






1 协程简介
1.1 发展历史
协程(Coroutine)的概念最早可以追溯到 20 世纪 60 年代,为了解决软硬件限制导致的 COBOL 无法实现 one-pass 编译问题,Melvin Conway 提出了一种协同式调度解决方案:其在编译器设计中将词法分析与语法分析合作运行,而不像其他编译器那样互相独立运行,两个模块来回交织,两个模块都具备让出和恢复的能力
但在1968 年,Dijkstra 发表论文 Go To Statement Considered Harmful ,结构化编程的理念深入人心,自顶向下的程序设计思想成为主流,协程跳来跳去的执行行为类似 goto 语句,违背自顶向下的设计思想,同时,抢占式调度的线程因其在资源管理、易用性、系统级支持以及对当时硬件环境的适应性等方面的优势,成为了那个时代并发处理的主流选择
随着现代网络技术的发展和高并发要求,抢占式调度在处理 IO 密集型任务时的低效成为软肋,自 2003 年起,为了更好的利用 CPU 资源,各类高级语言开始拥抱协程
1.2 线程实现模型
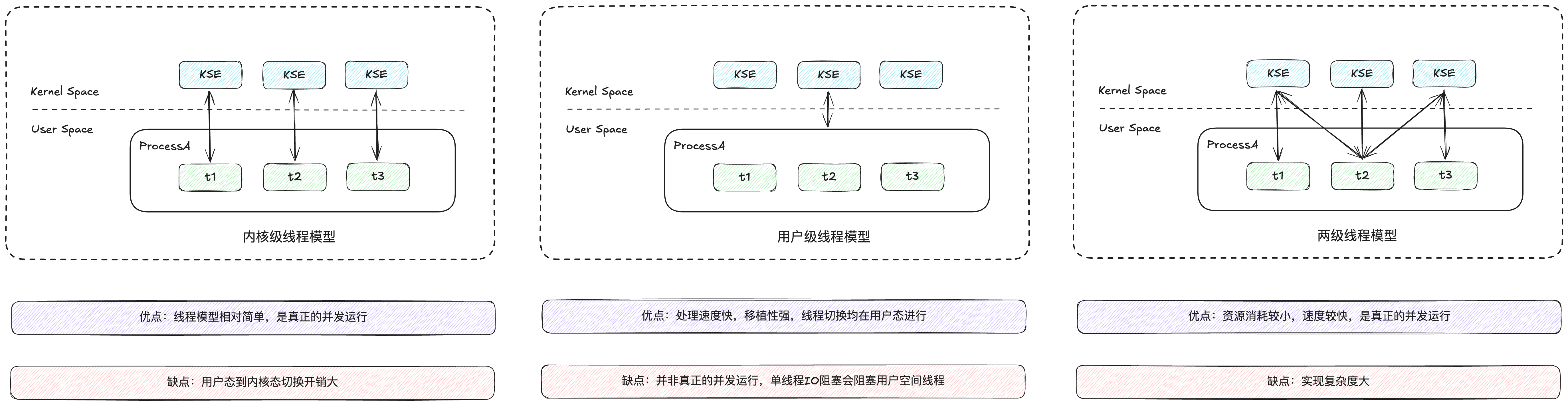
协程的实现是基于线程的实现模型,线程的实现模型分为三种:
- 内核级线程模型(UT : KSE = 1 : 1,eg:JVM)
- 用户级线程模型(UT : KSE = N : 1,eg: Java 的 Quasar,Python 的 Gevent,Js 的 Promise)
- 两级线程模型(也称混合型线程模型,UT : KSE = N : M,eg: Go 的 Goroutine )
Java 的 Quasar 的原理:通过字节码插桩和抛出异常的方式实现协程的挂起与恢复,从而允许在单线程中高效地调度多个轻量级的执行单元(Fiber),避免回调地狱并最大化 CPU 资源利用,ajdk 的实现原理与之类似
他们之间最大的差异在于用户线程(UT)与内核调度实体(KSE)之间的对应关系上
1.3 主要特点
- 轻量级,体现在占用资源更小,线程为 MB,协程为 KB
- 用户级,体现在协程的切换在用户态完成,减少了内核态与用户态切换的开销
2 GMP模型
2.1 基本概念
golang 协程实现原理是 GMP,三个主要元素:
-
G:Groutine,协程,用户轻量级线程,每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、状态以及任务函数,可重用。当 Goroutine 被调离 CPU 时,调度器代码负责把 CPU 寄存器的值保存在 G 对象的成员变量之中,当 Goroutine 被调度起来运行时,调度器代码又负责把 G 对象的成员变量所保存的寄存器的值恢复到 CPU 的寄存器,G 并非执行体,每个 G 需要绑定到 P 才能被调度执行
-
M:Machine,OS 线程抽象,代表着真正执行计算的资源,由操作系统的调度器调度和管理。M 结构体对象除了记录着工作线程的诸如栈的起止位置、当前正在执行的 Goroutine 以及是否空闲等等状态信息之外,还通过指针维持着与 P 结构体的实例对象之间的绑定关系,在绑定有效的 P 后,进入 schedule 循环,而 schedule 循环的机制大致是从 Global 队列、P 的 Local 队列以及 wait 队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复,M 并不保留 G 状态,这是 G 可以跨 M 调度的基础
-
P:Processor,调度逻辑处理器,G 实际上是由 M 通过 P 来进行调度运行的,对 G 来说,P 相当于 CPU 核,G 只有绑定到 P (在 P 的 local runq 中)才能被调度。对 M 来说,P 提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等
其中 G 细分为以下几类:
- 主协程:用来执行用户main函数的协程
- 主协程创建的协程:也是P调度的主要成员
- G0:每个 M 都有一个 G0 协程,是 runtime 的一部分,跟 M 绑定,主要用来执行调度逻辑的代码,不能被抢占也不会被调度(普通 G 也可以执行 runtime_procPin 禁止抢占),G0 的栈是系统分配的,比普通的 G 栈(2KB)要大,不能扩容也不能缩容
- sysmon:sysmon 是 runtime 的一部分,直接运行在 M 不需要 P,主要做一些检查工作:检查死锁、检查计时器获取下一个要被触发的计时任务、检查是否有 ready 的网络调用以恢复用户 G 的工作、检查一个 G 是否运行时间太长进行抢占式调度
其中 M 细分为以下几类:
- 普通 M:用来与 P 绑定执行 G 中任务
- m0:Go 程序是一个进程,进程都有一个主线程,m0 就是 Go 程序的主线程,通过一个与其绑定的 G0 来执行 runtime 启动加载代码;一个 Go 程序只有一个 m0
- 运行 sysmon 的 M:主要用来运行 sysmon 协程
2.2 设计思想
-
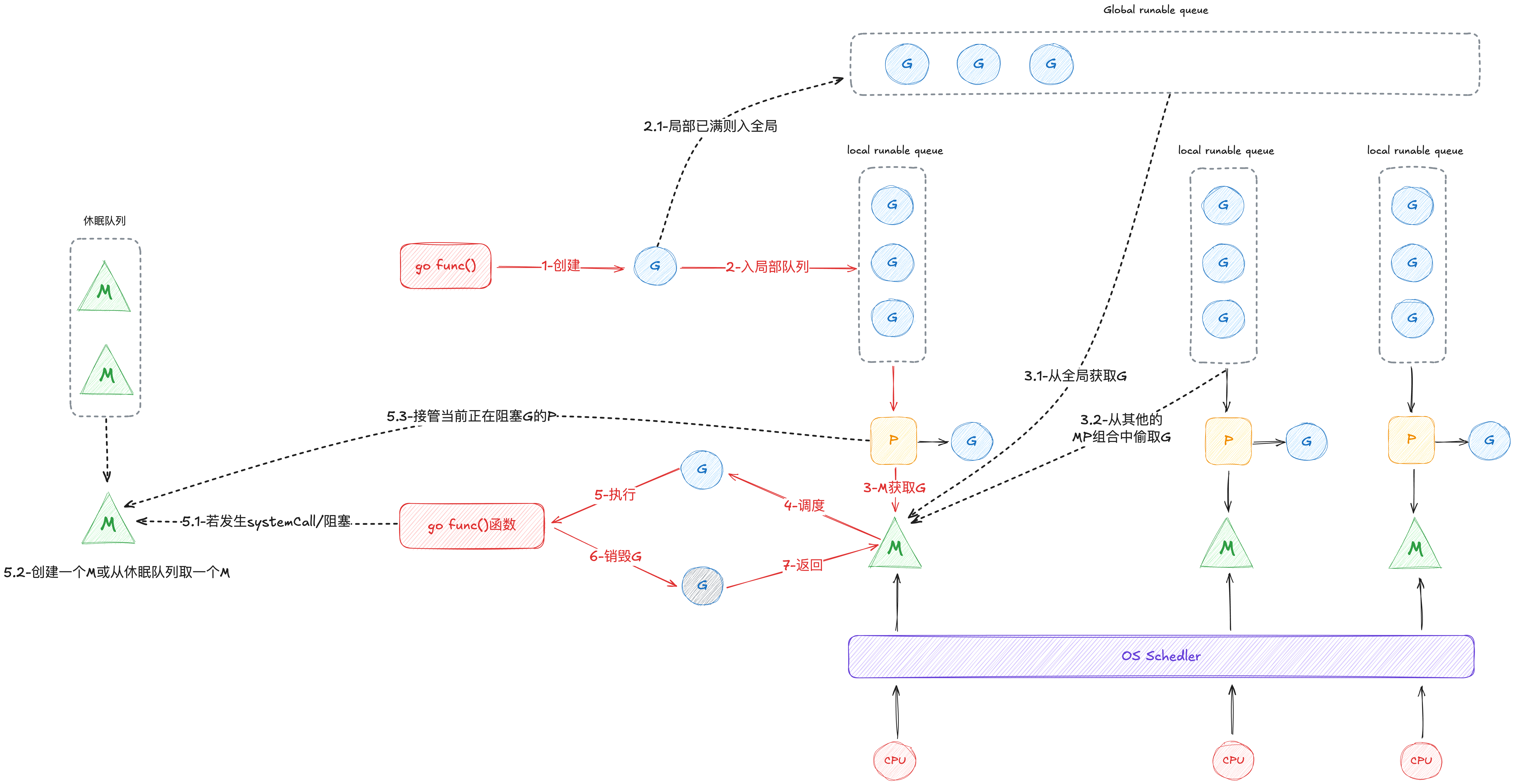
中间态思想:没有什么是加一层中间层不能解决的,传统的线程模型可以理解为 GM 模型(这里的 G 引申为用户的并发任务),为了解决传统 GM 模型的切换开销大(内核态到用户态),并发开销大(线程为 MB 级别,并发数量受内存限制)的问题,Go 语言引入了 一层 Processor 来作为两者的中间态,Processor 的设计进一步细化了并发时分复用的调度粒度,从 MB 到 KB,实现轻量,将内核态用户态的互相切换完整放在用户态执行,实现用户级快速切换
-
局部性原理:Processor 维护一个局部 Goroutine 可运行 G 队列,工作线程优先使用自己的局部运行队列,只有必要时才会去访问全局运行队列,这可以大大减少锁冲突,提高工作线程的并发性,并且可以良好的运用程序的局部性原理
-
工作窃取(work stealing机制):work stealing 机制是一种用于提高并发性能的策略,其允许一个处理器(P)在没有可运行的 Goroutine 时,从其他处理器的本地队列中窃取(steal)一些 Goroutine 来执行。这种机制有助于实现负载均衡,避免某些处理器过载而其他处理器空闲的情况
-
动态关联(Hand off 传递):当一个线程因为系统调用或其他原因阻塞时,GMP 不会让绑定的处理器(P)空闲,而是将当前的 P 传递给另一个线程,以便新线程可以继续执行 P 上的 Goroutine。 这有助于减少因线程阻塞导致的上下文切换开销,并保持程序的并发性
2.3 调度模型
根据源码可以整理出如下调度模型,其中体现了上文的核心四条设计思想,详细内容可见源码走读
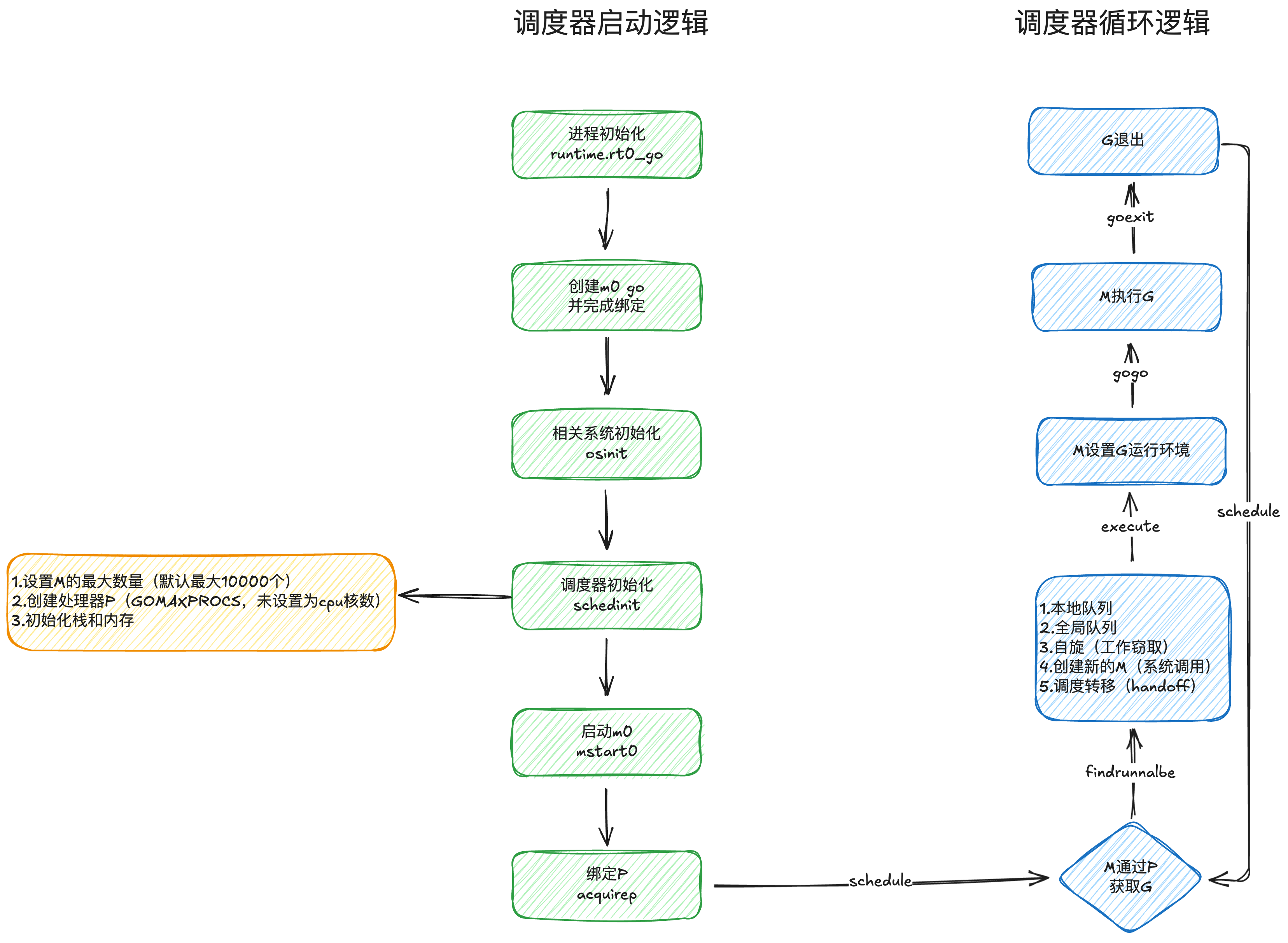
2.4 生命周期
根据源码可以整理出如下调度器的生命周期是,主要分为启动和循环逻辑,其中也体现了调度模型中的一些关键步骤比如 M 绑定 P,M 为 G 设置运行环境,详细内容可见源码走读
2.5 调度时机
-
主动调度:协程通过 runtime.Goshed 方法主动让渡自己的执行权利,之后这个协程会被放到全局队列中,等待后续被执行
-
被动调度:协程在休眠、channel 通道阻塞、网络 I/O 堵塞、执行垃圾回收时被暂停,被动式让渡自己的执行权利。大部分场景都是被动调度,这是 Go 高性能的一个原因,让 M 永远不停歇,不处于等待的协程让出 CPU 资源执行其他任务
-
抢占式调度:sysmon 协程上的调度,当发现 G 处于系统调用(如调用网络 io )超过 20 微秒或者 G 运行时间过长(超过10ms),会抢占 G 的执行 CPU 资源,让渡给其他协程,防止其他协程没有执行的机会
3 GMP源码
golang源码结构
- runtime/amd_64.s:涉及到进程启动以及对 CPU 执行指令进行控制的汇编代码,进程的初始化部分也在这里面
- runtime/runtime2.go:重要数据结构的定义,比如 g、m、p 以及涉及到接口、defer、panic、map、slice 等核心类型
- runtime/proc.go:核心方法的实现,涉及 gmp 调度等核心代码在这里
runtime:golang 的 runtime 是与用户代码一起打包在一个可执行文件中,是程序的一部分,在 golang 语言中的关键字编译时会变成 runtime 中的函数调用,例如 go 关键字对应 runtime 中的 newproc 函数
3.1 基本结构
基本结构是源码解读的切入口,其中每一个字段都对应着状态和逻辑,主要的结构体设计解读如下
3.1.1 g struct
g struct 中汇集了一个 Goroutine 在运行时所需的各种信息,包括其栈状态、执行状态、睡眠与阻塞信息,以及与系统资源(如线程、信号和调度)相关的多种状态和统计数据
// src/runtime/runtime2.go
type g struct {
// 记录协程栈的栈顶和栈底位置
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
// 内部 panic、defer
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
// 当前与 goroutine 绑定的 m
m *m // current m; offset known to arm liblink
// 保存与goroutine运行位置相关的寄存器和指针,如rsp、rbp、rpc等寄存器
sched gobuf
syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
syscallbp uintptr // if status==Gsyscall, syscallbp = sched.bp to use in fpTraceback
// 预期的栈顶指针,用于 traceback(回溯)
stktopsp uintptr // expected sp at top of stack, to check in traceback
// 用于做参数传递,睡眠时其他goroutine可以设置param,唤醒时该g可以读取这些param
param unsafe.Pointer
// 记录当前 goroutine 的状态
atomicstatus atomic.Uint32
// 栈锁,用于保护栈的扫描
stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
// goroutine的唯一id
goid uint64
// 与调度相关的链表
schedlink guintptr
// 记录此 goroutine 阻塞的时间
waitsince int64
//如果状态为 Gwaiting,则记录阻塞原因
waitreason waitReason
// 标记是否可以被抢占
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule
preemptShrink bool // shrink stack at synchronous safe point
// 指示 goroutine 是否在异步安全点停止
asyncSafePoint bool
// 在访问到未处理的错误地址时,会改为 panic 而不是崩溃
paniconfault bool
// 表示该 goroutine 的垃圾回收扫描工作是否已经完成
gcscandone bool
// 尽量不在垃圾回收期间分割栈
throwsplit bool
// 指示存在指向该 goroutine 栈中未上锁通道的指针
activeStackChans bool
// 指示 goroutine 即将停在通道的发送或接收上
parkingOnChan atomic.Bool
// 指示 goroutine 是否处于标记协助状态
inMarkAssist bool
// 用于协程切换的参数
coroexit bool
// 指示是否忽略竞争检测事件
raceignore int8
// 指示是否禁用来自 C 的回调
nocgocallback bool
// 与调度延迟统计相关的字段
tracking bool // whether we're tracking this G for sched latency statistics
trackingSeq uint8 // used to decide whether to track this G
trackingStamp int64 // timestamp of when the G last started being tracked
runnableTime int64 // the amount of time spent runnable, cleared when running, only used when tracking
// 锁定的 M(操作系统线程)指针
lockedm muintptr
// 与信号处理和写入缓冲区相关的字段
sig uint32
// 用于存储写缓冲区的数据
writebuf []byte
// 与信号相关的错误代码
sigcode0 uintptr
sigcode1 uintptr
// 出现信号的程序计数器位置
sigpc uintptr
// 创建此 goroutine 的父 goroutine 的唯一标识符
parentGoid uint64
// 创建该 goroutine 的语句的指令地址
gopc uintptr
// 记录创建该 goroutine 的祖先信息,通常用于调试
ancestors *[]ancestorInfo
// 记录 goroutine 函数的程序计数器
startpc uintptr
// 与竞态检测相关的上下文
racectx uintptr
// goroutine 等待某个操作的 sudog 结构
waiting *sudog
// cgo 追踪信息的上下文
cgoCtxt []uintptr
// 用于性能分析的标签
labels unsafe.Pointer
// 缓存的定时器,用于实现 time.Sleep 功能
timer *timer
// 记录睡眠结束的时间
sleepWhen int64
// 记录 goroutine 是否正在参与 select 操作以及是否有人赢得条件
selectDone atomic.Uint32
// 记录当前 goroutine 的堆栈状态,以支持性能分析
goroutineProfiled goroutineProfileStateHolder
// 协程切换过程中的参数
coroarg *coro
// 与当前 goroutine 跟踪状态相关的字段
trace gTraceState
// 用于记录垃圾回收的助力字节数,当其为正时表示 goroutine 在分配内存时可不必执行垃圾回收;为负时则要求执行垃圾回收
gcAssistBytes int64
}
3.1.2 m struct
m struct 描述了 Go 运行时中每个操作系统线程(M)的状态和相关信息。包含指向正在运行的 goroutine (g) 的引用、系统调用相关的字段、堆栈信息、信号处理的指针,以及与内存分配、锁管理和性能分析相关的各种标志和计数器
// src/runtime/runtime2.go
type m struct {
// 每个m都有一个对应的g0线程,用来执行调度代码,当需要执行用户代码的时候,g0会与用户goroutine发生协程栈切换
g0 *g
// 用于传递给 morestack 函数的 gobuf 参数,这个函数用于处理栈的增长
morebuf gobuf
// 对于 ARM 架构,做除法和求余操作的分母,主要与底层链接有关
divmod uint32
_ uint32 // align next field to 8 bytes
// 供调试使用,存储当前操作系统的进程 ID
procid uint64
// 指向进行信号处理的 goroutine,处理操作系统信号
gsignal *g
// Go 分配的信号处理栈,用于处理 C 代码的信号
goSigStack gsignalStack
// 保存的信号掩码,用于保存当前线程阻塞的信号
sigmask sigset
// tls作为线程的本地存储
// 其中可以在任意时刻获取绑定到当前线程上的协程g、结构体m、逻辑处理器p、特殊协程g0等信息
tls [tlsSlots]uintptr
// 启动 m 的函数
mstartfn func()
// 指向正在运行的 goroutine 对象
curg *g
// 在处理致命信号时运行的 Goroutine 的引用
caughtsig guintptr
// 当前执行 Go 代码时附加的 P(一个 Go 运行时的执行上下文)
p puintptr
// 用于调度的下一个 P 指针
nextp puintptr
// 在执行系统调用前附加的 P
oldp puintptr
// 当前 M 的唯一标识符
id int64
// 表示当前是否正在执行 malloc 操作的标志
mallocing int32
// 抛出异常时的类型
throwing throwType
// 与禁止抢占相关的字段,如果该字段不等于空字符串,要保持 curg 一直在这个 m 上运行
preemptoff string
// 当前持有的锁的数量
locks int32
// 表示当前 M 是否正在终止
dying int32
// 配置的性能分析采样频率
profilehz int32
// 标识当前 m 是否正在处于自己找工作的自旋状态
spinning bool
// 当前线程是否因等待操作而被阻塞
blocked bool
// 表示 C 线程是否调用了 sigaltstack
newSigstack bool
// 记录打印操作的锁状态
printlock int8
// 当前线程是否在执行 cgo 调用
incgo bool
// 指示此 m 是否为额外的线程
isextra bool
// 指示是否在执行 C 代码的额外线程
isExtraInC bool
// 指示是否在信号处理器中的额外线程
isExtraInSig bool
// 记录是否可以安全地释放 g0 并删除该 m
freeWait atomic.Uint32
// 是否需要额外的 m
needextram bool
// 用于追踪错误的状态
traceback uint8
// 总共进行的 cgo 调用次数
ncgocall uint64
// 当前进行中的 cgo 调用数量
ncgo int32
// 如果非零,表示 cgo 调用正在临时使用
cgoCallersUse atomic.Uint32
// 当在 cgo 调用中崩溃时用于追踪的堆栈信息
cgoCallers *cgoCallers
// 没有 goroutine 需要运行时,工作线程睡眠在这个 park 上
park note
// 指向全局的所有线程链表
alllink *m
// 指向调度链表的指针
schedlink muintptr
// 指向锁定的 goroutine 的指针
lockedg guintptr
// 用于存储创建当前线程的堆栈信息
createstack [32]uintptr
// 用于跟踪 LockOSThread
lockedExt uint32 // tracking for external LockOSThread
lockedInt uint32 // tracking for internal lockOSThread
// 下一个等待锁的线程
nextwaitm muintptr
// 与锁竞争有关的性能分析信息
mLockProfile mLockProfile
// 用于存储内存、块或互斥锁的堆栈跟踪信息
profStack []uintptr
// 在 gopark 中将参数传递给 park_m 的函数指针
waitunlockf func(*g, unsafe.Pointer) bool
// 等待锁的指针
waitlock unsafe.Pointer
// 跟踪跳过的次数
waitTraceSkip int
// 阻塞原因的枚举类型
waitTraceBlockReason traceBlockReason
// 系统调用的计时器
syscalltick uint32
// 用于调度空闲线程的链表链接
freelink *m
// 用于维护线程分析状态的信息
trace mTraceState
// 用于跟踪库调用的状态信息,方便进行性能分析
libcall libcall
libcallpc uintptr // for cpu profiler
libcallsp uintptr
libcallg guintptr
// 存储 Windows 系统调用的参数
winsyscall winlibcall
// 用于 VDSO 调用的堆栈指针和程序计数器,用于追踪和调试
vdsoSP uintptr // SP for traceback while in VDSO call (0 if not in call)
vdsoPC uintptr // PC for traceback while in VDSO call
// 完成的抢占信号的计数,用于检测抢占请求的处理情况
preemptGen atomic.Uint32
// 标记当前是否有待处理的抢占信号
signalPending atomic.Uint32
// 用于缓存程序计数器值的查找
pcvalueCache pcvalueCache
// 用于缓存程序计数器值的高速缓存
dlogPerM
// 操作系统特定的上下文信息
mOS
// 用于高效随机数生成的 ChaCha8 状态
chacha8 chacha8rand.State
// 存储用来生成随机数的种子
cheaprand uint64
// 存储当前 M 持有的锁的信息,用于锁的排序和管理
locksHeldLen int
// 维护一个数组,用于存储当前 m 持有的锁的信息(最多可持有 10 个锁)
locksHeld [10]heldLockInfo
}
3.1.3 p struct
p struct 是 Go 语言中的一个核心数据结构,代表了一个处理器优先级的执行上下文。它包含多个字段,分别用于管理处理器的状态、调度信息、内存分配、系统调用计数、工作队列、延迟调用、GC(垃圾回收)相关操作、以及性能监测
// src/runtime/runtime2.go
type p struct {
// 全局变量allp中的索引位置
id int32
// p的状态标识 one of pidle/prunning/...
status uint32
// 指向下一个处理器的指针,用于链式管理多个处理器
link puintptr
// 计数和性能监测相关字段
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
// 与该处理器关联的 M(操作系统线程)的指针,如果处理器处于闲置状态,则为 nil
m muintptr
// 用于分配微小对象和小对象的一个块的缓存空间,里面有各种不同等级的span
mcache *mcache
// 页面缓存,一个 chunk 大小(512kb)的内存空间,用来对堆上内存分配的缓存优化达到无锁访问的目的
pcache pageCache
// 与数据竞争检测相关的上下文信息
raceprocctx uintptr
// 可用的延迟(defer)结构的池,优化 defer 的使用
deferpool []*_defer
deferpoolbuf [32]*_defer
// 可以分配给g的id的缓存,每次会一次性申请16个
goidcache uint64
goidcacheend uint64
// 本地可运行的G队列的头部和尾部,达到无锁访问
runqhead uint32
runqtail uint32
// 存储可运行 goroutine 的数组,是一个使用数组实现的循环队列
runq [256]guintptr
// 指向一个即将运行的 goroutine 的指针,如果有时间片剩余,将优先调度它
runnext guintptr
// 存储已完成的 goroutine(状态为 Gdead)的结构体,供后续重用
gFree struct {
gList
n int32
}
// 用于管理 syscall 相关的结构体的缓存
sudogcache []*sudog
sudogbuf [128]*sudog
// 从堆中缓存 mspan 对象,用于优化内存分配
mspancache struct {
len int
buf [128]*mspan
}
// 单个 pinner 对象的缓存,减少重复创建时的内存分配
pinnerCache *pinner
// 跟踪状态,用于调试和分析程序
trace pTraceState
// 每个处理器的持久化内存分配器,减少锁竞争
palloc persistentAlloc // per-P to avoid mutex
// GC 性能检测仪字段
gcAssistTime int64 // Nanoseconds in assistAlloc
gcFractionalMarkTime int64 // Nanoseconds in fractional mark worker (atomic)
limiterEvent limiterEvent // limiterEvent tracks events for the GC CPU limiter
// 标记工作者的运行模式,用于协调 GC 相关的执行
gcMarkWorkerMode gcMarkWorkerMode
// 上一个标记工作者开始的时间戳
gcMarkWorkerStartTime int64
// 此处理器的 GC 工作缓冲区缓存,管理内存工作
gcw gcWork
// 此处理器的 GC 写入屏障缓冲区
wbBuf wbBuf
// 指示在下一个安全点是否运行 sched.safePointFn
runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point
// 当前处理器是否正在写入统计信息的计数器
statsSeq atomic.Uint32
// 定时器堆,用于管理定时操作
timers timers
// 记录活跃 goroutine 占用的最大栈空间
maxStackScanDelta int64
// 记录此处理器上扫描的 goroutine 栈的信息
scannedStackSize uint64 // stack size of goroutines scanned by this P
scannedStacks uint64 // number of goroutines scanned by this P
// 用于处理抢占
preempt bool
// 最近一次进入 GC 停止状态的时间戳
gcStopTime int64
}
2.2 调度启动
2.2.1 rt0_go
调度器的初始化和启动调度循环是在进程初始化是处理的,Go 进程的启动是通过汇编代码进行的,入口函数在 asm_amd64.s 中的 runtime.rt0_go
// src/runtime/asm_amd64.s
// m0 和 g0 互相绑定
get_tls(BX)
LEAQ runtime·g0(SB), CX
MOVQ CX, g(BX)
LEAQ runtime·m0(SB), AX
// save m->g0 = g0
MOVQ CX, m_g0(AX)
// save m0 to g0->m
MOVQ AX, g_m(CX)
// 检测初始化过程中的一些条件,比如参数的合法性等
CALL runtime·check(SB)
// 初始化 Go 运行时的参数处理
CALL runtime·args(SB)
// 进行操作系统相关的初始化,这个函数不同的操作系统有不同的实现
CALL runtime·osinit(SB)
// 初始化 Go 的调度器,为 Goroutine 的管理做好准备
CALL runtime·schedinit(SB)
// 创建主协程,主 Goroutine 创建完成后被加入到 p 的运行队列中,等待调度
MOVQ $runtime·mainPC(SB), AX
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// 启动 Machine,开始调度 Goroutine
// 在 g0 上启动调用 runtime.mstart 启动调度循环
// 首先可以被调度执行的就是主 Goroutine
// 然后主协程获得运行的 cpu 则执行 runtime.main 进而执行到用户代码的 main 函数
CALL runtime·mstart(SB)
2.2.2 schedt
在 runtime 中全局变量 sched 代表全局调度器,数据结构为 schedt 结构体,保存了调度器的状态信息、全局可运行 G 队列
// src/runtime/runtime2.go
type schedt struct {
// 用来为goroutine生成唯一id,需要以原子访问形式进行访问
goidgen atomic.Uint64
// 上一次网络轮询的时间。如果当前正在轮询,则值为 0
lastpoll atomic.Int64
// 当前轮询睡眠到的时间
pollUntil atomic.Int64
// 用于保护调度器内部数据结构的互斥锁,以确保并发安全
lock mutex
// 等待工作的空闲 m(机器)的指针链表
midle muintptr
// 空闲的工作线程数量
nmidle int32
// 空闲的且被 lock 的 m 的数量
nmidlelocked int32
// m 的创建计数和下一个 M ID
mnext int64
// 允许的最大 m 数量,超出后将导致程序中止
maxmcount int32
// 不计算在死锁中的系统 m 的数量
nmsys int32
// 释放的 m 的累计数量
nmfreed int64
// 当前系统 goroutine 的数量
ngsys atomic.Int32
// 等待工作的空闲 p(处理器)的指针链表
pidle puintptr
// 当前空闲 p 的数量
npidle atomic.Int32
// 正在进行自旋的 m 的数量
nmspinning atomic.Int32
// 表示是否需要自旋的原子布尔值;更改时需持有调度锁
needspinning atomic.Uint32
// 全局可运行队列,存储可以运行的 goroutine
runq gQueue
// 可运行队列的大小
runqsize int32
// 控制调度的结构体,允许用户禁用用户 goroutines 的调度
disable struct {
user bool
runnable gQueue // pending runnable Gs
n int32 // length of runnable
}
// 存放死亡 goroutine 的全局缓存,便于重用
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
// 用于保护 sudog(用于同步的结构体)的互斥锁
sudoglock mutex
// sudog 的中央缓存
sudogcache *sudog
// 用于保护 defer 结构体的互斥锁
deferlock mutex
// defer 的中央池,管理可用的 defer 结构体
deferpool *_defer
// 等待释放的 m 的链表,当其 m.exited 被设置时释放
freem *m
// 指示 GC 是否正在等待运行
gcwaiting atomic.Bool
// 用于停止调度的控制机制
stopwait int32
stopnote note
// 系统监视器是否在等待的原子布尔值
sysmonwait atomic.Bool
// 用于系统监视器的通知信号
sysmonnote note
// 在每次 GC 的安全点调用的函数
safePointFn func(*p)
// 记录安全点的等待时间
safePointWait int32
safePointNote note
// CPU Profiling 的速率
profilehz int32
// 最近一次改变 goroutine 数量(gomaxprocs)的时间
procresizetime int64
// 记录上次改变 gomaxprocs 时的总时间
totaltime int64
// 保护系统监视器操作的互斥锁
sysmonlock mutex
// 调度延迟的分布数据,表示 goroutine 在可运行状态的总时间
timeToRun timeHistogram
// 处理器空闲状态下的累计 CPU 时间。每次 GC 周期重置
idleTime atomic.Int64
// 由于等待同步原语(如互斥锁)而导致的累计等待时间
totalMutexWaitTime atomic.Int64
// 定义 STW 延迟的分布,分别用于 GC 相关和其他类型的 STW
stwStoppingTimeGC timeHistogram
stwStoppingTimeOther timeHistogram
// 定义 STW 的总延迟,是 stwStoppingTimeGC/Other 的超集
stwTotalTimeGC timeHistogram
stwTotalTimeOther timeHistogram
// goroutine 在等待运行时锁的累计等待时间,包括所有已退出的 M 的锁等待时间
totalRuntimeLockWaitTime atomic.Int64
}
2.2.3 schedinit
// src/runtime/proc.go
func schedinit() {
// 初始化调度相关的各种锁,确保多线程环境的安全性
lockInit(&sched.lock, lockRankSched)
lockInit(&sched.sysmonlock, lockRankSysmon)
lockInit(&sched.deferlock, lockRankDefer)
lockInit(&sched.sudoglock, lockRankSudog)
lockInit(&deadlock, lockRankDeadlock)
lockInit(&paniclk, lockRankPanic)
lockInit(&allglock, lockRankAllg)
lockInit(&allpLock, lockRankAllp)
lockInit(&reflectOffs.lock, lockRankReflectOffs)
lockInit(&finlock, lockRankFin)
lockInit(&cpuprof.lock, lockRankCpuprof)
allocmLock.init(lockRankAllocmR, lockRankAllocmRInternal, lockRankAllocmW)
execLock.init(lockRankExecR, lockRankExecRInternal, lockRankExecW)
traceLockInit()
lockInit(&memstats.heapStats.noPLock, lockRankLeafRank)
// 获取当前 goroutine
gp := getg()
// 如果竞争检测被启用,则初始化竞争检测上下文
if raceenabled {
gp.racectx, raceprocctx0 = raceinit()
}
// 最大 M 的计数设置
sched.maxmcount = 10000
// 将 crash 文件描述符设置为最大值
crashFD.Store(^uintptr(0))
// The world starts stopped.
worldStopped()
// 尽早初始化 tick 计时器
ticks.init()
// 模块数据验证
moduledataverify()
// 栈初始化
stackinit()
// 内存分配初始化
mallocinit()
// 获取早期的 GODEBUG 环境变量
godebug := getGodebugEarly()
// 初始化 CPU 配置,必须在算法初始化之前运行
cpuinit(godebug)
// 初始化随机数生成器
randinit()
// 初始化映射、哈希和随机数算法,不能在这之前使用
alginit()
// 进行常见的初始化,传入当前 M
mcommoninit(gp.m, -1)
// 初始化模块,提供 activeModules
modulesinit()
// 初始化类型链接,依赖于 activeModules
typelinksinit()
// 初始化接口表,依赖于 activeModules
itabsinit()
// 栈对象初始化,必须在 GC 启动之前调用
stkobjinit()
// 保存当前信号屏蔽
sigsave(&gp.m.sigmask)
// 初始化信号屏蔽
initSigmask = gp.m.sigmask
// 解析 Go 程序的命令行参数
goargs()
// 解析 Go 程序的环境变量
goenvs()
// 进行安全性初始化
secure()
// 检查文件描述符
checkfds()
// 解析调试变量
parsedebugvars()
// 初始化垃圾回收
gcinit()
// 分配用于处理错栈条件(如 g0 处的 morestack)时的堆栈空间
gcrash.stack = stackalloc(16384)
gcrash.stackguard0 = gcrash.stack.lo + 1000
gcrash.stackguard1 = gcrash.stack.lo + 1000
// 如果禁用内存分析,更新 MemProfileRate 为 0 以关闭内存分析
if disableMemoryProfiling {
MemProfileRate = 0
}
// 初始化当前 M 的性能堆栈
mProfStackInit(gp.m)
// 加锁,保护调度器状态
lock(&sched.lock)
// 存储最后轮询时间
sched.lastpoll.Store(nanotime())
// 初始化 P
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
// 调整可运行 goroutine 的数量
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
// 解锁
unlock(&sched.lock)
// World is effectively started now, as P's can run
worldStarted()
// 这个条件不应该被触发。仅作为保证 runtime·buildVersion 保存到生成的二进制文件中
if buildVersion == "" {
buildVersion = "unknown"
}
// 这个条件不应该被触发。仅作为保证 runtime·modinfo 保存到生成的二进制文件中
if len(modinfo) == 1 {
modinfo = ""
}
}
2.2.4 mstart0
调度系统时在 runtime.mstart0 函数中启动,这个函数是在 m0 的 g0 上执行的
// src/runtime/proc.go
// 定义mstart0函数,负责每个新线程的启动过程
func mstart0() {
// 获取当前的G(goroutine)结构体指针
gp := getg()
// 检查当前线程的栈底(lo)是否为0,判断是否使用系统分配的栈
osStack := gp.stack.lo == 0
if osStack {
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
// 初始化栈保护,以便可以开始调用常规的 Go 代码
gp.stackguard0 = gp.stack.lo + stackGuard
gp.stackguard1 = gp.stackguard0
// 调用mstart1函数,继续线程的启动过程
mstart1()
// 如果栈是系统分配的
if mStackIsSystemAllocated() {
osStack = true
}
// 调用mexit函数,退出线程并传递 osStack 状态
mexit(osStack)
}
// 定义 mstart1 函数,处理进一步的线程初始化
func mstart1() {
// 获取当前的G(goroutine)结构体指针
gp := getg()
// 检查当前 G 是否为 g0,调度器只在 g0 上执行
if gp != gp.m.g0 {
throw("bad runtime·mstart")
}
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
asminit()
// 初始化 m,主要是设置线程的备用信号堆栈和信号掩码
minit()
// 如果当前 g 的 m 是初始 m0,执行 mstartm0()
if gp.m == &m0 {
mstartm0()
}
// 如果有 m 的起始任务函数,则执行,比如 sysmon 函数
// 对于 m0 来说,是没有 mstartfn 的
if fn := gp.m.mstartfn; fn != nil {
fn()
}
// 如果不是 m0,需要绑定 p
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
// 进入调度循环,永不返回
schedule()
}
2.2.5 main
当经过初始的调度,主协程获取执行权后,首先进入的就是 runtime.main 函数
// src/runtime/proc.go
// The main goroutine.
func main() {
// 获取主线程
mp := getg().m
mp.g0.racectx = 0
// 设置最大堆栈大小,64位系统为1GB,32位系统为250MB
if goarch.PtrSize == 8 {
maxstacksize = 1000000000
} else {
maxstacksize = 250000000
}
// 设置最大堆栈的上限,避免调用 SetMaxStack 后分配堆栈过大导致随机崩溃
maxstackceiling = 2 * maxstacksize
// 允许 newproc 启动新的 OS 线程
mainStarted = true
// 如果有系统监视器,启动 sysmon(系统监视线程)
if haveSysmon {
systemstack(func() {
// 分配一个新的 m,运行 sysmon 系统后台监控(定期垃圾回收和调度抢占)
newm(sysmon, nil, -1)
})
}
// 锁定主协程到当前的主操作系统线程
lockOSThread()
// 确保主协程在 m0 上
if mp != &m0 {
throw("runtime.main not on m0")
}
// 记录 the world started 的时间
runtimeInitTime = nanotime()
if runtimeInitTime == 0 {
throw("nanotime returning zero")
}
// 如果启用了初始化追踪
if debug.inittrace != 0 {
inittrace.id = getg().goid
inittrace.active = true
}
// 执行初始化任务,必须在 defer 之前
doInit(runtime_inittasks)
// defer 解锁,以便在执行 Goexit 时也能解锁
needUnlock := true
defer func() {
if needUnlock {
unlockOSThread()
}
}()
// 启用垃圾回收
gcenable()
// 创建主初始化完成的信道
main_init_done = make(chan bool)
// 如果使用 Cgo,则执行相应的检查和初始化
if iscgo {
if _cgo_pthread_key_created == nil {
throw("_cgo_pthread_key_created missing")
}
if _cgo_thread_start == nil {
throw("_cgo_thread_start missing")
}
if GOOS != "windows" {
if _cgo_setenv == nil {
throw("_cgo_setenv missing")
}
if _cgo_unsetenv == nil {
throw("_cgo_unsetenv missing")
}
}
if _cgo_notify_runtime_init_done == nil {
throw("_cgo_notify_runtime_init_done missing")
}
if set_crosscall2 == nil {
throw("set_crosscall2 missing")
}
set_crosscall2()
startTemplateThread()
cgocall(_cgo_notify_runtime_init_done, nil)
}
// 运行初始化任务
for m := &firstmoduledata; m != nil; m = m.next {
doInit(m.inittasks)
}
// 禁用初始化追踪,以避免在 malloc 和 newproc 中收集统计数据的开销
inittrace.active = false
// 关闭主初始化完成信道
close(main_init_done)
needUnlock = false
// 解锁主线程
unlockOSThread()
// 如果是 C 归档或共享库,不执行 main 函数
if isarchive || islibrary {
return
}
// 调用 main.main 函数,间接调用以防止链接器在布局运行时时不知道 main 包的地址
fn := main_main
fn()
// 如果启用了竞争检测,运行退出钩子
if raceenabled {
runExitHooks(0)
racefini()
}
// 如果在主返回时有其他协程正在崩溃,则等待其他协程完成崩溃追踪
if runningPanicDefers.Load() != 0 {
for c := 0; c < 1000; c++ {
if runningPanicDefers.Load() == 0 {
break
}
Gosched()
}
}
// 如果处于崩溃状态,则等待
if panicking.Load() != 0 {
gopark(nil, nil, waitReasonPanicWait, traceBlockForever, 1)
}
// 运行退出钩子
runExitHooks(0)
// 退出程序
exit(0)
// 这个循环永远不会执行
for {
var x *int32
*x = 0
}
}
2.3 调度循环
调度循环启动之后,便会进入一个无限循环中,不断的执行以下循环 :
- schedule
- execute
- gogo
- goroutine任务
- goexit
- goexit1
- mcall
- goexit0
- schedule
其中调度的过程是在 m 的 g0 上执行的,而 goroutine 任务 -> goexit -> goexit1 -> mcall 则是在 goroutine 的堆栈空间上执行的
2.3.1 schedule
// src/runtime/proc.go
// 一次调度器的轮次:查找可运行的 goroutine 并执行
func schedule() {
mp := getg().m
// 前置检查
if mp.locks != 0 {
throw("schedule: holding locks")
}
if mp.lockedg != 0 {
stoplockedm()
execute(mp.lockedg.ptr(), false) // Never returns.
}
if mp.incgo {
throw("schedule: in cgo")
}
top:
// 获取当前的 P 并重置抢占标记
pp := mp.p.ptr()
pp.preempt = false
// 安全检查:如果正在自旋,运行队列应该是空的
if mp.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) {
throw("schedule: spinning with local work")
}
// 查找可运行的 goroutine(会阻塞直到有可运行的 goroutine)
gp, inheritTime, tryWakeP := findRunnable()
if debug.dontfreezetheworld > 0 && freezing.Load() {
lock(&deadlock)
lock(&deadlock)
}
// 重置自旋状态
if mp.spinning {
resetspinning()
}
// 如果当前用户调度被禁用,且该 goroutine 的调度也是禁用的
// 将其放入待定可运行的 goroutine 列表,以待重新启用用户调度时处理
if sched.disable.user && !schedEnabled(gp) {
lock(&sched.lock)
if schedEnabled(gp) {
unlock(&sched.lock)
} else {
sched.disable.runnable.pushBack(gp)
sched.disable.n++
unlock(&sched.lock)
goto top
}
}
// 如果即将调度一个非正常的 goroutine(例如 GC worker 或 tracereader)
// 则唤醒 P(逻辑处理器)如果有可用的
if tryWakeP {
wakep()
}
if gp.lockedm != 0 {
startlockedm(gp)
goto top
}
// 执行找到的可运行的 goroutine
execute(gp, inheritTime)
}
2.3.2 findrunnalbe
findrunnalbe 中首先从本地队列中检查,然后从全局队列中寻找,再从就绪的网络协程,如果这几个没有就去其他 p 的本地队列偷一些任务
// src/runtime/proc.go
// Finds a runnable goroutine to execute.
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
mp := getg().m
top:
pp := mp.p.ptr()
// 如果 GC 正在等待,停止 M
if sched.gcwaiting.Load() {
gcstopm()
goto top
}
if pp.runSafePointFn != 0 {
runSafePointFn()
}
// now 和 pollUntil 会被保存,以便于后续的工作窃取
now, pollUntil, _ := pp.timers.check(0)
// 尝试调度 trace reader
if traceEnabled() || traceShuttingDown() {
gp := traceReader()
if gp != nil {
trace := traceAcquire()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.ok() {
trace.GoUnpark(gp, 0)
traceRelease(trace)
}
return gp, false, true
}
}
// 尝试调度 GC worker
if gcBlackenEnabled != 0 {
gp, tnow := gcController.findRunnableGCWorker(pp, now)
if gp != nil {
return gp, false, true
}
now = tnow
}
// 每 61 次检查一次全局可运行队列,以确保公平性
if pp.schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
// 尝试从全局队列获取一个 goroutine
gp := globrunqget(pp, 1)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
// 唤醒最终器 goroutine
if fingStatus.Load()&(fingWait|fingWake) == fingWait|fingWake {
if gp := wakefing(); gp != nil {
ready(gp, 0, true)
}
}
// 处理 Cgo 的 yield 调用
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
// 从本地运行队列中获取 goroutine
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}
// 从全局运行队列中获取 goroutine
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
// 从就绪的网络协程中查找
if netpollinited() && netpollAnyWaiters() && sched.lastpoll.Load() != 0 {
if list, delta := netpoll(0); !list.empty() {
gp := list.pop()
injectglist(&list)
netpollAdjustWaiters(delta)
trace := traceAcquire()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.ok() {
trace.GoUnpark(gp, 0)
traceRelease(trace)
}
return gp, false, false
}
}
// 转为自旋状态,尝试从其他 P 中窃取工作
if mp.spinning || 2*sched.nmspinning.Load() < gomaxprocs-sched.npidle.Load() {
if !mp.spinning {
mp.becomeSpinning()
}
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
return gp, inheritTime, false
}
if newWork {
goto top
}
now = tnow
if w != 0 && (pollUntil == 0 || w < pollUntil) {
pollUntil = w
}
}
...
}
2.3.3 execute
整个函数的主要目的:
- 将一个准备运行的 goroutine (gp) 切换到运行状态(_Grunning)
- 确保在切换期间做出必要的状态更新和性能分析记录
- 处理 M(机器状态)与 G(goroutine)之间的关联,确保资源的正确分配与管理
- 考虑多线程环境中的调度与性能监控,保证程序的健壮性和性能有效性
// src/runtime/proc.go
func execute(gp *g, inheritTime bool) {
mp := getg().m
// 如果 goroutine 性能分析器处于活动状态
// 确保 gp(即当前要执行的 goroutine)其栈已写入到分析器中
if goroutineProfile.active {
tryRecordGoroutineProfile(gp, nil, osyield)
}
mp.curg = gp
gp.m = mp
// 将 gp 的状态从 _Grunnable 设置为 _Grunning(表示该 goroutine 正在运行)
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
// 将被抢占标志设置为 false,意味着该 goroutine 目前不会被抢占
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
if !inheritTime {
mp.p.ptr().schedtick++
}
// 检查性能分析器是否需要开启或关闭
hz := sched.profilehz
if mp.profilehz != hz {
setThreadCPUProfiler(hz)
}
// 获取一个跟踪对象,记录性能数据
trace := traceAcquire()
if trace.ok() {
trace.GoStart()
traceRelease(trace)
}
// 切换到待执行 g (goroutine) 的调度状态,开始执行该 goroutine
gogo(&gp.sched)
}
2.3.4 gogo
gogo 由汇编实现,主要是由 g0 切换到 g 栈,然后执行函数
// src/runtime/asm_amd64.s
TEXT runtime·gogo(SB), NOSPLIT, $0-8
// gobuf
MOVQ buf+0(FP), BX
MOVQ gobuf_g(BX), DX
// make sure g != nil
MOVQ 0(DX), CX
JMP gogo<>(SB)
2.3.5 goexit
当调用任务函数结束返回的时候,会执行到在创建 g 流程中就初始化好的指令:goexit
// src/runtime/asm_arm64.s
TEXT runtime·goexit(SB),NOSPLIT|NOFRAME|TOPFRAME,$0-0
MOVD R0, R0
BL runtime·goexit1(SB)
// src/runtime/proc.go
func goexit1() {
// 如果竞争检测功能被启用
if raceenabled {
// 结束竞争检测的操作
racegoend()
}
// 获取跟踪信息
trace := traceAcquire()
// 如果跟踪信息成功获取
if trace.ok() {
// 调用结束跟踪的函数
trace.GoEnd()
// 释放跟踪信息
traceRelease(trace)
}
// 调用 mcall 函数开始执行 goexit0
mcall(goexit0)
}
// goexit0 函数在 g0 上继续执行。
func goexit0(gp *g) {
// 销毁给定的 goroutine(gp)
gdestroy(gp)
// 调用调度器进行下一轮调度
schedule()
}
2.4 调度时机
2.4.1 gosched
协程可以选择主动让渡自己的执行权利,大多数情况下不需要这么做,但通过 runtime.Goched 可以做到主动让渡
Gosched 函数用于显式告诉调度器,现在可以切换到其他 goroutine。这是通过用户请求而非系统决定的方式切换 goroutine
// src/runtime/proc.go
func Gosched() {
// 检查是否有超时的任务
checkTimeouts()
// 调用 gosched_m 函数进行调度
mcall(gosched_m)
}
func gosched_m(gp *g) {
// 调用 goschedImpl 函数,传入当前 goroutine(gp)和一个表示没有被抢占的标志
goschedImpl(gp, false)
}
func goschedImpl(gp *g, preempted bool) {
// 获取跟踪信息
trace := traceAcquire()
// 读取当前 goroutine 的状态
status := readgstatus(gp)
// 检查 goroutine 的状态,确保其正在运行
if status&^_Gscan != _Grunning {
// 如果状态不正确,打印状态信息并抛出错误
dumpgstatus(gp)
throw("bad g status")
}
// 如果跟踪信息是有效的
if trace.ok() {
// 在状态转变前记录事件
if preempted {
// 如果被抢占,则记录被抢占事件
trace.GoPreempt()
} else {
// 否则记录调度事件
trace.GoSched()
}
}
// 尝试将当前 goroutine 状态从 _Grunning 更改为 _Grunnable
// 这是 atomic 操作,确保无竞争条件
casgstatus(gp, _Grunning, _Grunnable)
// 如果跟踪信息有效,释放跟踪信息
if trace.ok() {
traceRelease(trace)
}
// 释放当前 goroutine 的资源
dropg()
// 获得调度锁
lock(&sched.lock)
// 将当前 goroutine 放入全局运行队列
globrunqput(gp)
// 解锁调度锁
unlock(&sched.lock)
// 如果主程序已经启动,唤醒等待的 goroutine
if mainStarted {
wakep()
}
// 调用调度函数,切换到其他可以运行的 goroutine
schedule()
}
2.4.2 gopark
大部分情况下的调度都是被动调度,当协程在休眠、channel 通道阻塞、网络 IO 阻塞、执行垃圾回收时会暂停,被动调度可以保证最大化利用 CPU 资源。被动调度是协程发起的操作,所以调度时机相对明确
首先从当前栈切换到 g0 协程,被动调度不会将 G 放入全局运行队列,所以被动调度需要一个额外的唤醒机制
这里面涉及的函数主要是 gopark 和 ready 函数
gopark 函数用来完成被动调度,由_ Grunning 变为 _Gwaiting 状态
// src/runtime/proc.go
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceReason traceBlockReason, traceskip int) {
// 如果等待原因不是等待休眠,则检查超时情况
if reason != waitReasonSleep {
checkTimeouts()
}
mp := acquirem()
gp := mp.curg
// 读取当前 goroutine 的状态
status := readgstatus(gp)
// 检查当前 goroutine 状态是否是运行或扫描运行
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
// 设置等待锁
mp.waitlock = lock
// 设置解锁函数
mp.waitunlockf = unlockf
// 设置等待原因
gp.waitreason = reason
// 设置追踪块原因
mp.waitTraceBlockReason = traceReason
// 设置追踪跳过
mp.waitTraceSkip = traceskip
// 释放当前的 M
releasem(mp)
// 调用 park_m 函数进行真正的等待
mcall(park_m)
}
// park_m 是处理 goroutine 等待的具体实现
func park_m(gp *g) {
// 获取当前的 M
mp := getg().m
// 获取追踪信息
trace := traceAcquire()
if trace.ok() {
// 在转换之前追踪事件,可能会获取栈信息
trace.GoPark(mp.waitTraceBlockReason, mp.waitTraceSkip)
}
// 将 goroutine 状态从运行设置为等待
casgstatus(gp, _Grunning, _Gwaiting)
if trace.ok() {
// 释放追踪信息
traceRelease(trace)
}
// 释放当前 goroutine
dropg()
// 如果有解锁函数,就执行它
if fn := mp.waitunlockf; fn != nil {
// 执行解锁函数
ok := fn(gp, mp.waitlock)
// 清空解锁函数
mp.waitunlockf = nil
// 清空锁
mp.waitlock = nil
if !ok {
// 获取追踪信息
trace := traceAcquire()
// 状态从等待改为可运行
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.ok() {
trace.GoUnpark(gp, 2)
traceRelease(trace)
}
// 将 goroutine 重新安排,且不会返回
execute(gp, true)
}
}
// 调度器调度其他 goroutine
schedule()
}
2.4.3 retake
如果一个 g 运行时间过长就会导致其他 g 难以获取运行机会,当进行系统调用时也存在会导致其他 g 无法运行情况;当出现这两种情况时,为了让其他 g 有运行机会,则会进行抢占式调度
// src/runtime/proc.go
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
// 遍历所有的 p
for i := 0; i < len(allp); i++ {
pp := allp[i]
if pp == nil {
continue
}
pd := &pp.sysmontick
s := pp.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// 如果 G 正在同一个调度时间片上运行太长时间,则强制抢占
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
// 如果连续运行 10ms 则进行抢占
preemptone(pp)
sysretake = true
}
}
// 针对系统调用情况进行抢占
// 如果 p 的运行队列中有等待运行的 g 则抢占
// 如果没有空闲的 p 则进行抢占
// 系统调用时间超过 10ms 则进行抢占
if s == _Psyscall {
t := int64(pp.syscalltick)
if !sysretake && int64(pd.syscalltick) != t {
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
if runqempty(pp) && sched.nmspinning.Load()+sched.npidle.Load() > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
unlock(&allpLock)
incidlelocked(-1)
trace := traceAcquire()
if atomic.Cas(&pp.status, s, _Pidle) {
if trace.ok() {
trace.ProcSteal(pp, false)
traceRelease(trace)
}
n++
pp.syscalltick++
handoffp(pp)
} else if trace.ok() {
traceRelease(trace)
}
incidlelocked(1)
lock(&allpLock)
}
}
unlock(&allpLock)
return uint32(n)
}
















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











