









spark2--rdd
- 1. RDD概念
- 1.1 RDD定义
- 1.2 RDD 五大特性
- 第一个:A list of partitions
- 第二个:A function for computing each split
- 第三个:A list of dependencies on other RDDs
- 第四个:Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- 第五个:Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
- 图释
- 1.3 RDD的分区
- 2. RDD 算子分类
- 3. Spark容错机制
- 4. Spark共享变量
- 5. Sparkcore 模板
- 6. RDD 基础算子
- 7. RDD常用分析算子
- 8. RDD其他算子
- 9. Spark容错机制
- 10. Spark共享变量
1. RDD概念
1.1 RDD定义
RDD(Resilient Distributed Dataset)叫做弹性 分布式 数据集,是Spark中最基本的数据抽象,
代表一个不可变类型、可分区、里面的元素可并行计算的集合。可以认为RDD是分布式的"列表List或数组Array"(与其说是列表不如说是元组【其本身是不可变类型,只能通过血缘追踪】)

1.2 RDD 五大特性
第一个:A list of partitions
每个RDD都由一系列的分区构成**
对于RDD来说,每个分片都会被一个计算任务处理,分片数决定并行度;
用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值.
第二个:A function for computing each split
RDD的计算操作,是对RDD每个分区的计算**
Spark中RDD的计算是以分片为单位的,计数函数会被作用到每个分区上.
第三个:A list of dependencies on other RDDs
一个RDD会依赖于其他多个RDD
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算(Spark的容错机制).
第四个:Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
可选的,如果是二元组【KV】类型的RDD,在Shuffle过程中可以自定义分区器
当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner;
只有对于于key-value的RDD,才会有Partitioner,非key-va lue的RDD的Parititioner的值是None;
Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
第五个:Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
可选的,Spark程序运行时,Task的分配可以指定实现最优路径解:最优计算位置
对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。
按照"移动数据不如移动计算"的理念,Spark在进行任务调度的时候,会尽可能选择那些存有数据的worker节点来进行任务计算。(数据本地性)
图释

1.3 RDD的分区
分区是一个偏物理层的概念,也是 RDD 并行计算的核心。数在 RDD 内部被切分为多个子集合,每个子集合可以被认为是一个分区,运算逻辑最小会被应用在每一个分区上,每个分区是由一个单独的任务(task)来运行的,所以分区数越多,整个应用的并行度也会越高。子RDD的分区数 = 父RDD的分区数
RDD分区的设置
- RDD分区的原则是使得分区的个数尽量等于集群中的CPU核心(core)数目,这样可以充分利用CPU的计算资源;
- 在实际中为了更加充分的压榨CPU的计算资源,会把并行度设置为cpu核数的2~3倍;
2. RDD 算子分类
2.1 RDD模式的lazy模式
代码只定义不执行,不触发job。自然也就不构建Task,不产生RDD的数据。等待真正使用到对应RDD的数据返回给用户时,才会触发了job运行,执行所有RDD的构建和转换。
2.2 Tranformation算子:转换算子
- 功能:用于实现对RDD的数据进行转换
- 特点:都是lazy模式的,"一般"不会触发job的运行,算子返回值一定是RDD
2.3 Action算子:触发算子 行动算子
- 功能:触发job的运行,用户对RDD的数据进行输出或者保存
- 特点:一定会触发job的运行,返回值一定不是RDD
3. Spark容错机制
3.1 RDD 容错机制(persist缓存)
实际开发中某些RDD的计算或转换可能会比较耗费时间(RDD来之不易,并且使用不止一次),或某些RDD会频繁使用,那么可以将这些RDD进行持久化/缓存,来提高性能。缓存必须要通过触发算子触发,才能生效,如果缓存的RDD丢失了,那么只能通过血脉重新构建缓存。
-
cache:将RDD缓存在内存中
-
persist:将RDD【包含这个RDD的依赖关系】进行缓存,可以自己指定缓存的级别【和cache区别】
缓存级别:

-
unpersist: 将缓存的RDD进行释放
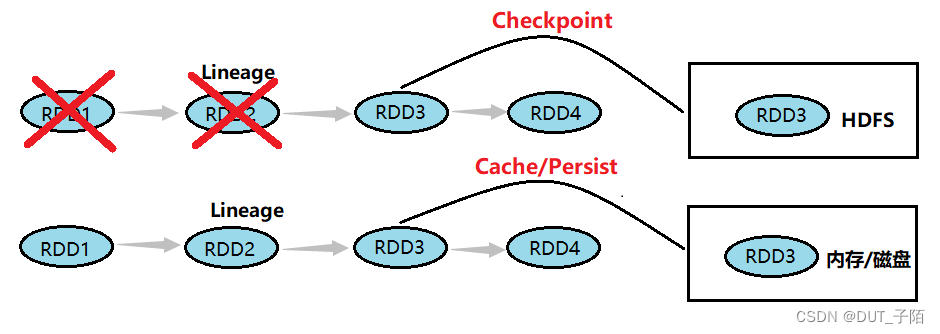
3.2 checkpoint检查点机制
RDD 数据可以持久化,但是持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
Checkpoint的产生就是为了更加可靠的数据持久化,在Checkpoint的时候一般把数据放在在 HDFS上,这就天然的借助了HDFS天生的高容错、高可靠来实现数据最大程度上的安全,实现了RDD的容错和高可用。
对RDD做checkpoint,可以切断对RDD的依赖关系,将RDD数据保存到可靠存储(如HDFS)以便数据恢复;
3.3 持久化和Checkpoint的区别
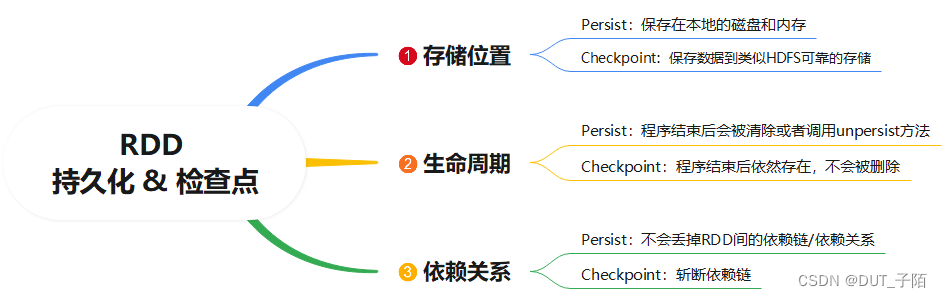
是否斩断血缘依赖:
4. Spark共享变量
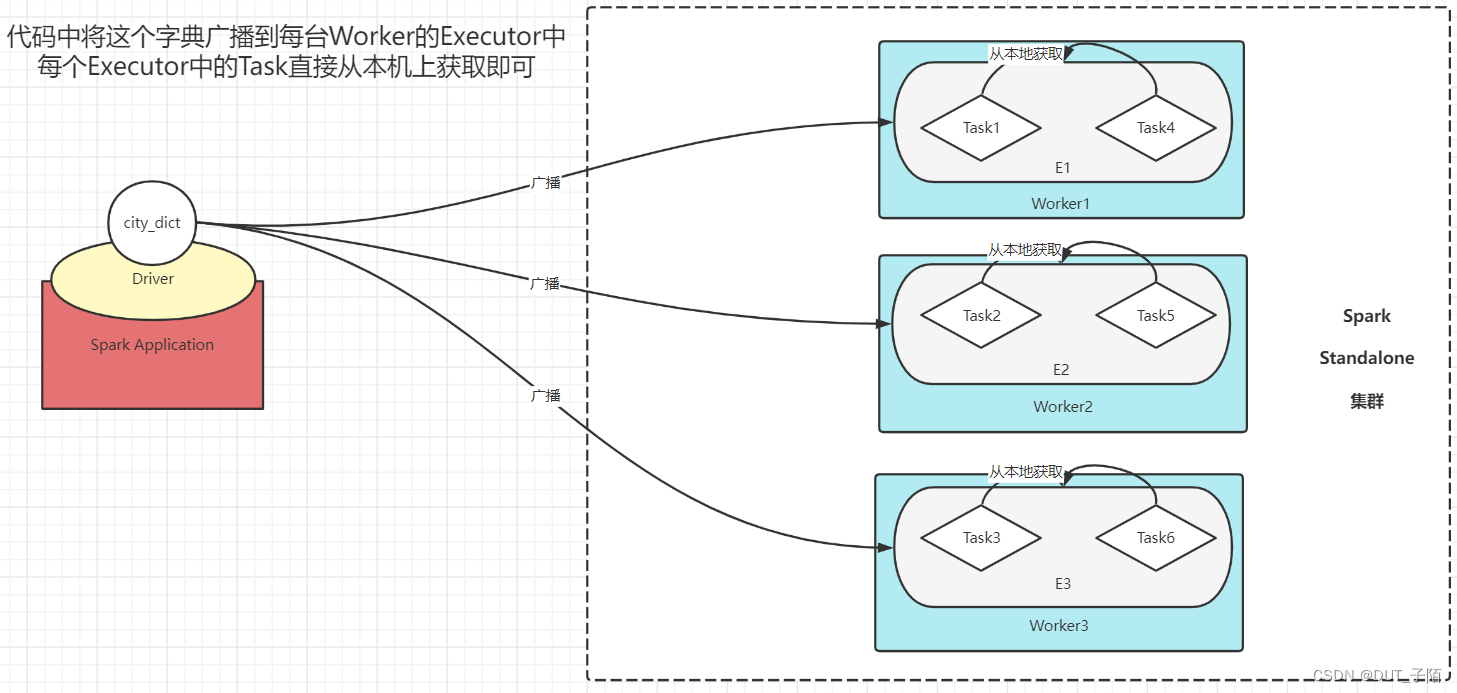
4.1 广播变量
广播变量: 将一个变量元素进行广播到每台Worker节点的Executor中,让每个Task直接从本地读取数据,减少网络传输IO,提高性能。如大小表join时,可以将小表进行广播。广播变量是一个只读变量,不能修改
4.2 Accumulators累加器
Accumulators累加器: 实现分布式的计算,在每个Task内部构建一个副本进行累加,并且返回每个Task的结果最后进行合并。累加器必须由触发算子触发才会生效。
5. Sparkcore 模板
下面所有的代码都依照这个模板运行,只编写这一块的内容 # todo:2-数据处理:读取、转换、保存
from pyspark import SparkContext, SparkConf
import os
if __name__ == '__main__':
# todo:0-设置系统环境变量
# 配置JDK的路径,就是前面解压的那个路径
os.environ['JAVA_HOME'] = '/export/server/jdk'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = '/export/server/hadoop'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = '/export/server/anaconda3/bin/python3'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = '/export/server/anaconda3/bin/python3'
# 若没有配置以下配置,则默认路径为 程序提交的当前位置(file:/root/pyspark_code_zimo/"当前项目名"/)
# 以下配置,配置后,文件数据默认路径为 hdfs://node1.itcast.cn:8020/user/root
# 配置Hadoop的配置路径(Yarn提交特有)
# os.environ['HADOOP_CONF_DIR'] = '/export/server/hadoop/etc/hadoop/'
# 配置Yarn的配置路径(Yarn提交特有)
# os.environ['YARN_CONF_DIR'] = '/export/server/hadoop/etc/hadoop/'
# 配置Hadoop的配置路径(Yarn提交特有)
# os.environ['HADOOP_CONF_DIR'] = '/export/server/hadoop/etc/hadoop/'
# 配置Yarn的配置路径(Yarn提交特有)
# os.environ['YARN_CONF_DIR'] = '/export/server/hadoop/etc/hadoop/'
# 申明当前以root用户的身份来执行操作
os.environ['HADOOP_USER_NAME'] = 'root'
# todo:1-构建SparkContext
# 修改运行模式为集群
# local模式
conf = SparkConf().setMaster("local[3]").setAppName("zimo set Remoteapp name")
# standalone模式
# conf = SparkConf().setMaster("spark://node1.itcast.cn:7077").setAppName("zimo set Remoteapp name")
# yarn模式
# conf = SparkConf().setMaster("spark://node1.itcast.cn:7077").setAppName("zimo set Remoteapp name")
sc = SparkContext(conf=conf)
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
# step2: 处理数据
# step3: 保存结果
# todo:3-关闭SparkContext
sc.stop()
6. RDD 基础算子
6.1 创建RDD算子(parallelize,textFile,wholeTextFile)
创建RDD算子:
| 算子名称 | 算子功能 |
|---|---|
| parallelize (list , numSlices=分区数) | 并行化一个已存在的集合 |
| textFile (文件路径 , minPartitions=最小分区数) | 读取外部文件 |
| wholeTextFile (文件夹路径 , minPartitions=最小分区数) | 取外部小文件 |
出现的其他函数:
| 算子名称 | 算子功能 |
|---|---|
| getNumPartitions () | 获取RDD分区数 |
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
input_rdd1 = sc.parallelize(data, numSlices=2)
# input_rdd2 = sc.textFile("hdfs://node1:8020/zimo/wordcount/data.txt",minPartitions=2)
input_rdd2 = sc.textFile("file:///root/pyspark_code_zimo/pyspark4/data.txt",minPartitions=2)
input_rdd3 = sc.wholeTextFiles("file:///root/pyspark_code_zimo/pyspark4/ratings100",minPartitions=3)
# step2: 处理数据
print("----- parallelize -----")
print(f"分区数:{input_rdd1.getNumPartitions()}")
print(input_rdd1.collect())
print("----- textFile -----")
re_rdd2=input_rdd2.map(lambda line: re.split(',',line))
print(f"分区数:{input_rdd2.getNumPartitions()}")
for item in re_rdd2.collect():
print(item)
print("----- wholeTextFiles -----")
print(f"分区数:{input_rdd3.getNumPartitions()}")
# 返回的是数组二元组[("文件名1","文件内容1”),("文件名2","文件内容2”)...]
print(input_rdd3.first())
for i in range(2):
print(f"第{i}行数据")
line_rdd = input_rdd3.flatMap(lambda content: content[i].split("\n"))
for item in line_rdd.take(5):
print(item)
6.2 基础转换算子(map,flatMap,filter)
基础转换算子:
| 算子名称 | 算子功能 | 使用场景 |
|---|---|---|
| map (self , f: T -> U ) -> RDD[U] | 对RDD中每个元素调用一次参数中的函数,并将每次调用的返回值放入一个新的RDD中 | 一对一转换 |
| flatMap (self , f : T -> Iterable[U]) -> RDD[U] | 将两层嵌套集合中的每个元素取出,扁平化处理,放入一层集合中返回,类似于SQL中explode函数 | 一对多转换 |
| filter (self, f: T -> bool ) -> RDD[T] | 对RDD集合中的每个元素调用一次参数中的表达式进行数据过滤,符合条件就保留,不符合就过滤 | 数据过滤 |
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
data1=[1,2,3,4,5,6,7,8]
input_rdd1=sc.parallelize(data1,numSlices=2)
data2=["子陌-是个-大帅逼","","edg-牛逼"]
input_rdd2 = sc.parallelize(data2, numSlices=2)
data3=["1 王一 女 21", "2 赵二 女 27", "3 张三 男 25",
"4 李四 女 2897", "5 男 21", "6 老六 男 18",]
input_rdd3 = sc.parallelize(data3, numSlices=2)
# step2: 处理数据
rs_rdd1=input_rdd1.map(lambda x:x+10)
print("===== map =====")
print(rs_rdd1.collect())
rs_rdd2=input_rdd2.flatMap(lambda line:re.split("-",line))
print("===== flatMap =====")
print(rs_rdd2.collect())
rs_rdd3=input_rdd3.filter(lambda line:len(re.split("\\s+",line))==4
and int(re.split("\\s+",line)[3])<200)
print("===== filter =====")
rs_rdd3.foreach(lambda x:print(x))
# step3: 保存结果
# 保存到文件中
6.3 基础行动算子(count,foreach,saveAsTextFile)
基础行动算子:
| 算子名称 | 算子功能 |
|---|---|
| count (self) -> int | 统计RDD中元素的个数,返回一个int值 |
| foreach (self , f : T -> None) -> None | 对RDD中每个元素调用一次参数中的函数,没有返回值 |
| saveAsTextFile (self , path ) -> None | 用于将RDD数据保存到外部文件系统中 |
# step1: 读取数据
data1=["子陌-是个-大帅逼","","edg-牛逼"]
input_rdd1 = sc.parallelize(data1, numSlices=2)
# step2: 处理数据
rs_rdd1=input_rdd1.flatMap(lambda line:re.split("-",line))
print("===== count =====")
print(f"input_rdd中元素个数:{input_rdd1.count()}")
print(f"rs_rdd中元素个数:{rs_rdd1.count()}")
print("===== foreach =====")
rs_rdd1.foreach(lambda x:print(x))
print("===== saveAsTextFile =====")
rs_rdd1.saveAsTextFile("hdfs://node1:8020/zimo/wordcount/word_output10")
# step3: 保存结果
# 保存到文件中
6.4 常见行动算子(first,take,collect,reduce)
常见行动算子:
| 算子名称 | 算子功能 |
|---|---|
| first (self) -> T | 返回RDD集合中的第一个元素 |
| take (self , num:int ) -> List[T] | 返回RDD集合中的前N个元素 |
| collect (self) -> List[T] | 将RDD转化成一个列表返回 |
| reduce (self,f : (T,T) -> U) -> U | 将RDD中的每个元素按照给定的聚合函数进行聚合,返回聚合的结果 |
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
data1=[1,2,3,4,5,6,7,8,9,10]
input_rdd1=sc.parallelize(data1,numSlices=2)
print("")
#step2: 处理数据
print("----- first -----")
print(f"第一个元素:{input_rdd1.first()}")
print("----- take -----") # 只适用于take小数据,因为会把所有结果数据加载到内存
print(f"前几个元素:{input_rdd1.take(3)}")
print("----- collect -----") # 只适用于小数据,因为会把RDD所有数据加载到内存
print(f"rdd所有元素:{input_rdd1.collect()}")
print("----- reduce -----")
print(f"分区数{input_rdd1.getNumPartitions()}")
input_rdd1.foreach(lambda x : print(x,"\t---所属分区:",TaskContext().partitionId()))
def fun1(x,y):
print(f"分区:{TaskContext().partitionId()},x={x},y={y},x-y={x-y}")
return x-y
print('',f"减法过程:{input_rdd1.reduce(fun1)}",sep='\n')
print(f"加法:{input_rdd1.reduce(lambda temp,item:temp+item)}")
# step3: 保存结果
# 保存到文件中
7. RDD常用分析算子
7.1 转换算子(union,distinct)
转换算子:
| 算子名称 | 算子功能 |
|---|---|
| union (self,other:RDD[U]) -> RDD[T/U] | 实现两个RDD中数据的合并 |
| distinct (self) -> RDD[T] | 实现对RDD元素的去重 |
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
data1 = [1,3,5,6,7,8,9,11,13]
data2 = [1,2,3,4,6,8,10,12,14]
input_rdd1 = sc.parallelize(data1, numSlices=3)
input_rdd2 = sc.parallelize(data2, numSlices=2)
print(input_rdd1.getNumPartitions())
print(input_rdd2.getNumPartitions())
# step2: 处理数据
# ----- union ----- (不经过suffle)
union_rdd = input_rdd1.union(input_rdd2)
print(union_rdd.getNumPartitions())
print(union_rdd.collect())
# ----- distince ----- (去重)
distince_rdd=union_rdd.distinct()
print(distince_rdd.collect())
# step3: 保存结果
7.2 分组聚合算子(groupByKey,reduceByKey)
分组聚合算子:
| 算子名称 | 算子功能 | 使用场景 |
|---|---|---|
| groupByKey (self, numpartitions, partitionFunction) -> RDD[Tuple[K,Iterable[V]]] | 对KV类型的RDD按照Key进行分组,相同K的Value放入一个集合列表中 | 需要对数据进行分组的场景,或者说分组以后的聚合逻辑比较复杂,不适合用reduce |
| reduceByKey (self,f: (T,T) -> T,numPartitions,partitionFunction) -> RDD[Tuple[K,V]] | 对KV类型的RDD按照Key进行分组,并对相同Key的所有Value使用参数中的函数进行聚合 | 需要对数据进行分组并且聚合的场景 |
groupByKey+map 与 reduceByKey的区别:
- groupByKey 没有Map端聚合的操作,只做分组,必须等分区结束才能实现,最终map需要做整体聚合
- reduceByKey是有Map端聚合操作,先分区内部聚合,再做分区间的聚合
- reduceByKey直接分组聚合的性能要高于先做groupByKey再做聚合的方式
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
input_rdd=sc.textFile("file:///root/pyspark_code_zimo/pyspark5/datas/wordcount/word.txt")
# step2: 处理数据
tuple_rdd=(
# 过滤空行
input_rdd.filter(lambda line : len(line.strip())>0)
# 扁平化,切割
.flatMap(lambda line : re.split('\\s+',line.strip()))
# 转换成二元组
.map(lambda word : (word,1))
)
# tuple_rdd.foreach(lambda x : print(x))
# ----- groupByKey+map -----
print("----- groupByKey+map -----")
group_rdd=tuple_rdd.groupByKey()
# print(group_rdd.collect())
rs_rdd=group_rdd.map(lambda x:(x[0],len(x[1])))
print(rs_rdd.collect())
# ----- reduceByKey -----
print("----- reduceByKey -----")
rs_rdd=tuple_rdd.reduceByKey(lambda temp,item:temp+item)
print(rs_rdd.collect())
# step3: 保存结果
7.3 排序算子(sortBy,sortByKey)
排序算子:
| 算子名称 | 算子功能 | 使用场景 |
|---|---|---|
| sortBy (self, keyFunc:(T) -> 0, asc: Boolean, numPartitions) -> RDD | 对RDD中的所有元素进行整体排序,可以指定排序规则 | 适用于所有对数据排序的场景,一般用于对大数据量非KV类型的RDD的数据排序 |
| sortByKey (self, asc, numPartitions) -> RR[Tuple[K,V]] | 对RDD中的所有元素按照Key进行整体排序,可以指定排序规则 | 适用于大数据量的KV类型的RDD按照Key排序的场景 |
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
input_rdd=sc.textFile("file:///root/pyspark_code_zimo/pyspark5/datas/function_data/sort.txt",minPartitions=2)
# step2: 处理数据
# todo: 虽然sortBy和sortByKey是转化算子但是他们仍然会执行job
# ----- sortBy ----- (需要suffle)
print("----- sortBy -----")
sort_rdd=input_rdd.sortBy(keyfunc=lambda line:line.split(',')[1]
,ascending=False # 默认升序
,numPartitions=2)
sort_rdd.foreach(lambda x : print(x))
# ----- sortByKey ----- (需要suffle)
print("----- sortByKey -----")
def to_tuple(x):
list=x.split(',')
return (list[1],(list[0],list[2]))
tuple_rdd=input_rdd.map(lambda x : to_tuple(x))
sort_rdd=tuple_rdd.sortByKey(ascending=False,numPartitions=2)
sort_rdd.foreach(lambda x :print(x))
# step3: 保存结果
7.4 TopN算子(top,takeOrdered)
TopN算子:
| 算子名称 | 算子功能 | 特点 |
|---|---|---|
| top (self,num) -> List[0] | 对RDD中的所有元素降序排序,并返回前N个元素,即返回RDD中最大的前N个元数据 | 不经过Shuffle,将所有元素放入Driver内存中排序,性能更好,只能适合处理小数据量 |
| takeOrdered(self,num) -> List[0] | 对RDD中的所有元素升序排序,并返回前N个元素,即返回RDD中最小的前N个元数据 | 不经过Shuffle,将所有元素放入Driver内存中排序,只能适合处理小数据量 |
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
data=[1,2,3,4,5,6,7,8,9]
input_rdd=sc.parallelize(data,numSlices=2)
# step2: 处理数据
# todo:只适合小数据,因为会把所有数据导入内存,不经过shuffle
# ----- top ----- 取最大
print("----- top -----")
list_rdd=input_rdd.top(3)
print(*list_rdd)
# ----- takeOrdered ----- 取最小
print("----- takeOrdered -----")
list_rdd=input_rdd.takeOrdered(3)
print(*list_rdd)
# step3: 保存结果
7.5 重分区算子(repartition,coalesce)
重分区算子:
| 算子名称 | 算子功能 | 特点 |
|---|---|---|
| repartition (self,numPartitions) -> RDD[T] | 调整RDD的分区个数 | 必须经过Shuffle过程,repartition底层就是coalesce(shuffle=True) |
| coalesce (self, numPartitions, shuffle:boolean) -> RDD[T] | 降低分区个数,不需要经过shuffle就可以实现 | 可以选择是否经过Shuffle,默认情况下不经过shuffle |
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
data = [1,3,5,6,7,8,9,11,13,1,2,3,4,6,8,10,12,14]
input_rdd = sc.parallelize(data, numSlices=2)
print(input_rdd.getNumPartitions())
distinct_rdd=input_rdd.distinct()
# step2: 处理数据
# ----- repartition ----- (可以调大或者调小,必须经过shuffle)
print("----- repartition -----")
up_rdd=distinct_rdd.repartition(3)
print(up_rdd.getNumPartitions())
# ----- coalesce ----- (只能调小,可以不经过shuffle)
print("----- coalesce -----")
down_rdd=distinct_rdd.coalesce(1)
print(down_rdd.getNumPartitions())
# step3: 保存结果
8. RDD其他算子
8.1 其他聚合算子(fold,aggregate)
其他聚合算子:
| 算子名称 | 算子功能 | 特点 |
|---|---|---|
| fold (self, zeroValue: T, f:(T,T) -> T) -> T | 将RDD中的每个元素按照给定的聚合函数进行聚合,返回聚合的结果 | 有初始值,每个分区在计算时都会计算上初始值,分区间计算时也会计算1次初始值 (初始值一共会被聚合 分区数+1次) |
| aggregate (self, zeroValue: T, f1:(T,T) -> T, f2:(T,T) -> T) -> T | 将RDD中的每个元素进行聚合,返回聚合的结果 | 有初始值,并且可以单独指定分区内聚合逻辑和分区间聚合逻辑,分区间计算时也会计算1次初始值 (初始值一共会被聚合 分区数+1次) |
聚合算子reduce,fold,aggregate的区别与共性:
- 共性:都是带有Map聚合的算子
- 区别:
算子名 是否支持初始值 分区内与分区间聚合逻辑是否一致 reduce 不支持 一致 fold 支持 一致 aggregate 支持 不一致
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
input_rdd = sc.parallelize(data, numSlices=2)
# step2: 处理数据
def fun1(x,y):
print(f"分区:{TaskContext().partitionId()},x={x},y={y},x-y={x - y}")
return x - y
# ----- fold -----
print("----- fold -----")
foldrs_rdd=input_rdd.fold(1,fun1)
print(f"foldrs_rdd = {foldrs_rdd}")
# ----- aggregate -----
print("----- aggregate -----")
aggrs_rdd=input_rdd.aggregate(zeroValue=10,seqOp=fun1,combOp=lambda temp,item:temp+item)
print(f"aggrs_rdd = {aggrs_rdd}")
# step3: 保存结果
8.2 其他KV类型算子(keys,values,mapValues,collectAsMap)
其他KV类型算子:
| 算子名称 | 算子功能 |
|---|---|
| keys (self: RDD[Tuple[K,V]] ) -> RDD[K] | 针对二元组KV类型的RDD,返回RDD中所有的Key,放入一个新的RDD中 |
| values (self: RDD[Tuple[K,V]] ) -> RDD[V] | 针对二元组KV类型的RDD,返回RDD中所有的Value,放入一个新的RDD中 |
| mapValues (self: RDD[Tuple[K,V]], f: (V) -> U) -> RDD[Tuple[K,U]] | 针对二元组KV类型的RDD,对RDD中每个元素的Value进行map处理,结果放入一个新的RDD中 |
| collectAsMap (self: RDD[Tuple[K,V]]) -> Dict[K,V] | 将二元组类型的RDD转换成一个Dict字典(将RDD中元素的结果放入Driver内存中的一个字典中,数据量必须要小) |
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
data=[("老一",21),("老二",22),("老三",23),("老四",24),("老五",25)]
input_rdd=sc.parallelize(data,numSlices=2)
# step2: 处理数据
# ----- keys ------
print("----- keys ------")
keys_rdd=input_rdd.keys()
print(keys_rdd.collect())
# ----- values ------
print("----- values ------")
values_rdd=input_rdd.values()
print(values_rdd.collect())
# ----- mapValues ----- (只对 kv中的v进行map操作)
print("----- mapValues ------")
kv_rdd=input_rdd.mapValues(lambda value : value+10)
print(kv_rdd.collect())
# ----- collectAsMap ----- (变成字典)
print("----- collectAsMap ------")
coll_rdd=input_rdd.collectAsMap() # 返回一整个字典
print(coll_rdd)
# step3: 保存结果
8.3 Join关联算子(join,fullOuterJoin,leftOuterJoin,rightOuterJoin)
关联算子:
| 算子名称 | 算子功能 |
|---|---|
| join (self: RDD[Tuple[K,V]], otherRdd: RDD[Tuple[K,W]]) -> RDD[Tuple[K,(V,W)]] | 实现两个KV类型的RDD之间按照K进行关联,将两个RDD的关联结果放入一个新的RDD中 |
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
data1=[("老一",20),("老二",20),("老三",20),("老四",20),("老六",20)]
data2=[("老一","female"),("老二","male"),("老三","male"),("老五","female")]
input_rdd1=sc.parallelize(data1,numSlices=2)
input_rdd2=sc.parallelize(data2,numSlices=2)
# step2: 处理数据
# ----- join ----- (内连接)
print("----- join -----")
join_rdd1=input_rdd1.join(input_rdd2)
print(join_rdd1.collect())
# ----- fullOuterJoin ----- (内连接)
print("----- fullOuterJoin -----")
join_rdd2 = input_rdd1.fullOuterJoin(input_rdd2)
print(join_rdd2.collect())
# ----- leftOuterJoin ----- (内连接)
print("----- leftOuterJoin -----")
join_rdd3 = input_rdd1.leftOuterJoin(input_rdd2)
print(join_rdd3.collect())
# ----- rightOuterJoin ----- (内连接)
print("----- rightOuterJoin -----")
join_rdd4 = input_rdd1.rightOuterJoin(input_rdd2)
print(join_rdd4.collect())
8.4 分区处理算子(mapPartitions , foreachPartition)
** 分区处理算子:**
| 算子名称 | 算子功能 |
|---|---|
| mapPartitions (self: RDD[T], f: Iterable[T] -> Iterable[U] ) -> RDD[U] | 对RDD每个分区的数据进行操作,将每个分区的数据进行map转换,将转换的结果放入新的RDD中 |
| foreachParition (self: RDD[T] , f: Iterable[T] -> None) -> None | 对RDD每个分区的数据进行操作,将整个分区的数据加载到内存进行foreach处理,没有返回值 |
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
input_rdd=sc.parallelize((1,2,3,4,5,6,7,8,9),numSlices=2)
# step2: 处理数据
# # ----- 单元素操作 -----
# map_rdd=input_rdd.map(lambda x:x+100)
# def saveToMysql(x):
# print(x)
# map_rdd.foreach(lambda x:saveToMysql(x))
# ----- 分区操作 -----
def opPart(part):
rs=[i+100 for i in part]
return rs
mapPar_rdd=input_rdd.mapPartitions(lambda part:opPart(part))
def saveToMysql(part):
for i in part:
print(i)
# repartition增大分区防止内存溢出
mapPar_rdd.repartition(4).foreachPartition((lambda part:saveToMysql(part)))
# step3: 保存结果
9. Spark容错机制
9.1 缓存机制(cache , persist , unpersist,checkpoint)
缓存机制:
| 算子名称 | 算子功能 | 注意点 |
|---|---|---|
| cache | 将RDD缓存在内存中 | 只缓存在内存,如果内存不够,缓存会失败 |
| persist (StorageLevel) | 将RDD(包含这个RDD的依赖关系)进行缓存,可以自己指定缓存的级别(和cache区别) | 缓存级别在下方 |
| unpersist (blocking=True) | 将缓存的RDD进行释放 | blocking=True时:等释放完再继续下一步;如果不释放,Spark程序结束,也会释放这个程序中的所有内存 |
| setCheckpointDir (path) | 设置缓存位置 | 只缓存在内存,如果内存不够,缓存会失败 |
| checkpoint | 将RDD的数据(不包含RDD依赖关系)存储在HDFS上 | 只缓存在内存,如果内存不够,缓存会失败 |
# 缓存在磁盘中:注意这不是HDFS
StorageLevel.DISK_ONLY = StorageLevel(True, False, False, False)
StorageLevel.DISK_ONLY_2 = StorageLevel(True, False, False, False, 2)
StorageLevel.DISK_ONLY_3 = StorageLevel(True, False, False, False, 3)
# 缓存在内存中
StorageLevel.MEMORY_ONLY = StorageLevel(False, True, False, False)
StorageLevel.MEMORY_ONLY_2 = StorageLevel(False, True, False, False, 2)
# 缓存在内存中,如果内存不足就写入磁盘
StorageLevel.MEMORY_AND_DISK = StorageLevel(True, True, False, False)
StorageLevel.MEMORY_AND_DISK_2 = StorageLevel(True, True, False, False, 2)
# 缓存在堆外内存中:不是Executor内存
StorageLevel.OFF_HEAP = StorageLevel(True, True, True, False, 1)
# 缓存在内存中,如果内存不足就写入磁盘并且不经过序列化
StorageLevel.MEMORY_AND_DISK_DESER = StorageLevel(True, True, False, True)
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
input_rdd=sc.textFile("file:///root/pyspark_code_zimo/pyspark6/datas/wordcount/word.txt",minPartitions=3)
print("----------------------------------------")
# step2: 处理数据
rs_rdd = (input_rdd
.filter(lambda line: len(line.strip()) > 0)
.flatMap(lambda line: re.split("\\s+", line))
.map(lambda word: (word, 1))
.reduceByKey(lambda tmp, item: tmp + item)
)
# 对rs_rdd进行缓存
# rs_rdd.cache() # 只缓存到内存, 若内存不足则缓存失败
# rs_rdd.persist(StorageLevel.MEMORY_AND_DISK)
# 对rs_rdd进行持久化存储
# sc.setCheckpointDir("hdfs://node1:8020/zimo/wordcount/wordcount.txt") # 设置缓存位置
# rs_rdd.checkpoint()
print(rs_rdd.count())
print(rs_rdd.first())
print(rs_rdd.collect())
rs_rdd.unpersist(blocking=True)
time.sleep(10000)
# step3: 保存结果
10. Spark共享变量
10.1 广播变量(broadcast)
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
user_input_rdd=sc.textFile("file:///root/pyspark_code_zimo/pyspark6/datas/broadcast/users.tsv",minPartitions=2)
city_input_rdd=sc.textFile("file:///root/pyspark_code_zimo/pyspark6/datas/broadcast/city.csv",minPartitions=2)
# step2: 处理数据
city_etl_rdd=(
city_input_rdd.map(lambda line:line.strip().split(','))
)
city_dict=city_etl_rdd.collectAsMap()
broadcast_city=sc.broadcast(city_dict) # 定义成为一个广播变量
def join_city(line):
city_id=re.split("\\s+",line)[3]
# city_name=city_dict.get(city_id)
city_name = broadcast_city.value.get(city_id) # .value 从广播变量中获取它的值
return line + "\t" + city_name
user_rs_rdd=(
user_input_rdd.map(lambda line:join_city(line))
)
user_rs_rdd.foreach(lambda x:print(x))
broadcast_city.unpersist(blocking=True) # 释放广播变量
# step3: 保存结果
10.2 累加器(accumulator)
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
input_rdd=sc.textFile("file:///root/pyspark_code_zimo/pyspark6/datas/sogou/sogou.tsv",minPartitions=3)
print("----------------------------------------")
# step2: 处理数据
# 需求:统计出10点搜索的日志有多少条 计数功能
# sum1=0
sum2=sc.accumulator(0) # 定义一个累加器
def acc_count(line):
# global sum1
hour =re.split("\\s+", line)[0][0:2]
if hour=="10":
# sum1+=1
sum2.add(1) # 进行累加
return None
input_rdd.foreach(lambda line:acc_count(line))
# print(sum1) # 结果为 0
print(sum2.value) # 结果为 104872
# step3: 保存结果















 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









