






一、KNN算法原理:
1.概念:
1).通俗:KNN 就是一个“随大流”的算法。
2).专业:样本相似性:样本都是属于一个任务数据集的。样本距离越近则越相似
2.核心原理:
“近朱者赤,近墨者黑”:物以类聚,人以群分
1).关键参数:
K值:
表示最近邻的k个样本----选几个邻居?(K = 3就是看最近的3个邻居投票)
距离的度量:
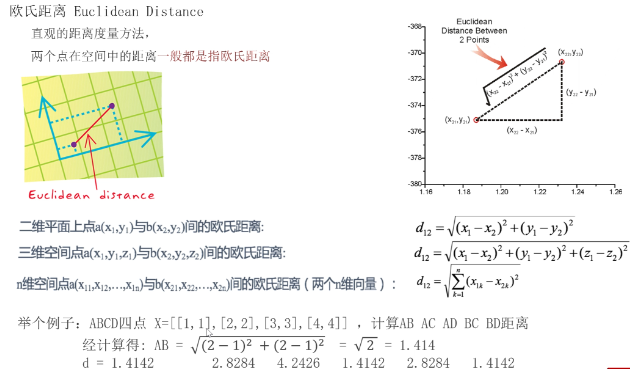
怎么算“最近”?常用欧式距离(两点间的直线距离)
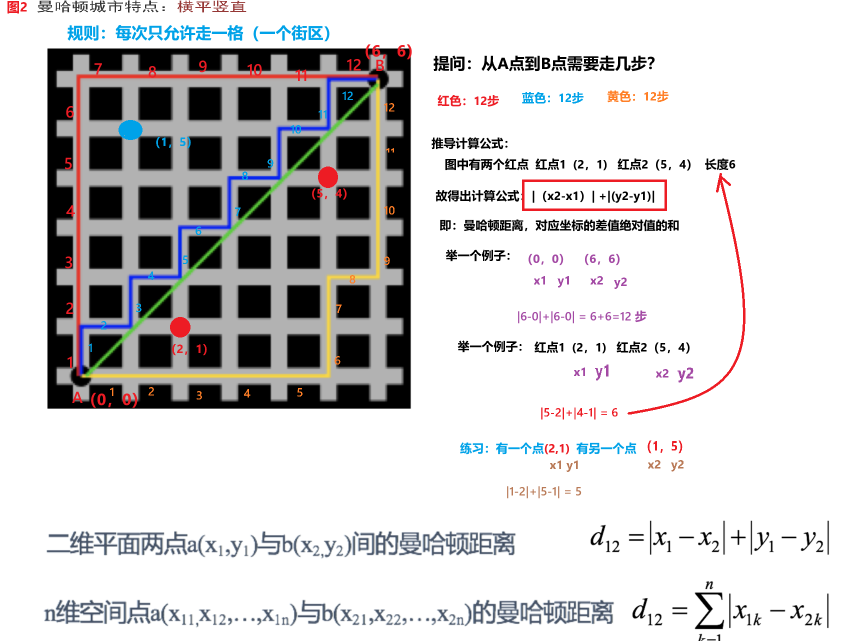
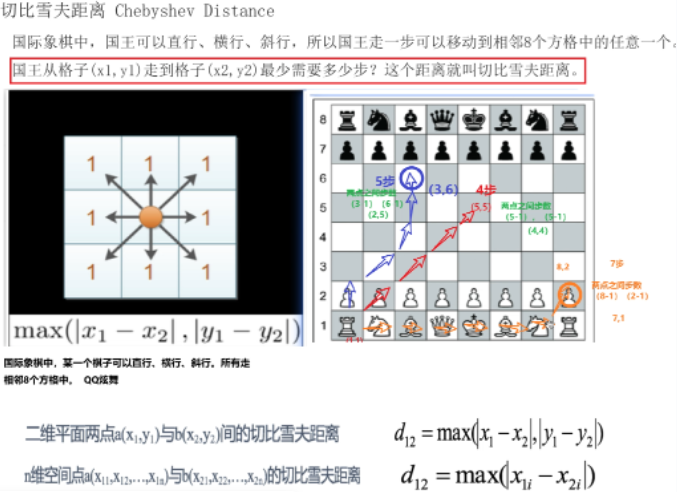
——当然还有曼哈顿距离、切比雪夫距离、
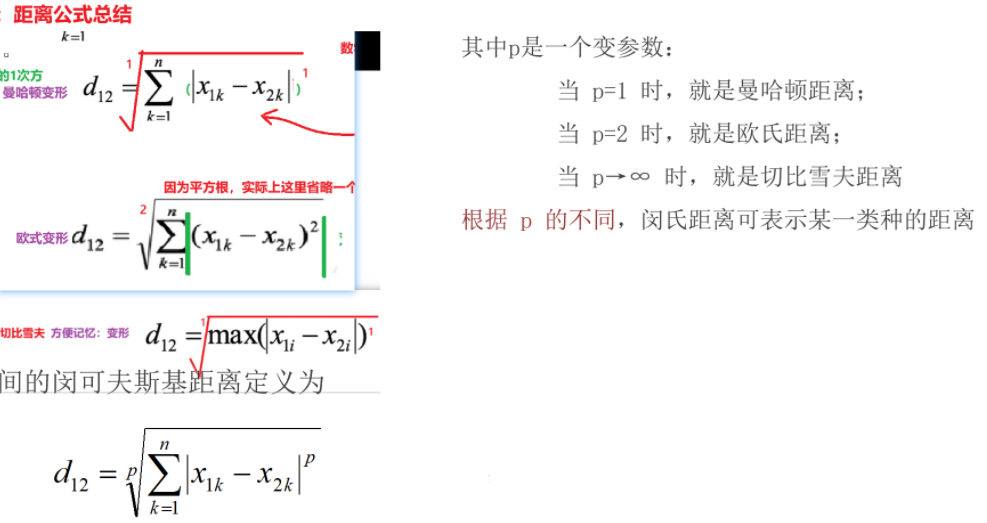
闵可夫斯基距离(它是前面三个距离的公共表达式)
总而言之:KNN就是“跟着邻居混”,邻居啥样你啥样!
3.四个距离的详解:
1).欧式距离
2).曼哈顿距离
3).切比雪夫距离
4).闵式距离(闵可夫斯基距离)
二、KNN算法的应用方式:
1.分类:
1).流程
1.计算未知样本到每一个训练样本的距离
2.将训练样本根据距离大小升序排列
3.取出距离最近的 K 个训练样本
4.进行多数表决,统计 K 个样本中哪个类别的样本个数最多
5.将未知的样本归属到出现次数最多的类别
2.)代码
# 1.导包
from sklearn.preprocessing import MinMaxScaler
# 2.准备数据
x_train = [[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]
x_test = [[100, 2, 8, 50], [30, 4, 10, 35]]
# 3.特征工程
# TODO 归一化
# 创建归一化对象
"""
feature_range:把数据按比例压缩到“0到1”的范围内。
就像把一群高矮不一的人塞进一个标准化的“身高测量尺”,
最矮的强制变成0,最高的强制变成1,其他人按比例分布在中间。
"""
mms = MinMaxScaler(feature_range=(0, 1))
# fit_transform: 用于训练集,计算最小值、最大值等结果保存到mms对象并转换
new_x_train = mms.fit_transform(x_train)
print(new_x_train)
print('-------------------------------------------------')
"""
# transform: 用于测试集,只转换(直接使用mms对象中计算结果),
如果也用fit.transform的话会造成数据泄露
"""
new_x_test = mms.transform(x_test)
print(new_x_test)2.回归
1).流程
1.计算未知样本到每一个训练样本的距离
2.将训练样本根据距离大小升序排列
3.取出距离最近的 K 个训练样本
4.把这个 K 个样本的目标值计算其平均值
5.将未知的样本的预测归属于平均值
2.)代码
# 1.导包
from sklearn.preprocessing import StandardScaler
# 2.准备数据
x_train = [[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]
x_test = [[100, 2, 8, 50], [30, 4, 10, 35]]
# 3.特征工程
# TODO 标准化
# 创建标准化对象
ss = StandardScaler()
# fit_transform: 用于训练集,计算最小值、最大值等结果保存到mms对象并转换
new_x_train = ss.fit_transform(x_train)
print(new_x_train)
print('-------------------------------------------------')
# transform: 用于测试集,只转换(直接使用mms对象中计算结果)
new_x_test = ss.transform(x_test)
print(new_x_test)
print('-------------------------------------------------')
# TODO 拓展如何获取平均值和标准差
print(ss.mean_)
print('-------------------------------------------------')
print(ss.var_)
print('-------------------------------------------------')
print(ss.scale_)三、实现流程
1.数据处理
1).划分数据集:
a.x_train:训练集特征数据
b.y_train:训练集标签数据
c.x_test:测试集特征数据
d.y_test:测试集标签数据
2.特征预处理
1).归一化:
a.相关库:sklearn.preprocessing.MinMaxScaler
b.计算公式: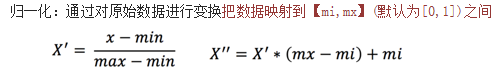
c.示例
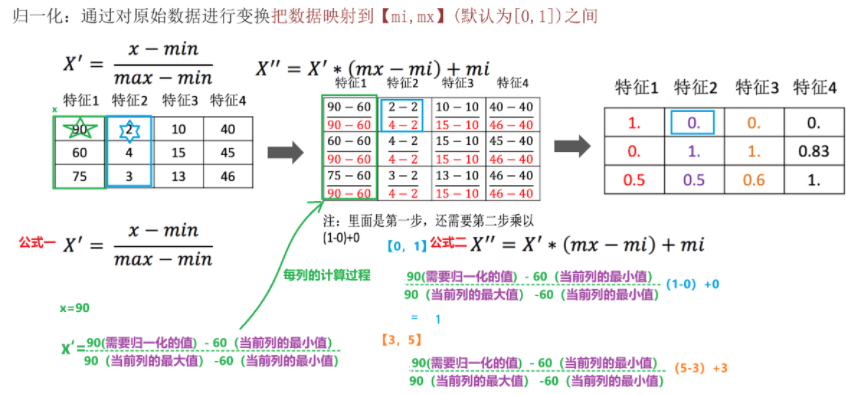
2).标准化:
a.相关库:sklearn.preprocessing.StandScaler
b.计算公式:
c.示例
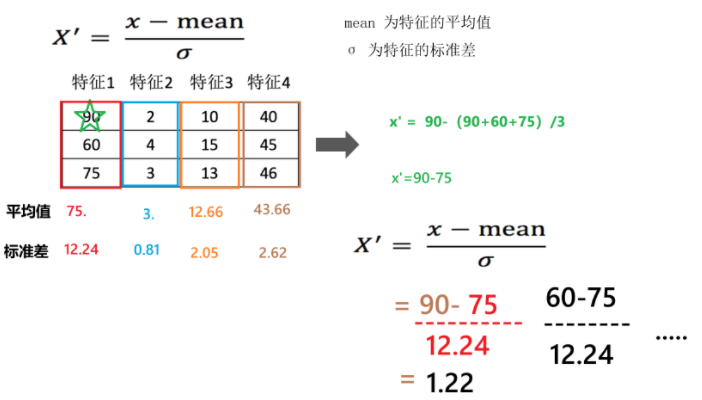
3.模型训练
1).实例化:
根据数据类型 离散选择分类,相关库:sklearn.neighbors.KNeighborsClassifier
连续选择回归,相关库:sklearn.neighbors.KNeighborsRegressor
2).训练:
fit(x_train,y_train)
3).超参数选择:
a.交叉验证:
训练集的所有数据均分cv份,每一份轮流作验证集,其它cv-1份作为训练集,cv等于几表示几折交叉验证

b.网格搜索:
网格搜索是模型调参的有力工具。寻找最优超参数的工具!
只需要将若干参数传递给网格搜索对象,它自动帮我们完成不同超参数的组合、模型训练、模型评估,最终返回一组最优的超参数。

c.交叉和网格搜索的联系 
d.GridSearchCV:

4.模型评价

四、鸢尾花案例代码:
1.鸢尾花数据的两种导入方法和两种可视化方法
# 导入相关的包
from sklearn.datasets import load_iris
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def get_data1():
# 获取鸢尾花数据集
# TODO 方式一:通过load_iris()函数
iris = load_iris()
# 特征和标签组合为DataFrame
# 特征是iris.data,标签是iris.target
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['label'] = iris.target
return df
print('-----------------------------------------')
def get_data2():
# TODO 方式二:通过pandas读取本地鸢尾花数据集
df = pd.read_csv('data/iris.csv', names=['花萼长', '花萼宽', '花瓣长', '花瓣宽', 'label'])
return df
if __name__ == '__main__':
# 获取鸢尾花数据集
# iris_data1 = get_data1()
iris_data2 = get_data2()
# 查看原始数据
print(iris_data2.head())
# matplotlib可视化查看
iris_data2.plot(kind='scatter', x='花萼长', y='花萼宽')
plt.show()
# seaborn可视化查看
"""
fit_reg: 布尔类型,默认为 True。
当设置为 True 时,seaborn 会自动拟合一条回归线(regression line)并显示在图上。
当设置为 False 时,只绘制散点图,不显示回归线。
"""
sns.lmplot(x='花萼长', y='花萼宽', hue='label', data=iris_data2, fit_reg=False)
plt.show()2.鸢尾花完整代码
# 1.导入包
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split,GridSearchCV
# 2.加载本地数据
df = pd.read_csv('data/iris.csv',names = ['花萼长', '花萼宽', '花瓣长', '花瓣宽', '标签'])
print(df.shape)
# TODO:3.按照比例切割数据集
# train_test_split 一般按照8:2或者7:3比例
# test_size 设置测试集的比例 random_state 设置随机种子,保证每次运行结果一样
x_train, x_test, y_train, y_test = train_test_split(df[['花萼长', '花萼宽', '花瓣长', '花瓣宽']], df['标签'],
test_size=0.2, random_state=1)
print(x_train.shape)
print(x_test.shape)
# 4.特征工程:标准化处理
from sklearn.preprocessing import StandardScaler
# 创建标准化对象
ss = StandardScaler()
# 先处理训练集特征
new_t_train = ss.fit_transform(x_train)
# 再处理测试集特征
new_t_test = ss.transform(x_test)
# 5.模型训练 -- 分类
# 导入包
from sklearn.neighbors import KNeighborsClassifier
# 创建模型对象
model = KNeighborsClassifier() # TODO: 这里不需要再传参
print('====================================================')
# TODO 添加网格搜索交叉验证操作
model = GridSearchCV(estimator = model,param_grid = {'n_neighbors' : [i for i in range(1,11)]},cv = 4)
# model = GridSearchCV(model,param_grid={'n_neighbors':range(1,11)},cv=5)
print('====================================================')
# 训练模型
model.fit(new_t_train,y_train)
print('====================================================')
# TODO 获取最优参数
print(model.best_params_)
print(model.best_score_)
print(model.cv_results_)
print('====================================================')
# 6.模型预测
y_predict = model.predict(new_t_test)
# 7.模型评估
# 准确率评估
# 方式1:使用accuracy_score函数进行预测值和真实值进行对比
# 导入包
from sklearn.metrics import accuracy_score
# 预测值和真实值进行对比
print(accuracy_score(y_test,y_predict))
print('-----------------------------------------')
# # 方式2:原始方式,人工手动对比
# print(y_test == y_predict )
# print(29 / 30)
print('-----------------------------------------')
















 1889
1889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









