Cross-Entropy Loss)
3.1 概念:
交叉熵是衡量两个概率分布(真实分布 y和预测分布 p)差异的指标。
3.2 核心思想:
最小化交叉熵损失函数实际上是在寻找能够最大化观测数据的对数似然性的模型。
3.3 二分类公式:

3.4 举个栗子 – 损失函数手工计算

计算损失示例:= [ 1log0.40 + (1-1)log(1-0.40) + # 第1个样本产生的损失 0log0.68 + (1-0)log(1-0.68) + # 第2个样本产生的损失 1log0.41 + (1-1)log(1-0.41) + …. # ...
4). 关系
4.1 核心思想:
伯努利分布的似然函数是逻辑回归交叉熵损失的来源,对其取负对数,直接得到交叉熵损失!
4.2 转换过程:
4.2.1 把最大化问题将其变为最小化问题(最大化似然函数 -> 最小化交叉熵损失):
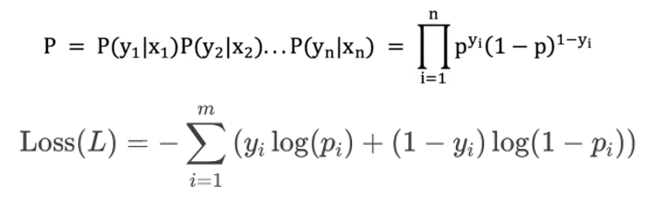
4.2.2 把连乘问题将其变为连加问题:
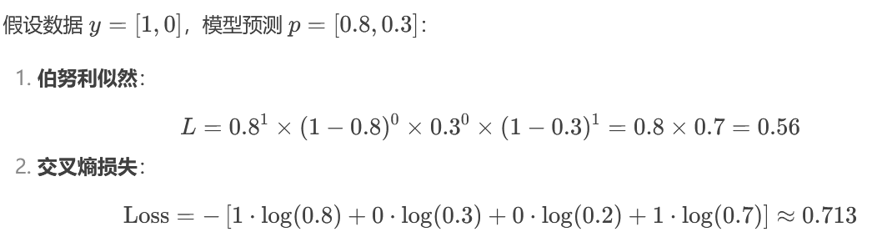
4.2.3 图解:

三、Scikit-learn实战:癌症分类预测
1. 逻辑回归的API

2. 实战-癌症分类预测案例:
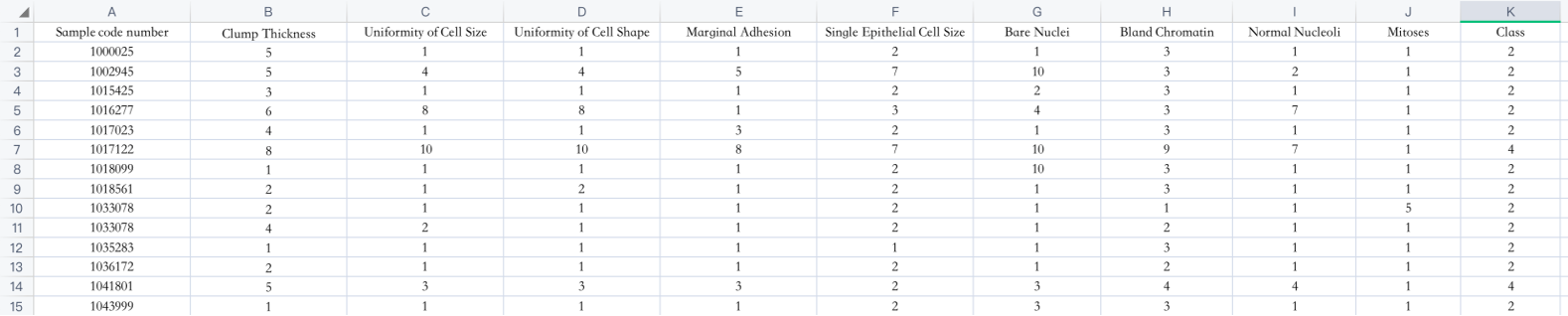
1).数据描述:
1.1 699条样本,共11列数据,第一列用于检索的id,后9列分别是与肿瘤相关的医学特征,最后一列表示肿瘤类型的数值;
1.2 包含16个缺失值,用”?”标出;
1.3 表示良性,4表示恶性。
2). 代码演示
# 1.导包
# 用于数据处理和分析
import pandas as pd
# 用于数值计算
import numpy as np
# 导入train_test_split函数,用于分割数据集
from sklearn.model_selection import train_test_split
# 导入StandardScaler类,用于数据标准化
from sklearn.preprocessing import StandardScaler
# 导入LogisticRegression类,用于创建逻辑回归模型
from sklearn.linear_model import LogisticRegression
# 导入accuracy_score函数,用于评估模型准确率
from sklearn.metrics import accuracy_score
# 2.使用pandas库读取数据集
data = pd.read_csv('data/breast-cancer-wisconsin.csv')
# 3.了解数据
# 显示数据集的基本信息,包括数据量、特征数量、特征类型及内存占用情况
data.info()
# 打印数据集的前几行(head默认前5行),以便快速查看数据样例
print(data.head())
# 4.数据预处理
# 缺失值/异常值处理
data = data.replace('?', np.NaN)
data.dropna(inplace=True)
# 提前找到特征集和标签集方便切割数据集
features = data.iloc[:, 1:-1]
label = data.iloc[:, -1]
x_train, x_test, y_train, y_test = train_test_split(features, label, test_size=0.2, random_state=888)
# 5.特征工程(归一化或者标准化)
ss = StandardScaler()
x_train = ss.fit_transform(x_train) # 训练集标准化
x_test = ss.transform(x_test) # 测试集标准化
# TODO 6.创建模型(根据业务选择对应模型)
model = LogisticRegression()
# 7.模型训练
model.fit(x_train, y_train)
# 8.模型预测
y_predict = model.predict(x_test)
# 9.模型评估
print(f"准确率:{model.score(x_test, y_test)}")四、分类结果评估体系
1. 混淆矩阵(Confusion Matrix)
1). 概念:
模型的预测结果与实际标签的对比情况。即如下图:

2). 混淆矩阵的四个指标:
真实值是 正例 的样本中,被分类为 正例 的样本数量有多少,叫做真正例(TP,True Positive) 真实值是 正例 的样本中,被分类为 假例 的样本数量有多少,叫做伪反例(FN,False Negative) 真实值是 假例 的样本中,被分类为 正例 的样本数量有多少,叫做伪正例(FP,False Positive) 真实值是 假例 的样本中,被分类为 假例 的样本数量有多少,叫做真反例(TN,True Negative)
3). 举个栗子:
已知:样本集10样本,有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例。
模型A:预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本 请计算:TP、FN、FP、TN
真正例 TP 为:3 伪反例 FN 为:3 伪正例 FP 为:0 真反例 TN:4
模型B:预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本 请计算:TP、FN、FP、TN
真正例 TP 为:6 伪反例 FN 为:0 伪正例 FP 为:3 真反例 TN:1
4). 代码演示:
# 1.导入库
from sklearn.metrics import confusion_matrix # 混淆矩阵
import pandas as pd # 创建DataFrame对象
# 2.准备数据,假设10个样本数据中,6个是恶性,4个是良性
y_ture = ['恶性','恶性','恶性','恶性','恶性','恶性','良性','良性','良性','良性']
# 3.创建A和B两个不同的模型,来模拟不一样的预测结果
print('======================================================================')
# 3.1 准备模型A的预测结果:3个恶心,4个良性
cm_pre_A = ['恶性','恶性','恶性','良性','良性','良性','良性','良性','良性','良性']
# 3.2 创建模型A的混淆矩阵
cm_A = confusion_matrix(y_ture,cm_pre_A,labels = ['恶性','良性'])
# 3.3 打印模型A的混淆矩阵
print(f'模型A预测结果为:\n{cm_A}')
# 3.4 为了能让结果展示得更加美观直接,使用pandas添加行列标签,转换成DataFrame对象
# 用index 和 columns 来添加行和列的标签
df_cm_A = pd.DataFrame(cm_A,index = ['恶性(正例)','良性(反例)'],columns = ['恶性(正例)','良性(反例)'])
print(f'模型A预测结果为:\n{df_cm_A}')
print('======================================================================')
# 4.1 准备模型B的预测结果:6个恶性,1个良性
cm_pre_B = ['恶性','恶性','恶性','恶性','恶性','恶性','恶性','恶性','恶性','良性']
# 4.2 创建模型B的混淆矩阵
cm_B = confusion_matrix(y_ture,cm_pre_B,labels = ['恶性','良性'])
# 4.3 打印模型B的混淆矩阵
print(f'模型B预测结果为:\n{cm_B}')
# 4.4 为了能让结果展示得更加美观直接,使用pandas添加行列标签,转换成DataFrame对象
# 用index 和 columns 来添加行和列的标签
df_cm_B = pd.DataFrame(cm_B,index = ['恶性(正例)','良性(反例)'],columns = ['恶性(正例)','良性(反例)'])
print(f'模型B预测结果为:\n{df_cm_B}')2. 四大核心指标
1). 准确率(Accuracy_score):
1.1 思想:
预测正确的样本占总样本的比例。
1.2 公式+图解:

2). 精确率(Precision)
2.1 思想:
又叫查准率,预测为正例的样本中真实正例的比例。
2.2 公式+图解:

2.3 代码演示:
# 导入必要的评估指标函数
from sklearn.metrics import precision_score
def dm01_精度Precision():
"""
肿瘤分类模型精确率(Precision)评估示例
演示不同预测策略下精确率指标的变化
"""
# 真实标签(ground truth)
# 共9个样本:6个恶性(正例),3个良性(负例)
y_true = ["恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "良性", "良性", "良性"]
# ==================================
# 模型A:保守预测(侧重减少误诊)
# ==================================
# 预测结果:3个恶性(其中3个正确),5个良性
# 注意:要保持与y_true相同长度
y_pred1 = ["恶性", "恶性", "恶性", "良性", "良性", "良性", "良性", "良性", "良性"]
# 计算精确率(关注"恶性"类别的预测准确性)
# pos_label指定正例标签为"恶性"
precision_A = precision_score(y_true, y_pred1, pos_label="恶性")
print(f"模型A精确率: {precision_A:.2f}") # 输出 1.00 (3/3)
# ==================================
# 模型B:激进预测(侧重减少漏诊)
# ==================================
# 预测结果:全部预测为恶性
y_pred2 = ["恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性"]
precision_B = precision_score(y_true, y_pred2, pos_label="恶性")
print(f"模型B精确率: {precision_B:.2f}") # 输出 0.67 (6/9)
# 执行函数
if __name__ == "__main__":
dm01_精度Precision()3). 召回率
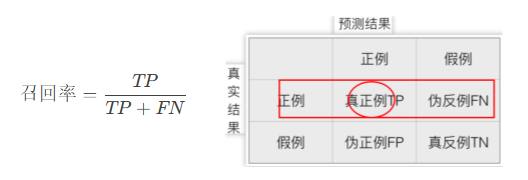
3.1 思想:
又叫查全率,真实正例的样本中被正确预测的比例。
3.2 公式+图解:
3.3 代码演示:
# 召回率(查全率)
from sklearn.metrics import recall_score
def dm02_召回率recall():
# 样本集中共有6个恶性肿瘤样本,4个良性肿瘤样本
y_true = ["恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "良性", "良性", "良性", "良性"]
# 1. 模型A: 预测对了3个恶性肿瘤样本,4个良性肿瘤样本
y_pred1 = ["恶性", "恶性", "恶性", "良性", "良性", "良性", "良性", "良性", "良性", "良性"]
result = recall_score(y_true, y_pred1, pos_label="恶性")
print("模型A召回率:", result)
# 2. 模型B: 预测对了6个恶性肿瘤样本,1个良性肿瘤样本
y_pred2 = ["恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "良性"]
result = recall_score(y_true, y_pred2, pos_label="恶性")
print("模型B召回率:", result)
if __name__ == '__main__':
# 执行函数
dm02_召回率recall()4). F1-Score
4.1 思想:
精确率和召回率的调和平均数。
4.2 公式:
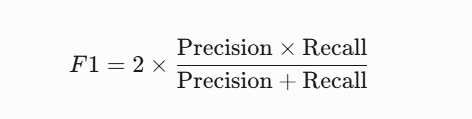
其中:Precision(精确率) Recall(召回率)
4.3 代码演示:
from sklearn.metrics import f1_score
# 真实标签(6个恶性,4个良性)
y_true = ["恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "良性", "良性", "良性", "良性"]
# 模型A预测(3个恶性正确,3个恶性错误)
y_pred_a = ["恶性", "恶性", "恶性", "良性", "良性", "良性", "良性", "良性", "良性", "良性"]
f1_a = f1_score(y_true, y_pred_a, pos_label="恶性")
print("模型A的F1分数:", f1_a) # 输出: 0.545
# 模型B预测(6个恶性正确,3个良性错误)
y_pred_b = ["恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "良性"]
f1_b = f1_score(y_true, y_pred_b, pos_label="恶性")
print("模型B的F1分数:", f1_b) # 输出: 0.85). 分类评估报告(classification_report)~敲重点
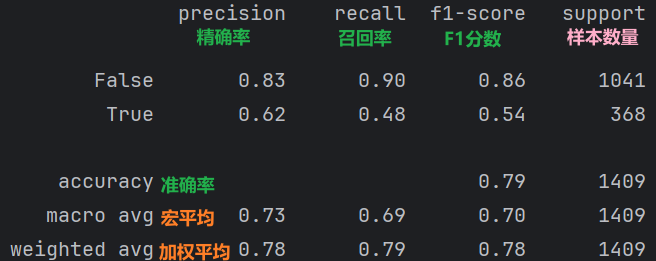
为什么要说:因为该报告包含了模型的精确度、召回率、F1分数等评估指标,非常的全面
5.1 API
sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
y_true:真实目标值
y_pred:估计器预测目标值
labels:指定类别对应的数字
target_names:目标类别名称
return:每个类别精确率与召回率
5.2 结果图解
3.ROC曲线与AUC面积
补充:真正率TPR与假正率FPR
TPR (True Positive Rate):正样本中被预测为正样本的概率。
FPR (False Positive Rate):负样本中被预测为正样本的概率。
通过这两个指标可以描述模型对正/负样本的分辨能力。
1). ROC曲线(Receiver Operating Characteristic curve)
概念:
是一种常用于评估分类模型性能的可视化工具。ROC曲线以模型的真正率TPR为纵轴,假正率FPR为横轴,它将模型在不同阈值下的表现以曲线的形式展现出来。
2). AUC (Area Under the ROC Curve)曲线下面积
2.1 概念:
ROC曲线的优劣可以通过曲线下的面积(AUC)来衡量,AUC越大表示分类器性能越好。
2.2 图解:

3). 图像展示:
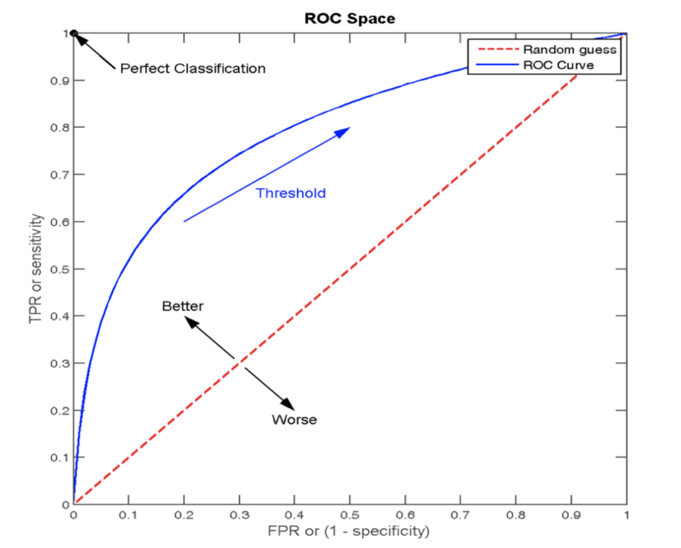
ROC 曲线图像中,4 个特殊点的含义:

曲线越靠近 (0,1) 点则模型对正负样本的辨别能力就越强!!!
4). ROC、AUC的API:
from sklearn.metrics import roc_auc_score
sklearn.metrics.roc_auc_score(y_true, y_score)
计算ROC曲线面积,即AUC值
y_true:每个样本的真实类别,必须为0(反例),1(正例)标记;
y_score:预测得分,可以是正例的估计概率、置信值或者分类器方法的返回值。
注意:ROC和AUC它两必须是一起使用的,不是单独的,和网格搜索交叉验证一样
五、综合案例:电信客户流失预测
1. 了解数据:
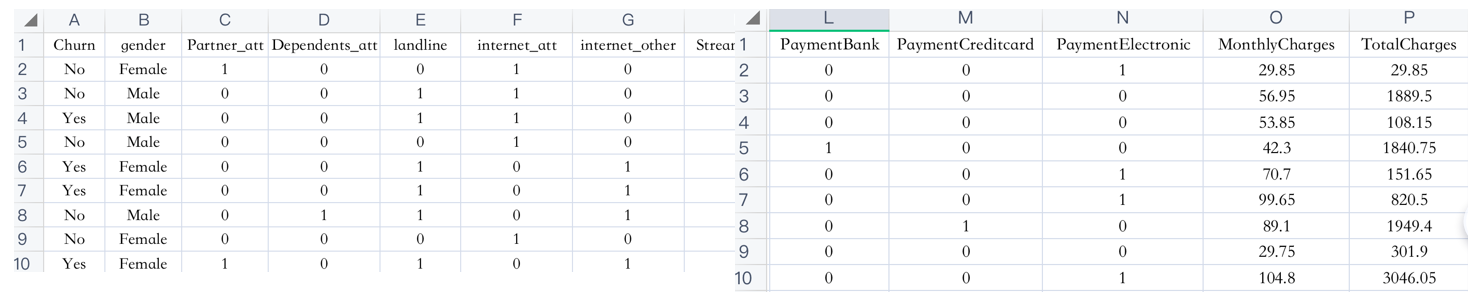
2. 代码演示:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 1.导入库
import pandas as pd
# 2.加载数据
data = pd.read_csv('data/churn.csv')
# 3.了解数据
print(data.head())
data.info()
# 4.数据预处理
# 因为数据gander列就是二分类类型,所以需要对其进行处理,把male和female都转化为True、False
# TODO: 参数columns用来指定列,drop_first=True,默认是False,表示会自动删除每个分类特征的第一个类别列,以避免多重共线性问题
data = pd.get_dummies(data) # 默认是把所有的列都进行热编码,如果只对gender列进行热编码,可以指定columns=['gender']
print(data.head())
print('--------------------------------')
# TODO:删除热编码多余的列方式:drop(要删除的列名, axis=1, inplace=True)
data.drop(['gender_Male','Churn_No'],axis=1,inplace=True)
print(data.head())
print('--------------------------------')
# 修改列名,用rename把Churn_Yes改为flag,gender_Female改为gender
data.rename(columns={'Churn_Yes':'flag','gender_Female':'gender'},inplace=True)
print(data.head())
print('--------------------------------')
# 5.数据切割
# 提取特征列,表示所有的行,所有的列,-2表示不包含最后一列和倒数第二列
features = data.iloc[:,1:-2]
# 提取标签列,表示所有的行,只要倒数第二列
labels = data.iloc[:,-2]
# 切割,设置测试集的占比为20%,并且设置随机数种子来保证每次切出来的数据都是相同的
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(features,labels,test_size=0.2,random_state=0)
# 6.特征工程(标准化)
from sklearn.preprocessing import StandardScaler
# 创建标准化对象
ss = StandardScaler()
# 训练集标准化
x_train = ss.fit_transform(x_train)
# 测试集标准化
x_test = ss.transform(x_test)
# 7.创建模型(逻辑回归)
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
# 8.模型训练
lr.fit(x_train,y_train)
# 9.模型预测
y_pred = lr.predict(x_test)
# 10.模型评估(准确率,精确率,召回率,f1_score)
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score
print(f'模型的准确率(accuracy_score):{accuracy_score(y_test,y_pred)}')
print(f'模型的精确率(precision_score):{precision_score(y_test,y_pred)}')
print(f'模型的召回率(recall_score):{recall_score(y_test,y_pred)}')
print(f'模型的f1_score:{f1_score(y_test,y_pred)}')
# 11.模型综合评分报表
# 导入classification_report模块,用于生成模型评估报告
from sklearn.metrics import classification_report
# 输出分类评估报告
# 参数y_test是测试集的真实标签,y_pred是模型预测的标签
# 该报告包含了模型的精确度、召回率、F1分数等评估指标
print(classification_report(y_test, y_pred))
# 12.数据可视化
import matplotlib.pyplot as plt
import seaborn as sns
# 用sns画出数据关系热力图
# 创建一个新的图形,设置图形大小为8英寸宽,6英寸高
plt.figure(figsize=(8,6))
# 使用Seaborn库绘制热力图,展示数据集中各特征的相关性
# data.corr()计算数据的相关性矩阵,annot=True表示在图中显示相关性数值,cmap='coolwarm'设置颜色主题
sns.heatmap(data.corr(),annot=True,cmap='coolwarm')
# 设置图形标题为'数据关系热力图'
plt.title('数据关系热力图')
# 显示图形
plt.show()六、常见问题解答
1. 逻辑回归和线性回归有什么区别?
逻辑回归用于分类问题,输出是分类的概率(0到1之间),通过Sigmoid函数将线性回归的输出映射到(0,1)区间。
线性回归用于回归问题,输出是连续值,直接预测目标变量的值。
2. 如何选择合适的阈值?
阈值的选择取决于具体的应用场景。例如,在医疗诊断中,可能更倾向于降低假阴性(FN),因此可以将阈值设置得更低一些;而在某些成本敏感的应用中,可能更关注降低假阳性(FP),则可以提高阈值。
3. 精确率和召回率哪个更重要?
这取决于具体任务的需求。如果更关注预测结果的可靠性,则精确率更重要;如果更关注不遗漏正样本,则召回率更重要。通常,F1分数可以综合考虑两者,是一个平衡指标。
4. 如何处理数据不平衡问题?
可以通过过采样(如SMOTE)、欠采样、调整类别权重等方法来处理数据不平衡问题。在逻辑回归中,可以使用class_weight参数来调整类别权重。
5. 逻辑回归的损失函数是什么?
逻辑回归的损失函数是交叉熵损失函数,它衡量的是预测概率分布和真实分布之间的差异。最小化交叉熵损失函数等价于最大化似然函数。
6. 逻辑回归的参数如何优化?
通常使用梯度下降或其变体(如SGD)来优化逻辑回归的参数。还可以使用正则化(如L1或L2)来防止过拟合。
7. 如何评估逻辑回归模型?
可以使用精确率、召回率、F1分数、AUC等指标来评估模型性能。AUC值越高,模型的性能越好。此外,混淆矩阵可以直观地展示模型的预测结果。
七、文章亮点总结
1. 逻辑回归基础:
逻辑回归是一种用于分类问题的统计方法,通过Sigmoid函数将线性回归的输出映射到(0,1)区间,从而实现分类预测。
逻辑回归的核心是极大似然估计,通过最小化交叉熵损失函数来优化模型参数。
2. Sigmoid函数与决策边界:
Sigmoid函数将线性回归的输出值映射为概率值,决策边界通常设置为0.5,用于分类预测。
决策边界是线性超平面,在二维空间中为直线。
3. 模型优化手段:
通过极大似然估计(MLE)来估计模型参数,最大化观测数据的似然性。
使用交叉熵损失函数来衡量预测分布与真实分布的差异,并最小化该损失函数。
4. 分类结果评估体系:
使用混淆矩阵来展示模型的预测结果,包括TP、FN、FP、TN四个指标。
通过精确率、召回率、F1分数等指标来评估模型的性能,AUC值可以衡量模型对正负样本的辨别能力。
5. Scikit-learn实践:
提供了详细的代码示例,从数据预处理、特征工程、模型训练到评估的完整流程。
使用逻辑回归API进行癌症分类预测,展示了模型的准确率、精确率、召回率和F1分数的计算方法。
6. 电信客户流失案例:
电信客户流失预测案例展示了如何处理实际数据,包括数据预处理、特征工程、模型训练和评估。
使用ROC曲线和AUC值来评估模型的性能,展示了数据可视化的技巧。
最后,以上就是全部关于逻辑回归的知识点概述了,仅代表个人观点,如果有什么不对或者不足的地方还请各位大佬多多包涵,其他小伙伴们也可以结合AI工具进行更好的理解。
看完之后觉得还行,对你有所帮助的,那就是我莫大的荣幸啦!
关注我,让我们一起慢慢进步,赶上大佬们的步伐~
所有文章的数据源都在这里啦:欢迎食用(需要自己找到对应的文件夹哈)
链接: https://pan.baidu.com/s/1EH0oqDYcs9ukpn90U4AbGg?pwd=0577 提取码: 0577 (自动填充的)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









