






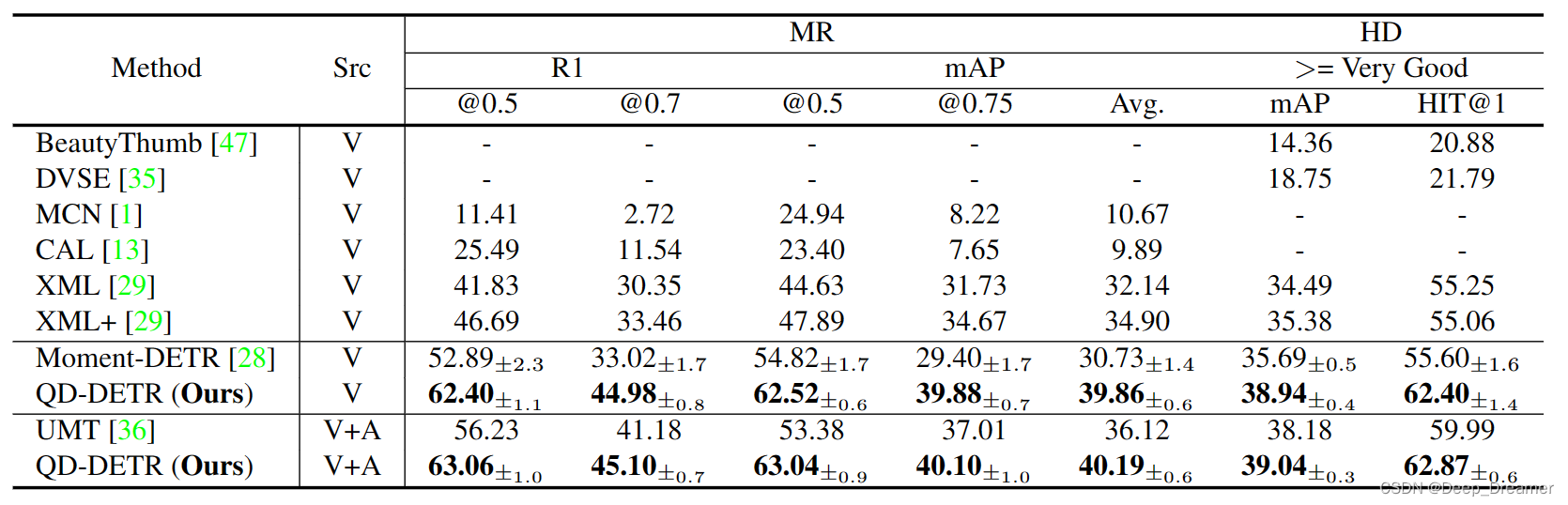
最近,随着对视频理解的需求急剧增加,视频时刻检索和高光检测(MR/HD)正成为人们关注的焦点。MR/HD的关键目标是定位时刻并估计对给定文本查询的剪辑一致性水平,即显著性得分。尽管最近基于transformer的模型带来了一些进步,但我们发现这些方法并不能充分利用给定查询的信息。例如,在预测时刻及其显著性时,有时会忽略文本查询和视频内容之间的相关性。为了解决这个问题,我们引入了查询相关DETR(QD-DETR),这是一种专为MR/HD量身定制的检测转换器。当我们观察到给定查询在transformer架构中的不重要作用时,我们的编码模块从跨注意力层开始,将文本查询的上下文显式地注入视频表示中。然后,为了增强模型利用查询信息的能力,我们对视频查询对进行操作,以产生不相关的对。这样的负面(不相关)视频查询对被训练以产生低显著性得分,这反过来又鼓励模型估计查询视频对之间的精确一致性。最后,我们提出了一个输入自适应显著性预测器,它自适应地定义了给定视频查询对的显著性得分标准。我们的大量研究验证了建立MR/HD的查询相关表示的重要性。具体而言,QD-DETR在QVHighlights、TVSum和Charades STA数据集上优于最先进的方法。
在描述时刻时,最受欢迎的查询类型之一是自然语言句子(文本)。虽然早期的方法使用卷积网络,但最近的方法表明,部署转换器架构的注意力机制更有效地将文本查询融合到视频表示中。例如,Moment DETR[28]引入了转换器架构,该架构通过修改检测转换器(DETR)来处理文本和视频令牌作为输入,UMT[36]提出了转换器架构以采用多模式源,例如视频和音频。此外,他们还利用了转换器解码器中的文本查询。尽管他们以开创性的架构在MR/HD领域取得了突破,但他们忽视了文本查询的作用。为了验证我们的说法,我们研究了Moment DETR[28]对MR/HD中文本查询的影响(图1)。给定具有相关正面查询和不相关负面查询的视频片段,我们观察到基线在估计每个视频片段的查询相关性得分(即显著性得分)时经常忽略给定的文本查询
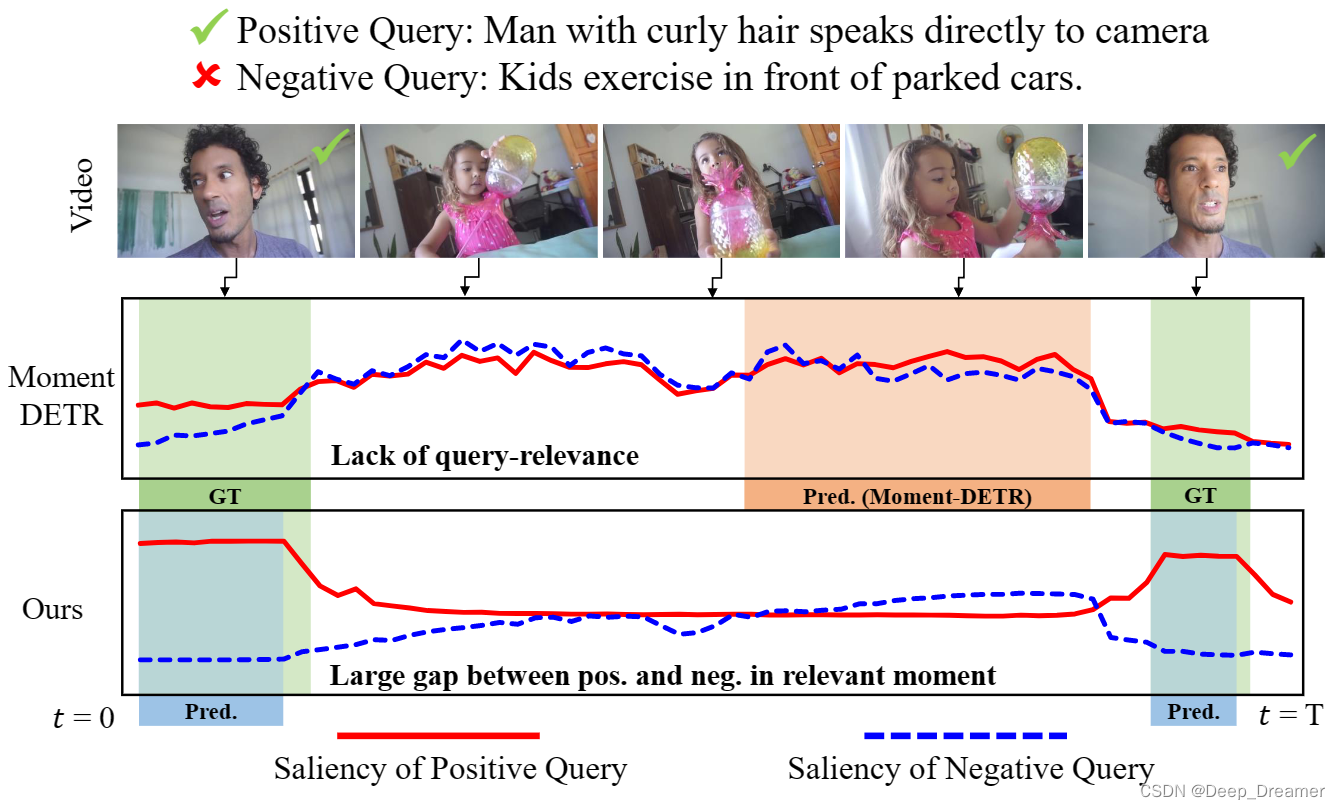
为此,我们提出了产生查询相关视频表示的查询相关DETR(QDDETR)。我们的重点是确保模型对每个片段的预测高度依赖于查询。首先,为了充分利用查询中的上下文信息,我们修改了transformer编码器,使其在第一层就配备了交叉注意层。通过插入视频作为查询,插入文本作为交叉关注层的关键字和值,我们的编码器在提取视频表示时加强了文本查询的参与。然后,为了不仅向视频特征中注入大量文本信息,而且使其得到充分利用,我们利用了通过混合原始对生成的负面视频查询对。具体来说,学习该模型以抑制这种负(不相关)对的显著性得分。我们的期望是文本查询在预测中的贡献增加,因为根据文本查询是否相关,视频有时需要产生高显著性分数,有时需要产生低显著性分数。最后,为了应用动态标准来标记每个实例的亮点,我们部署了一个显著性令牌来表示整个视频,并将其用作输入自适应显著性标准。将所有组件组合在一起,我们的QD-DETR通过集成源和查询模式来生成依赖于查询的视频表示。这进一步允许在变换器解码器中使用位置查询[34]。总的来说,与现有方法相比,我们的卓越性能验证了文本查询在MR/HD中的作用的重要性。
Query-Dependent DETR
时刻检索和高亮检测的共同目标是通过文本查询找到首选时刻。给定L个剪辑的视频和具有N个单词的文本查询,我们将它们的表示分别表示为由冻结视频和文本编码器提取的{v1,v2,…,vL}和{t1,t2,…,tN}。使用这些表示,主要目标是在视频中定位中心坐标mc和宽度σ,并对每个剪辑的高光分数(显著性分数){s1,s2,…,sL}进行排序。
时刻检索和高亮检测的共同目标是通过文本查询找到首选时刻。给定L个剪辑的视频和具有N个单词的文本查询,我们将它们的表示分别表示为由冻结视频和文本编码器提取的{v1,v2,…,vL}和{t1,t2,…,tN}。使用这些表示,主要目标是在视频中定位中心坐标mc和宽度σ,并对每个剪辑的高光分数(显著性分数){s1,s2,…,sL}进行排序。
将变换器[12,52]用于MR的一种简单方法是将矩量预测作为一组片段[28],或者根据片段预测生成矩[36]。为了利用多模态信息,例如视频和文本查询,他们要么简单地将特征连接在模态上,要么插入文本以形成对变换器解码器的时刻查询。然而,我们声称应该仔细考虑视频和文本查询之间的关系,而不是简单的串联,因为MR/HD要求每个视频剪辑都要通过文本查询进行有条件的评估
我们的整体架构如图2所示,遵循混凝土基线Moment DETR[28]的设计。给定从固定主干提取的视频和查询表示,QD-DETR首先使用交叉关注层将视频表示转换为依赖于查询的。为了进一步增强视频表示的查询意识,我们将不相关的视频查询对以低显著性纳入学习目标。然后,与转换器编码器-解码器架构一起,定义显著性令牌,当特定视频实例参与时,该显著性令牌变为自适应显著性预测器。
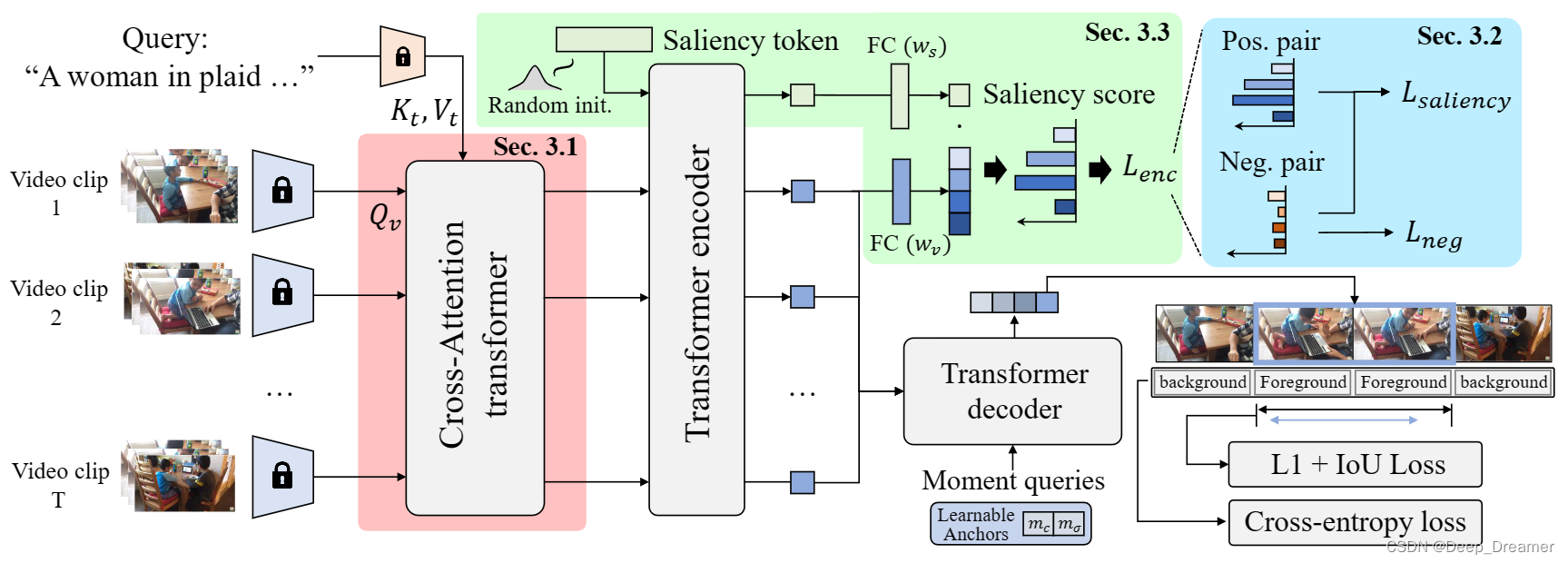
Cross-Attentive Transformer Encoder
在本小节中,我们使用斜体字母来表示交叉关注层的查询、键和值。用于MR/HD的编码器的关键目标是产生配备有关于查询相关性程度的信息的片段表示,因为这些特征直接用于检索查询匹配矩和预测片段显著性得分。然而,现有作品的编码过程可能无法确保对每个片段进行查询。例如,Moment DETR[28]天真地将视频与查询连接起来,以输入到自关注层,如果视频片段之间的高度相似性超过了文本查询的贡献,则这可能导致查询的作用不显著。另一方面,UMT[36]仅将文本查询用于变换器解码器中的时刻查询的合成,因此产生的视频表示与文本查询不相关联。
为了将文本上下文纳入每个视频片段表示,我们在编码器的第一层在源和查询模态之间部署了交叉关注层。这确保了查询的一致贡献,从而提取依赖于查询的视频表示。详细地说,对于交叉关注层的查询是通过将视频剪辑投影为Qv=[pq(v1),…,pq(vL)]来准备的,关键字和值是用查询文本特征计算的,因为Kt=[pk(t1),…,pk(tN)]和Vt=[pv(t1)…,pv(tN)]。pq(·),pk(·)和pv(·)是查询、关键字和值的投影层。然后,交叉关注层的操作如下:
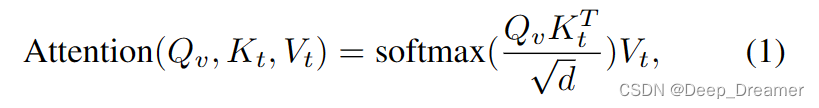
其中,d是投影键、值和查询的维度。由于softmax分数仅分布在查询元素上,因此视频剪辑用与文本相似性成比例的文本查询的加权和来表示。然后通过MLP投影注意力得分,并将其集成到原始视频表示中作为典型的变换器层。对于本文的其余部分,我们将依赖于查询的视频令牌,即交叉关注层的输出定义为X={x1v,x2v,…,xLv}。
Learning from Negative Relationship
虽然交叉关注层明确地融合了中间视频片段表示的视频和查询特征,以体系结构的方式参与查询信息,但我们认为,给定的视频-文本对缺乏多样性来学习一般关系。例如,单个视频中的许多连续剪辑通常共享相似的外观,并且与特定查询的相似性将不是高度可区分的,因此,文本查询可能不会对预测产生太大影响。
因此,我们考虑了受许多识别实践[20,31,32,40]启发的不相关视频对之间的关系,这些识别实践学习不同类别的判别特征。为了实现这样的关系,我们将给定的训练视频查询对定义为正对,并将来自不同对的视频和查询混合以构建负对。图3说明了在训练中增加这种负配对并将其与正配对一起使用的方法。当正对中的视频片段被训练以根据查询相关性产生分段显著性得分时,不相关的负视频查询对被强制具有最低显著性得分。形式上,用于抑制负对的显著性的损失函数xnegv表示如下:
![]()
其中S(·)是显著性得分预测因子。该训练方案还可以防止模型在不考虑查询相关性的情况下仅基于视频剪辑之间的相互关系来预测时刻和亮点,因为相同的视频实例应该根据给出的是肯定查询还是否定查询而被不同地预测。
Input-Adaptive Saliency Predictor
显著性预测器S(·)的简单实现将是堆叠一个或多个完全连接的层。然而,这种通用头部为每个视频查询对的显著性预测提供了相同的标准,忽略了视频和自然语言查询对的多样性。这违反了我们提取依赖查询的视频表示的关键思想。
因此,我们定义了要用作输入自适应显著性预测器的显著性令牌xs。简言之,显著性令牌是一个随机初始化的可学习向量,当被添加到编码视频令牌序列并通过变换器编码器投影时,该向量成为输入自适应预测器。
为了说明这一点,如图2所示。我们首先将显著性令牌与依赖于查询的视频令牌X连接起来。我们将这些令牌处理到转换器编码器,转换器编码器使显著性令牌用依赖于输入的上下文重新组织。因此,显著性和视频令牌分别由具有权重ws和wv的对应的单个完全连接层投影,其中它们的scaledot乘积成为显著性得分。形式上,显著性得分S(xi v)计算如下:
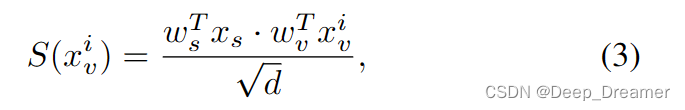
其中d是投影的令牌的通道维度。
Decoder and Objectives
变压器解码器。最近,对查询在检测转换器中的作用的理解受到了关注[34,39]。验证了利用位置信息设计查询不仅有助于加速训练,而且有助于提高准确性。然而,很难将这些研究直接用于处理多模态数据(例如,MR/HD)的任务,因为多模态数据通常具有不同的位置定义;位置可以理解为视频中的时间和文本中的单词顺序。
相反,我们的架构设计消除了将文本查询馈送到解码器的需要,因为查询信息已经被纳入视频表示中。为此,我们修改2D动态锚框[34]以表示视频中的1D时刻。具体来说,我们利用矩的中心坐标mc和持续时间mσ来设计查询。与之前在图像域中的方法类似,我们将中心坐标周围的特征集中起来,并用持续时间调制交叉注意力图。然后,对坐标和持续时间进行分层修正。
损失函数。QD-DETR的培训目标分别包括MR/HD的损失函数。首先,从基线开始采用MR的目标函数[28],其中关键焦点是定位所需的力矩。力矩恢复损失Lmr测量GT力矩和预测对应力矩之间的差异。它由L1损失和先前工作[44]中的广义IoU损失LgIoU(·)组成,并进行了微小修改以定位时间矩。
此外,交叉熵损失用于通过LCE=−Py∈y y log(Plot y)将预测的矩分类为前景和背景,其中{fg,bg}⊂y。因此,Lmr的定义如下:
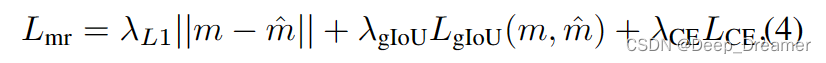
其中m和Plot m是地面实况矩及其对应的预测,包含中心坐标mc和持续时间mσ。此外,λ*是用于平衡损失的超参数
HD的损失函数用于估计显著性得分。它包括两个组成部分;边际排名损失Lmarginan和秩意识对比损失Lcont。在[28]之后,裕度秩损失通过两对高秩和低秩剪辑进行操作。具体地说,与GT时刻内的低秩剪辑和GT时刻外的负剪辑相比,确保高秩剪辑保持更高的显著性得分。简而言之,Lmargin定义为:
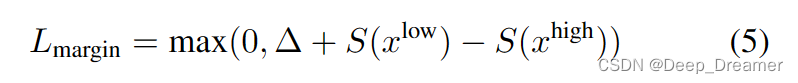
其中∆是裕度,S(·)是显著性得分估计器,xhigh和xlow分别是来自两对高阶和低阶剪辑的视频标记。除了仅间接指导显著性预测器的边缘损失外,我们还使用秩感知对比损失[21]来学习具有对比损失的精确分割的显著性水平。给定最大秩值R,小批量中的每个剪辑的显著性得分都低于R。然后,我们对批量进行R次迭代,每次都利用显著性得分高于迭代指数(R∈{0,1,…,R−1})的样本来构建正集Xposr。具有比迭代索引更低秩的样本被包括在负集合Xnegr中。
秩感知对比损失Lcont被定义为:
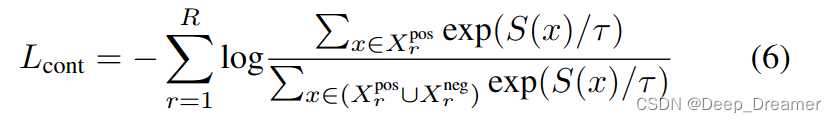
其中τ是温度标度参数。请注意,Xnegro还包括第3.2节中定义的负对xnegv中的所有剪辑。最后,对于边际损失和秩感知对比损失,Lhland总损失函数Ltotal定义如下:
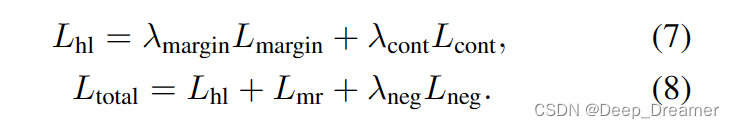
正如本文所阐述的,我们的目的是强调文本查询在检索相关时刻并估计其与给定文本查询的一致性水平方面的作用。同样,所提出的组件期望给定的查询能够维护有意义的上下文。如果没有,并且提供了嘈杂的文本查询,即不匹配或不相关的基本事实文本,则训练可能不会像报道的那样有效。
结论尽管transformer体系结构的出现对MR/HD来说是强大的,但在这种体系结构中,文本查询的作用还缺乏研究。因此,我们重点研究了文本查询的作用。由于我们发现文本信息在表达视频表示时没有得到充分利用,我们设计了交叉注意变换编码器,并提出了一种负对训练方案。交叉注意编码器在提取视频表示时确保了查询的贡献,负对训练通过防止在不考虑查询的情况下解决问题来强制模型学习查询和视频之间的关系。最后,为了保持依赖于查询的视频表示的多样性,我们将显著性令牌定义为输入自适应显著性预测器。大量实验验证了QD-DETR具有优异性能的强度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









