







Multimodal Spatiotemporal Representation for Automatic Depression Level Detection
《自动抑郁检测的多模态时空表示》
——TAFFC.2020
文章提出了一种新的时空注意网络STA和多模态注意特征融合策略MAFF来获得抑郁线索的多模态表征,用于预测个体的抑郁水平。STA网络可以有效的提取输入信号的时空信息并强调与抑郁有关的特征。MAFF可以将音频特征和视频特征有效补充和融合最终得到与抑郁有关的多模态表征,在AVEC2013和AVEC2014上得到了很好的效果。
文章的创新点在于STA的框架部分和MAFF的策略部分。
输入是音频信号和面部图像。
文中认为的以往的相关工作
作者认为有些网络使用2DCNN进行特征的提取,往往会丢失或忽略掉图像中的动态信息。有些网络也尝试使用傅里叶变换获得每个行为的光谱表示原语(如面部动作单位,头姿势,凝视方向等)编码面部活动,但原语往往不足以提取详细的面部外观。在使用时空特征检测抑郁症的工作中也出现了类似的问题,即使使用了三维CNN与递归神经网络(RNN)的结合。这是因为3DCNN对所有连续帧进行平均的处理,忽略了显著特征在时间空间中的不均匀分布(没有去着重强调与抑郁有关的不均匀特征)。
且作者认为“不同的视频帧对抑郁检测的影响并不完全相同”并进行了验证—因此需要在网络中加入能有效区分关键帧的模块”
为了说明不同的视频帧对抑郁检测的影响并不完全相同,作者利用二维CNN+LSTM结构对具有60个连续视频帧的视频片段进行处理。
二维CNN+LSTM的训练过程如下:二维CNN使用视频帧进行独立训练。然后,我们将视频片段的每一帧输入到二维CNN中,并将最后一个完整连接层的输出作为帧特征。这样,视频片段就可以被编码为一个时间特征序列。最后,将特征序列输入到LSTM中,生成时间序列表示。如图1所示,(a)和(b)是一个健康个体的音频和视频时间序列表示。©和(d)是抑郁个体的结果。MATLAB中的Imagesc功能用于绘制这些图形,每一列对应于音频或视频帧。
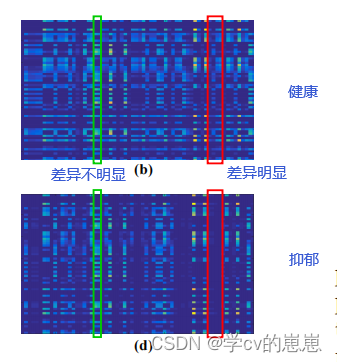
从图1中可以看出,各列中(b)与(d)之间的差异并不完全相同。例如,用红框包围的部件比用绿框包围的对应部件更具鉴别性。因此,这些音频/视频帧对于区分健康状态和抑郁状态并不同样重要。
网络框架的整体流程
首先将一个视频样本分割成固定长度的片段,并将这些片段分别输入到STA网络中,得到每个视频段对应的时间和空间特征,再将多个视频段级的特征经过EEP(特征演化池)融合成视频级特征VLF,再将VLF和ALF经过MLAFF进行模态间的对照融合最终得到抑郁严重程度的得分。
网络的流程如下图所示:
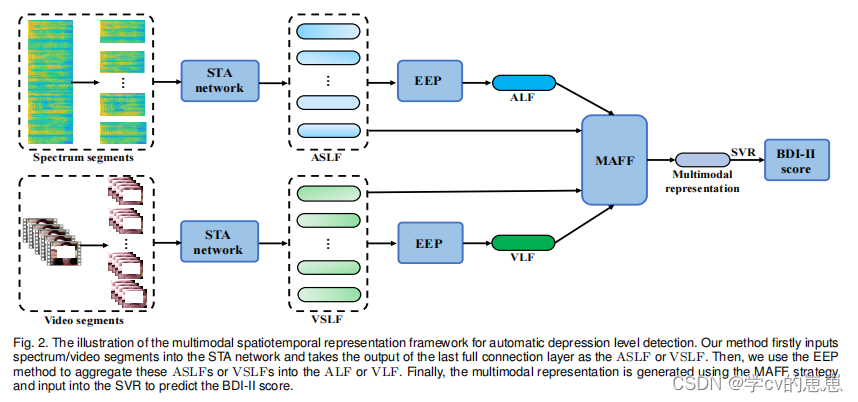
记录一下视频部分是如何处理的。语音类似,只是处理的数学公式不同。
方法的工作分为段特征提取部分、段级特征聚合和模态融合等部分。
1 段级特征提取
段级特征的提取由STA模块完成。
首先是一个视频段(文章这里使用了60帧图片)输入STA,SYA分为两支路,一个是3DCNN支路,提取空间特征,一个视频段对应一个特征向量。一个支路是2DCNN+LSTM,来提取是频段的时间信息,每帧图片对应一个特征向量,接着通过注意力的计算方式来将两种特征进行融合,在此过程中网络会给重要帧分配一个重要参数来区别关键帧,达到强调关键帧的作用。最终,一个视频段对应一个特征向量VSLF。
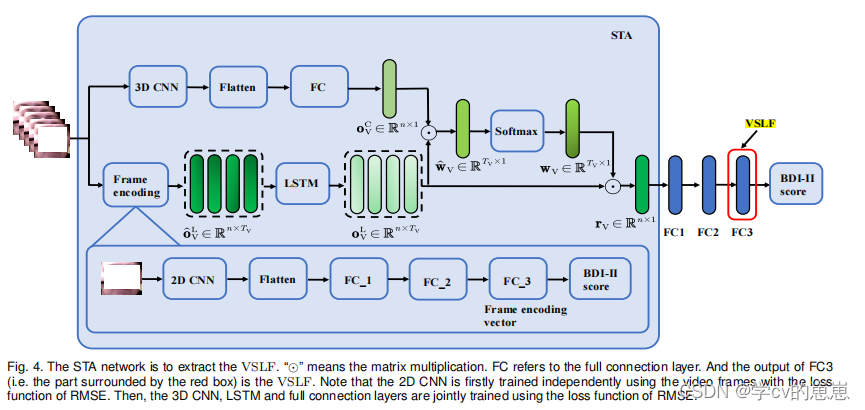
时空注意网络STA的来源
在[48]中提出了一种时间注意模型,可以强调抑郁检测的特征序列中的关键特征。但是,[48]中使用的行为原语不足以表征面部外观。此外,在表情识别[37]领域开发了一种时空表示方法。这种方法不仅检查了不同视频帧之间的差异,而且还提供了整个面部的空间外观。考虑到这两项工作的优势,提出了STA网络来生成音频/视频数据的时空表示,并突出有助于抑郁检测的帧。
此外,我们还提出了一种多模态注意特征融合(MAFF)策略来提取模态之间的互补信息,以提高多模态表示的质量。具体来说,我们的方法由三个步骤组成。
2 段级特征聚合
段级特征融合使用EEP特征演化池。
3 音频和视频模态的融合
MAFF是对音频特征和视频特征进行有效融合的。生成具有模态互补信息的多模态表示,并输入到支持向量回归预测器来估计抑郁症的严重程度。
网络的输入信号是抑郁症患者的语音信号和视频信号。输出是BDI-II得分(the Beck Depression Inventory-II score)。
网络的工作流程
首先,我们将长期语音振幅谱/视频①分割成固定长度的段,并②将这些段输入到STA网络中:第一支路将一个视频片段输入到3DCNN中,以提取空间特征。第二支路采用LSTM或2DCNN+LSTM网络,获得与视频段对应的时间序列表示。然后,③我们利用空间特征和时间序列表征之间的注意机制。该过程不仅将空间特征嵌入到时间序列表示中,而且还为时间序列表示中的每个帧特征分配不同的权值系数,以强调与抑郁检测相关的帧。视频段级的时空特征(VSLF)可以从STA网络的最后一个完整连接层的输出中获得。其次,④为了获得长期视频的表示,我们采用特征进化池(EEP)方法总结了段级特征(VSLF)中各维度的变化,并将其聚合为视频级特征(VLF)。⑤在ALF和vslf之间使用注意机制来获得音频注意视频特征(AAVF)。这样,我们从视频模态中获得了与音频模态相似的信息,并实现了音频模态对视频模态的补充。同样,视频注意音频特征(VAAF)是通过VLF和aslf之间的注意机制获得的。在本文中,我们将AAVF和VAAF作为模态互补信息。多模态表示可以通过连接ALF、AAVF、VLF和VAAF来生成。并采用支持向量回归(SVR)方法预测个体抑郁水平。
文章贡献
1)我们提出了一种新的时空注意(STA)网络,它不仅利用注意机制将空间特征嵌入到时间序列表示中,而且强调了有助于抑郁检测的音频和视频帧。
2)在本文中,我们采用EEP方法来总结段级特征各维度的变化,以便将aslf或vslf聚合到ALF或VLF中。据我们所知,这是第一次将EEP方法应用于自动抑郁检测领域。
3)我们提出了一种多模态注意特征融合(MAFF)策略。该方法利用注意机制提取不同模态之间的互补信息,以提高多模态表示的质量。















 3791
3791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









