






一、CDN与存储
1、什么是CDN
CDN的全称是Content Delivery Network,即内容分发网络。
我们都用过天猫超市,在上面买东西非常方便。天猫超市的模式是货品先入天猫超市(后文简称为"猫超")的菜鸟仓,然后由猫超统一派送的。
为了缩短物流的时间,可以让消费者快速的收到货品,菜鸟在全国各地建了本地仓库,现在大多数情况下,在猫超下单,第二天都可以收到(楼主在江浙沪包邮区,其他地区可能稍有延迟)。
比如我在杭州市西湖区,下单购买了一箱零食,没过多久就可以看到猫超已经发货了,发货地址是杭州的萧山仓,从杭州的一个区运输到另外一个区,24小时怎么也到了。
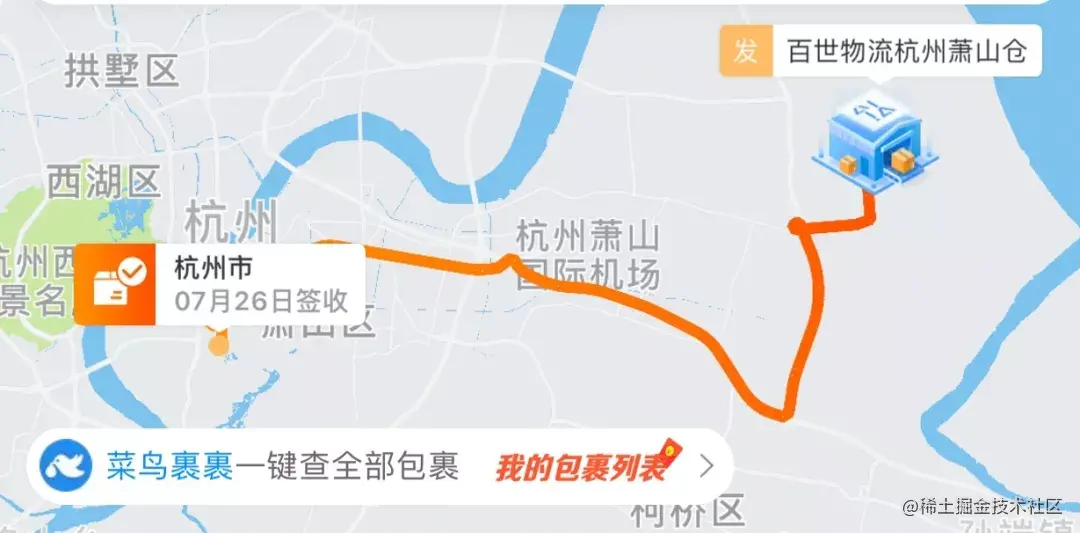
猫超的配送采用的是智能仓配模式,菜鸟为天猫超市提供全国智能分仓,在商品销售前就已经来到距离消费者最近的仓储基地,下单购买后,由最近的仓发货,就近配送,速度比跨越多个省市跑过来的快多了。
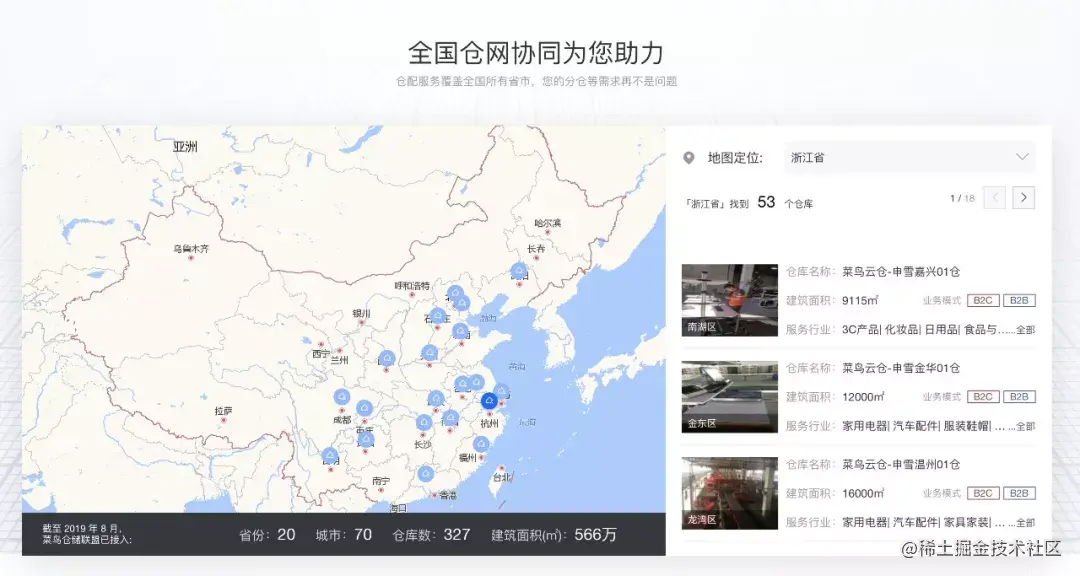
我们可以在菜鸟网络的官网上看到其全国各地的仓库情况,我们可以看到他目前覆盖了全国20哥省份,70个城市,共有327各仓库。这些仓库组合在一起被称之为"全国仓网"。
我们在浏览网络的时候,其实就和以上这个过程十分相似,我们访问一个页面的时候,会向服务器请求很多网络资源,包括各种图片、声音、影片、文字等信息。这和我们要购买的多种货物一样。
就像猫超会把货物提前存储在菜鸟建设在全国各地的本地仓库来减少物流时间一样,网站也可以预先把内容分发至全国各地的加速节点。这样用户就可以就近获取所需内容,避免网络拥堵、地域、运营商等因素带来的访问延迟问题,有效提升下载速度、降低响应时间,提供流畅的用户体验。
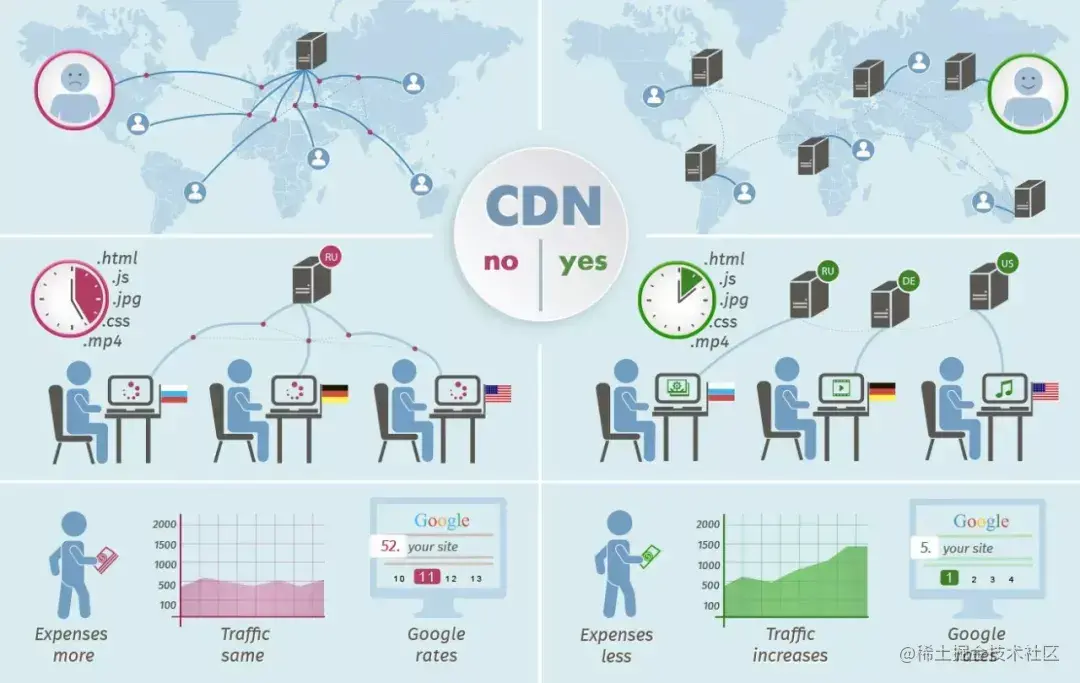
所以,"内容分发网络"就像前面提到的"全国仓配网络"一样,解决了因分布、带宽、服务器性能带来的访问延迟问题,适用于站点加速、点播、直播等场景。使用户可就近取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度和成功率。
1.1 有了仓配网络之后,除了可以提升货物的配送效率,还有很多其他的好处:
1)首先通过预先做好了货物分发,使得最终货品从出仓到消费者手中的过程是比较短的,那么同城范围内可选择的配送公司就有很多选择,除了比较大的四通一达、顺丰以外,还可以选用一些小的物流公司、甚至菜鸟直接调用饿了么的蜂鸟配送也不是不可能。
CDN技术消除了不同运营商之间互联的瓶颈造成的影响,实现了跨运营商的网络加速,保证不同网络中的用户都能得到良好的访问质量
2)对于仓配系统来说,最大的灾难可能就是仓库发生火灾、水灾等自然灾害。如果把原来的一个集中式的大仓库打散成多个分布式的小仓库,分别部署在不同地区,就可以有效的减小自然灾害带来的影响。
广泛分布的CDN节点加上节点之间的智能冗余机制,可以有效地预防黑客入侵以及降低各种DDoS攻击对网站的影响,同时保证较好的服务质量
2、CDN的基本工作过程
传统快递企业采用的配送模式,通过"商家→网点→分拨→分拨→网点→客户"的环节进行配送。这个过程会有一些问题,如环节多、时效慢、易破损等。
上面这个过程和传统网站的请求响应过程类似,一般经历以下步骤:
- 用户在自己的浏览器中输入要访问的网站域名。
- 浏览器向本地DNS服务器请求对该域名的解析。
- 本地DNS服务器中如果缓存有这个域名的解析结果,则直接响应用户的解析请求。
- 本地DNS服务器中如果没有关于这个域名的解析结果的缓存,则以迭代方式向整个DNS系统请求解析,获得应答后将结果反馈给浏览器。
- 浏览器得到域名解析结果,就是该域名相应的服务设备的IP地址 。
- 浏览器获取IP地址之后,经过标准的TCP握手流程,建立TCP连接。
- 浏览器向服务器发起HTTP请求。
- 服务器将用户请求内容传送给浏览器。
- 经过标准的TCP挥手流程,断开TCP连接。
电商自建物流之后,配送模式有所变化:提前备货将异地件转化成同城件,省去干线环节提升时效,仓储高自动化分拣保证快速出库的同时也保证了分拣破损率较低。
对于用户来说,购物过程并没有变化,唯一的感受就是物流好像是比以前快了。所以,引入CDN之后,用户访问网站一般经历以下步骤:
- 当用户点击网站页面上的内容URL,先经过本地DNS系统解析,如果本地DNS服务器没有相应域名的缓存,则本地DNS系统会将域名的解析权交给CNAME指向的CDN专用DNS服务器。
- CDN的DNS服务器将CDN的全局负载均衡设备IP地址返回给用户。
- 用户向CDN的全局负载均衡设备发起URL访问请求。
- CDN全局负载均衡设备根据用户IP地址,以及用户请求的URL,选择一台用户所属区域的区域负载均衡设备,并将请求转发到此设备上。
- 基于以下这些条件的综合分析之后,区域负载均衡设备会选择一个最优的缓存服务器节点,并从缓存服务器节点处得到缓存服务器的IP地址,最终将得到的IP地址返回给全局负载均衡设备:
- 根据用户IP地址,判断哪一个边缘节点距用户最近;
- 根据用户所请求的URL中携带的内容名称,判断哪一个边缘节点上有用户所需内容;
- 查询各个边缘节点当前的负载情况,判断哪一个边缘节点尚有服务能力。
- 全局负载均衡设备把服务器的IP地址返回给用户。
- 用户向缓存服务器发起请求,缓存服务器响应用户请求,将用户所需内容传送到用户终端。如果这台缓存服务器上并没有用户想要的内容,而区域均衡设备依然将它分配给了用户,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器将内容拉到本地。
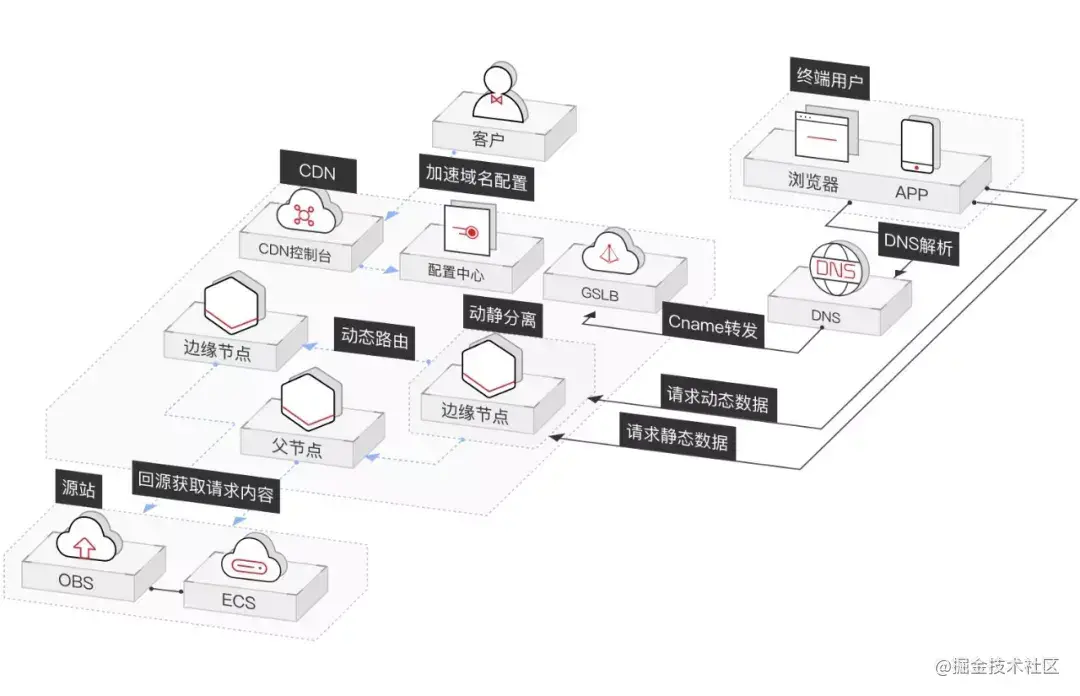
图:华为云全站加速示意图
CDN全局负载均衡设备与CDN区域负载均衡设备根据用户IP地址,将域名解析成相应节点中缓存服务器的IP地址,实现用户就近访问,从而提高服务端响应内容的速度。
3、CDN的组成
前面我们说过,一个仓配网络是由多个仓库组成的,同理,内容分发网络(CDN)是由多个节点组成的。一般来讲,CDN网络主要由中心节点、边缘节点两部分构成。
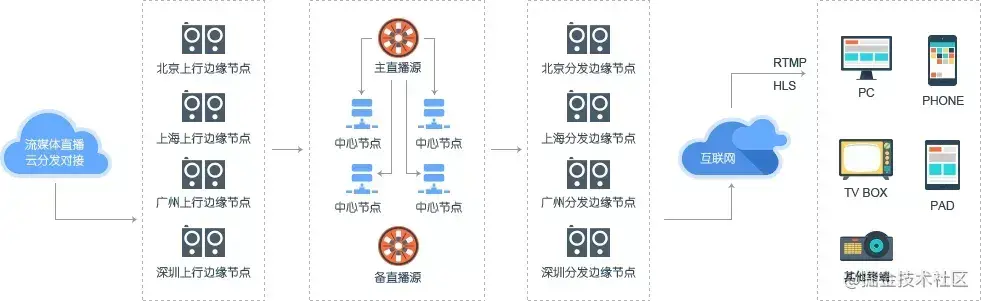
图:帝联云下载加速场景图
3.1 中心节点
中心节点包括CDN网管中心和全局负载均衡DNS重定向解析系统,负责整个CDN网络的分发及管理。
3.2 边缘节点
CDN边缘节点主要指异地分发节点,由负载均衡设备、高速缓存服务器两部分组成。
负载均衡设备负责每个节点中各个Cache的负载均衡,保证节点的工作效率;同时还负责收集节点与周围环境的信息,保持与全局负载均衡DNS的通信,实现整个系统的负载均衡。
高速缓存服务器(Cache)负责存储客户网站的大量信息,就像一个靠近用户的网站服务器一样响应本地用户的访问请求。通过全局负载均衡DNS的控制,用户的请求被透明地指向离他最近的节点,节点中Cache服务器就像网站的原始服务器一样,响应终端用户的请求。因其距离用户更近,故其响应时间才更快。
中心节点就像仓配网络中负责货物调配的总仓,而边缘节点就是负责存储货物的各个城市的本地仓库。
目前,主要由很多提供CDN服务的云厂商在各地部署了很多个CDN节点,拿阿里云举例,我们可以在阿里云的官网上了解到:阿里云在全球拥有2500+节点。中国大陆拥有2000+节点,覆盖34个省级区域,大量节点位于省会等一线城市。海外和港澳台拥有500+节点,覆盖70多个国家和地区。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ezIrpzej-1647091039675)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/f1d4e57ee5d44e1a98714689823ab5ce~tplv-k3u1fbpfcp-zoom-1.image “-w777”)]
图:阿里云在中国大陆的CDN节点的分布情况
有了如上图的阿里云在中国大陆的CDN节点的分布之后(这是不是也和我们前面看到的那张菜鸟网络的全国仓网很像),一个在杭州的电信网络用户,访问某个部署在阿里云上面的网站时,获取到的一些资源,如页面上的某个图片、某段影片或者某些文字,可能就是该网站预先分发到浙江的某个移动CDN存储节点提供的,这样就可以大大的减少网站的响应时间。
4、CDN相关技术
首先我们想一下,要想建设一个庞大的仓配网络都需要考虑哪些问题,需要哪些技术手段呢?
笔者认为主要是四个重要关注的点,分别是:
1、如何妥善的将货物分发到各个城市的本地仓。
2、如何妥善的各个本地仓存储货物。
3、如何根据用户的收货地址,智能的匹配出应该优先从哪个仓库发货,选用哪种物流方式等。
4、对于整个仓配系统如何进行管理,如整体货物分发的精确度、仓配的时效性、发货地的匹配度等。

图:菜鸟仓库智能机器人分拣货物
这其实和CDN中最重要的四大技术不谋而合,那就是内容发布、内容存储、内容路由以及内容管理等。
4.1 内容发布
它借助于建立索引、缓存、流分裂、组播(Multicast)等技术,将内容发布或投递到距离用户最近的远程服务点(POP)处。
4.2 内容存储
对于CDN系统而言,需要考虑两个方面的内容存储问题。一个是内容源的存储,一个是内容在 Cache节点中的存储。
4.3 内容路由
它是整体性的网络负载均衡技术,通过内容路由器中的重定向(DNS)机制,在多个远程POP上均衡用户的请求,以使用户请求得到最近内容源的响应。
4.4 内容管理
它通过内部和外部监控系统,获取网络部件的状况信息,测量内容发布的端到端性能(如包丢失、延时、平均带宽、启动时间、帧速率等),保证网络处于最佳的运行状态。
二、PM2
1、PM2是什么
- 是可以用于生产环境的Nodejs的进程管理工具,并且它内置一个负载均衡。它不仅可以保证服务不会中断一直在线,并且提供0秒reload功能,还有其他一系列进程管理、监控功能。并且使用起来非常简单。
- 嗯嗯,最好的用处就是监控我们的生产环境下的node程序运行状态,让它给我们日以继日的处于工作状态。
- pm2官方文档
2、为森么要使用pm2
-
原始社会的我们开发node服务端程序一般过程:
- 编写好node程序app.js,运行node app.js;或者写入script使用npm运行;打开浏览器访问;
- 好像需要修改内容,浏览器对修改的内容没有显示出来?->node app.js->再次运行;
- 浏览器忽然访问不到服务,好像出错啦?重启下->node app.js->再次运行;
- 哎呀开了好多控制台窗口,一不小心关闭了,服务又访问不到了,继续打开控制台->node app.js->再次运行;
-
好崩溃!好像有个工具nodemon;安装使用nodemon app.js;哇,可以自动监听文件修改变化自动重启,但是关闭控制台服务还是会被摧毁。
-
通过这个很常用的场景,我们了解到要避免这些麻烦一个服务器至少需要有:后台运行和自动重启,这两个能力。
-
再来看看使用pm2可拥有的能力:
- 日志管理;两种日志,pm2系统日志与管理的进程日志,默认会把进程的控制台输出记录到日志中;
- 负载均衡:PM2可以通过创建共享同一服务器端口的多个子进程来扩展您的应用程序。这样做还允许以零秒停机时间重新启动应用程序。
- 终端监控:可以在终端中监控应用程序并检查应用程序运行状况(CPU使用率,使用的内存,请求/分钟等)。
- SSH部署:自动部署,避免逐个在所有服务器中进行ssh。
- 静态服务:支持静态服务器功能
- 支持开发调试模式,非后台运行,pm2-dev start ;
3、PM2的主要特性:
- 内建负载均衡(使用Node cluster 集群模块)
- 后台运行
- 0秒停机重载
- 具有Ubuntu和CentOS 的启动脚本
- 内存的使用 过多了 CPU调度太频繁 会帮助你重启
- 停止不稳定的进程(避免无限循环)
- 控制台检测
- 提供 HTTP API
- 远程控制和实时的接口API ( Nodejs 模块,允许和PM2进程管理器交互 )
- 查看restart 个数 就能知道代码是否有问题,但是提前要走压测,wrk
4、常用命令
1. pm2需要全局安装
npm install -g pm2
2. 进入项目根目录
2.1 启动进程/应用 pm2 start bin/www 或 pm2 start app.js
2.2 重命名进程/应用 pm2 start app.js --name wb123
2.3 添加进程/应用 watch pm2 start bin/www --watch
2.4 结束进程/应用 pm2 stop www
2.5 结束所有进程/应用 pm2 stop all
2.6 删除进程/应用 pm2 delete www
2.7 删除所有进程/应用 pm2 delete all
2.8 列出所有进程/应用 pm2 list
2.9 查看某个进程/应用具体情况 pm2 describe www
2.10 查看进程/应用的资源消耗情况 pm2 monit
2.11 查看pm2的日志 pm2 logs
2.12 若要查看某个进程/应用的日志,使用 pm2 logs www
2.13 重新启动进程/应用 pm2 restart www
2.14 重新启动所有进程/应用 pm2 restart all
5、PM2.json
{
"apps": [
{
"name": "worker",
"script": "./app.js",
"out_fil": "log/node-app.stdout.log",
"watch": true,
"instances" : "max",
"exec_mode" : "cluster"
}]
}
说明:
- name:应用程序名称
- script:应用程序的脚本路径
- out_file:自定义应用程序日志文件
- watch:监听应用目录的变化,一旦发生变化,自动重启
- instances:启用多少个实例,用于负载均衡
- exec_mode:应用程序启动模式,这里设置的是cluster_mode(集群),默认是fork
三、Docker
1、微服务架构介绍
-
通过将功能分解到各个离散的服务中以实现对解决方案的解耦。
-
你可以将其看作是在架构层次而非获取服务的
1.1 程序开发的角度:
把一个大型的单个应用程序和服务拆分为数个甚至数十个的支持微服务,它可扩展单个组件而不是整个的应用程序堆栈,从而满足服务等级协议。
1.2 定义:
围绕业务领域组件来创建应用,这些应用可独立地进行开发、管理和迭代。在分散的组件中
使用云架构和平台式部署、管理和服务功能,使产品交付变得更加简单。
微服务(Microservice)这个概念是2012年出现的,作为加快Web和移动应用程序开发进程的一种方
法,2014年开始受到各方的关注,而2015年,可以说是微服务的元年;
2、传统开发模式和微服务的区别:
2.1 传统开模式:
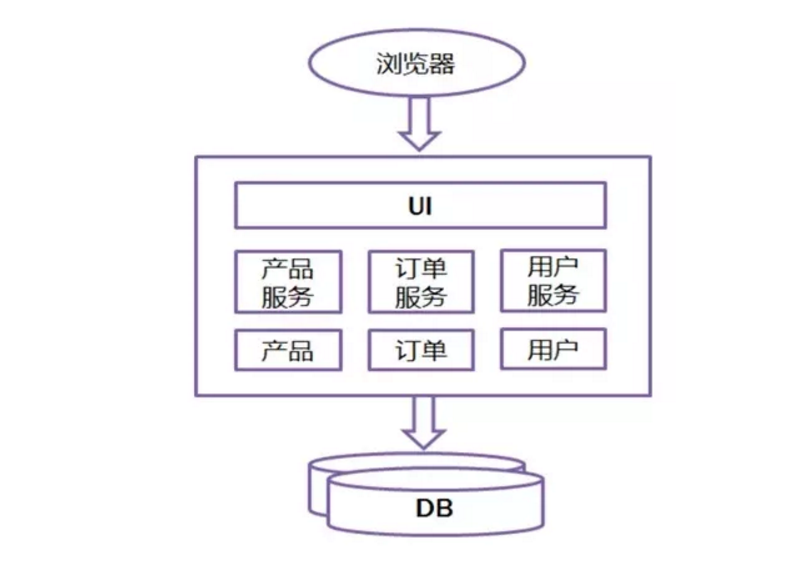
缺点:
1、效率低:开发都在同一个项目改代码,相互等待,冲突不断
2、维护难:代码功能耦合在一起,新人不知道何从下手
3、不灵活:构建时间长,任何小修改都要重构整个项目,耗时
4、稳定性差:一个微小的问题,都可能导致整个应用挂掉
5、扩展性不够:无法满足高并发下的业务需求
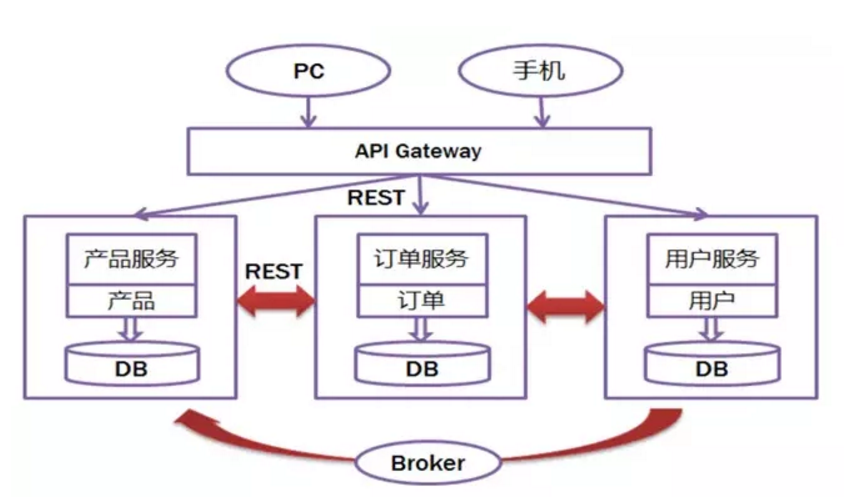
2.2 基于微服务的开发模式:
1、一些列的独立的服务共同组成系统
2、一些列的独立的服务共同组成系统
3、单独部署,跑在自己的进程中
4、每个服务为独立的业务开发
5、分布式管理
6、非常强调隔离性
2.3 Java :一次编译,到处运行 JVM Java虚拟机
Docker :真正实现一次编译,到处运行
Docker 是一个开源的应用容器引擎,它基于 Google 公司推出的 Go 语言实现
让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或
Windows 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
3、虚拟化容器技术-Docker简介
3.1 目标
了解虚拟化技术
3.2 概述
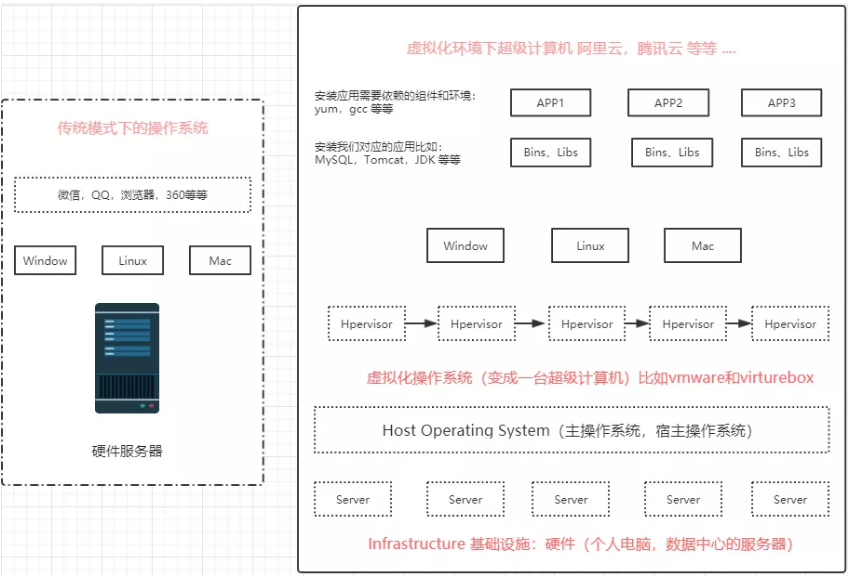
在计算机中,虚拟化(英语:Virtualization)是一种资源管理技术,是将计算机的各种实体资源,如服务器、网络、内存及存储等,予以抽象、转换后呈现出来,打破实体结构间的不可切割的障碍,使用户可以比原本的组态更好的方式来应用这些资源。这些资源的新虚拟部份是不受现有资源的架设方式,地域或物理组态所限制。一般所指的虚拟化资源包括计算能力和资料存储。
(比如:vmware也是一个虚拟资源,大家都在使用vmware,大家都是在上面建立一个虚拟机,其实这就是一种虚拟化技术,或者半虚拟化技术,大家是不是使用vmware安装一个centos的系统或者安装一个windows的系统。那么你在上面操作其实和你在实体机上操作是不是比较类似,对吧,他们之间这种技术就是虚拟化技术。
这种虚拟化技术它有一个小小的弊端,我们在我们的vmware上面创建了一个centos的虚拟机,它在使用的时候是以我当前的操作系统紧密相连的,简单点说,你的操作系统内存只有4G,你在创建虚拟机的时候你会分配8个G吗?
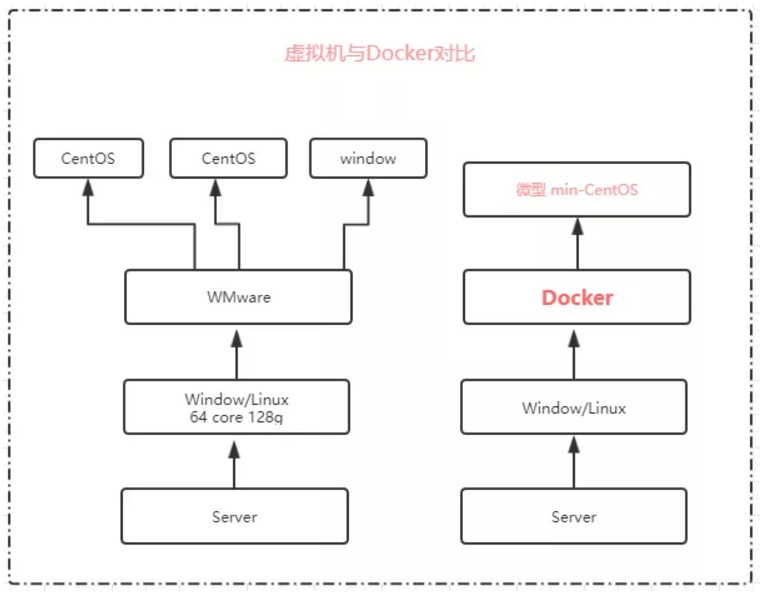
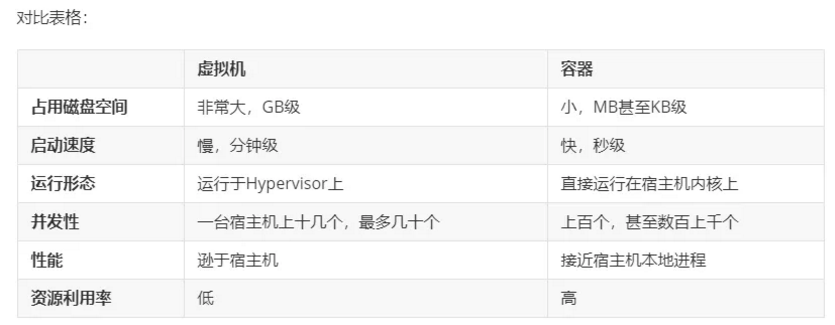
说不能,说明虚拟机是依赖我们的当前的物理系统,它只不过是在之上构建了虚拟的系统,我们就可以使用它,这种其实就是一种半虚拟化技术。)这种虚拟机技术,完全依赖底层的宿主机,每个虚拟机本身都是独立的,隔离的,每一个都有自己单独的内存,资源没有办法达到共享,资源达不到最大化的利用和使用。而docker和它不一样,它是共享的,大白话就是我的上面有docker容器可以共享我的资源,这个时候就会在宿主机上或者一台主机上,我可以部署很多个docker容器,他们是共享的 docker这种容器技术,给我们的开发和运维去做一个统一的环境,是非常非常好的,也是非常高效和快捷的。
大家知道在真实的开发中,开发人员和与运维人员经常因为环境的问题出现故障和扯皮,这个是非常常见的纠纷,比如你在电脑上的环境都是你自己安装部署的,ok你开发完了运行没有任何问题,但是测试人员在测试的时候出问题了。为什么呢?因为它和你的环境不一样,比如你使用的是jdk1.8他使用的是1.7,常常因为各种版本的问题造成不必要的麻烦,而使用docker这个容器,首先他的第一件事情就是它能帮助我们统一运行环境。这样的话,这样的话能提高我们的开发效率,因为大家都使用的是同一个环境。所以说呀,docker以后在未来的开发环境中,用的越来越多,但是呢,docker在真正的学习过程中,它是有点偏运维方面。这也就是为什么现在招聘里面有一个职位叫:运维开发工程师
4、Docker和虚拟机形象比喻
4.1 什么是物理机

4.2 什么是虚拟机

4.3 什么是docker

5、虚拟化容器技术–什么是Docker
官网:https://www.docker.com/
图例:

一头鲸鱼通过身上的集装箱(Container)来将不同种类的货物进行隔离,而不是通过生出很多小鲸鱼来承运不同种类的货物。Docker是一个开源的应用容器引擎,基于GO语言并遵从 Apache2.0协议开源。Docker可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的容器是完成使用沙箱机制,相互之间不会有任何接口重叠,更重要的容器性能开销极低。一个完整的Docker基本架构由如下几个部分构成:客户端,宿主机,注册中心
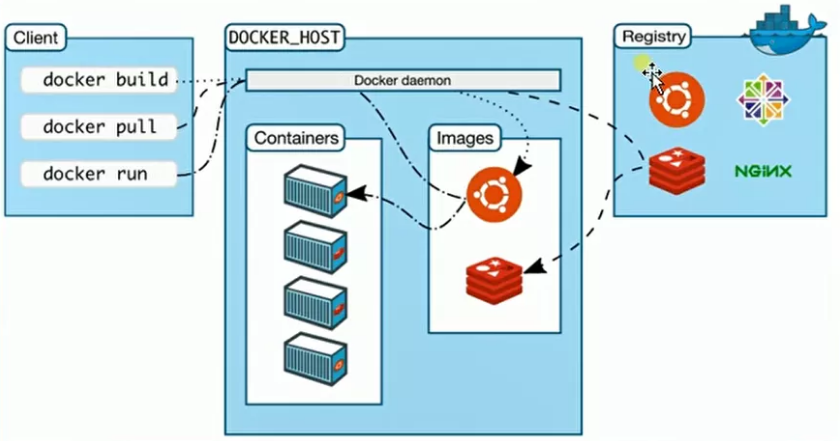
5.1 Docker客户端
也就是在窗口中执行的命令,都是客户端
5.2 Docker Daemon守护进程
用于去接受client的请求并处理请求
5.3 仓库:
Docker用Registry来保存用户构建的镜像。Registry分为公共和私有两种。Docker公司运营公共的Registry叫做Docker Hub。远程仓库地址:https://hub.docker.com/
5.4 镜像:
简单点说:镜像不是单一的文件:而是有多层构成,我们可以通过 docker history 镜像名|id 查看镜像中各层内容及大小,每层都对应着Dockerfifile中的一条指令。Docker镜像默认存在/var/lib/docker/中。镜像从何而来:Docker Hub是由docker公司负责和维护的公共注册中心,包含大量的镜像文件,Docker客户端工具默认从这个公共镜像仓库下载镜像, 远程仓库地址:https://hub.docker.com/
5.5 容器
容器其实是在镜像的最上面加了一层读写层,在运行容器里做的任何文件改动,都会写到这个读写层。如果容器删除了,最上面的读写层也就删除了,改动也就丢失了。Docker使用存储驱动管理镜像每层内容及可读写层的容器层。
6、虚拟化容器技术-- 什么镜像
远程仓库镜像地址:https://hub.docker.com/
解释:镜像就像你下载了一个gz或zip压缩包。只不过这个镜像文件中意见包括了几个部分:
-
微型计算机(文件系统,网络)
-
当前镜像的文件,比如你下载的tomcat,tomcat的镜像文件就包括了:微型计算机 + Tomcat环境+Jdk环境 = Tomcat镜像
7、虚拟化容器技术-- 什么容器
什么是容器:就是镜像创建出来的一个运行的系统,与其说是系统还不如说,容器就是一个进程。就好比你之前下载了tomcat就开始进行解压安装和运行。
当下Docker容器化技术的背景和支撑
8、总结
8.1 什么是Docker
1:使用最广泛的开源容器.
2:一种操作系统的虚拟化技术 linux 内核
3:依赖于Linux内核特性:NameSpace和Cgroups
4:一个简单的应用程序打包工具
8.2 作用和目的
1:提供简单的应用程序打包工具
2:开发人员和运维人员职责逻辑分离
3:多环境保持一致。消除了环境的差异。
8.3 Docker的应用场景
1:应用程序的打包和发布
2:应用程序隔离
3:持续集成
4:部署微服务
5:快速搭建测试环境
6:提供PaaS平台级产品
8.4 容器带来的好处有哪些?
1)秒级的交付和部署
2)保证环境一致性
3)高效的资源利用
4)弹性的伸缩
5)动态调度迁移成本低
8.5 注意:
Docker本身并不是容器,它是创建容器的工具,是应用容器引擎 。
- 想要搞懂Docker,其实看它的两句口号就行 :第一句,是“Build, Ship and Run”

也就是
搭建、发送、运行 三板斧
第二句口号就是:“Build once,Run anywhere**(搭建一次,到处能用)**”。
Docker技术的三大核心概念,分别是:
镜像(Image)
容器(Container)
仓库(Repository
负责对Docker镜像进行管理的,是Docker Registry服务(类似仓库管理员)。
不是任何人建的任何镜像都是合法的。万一有人盖了一个有问题的房子呢?所以,Docker Registry服务对镜像的管理是非常严格的。最常使用的Registry公开服务,是官方的Docker Hub,这也是默认的Registry,并拥有大量的高质量的官方镜像。
9、Dockerfile
9.1 什么是dockerfile
Dockerfile是一个包含用于组合映像的命令的文本文档。可以使用在命令行中调用任何命令。 Docker通过读取Dockerfile中的指令自动生成映像。
docker build 命令用于从Dockerfile构建映像。可以在docker build命令中使用-f标志指向文件系统中任何位置的Dockerfile。
例:
docker build -f /path/to/a/Dockerfile
9.2 Dockerfile的基本结构
Dockerfile 一般分为四部分:基础镜像信息、维护者信息、镜像操作指令和容器启动时执行指令,’#’ 为 Dockerfile 中的注释。
9.3 Dockerfile文件说明
Docker以从上到下的顺序运行Dockerfile的指令。为了指定基本映像,第一条指令必须是FROM。一个声明以#字符开头则被视为注释。可以在Docker文件中使用RUN,CMD,FROM,EXPOSE,ENV等指令。
在这里列出了一些常用的指令。
1. FROM:指定基础镜像,必须为第一个命令
格式:
FROM <image>
FROM <image>:<tag>
FROM <image>@<digest>
示例:
FROM mysql:5.6
注:
tag或digest是可选的,如果不使用这两个值时,会使用latest版本的基础镜像
2.MAINTAINER: 维护者信息
格式:
MAINTAINER <name>
示例:
MAINTAINER Jasper Xu
MAINTAINER sorex@163.com
MAINTAINER Jasper Xu <sorex@163.com>
3.RUN:构建镜像时执行的命令
RUN用于在镜像容器中执行命令,其有以下两种命令执行方式:
shell执行
格式:
RUN <command> exec执行
格式:
RUN ["executable", "param1", "param2"]
示例:
RUN ["executable", "param1", "param2"]
RUN apk update
RUN ["/etc/execfile", "arg1", "arg1"]
注:
RUN指令创建的中间镜像会被缓存,并会在下次构建中使用。如果不想使用这些缓存镜像,可以在构建时指定--no-cache参数,如:docker build --no-cache
4.ADD:将本地文件添加到容器中,tar类型文件会自动解压(网络压缩资源不会被解压),可以访问网络资源,类似wget
格式:
ADD <src>... <dest>
ADD ["<src>",... "<dest>"] 用于支持包含空格的路径
示例:
ADD hom* /mydir/ # 添加所有以"hom"开头的文件
ADD hom?.txt /mydir/ # ? 替代一个单字符,例如:"home.txt"
ADD test relativeDir/ # 添加 "test" 到 `WORKDIR`/relativeDir/
ADD test /absoluteDir/ # 添加 "test" 到 /absoluteDir/
5.COPY:功能类似ADD,但是是不会自动解压文件,也不能访问网络资源
CMD:构建容器后调用,也就是在容器启动时才进行调用。
格式:
CMD ["executable","param1","param2"] (执行可执行文件,优先)
CMD ["param1","param2"] (设置了ENTRYPOINT,则直接调用ENTRYPOINT添加参数)
CMD command param1 param2 (执行shell内部命令)
示例:
CMD echo "This is a test." | wc -
CMD ["/usr/bin/wc","--help"]
注:
CMD不同于RUN,CMD用于指定在容器启动时所要执行的命令,而RUN用于指定镜像构建时所要执行的命令。
6.ENTRYPOINT:配置容器,使其可执行化。配合CMD可省去"application",只使用参数。
格式:
ENTRYPOINT ["executable", "param1", "param2"] (可执行文件, 优先)
ENTRYPOINT command param1 param2 (shell内部命令)
示例:
FROM ubuntu
ENTRYPOINT ["top", "-b"]
CMD ["-c"]
注:
ENTRYPOINT与CMD非常类似,不同的是通过docker run执行的命令不会覆盖ENTRYPOINT,而docker run命令中指定的任何参数,都会被当做参数再次传递给ENTRYPOINT。Dockerfile中只允许有一个ENTRYPOINT命令,多指定时会覆盖前面的设置,而只执行最后的ENTRYPOINT指令
7.LABEL:用于为镜像添加元数据
格式:
LABEL <key>=<value> <key>=<value> <key>=<value> ...
示例:
LABEL version="1.0" description="这是一个Web服务器" by="IT笔录"
注:
使用LABEL指定元数据时,一条LABEL指定可以指定一或多条元数据,指定多条元数据时不同元数据之间通过空格分隔。推荐将所有的元数据通过一条LABEL指令指定,以免生成过多的中间镜像。
8.ENV:设置环境变量
格式:
ENV <key> <value> #<key>之后的所有内容均会被视为其<value>的组成部分,因此,一次只能设置一个变量
ENV <key>=<value> ... #可以设置多个变量,每个变量为一个"<key>=<value>"的键值对,如果<key>中包含空格,可以使用\来进行转义,也可以通过""来进行标示;另外,反斜线也可以用于续行
示例:
ENV myName John Doe
ENV myDog Rex The Dog
ENV myCat=fluffy
9.EXPOSE:指定于外界交互的端口
格式:
EXPOSE <port> [<port>...]
示例:
EXPOSE 80 443
EXPOSE 8080
EXPOSE 11211/tcp 11211/udp
注:
EXPOSE并不会让容器的端口访问到主机。要使其可访问,需要在docker run运行容器时通过-p来发布这些端口,或通过-P参数来发布EXPOSE导出的所有端口
10.VOLUME:用于指定持久化目录
格式:
VOLUME ["/path/to/dir"]
示例:
VOLUME ["/data"]
VOLUME ["/var/www", "/var/log/apache2", "/etc/apache2"
注:
一个卷可以存在于一个或多个容器的指定目录,该目录可以绕过联合文件系统,并具有以下功能:
1 卷可以容器间共享和重用
2 容器并不一定要和其它容器共享卷
3 修改卷后会立即生效
4 对卷的修改不会对镜像产生影响
5 卷会一直存在,直到没有任何容器在使用它
11.WORKDIR:工作目录,类似于cd命令
格式:
WORKDIR /path/to/workdir
示例:
WORKDIR /a (这时工作目录为/a)
WORKDIR b (这时工作目录为/a/b)
WORKDIR c (这时工作目录为/a/b/c)
注:
通过WORKDIR设置工作目录后,Dockerfile中其后的命令RUN、CMD、ENTRYPOINT、ADD、COPY等命令都会在该目录下执行。在使用docker run运行容器时,可以通过-w参数覆盖构建时所设置的工作目录。
12.USER: 指定运行容器时的用户名或 UID,后续的 RUN 也会使用指定用户。使用USER指定用户时,可以使用用户名、UID或GID,或是两者的组合。当服务不需要管理员权限时,可以通过该命令指定运行用户。并且可以在之前创建所需要的用户**
格式:
USER use
USER user:group
USER uid
USER uid:gid
USER user:gid
USER uid:group
示例:
USER www
注:
使用USER指定用户后,Dockerfile中其后的命令RUN、CMD、ENTRYPOINT都将使用该用户。镜像构建完成后,通过`docker run`运行容器时,可以通过-u参数来覆盖所指定的用户。
13.ARG:用于指定传递给构建运行时的变量
格式:
ARG <name>[=<default value>]
示例:
ARG site
ARG build_user=www
14.ONBUILD:用于设置镜像触发器
格式:
ONBUILD [INSTRUCTION]
示例:
ONBUILD ADD . /app/src
ONBUILD RUN /usr/local/bin/python-build --dir /app/src
注:
15.
10、图片说明

四、Commander
事实上,在Node.js或ruby等语言环境里,只要在文件头部添加一行所谓的shebang(提供一个执行环境),就可以将代码转为命令行执行。难在命令行选项处理和流程控制,所以才有了这类工具的出现,叫它们命令行框架最合适。
类似Commander的工具有很多,但多数以规范命令行选项为主,对一些编码细节还要自己实现,比如:何时退出程序(调用process.exit(1))。Commander把这一切都简化了,小巧灵活、简单易用,有它足够了。
1、概念定义
简单直接的命令行工具开发组件。
2、概念解释
- 这是一个
组件,说明是第三方开发的,其实就是开发Express的大神tj开发的。ruby语言也有一个同名的开发组件,同样是tj的杰作,所以,虽为组件,但足够权威,“您值得拥有”。 命令行工具开发,Commander的英文解释是命令,如其名字,这个是用来开发命令行命令的。简单直接,怎么简单?四个函数而已。怎么直接?如果您了解“命令行”的话,就能体会深刻,它通常包含命令、选项、帮助和业务逻辑四个部分,该组件分别提供了对应函数。
因此,只要记住该Commander这个名字和这一句话的概念定义,基本上已经掌握了该组件的全部。下面的用法介绍,仅仅是帮助您更好的记忆和使用。
3、用法介绍:
这里,我们也给它概念化,叫“命令行开发三步曲”。具体以 gitbook-summary为例,解释如下:
3.1 第1步:给工具起名字
这个名字,是工具的名字(其实也是命令,我叫它主命令),用来区分系统命令,限定命令使用的上下文。我通常用工程的名字或操作对象的名字代替,是个名词,比如:book。而用Commander写的命令是个动词(其实是用.command()方法定义的子命令),比如:generate,最后的形式如下:
$ book generate [--options]
只所以把起名字单独提出来,主要是在Node.js的世界里,这一步是固定不变的,只要记住就是了。方法是,在package.json里定义下面的字段:
{
"bin": {
"book": "./path/to/your-commander.js"
}
}
注:package.json文件是包配置文件,是全局配置不可逾越之地。很多工具,都是基于它,提供入口程序的。比如:Node.js自己就是请求main字段的(没有定义,默认请求index.js文件),Npm请求scripts字段。这里多了一个,Commander请求bin字段。
如果,不使用package.json,那么定义的就是node命令之下的子命令,调用方法是:
$ node ./path/to/your-commander.js generate [--options]
如果连node都不想输入,那么就要在代码第一行添加shebang,即:
#!/usr/bin/env node
3.2 第2步:填充四个函数
这一步,用于定义命令、选项、帮助和业务逻辑,完全是Commander概念定义的使用。其实,第三方组件,也就是起到这种微框架的作用。具体用法,自然最好是看 官方文档 了。这里,需要进一步思考的是,对于这个组件而言,这四个函数,最重要的是什么?
我们想到的通常是业务逻辑,不过,请注意,只要是开发,逻辑部分自然只能开发者自己实现,所以,Commander仅仅提供了一个接口函数而已。这里的命令,仅是一个名称。帮助是提示,也仅是简单的文本信息。剩下的各种选项,可以规范,也最为关键,才是Commander的可爱之处。
1)命令:
使用command函数定义(子命令),例如
var program = require("commander");
program
.command("summary <cmd>")
.alias("sm") //提供一个别名
.description("generate a `SUMMARY.md` from a folder") //描述,会显示在帮助信息里
...
当使用-h选项调用命令时,上述命令summary|sm会被显示在帮助信息里。这里的alias和description仅是锦上添花而已。
更复杂的,例如下面官方的例子, .command() 包含了描述信息和 .action(callback) 方法调用,就是说要用子命令各自对应的执行文件,这里就是./pm-install.js,以及 ./pm-search.js 和 ./pm-list.js等。
#!/usr/bin/env node
var program = require('..');
program
.version('0.0.1')
.command('install [name]', 'install one or more packages')
.command('search [query]', 'search with optional query')
.command('list', 'list packages installed')
.command('publish', 'publish the package')
.parse(process.argv);
说明:不使用command方法直接定义主命令,个人建议不要这么做。中规中矩地定义每一个子命令(本文统称命令),只要使用command方法,不带描述信息,附带action方法。如果定义类似git类型的,一连串的命令,一个一个来,显然麻烦,就把描述信息放在command里,去掉action方法,这时默认请求对应的js文件。
- 我们的代码其实就是主命令
- 这个命令的回调是注册一个action(理解主命令)
program
.action((t) => {
console.log('top action call',t)
})
.parse(process.argv);
// 输入:node test
// 输出:top action call
// 输入:node test --help
// 观察
- 注册一个子命令(理解子命令)
program
.action((t) => {
console.log('top action call')
})
// 注意,command返回的是子命令对象,而非主命令
// 所以后续的.是在配置子命令对象
.command('cmd1')
.action((t) => {
console.log('child1 action call')
})
// 从主命令这边解析,所以不是.parse。而是program.parse。
// 当然,如果我们也可以从某个子命令那里开始解析,但不推荐
program.parse(process.argv);
// 说明:command语法结构:command('命令名 参数1 参数2 参数3','描述')
// 也就是支持多个参数,关于参数的使用下面会有案例分析
// 对于参数,和正常js函数的参数一样理解就行了
// <参数> : 代表这个参数是required的,需要在可选参数之前
// [参数] : 代表这个参数是可选的
// <参数...> 或 [参数...] : 和es6...一样理解就行了
// 输入:node test
// 输出:top action call
// 输入:node test cmd1
// 输出:child1 action call
// 说明:此时匹配的是子命令,而不是主命令,所以主命令回调不会执行
- 注册两个子命令,及后代命令(理解子命令)
program
.action((t) => {
console.log('top action call')
})
.command('cmd1')
.action((t) => {
console.log('child1 action call')
})
.command('cmd11')
.action((t) => {
console.log('child11 action call')
})
program
.command('cmd2')
.action((t) => {
console.log('child2 action call')
})
program.parse(process.argv);
// 结构为:
// 主命令
// --cmd1
// --cmd11
// --cmd2
// 输入:node test
// 输出:top action call
// 输入:node test cmd1
// 输出:child1 action call
// 输入:node test cmd1 cmd11
// 输出:child11 action call
// 输入:node test cmd2
// 输出:child2 action call
// 观察
// 输入:node test --help
// 观察:commands: cmd1 cmd2
// 输入:node test cmd1 --help
// 观察:commands: cmd11
- 命令 + 参数(理解参数的必传、选传、和…及action回调参数的值)
program
.command('cmd1 <arg1> [arg2] [arg3...]')
.action((...t) => {
console.log('child1 action call',t)
})
program.parse(process.argv);
// 说明:参数的概念前面有描述
// 这边重点介绍下action的参数:
// 自己可以输出t看结构:
// [arg1,arg2,arg3,{},currentCommandRef]
// 如果第一的时候是两个参数,则为
// [arg1,arg2,{},currentCommandRef]
// 输入:node test cmd1
// 输出:missing required argument 'arg1'
// 输入:node test 1
// 输出:child1 action call ['1',undefined,[],{},currentCommandRef]
// 输入:node test 1 2 3 4
// 输出:child1 action call ['1','2',['3','4'],{},currentCommandRef]
复制代码
- 命令 + 配置({isDefault:true})
program
.command('cmd1 <arg1> [arg2] [arg3...]',{isDefault:true})
.action((...t) => {
console.log('child1 action call',t)
})
program.parse(process.argv);
// 输入:node test 1
// 输出:child1 action call ['1',undefined,[],{},currentCommandRef]
// 说明:也就是isdefault:会配置当前命令为当前层级的默认命令
// 再说一遍:当前层级
// 案例二
program
.action((t) => {
console.log('top action call')
})
.command('cmd1')
.action((t) => {
console.log('child1 action call')
})
.command('cmd11',{isDefault:true})
.action((t) => {
console.log('child11 action call')
})
program.parse(process.argv);
// 输入:node test
// 输出:top action call
// 输入:node test cmd1
// 输出:child11 action call
// 案例三
program
.action((t) => {
console.log('top action call')
})
.command('cmd1',{isDefault:true})
.action((t) => {
console.log('child1 action call')
})
.command('cmd11',{isDefault:true})
.action((t) => {
console.log('child11 action call')
})
program.parse(process.argv);
// 输入:node test
// 输出:child11 action call
- 命令 + 配置({hidden: true})
program
.action((t) => {
console.log('top action call')
})
.command('cmd1')
.action((t) => {
console.log('child1 action call')
})
program.parse(process.argv);
// 输入:node test --help
// 观察:commands
program
.action((t) => {
console.log('top action call')
})
.command('cmd1',{hidden:true})
.action((t) => {
console.log('child1 action call')
})
program.parse(process.argv);
// 输入:node test --help
// 观察:commands
// 输入:node test cmd1
// 输出:child1 action call
// 总结:{hidden:true},只是在--help时不把改命令暴露出去,但不影响正常使用
复制代码
- 命令 + 描述(description)
// 案例一:主命令 + description
program
.description('主命令描述')
.action((...t) => {
console.log('top action call',t)
})
.parse(process.argv);
// 输入:node test --help
// 输出:主命令描述
// 案例二:主命令接收参数
.arguments('<arg1> [arg2] [arg3]')
.description('主命令描述')
.action((...t) => {
console.log('top action call',t)
})
.parse(process.argv);
// 输入:node test 1
// 输出:top action call ['1',undefined,undefined,{},currentCommandRef]
// 案例三:主命令接受参数 + 描述参数
program
.arguments('<arg1> [arg2] [arg3]')
.description('主命令描述',{
arg1:'这个是arg1 的描述',
arg2:'这个是arg2 的描述',
arg3:'这个是arg3 的描述',
})
.action((...t) => {
console.log('top action call',t)
})
.parse(process.argv);
// 输入:node test --help
// 输出:
// 主命令描述
// Arguments:
// arg1 这个是arg1 的描述
// arg2 这个是arg2 的描述
// arg3 这个是arg3 的描述
// 案例四:子命令 + 描述
program
.arguments('<arg1> [arg2] [arg3]')
.description('主命令描述',{
arg1:'这个是arg1 的描述',
arg2:'这个是arg2 的描述',
arg3:'这个是arg3 的描述',
})
.action((...t) => {
console.log('top action call',t)
})
.command('cmd1 <carg1> [carg2]')
.description('子命令1描述',{
carg1:'这个是carg1 的描述',
carg2:'这个是carg2 的描述',
})
program.parse(process.argv);
// 输入:node test --help
// 输入:node test cmd1 --help
// 总结:也就是为当前层的命令及参数增加描述介绍
2) 选项:
使用option方法定义,可以理解为命令行数据结构。
该函数很简单,可以方便的将文本输入转化为程序需要的数据形式。其功能如下:
- 可以设置任何数量的选项,每一个对应一个
.option函数调用; - 可以设置默认值;
- 可以提供文本、数值、数组、集合和范围等约束类型(通过提供处理函数);
- 可以使用正则表达式;
说明:option方法,基本使用就用选项名称和描述;复杂一点就要提供处理函数或默认值;再复杂就用arguments方法代替option方法,使用可变参数(带...的参数)。
- 理解option(基本概念)
program
.option('-a,--add','add something')
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test --help
// 观察options:
Options:
-a,--add add something
-h, --help display help for command
// 输入:node test
// 输出:{}
// 输入:node test -a
// 输出:{ add: true }
// 说明:options是用于注册选项
// 语法:option('-短描述 --长描述 参数1 参数2 参数3','描述',[入参格式函数],[迭代初始值])
// 对比命令command用action来执行回调,选项则使用.opts()来获取选项值
// 对比命令,同一个选项可以使用多次,但命令只是第一次有效
// 对于选项,我们可以把它理解为reduce,特别是:
// [入参格式函数],[迭代初始值] 和 recude(cb(),defaultValue) 一样理解就好
- 选项 + 参数(接收单个参数)
program
.option('-a,--add <arg1>','add something')
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -a 1
// 输出:{ add: '1' }
program
.option('-a,--add [arg1] [arg2]','add something')
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -a 1 2
// 输出:{ add: '1' }
// 说明:和命令的参数对比,选项只有定义了一个参数,不能arg1 arg2
// 思考:那要接收多个参数怎么办呢?⬇️
- 选项 + 参数(接收多个参数)
// 方案一
program
.option('-a,--add [arg1...]','add something')
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -a 1 2 3
// 输出:{ add: [ '1', '2', '3' ] }
// 输入:node test -a
// 输出:{ add: true }
// 说明:和命令的参数对比,如果是可选参数,且是...,不传参数的值不是[]而是默认值
// 方案二
program
.option('-a,--add [arg1...]','add something')
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -a 1
// 输出:{ add: ['1'] }
// 输入:node test -a 1 -a 2
// 输出:{ add: [ '1', '2' ] }
// 说明:也就是如果参数是...,值会叠加,否则值会覆盖
// 说明:对比命令,同一个选项可以使用多次,但命令只是第一次有效
- 选项 + 参数 + 入参格式函数
// 案例一
const addFormat = (value,Accumulator) => {
console.log(value,Accumulator)
return value
}
program
.option('-a,--add [arg1]','add something',addFormat)
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -a 1
// 输出:
1 undefined
{ add: '1' }
// 案例二
const addFormat = (value,Accumulator) => {
console.log(value,Accumulator)
return '我来修改返回值' + value
}
program
.option('-a,--add [arg1]','add something',addFormat)
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -a 1
// 输出:
1 undefined
{ add: '我来修改返回值1' }
// 输入:node test -a 1 -a 2
// 输出:
1 undefined
2 我来修改返回值1
{ add: '我来修改返回值2' }
// 说明:我们发现,第一次执行返回的值会作为第二次执行参数时候的第二个参数值
// 我们可以用:reduce来理解这个函数
// 案例三(加深对 入参格式函数 的作用对象 的理解)
const addFormat = (value,Accumulator) => {
console.log(value,Accumulator)
return '我来修改返回值' + value
}
program
.option('-a,--add [arg1...]','add something',addFormat)
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -a 1 2 -a 3 4
// 输出:
1 undefined
2 我来修改返回值1
3 我来修改返回值2
4 我来修改返回值3
{ add: '我来修改返回值4' }
// 说明:我们发现入参格式函数作用于每个参数
- 选项 + 参数 + 默认值
program
.option('-a,--add [arg1]','add something',1)
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -a
// 输出:{ add: 1 }
// 说明:我们发现输入的都是string类型,这边输出取的是默认值1
// 也就是如果没有设置默认值,默认的默认值为true
- 选项 + 参数 + 入参格式函数 + 默认值
const addFormat = (value,Accumulator) => {
console.log(value,Accumulator)
return value
}
program
.option('-a,--add [arg1]','add something',addFormat,1)
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -a
// 输出:{ add: 1 }
// 输入:node test -a 2
// 输出:
2 1
{ add: '2' }
- 选项 + 参数 + 入参格式函数(具体案例加深理解)
// 案例一、入参字符串类型 => 其他类型
const intFormat = (value,Accumulator) => {
const formatValue = parseInt(value,10)
if(isNaN(formatValue)) {
throw new program.InvalidOptionArgumentError('Not a number.');
}
return formatValue
}
program
.option('-i,--integer [arg1...]','to integer',intFormat)
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -i xx
// 输出:
error: option '-i,--integer [arg1...]' argument 'ad' is invalid. Not a number.
// 输入:12.6
// 输出:{ integer: 12 }
// 案例二、入参 => 其他格式
const splitFormat = (value,Accumulator) => {
return value.split(', ')
}
program
.option('-s,--split [arg1...]','to integer',splitFormat)
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -s 1,2,3
// 输出:{ split: [ '1,2,3' ] }
// 案例三、迭代
const collectFormat = (value,Accumulator) => {
Accumulator.push(value)
return Accumulator
}
program
.option('-c,--collect [arg1...]','to integer',collectFormat,[])
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -c 1 2 -c 3
// 输出:{ collect: [ '1', '2', '3' ] }
// 案例四、迭代
const statisticsFormat = (value,Accumulator) => {
Accumulator +=1
console.log('currentValue',value,'execCounter',Accumulator)
return Accumulator
}
program
.option('-s,--statistics [arg1...]','to integer',statisticsFormat,0)
.parse(process.argv);
const options = program.opts()
console.log(options)
// 输入:node test -s a b -s c
// 输出:
currentValue a execCounter 1
currentValue b execCounter 2
currentValue c execCounter 3
{ statistics: 3 }
- version:我们可以理解为简化版的选项
program
.version('0.1.1','-v,--version','版本描述')
.parse(process.argv)
// 输入:node test -v
// 输出:0.1.1
// 作用:用于标记当前命令的版本
// 输入:node test --help
// 观察:Options
Options:
-v,--version 版本描述
-h, --help display help for command
- help:我们可以理解为简化版的选项
// 观察⬆️
// 具体修改没有测试,这边主要介绍概念
3)描述
- 命令的描述
program
.description('这个是top命令的描述')
program.parse()
// 输入:node test --help
// 观察:这个是top命令的描述
program
.command('cmd1')
.description('这个是child1命令的描述')
program.parse()
// 输入:node test --help
// 观察:
Commands:
cmd1 这个是child1命令的描述
// 说明:description、arguments也都可以为子命令服务
program
.command('cmd1','这个是child1命令的描述')
program.parse()
// 输入:node test --help
// 观察:
Commands:
cmd1 这个是child1命令的描述
- 选项的描述
program
.option('cmd1','这个是选项的描述')
program.parse()
// 输入:node test --help
// 观察:
Options:
cmd1 这个是选项的描述
- 参数的描述
// 案例一、主命令 参数的描述
program
.arguments('[arg1] <arg2>')
.description('这个是top命令的描述',{
arg1:'arg1 的描述',
arg2:'arg2 的描述'
})
program.parse()
// 输入:node test --help
// 观察:
这个是top命令的描述
Arguments:
arg1 arg1 的描述
arg2 arg2 的描述
// 案例二、子命令 参数的描述
program
.command('cmd1 [cArg1] [cArg2]')
.description('这个是child1命令的描述',{
cArg1:'cArg1 的描述',
cArg2:'cArg2 的描述'
})
program.parse()
// 输入:node test cmd1 --help
// 观察:
这个是child1命令的描述
Arguments:
cArg1 cArg1 的描述
cArg2 cArg2 的描述
4)帮助:
使用help方法输出一切有用的描述信息,这些信息通常在命令和选项的定义中,例如
program.help();
如果要定制帮助信息,就用:
program.on('--help',cb);
5)逻辑:
使用action方法注册逻辑,将代码转向执行自己的逻辑代码,当然,git类型的多命令也可以不用。例如
program.action(function(cmd, options) { //code });
3.3 第3步:开发业务逻辑
撰写action可以调用的代码就是了。
五、Node.js进程管理
1、简介
process是一个全局内置对象,可以在代码中的任何位置访问此对象,这个对象代表我们的node.js代码宿主的操作系统进程对象。
使用process对象可以截获进程的异常、退出等事件,也可以获取进程的当前目录、环境变量、内存占用等信息,还可以执行进程退出、工作目录切换等操作。
2、cwd函数的基本用法
当我们想要查看应用程序当前目录时,可以使用cwd函数,使用语法如下:
process.cwd();
3、chdir函数的基本用法
如果需要改变应用程序目录,就要使用chdir函数了,它的用法如下:
process.chdir("目录");
4、stdout的基本用法
stdout是标准输出流,它是干什么的呢?请下看下面的示例:
console.log = function(d){
process.stdout.write(d+'\n');
}
没错,它的作用就是将内容打印到输出设备上,console.log就是封装了它。
5、stderr的基本用法
stderr是标准错误流,和stdout的作用差不多,不同的是它是用来打印错误信息的,我们可以通过它来捕获错误信息,基本使用方法如下:
process.stderr.write(输入内容);
6、stdin的基本用法
stdin是进程的输入流,我们可以通过注册事件的方式来获取输入的内容,如下:
process.stdin.on('readable', function() {
var chunk = process.stdin.read();
if (chunk !== null) {
process.stdout.write('data: ' + chunk);
}
});
示例中的chunk就是输入流中的内容。
7、exit函数的基本用法
如果你需要在程序内杀死进程,退出程序,可以使用exit函数,示例如下:
process.exit(code);
参数code为退出后返回的代码,如果省略则默认返回0;
8、监听进程事件
使用process.on() 方法可以监听进程事件。
exit事件
当进程要退出之前,会触发exit事件。通过监听exit事件,我们可就以在进程退出前进行一些清理工作:
//参数code表示退出码
process.on("exit",function(code){
//进行一些清理工作
console.log("I am tired...")
});
var tick = Date.now();
console.log(tick);
uncaughtException事件
如果进程发生了未捕捉的异常,会触发uncaughtException事件。通过监听这个事件,你可以 让进程优雅的退出:
//参数err表示发生的异常
process.on("uncaughtException",function(err){
console.log(err);
});
//故意抛出一个异常
throw new Error("我故意的...");
9、设置编码
在我们的输入输出的内容中有中文的时候,可能会乱码的问题,这是因为编码不同造成的,所以在这种情况下需要为流设置编码,如下示例:
process.stdin.setEncoding(编码);
process.stdout.setEncoding(编码);
process.stderr.setEncoding(编码);
10、process.argv
process 对象是一个全局变量,它提供当前 Node.js 进程的有关信息,以及控制当前 Node.js 进程。 因为是全局变量,所以无需使用 require()。
process.argv 属性返回一个数组,这个数组包含了启动Node.js进程时的命令行参数,
其中:
-
数组的第一个元素process.argv[0]——返回启动Node.js进程的可执行文件所在的绝对路径
-
第二个元素process.argv[1]——为当前执行的JavaScript文件路径
-
剩余的元素为其他命令行参数
例如:
输入命令:node scripts/build.js “web-runtime-cjs,web-server-renderer”
结果:
console.log(process.argv[0]) // 打印 D:\nodeJs\node.exe
console.log(process.argv[1]) // 打印 E:\Study_document\vue-resource\vue-dev\scripts\build.js
console.log(process.argv[2]) // 打印 web-runtime-cjs,web-server-renderer
六、Node.js常用模块
1、async模块
async模块是为了解决嵌套金字塔,和异步流程控制而生.常用的方法介绍
npm 安装好async模块,然后引入就可以使用 var async = require(‘async’);
1.1 series(tasks,[callback])
多个函数从上到下依次执行,相互之间没有数据交互
var async = require('async');
var task1 = function(callback){
console.log("task1");
callback(null,"task1")
}
var task2 = function(callback){
console.log("task2");
callback(null,"task2")
}
var task3 = function(callback){
console.log("task3");
callback(null,"task3")
}
async.series([task1,task2,task3],function(err,result){
console.log("series");
if (err) {
console.log(err);
}
console.log(result);
})
输出结果:
task1
task2
task3
series
[ 'task1', 'task2', 'task3' ]
如果中途发生错误,则将错误传递到回调函数,并停止执行后面的函数
1.2 parallel(tasks,[callback])
多个函数并行执行,不会等待其他函数
var async = require('async')
var task1 =function(callback){
console.log("task1");
setTimeout(function(){
callback(null,"task1")
},5000);
}
var task2 =function(callback){
console.log("task2");
setTimeout(function(){
callback(null,"task2")
},1000);
}
var task3 =function(callback){
console.log("task3");
setTimeout(function(){
callback(null,"task3")
},3000);
}
console.time("parallel方法");
async.parallel([task1,task2,task3],function(err,result){
console.log("parallel");
if (err) {
console.log(err);
}
console.log(result);
console.timeEnd("parallel方法");
})
输出结果:
task1
task2
task3
parallel
[ 'task1', 'task2', 'task3' ]
parallel方法: 5.017s
3个函数分别延迟5000ms,1000ms,3000ms 结果5000ms就执行完毕.
如果中途出错,则立即将err和值传到最终的回调函数,其他未执行完毕的函数将不再执行,但是要占一个位置
1.3 waterfall(tasks,[callback]) :瀑布流
依次执行,前一个函数的输出为后一个函数的输入
var async = require('async');
var task1 =function(callback){
console.log("task1");
callback(null,"11")
}
var task2 =function(q,callback){
console.log("task2");
console.log("task1函数传入的值: "+q);
callback(null,"22")
}
var task3 =function(q,callback){
console.log("task3");
console.log("task2函数传入的值: "+q);
callback(null,"33")
}
console.time("waterfall方法");
async.waterfall([task1,task2,task3],function(err,result){
console.log("waterfall");
if (err) {
console.log(err);
}
console.log("result : "+result);
console.timeEnd("waterfall方法");
})
输出结果:
task1
task2
task1函数传入的值: 11
task3
task2函数传入的值: 22
waterfall
result : 33
waterfall方法: 3.219ms
如果中途出现错误,后面的函数将不在执行,之前执行的结果和错误信息将直接传到最终的回调函数
1.4 parallelLimit(tasks,limit,[callback])
和parallel类似,只是limit参数限制了同时并发执行的个数,不再是无限并发
var async = require('async')
var task1 =function(callback){
console.log("task1");
setTimeout(function(){
callback(null,"task1")
},5000);
}
var task2 =function(callback){
console.log("task2");
setTimeout(function(){
callback(null,"task2")
},3000);
}
var task3 =function(callback){
console.log("task3");
setTimeout(function(){
callback(null,"task3")
},4000);
}
console.time("parallelLimit方法");
async.parallelLimit([task1,task2,task3], 2, function(err,result){
console.log("parallelLimit");
if (err) {
console.log(err);
}
console.log(result);
console.timeEnd("parallelLimit方法");
})
输出结果:
task1
task2
task3
parallelLimit
[ 'task1', 'task2', 'task3' ]
parallelLimit方法: 7.018s
三个函数分别是延迟5000ms,3000ms,4000ms结果执行时间为什么是7000ms呢
因为首先执行函数1和2,
3秒后函数2执行完毕,这个时候函数3开始执行,
5秒后函数1执行完毕,函数3还有2秒,
7秒后函数3执行完毕.
1.5 auto(tasks,[callback])
多个函数有数据交互,有的并行,有的依次执行
var async = require('async')
console.time("auto方法");
async.auto({
task1: function(callback){
console.log("tsak1");
setTimeout(function(){
callback(null, 'task11', 'task12');
},2000);
},
task2: function(callback){
console.log('task2');
setTimeout(function(){
callback(null, 'task2');
},3000);
},
task3: ['task1', 'task2', function(callback, results){
console.log('task3');
console.log('task1和task2运行结果: ',results);
setTimeout(function(){
callback(null, 'task3');
},1000);
}],
task4: ['task3', function(callback, results){
console.log('task4');
console.log('task1,task2,task3运行结果: ',results);
setTimeout(function(){
callback(null, {'task41':results.task3, 'task42':'task42'});
},1000);
}]
}, function(err, results) {
console.log('err :', err);
console.log('最终results : ', results);
console.timeEnd("auto方法");
});
5秒运行完毕,
函数1和2并行,3秒执行完毕,
函数1和2执行完毕后,函数3,4依次执行共计5秒.
1.6 whilst(test,fn,[callback])
相当于while循环,fn函数里不管是同步还是异步都会执行完上一次循环才会执行下一次循环,对异步循环很有帮助,
test是条件,为true时执行fn里的方法
var async = require('async')
var datalist = [{number:10},{number:20},{number:30},{number:40},{number:50}];
var count = 0;
var test = function () {
return count<datalist.length;
};
var fn = function(callback){
console.log(datalist[count].number);
setTimeout(function () {
count++;
callback();
},1000)
};
async.whilst(test,fn,function(err){
if(err){
console.log(err);
}
console.log('whilst结束');
});
1.7 doWhilst
和whilst类似,和do-while一个意思,首先执行一次fn,再判断,和whilst相比它把fn和test位置交换了而已.
until和whilst相反,当test判断为false的时候执行fn里的方法,为true时跳出,
doUntil与doWhilst相反.
1.8 forever(fn,errback)
forever就是无限循环了.只有当中途出现错误的时候才会停止
1.9 compose(fn1,fn2,fn3…)
这个方法会创建一个异步的集合函数,执行的顺序是倒序.前一个fn的输出是后一个fn的输入.有数据交互
var async = require('async')
var task1 =function(m,callback){
console.log("task1");
setTimeout(function(){
callback(null,m*2)
},1000);
}
var task2 =function(m,callback){
console.log("task2");
setTimeout(function(){
callback(null,m+3)
},1000);
}
var task3 =function(m,callback){
console.log("task3");
setTimeout(function(){
callback(null,m*5)
},1000);
}
console.time("compose方法");
var com = async.compose(task3,task2,task1);
com(2,function(err,result){
if (err) {
console.log(err);
}
console.log(result);
console.timeEnd("compose方法");
})
输出结果:
task1
task2
task3
35
compose方法: 3.038s
相当于 var m=2; (m*2+3)*5 =35;
1.10 parallelLimit 和 eachLimit
1) 概述
async.parallelLimit 方法在文档中位于 Controll Flow 章节,表明这个方法是用来做流程控制的,async.eachLimit 方法位于 Collections 章节,表明这个方法是用来做数据处理的。在实际开发中我们可以使用这两个方法来完成同样的工作,下面我们就以给 26 位用户发送邮件这个任务来举例。
2) 使用 async.parallelLimit 方法实现
async.parallelLimit 方法接受两个参数,第一个参数为任务数组,每个任务是一个函数,第二个参数为每次并行执行的任务数,第三个参数为回调函数。使用 async.parallelLimit 完成发送邮件任务的思路是先使用数据与所要做的任务,组装成任务数组交给 async.parallelLimit 方法去执行。
let userEmailList = [ 'a@example.com', 'b@example.com', ..., 'z@example.com' ];
let limit = 5;
let taskList = userEmailList.map(function (email) {
return function (callback) {
sendEmail(email, function (error, result) {
return callback(error, result);
});
}
});
async.parallel(taskList, limit, function (error, result) {
console.log(error, result);
});
3) 使用 async.eachLimit 方法实现
async.eachLimit 方法接受四个参数,第一个参数为原始数据数组,第二个参数为每次并行处理的数据量,第三个参数为需要为数据进行的处理,第四个参数为回调函数。使用 async.eachLimit 完成发送邮件任务的思路是定义一个对数据进行处理的函数,然后使用 async.eachLimit 将处理函数应用所有数据上。
let userEmailList = [ 'a@example.com', 'b@example.com', ..., 'z@example.com' ];
let limit = 5;
let processer = function (email) {
sendEmail(email, function (error) {
return callback(error, result);
});
}
async.eachLimit(userEmailList, limit, processer, function (error, result){
console.log(error);
});
通过以上代码和 async 文档 可以看出 each 系列函数最终的回调函数是没有运行结果的,所以每一次 processor 中的结果需要另行存储处理。
4) 总结
通过对比以上两种方案,很容易发现 async.parallelLimit 与 async.eachLimit 的区别与应用场景,async.parallelLimit 作为流程控制方法,应该应用于并发处理不同的任务并返回结果,async.eachLimit 作为数据处理方法,应该应用于并发地对一批数据进行相同的处理。所以显然对于给 26 为用户发送邮件这个任务应该使用 async.eachLimit 方法来实现。
在应用场景选择恰当的情况下很少使用到 async.parallelLimit 方法,使用 async.parallel 就可以了,毕竟任务数量不会非常巨大,不做限制一次性并行执行也不会有太大问题。但是如果使用不当,用作数据处理,数据的量级可能会非常巨大,如果不做并行数量限制显然是不可取的方式。
因为对于这两个方法理解地不够透彻,并且受到 Promise.all 使用方式的影响,很多历史代码中从未出现过 async.eachLimit,都是使用 async.parallelLimit 配合 map 笨拙的实现了功能。
2、config包(配置文件管理)
2.1基本使用
在程序部署过程中,不同的环境(生产环境、开发环境)程序的一些配置参数不同,比如数据库信息配置。
对于配置的参数,我们通常使用配置文件管理。
在nodejs中,可以使用第三方模块config模块管理操作配置文件。
- config模块的作用
允许开发人员将不同运行环境下的应用配置信息抽离到单独的文件中,模块内部自动判断当前应用的运行环境(环境变量配置的-NODE_ENV的值),并读取对应的配置信息,极大提供应用配置信息的维护成本,避免了当运行环境重复的多次切换时,手动到项目代码中修改配置信息。
- 使用步骤
- 使用
npm install config命令下载模块 - 在项目的根目录下新建config文件夹
- 在config文件夹下新建default.json、development.json、production.json文件
- 在项目中通过require方法,将模块导入程序中
- 使用模块内部提供的
get方法获取配置信息
- 代码示例:
default.json
{
"title":"管理系统"
}
production.json
{
"title":"管理系统-生产环境"
}
development.json
{
"title":"管理系统-开发环境",
"db": {
"user":"root",
"pwd": "root",
"host":"127.0.0.1",
"port":28888,
"datasource": "myblog"
}
}
app.js
const config = require('config')
const title = config.get('title')
console.log(title)
const host = config.get('db.host')
console.log(host)
console.log(process.env.NODE_ENV)
输出结果
管理系统-开发环境
127.0.0.1
development
2.2 扩展
在实际开发中,对于一些敏感配置信息(如:数据库登录密码),我们一般不会选择明文写在配置文件中,而是配置在系统变量中。操作步骤如下
- 在config文件夹中建立
custom-environment-variables.json文件。 - 配置项属性的值填写系统环境变量的名字
- 项目运行时config模块查找系统环境变量,并读取其值作为配置项的值。
custom-environment-variables.json文件
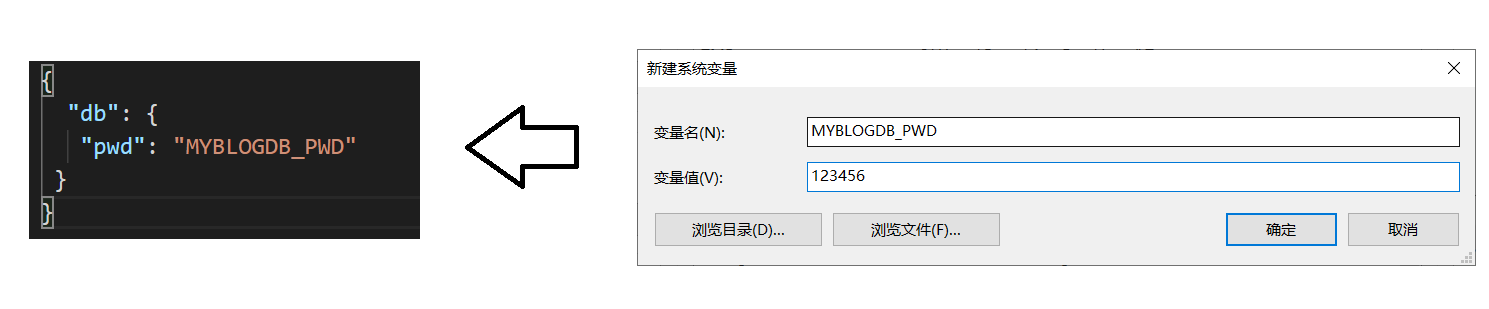
{
"db": {
"pwd": "MYBLOGDB_PWD"
}
}
app.js
const config = require('config')
console.log(process.env.NODE_ENV)
console.log(config.get('db.pwd'))
输出结果:
development
123456
3、Crypto模块
3.1 下载加密库
npm install crypto
常见的摘要算法 与 对应的输出位数:
- MD5:128位
- SHA-1:160位
- SHA256 :256位
- SHA512:512位
3.2 MD5加密
1)概述:
MD5消息摘要算法,属Hash算法一类。MD5算法对输入任意长度的消息进行运行,产生一个128位的消息摘要(32位的数字字母混合码)。
2)MD5主要特点:
不可逆,相同数据的MD5值肯定一样,不同数据的MD5值不一样
//引入crypto模块
var crypto = require('crypto');
var md5 = crypto.createHash('md5');
var message = 'hello';
var digest = md5.update(message, 'utf8').digest('hex'); //hex转化为十六进制
console.log(digest);
// 输出如下:注意这里是16进制
// 5d41402abc4b2a76b9719d911017c592
3)crypto.createHash()方法用于创建一个哈希对象,该哈希对象可通过使用所述算法创建哈希摘要。
-
用法:
crypto.createHash( algorithm, options ) -
参数: 此方法接受两个参数,如avobe所述,如下所述:
-
algorithm: 它取决于平台上的OpenSSL版本所支持的可访问算法。它返回字符串。示例是sha256,sha512等。
-
options: 它是可选参数,用于控制流的行为。它返回一个对象。此外,对于XOF哈希函数(如“ shake256”),选项outputLength可用于确定所需的输出长度(以字节为单位)。
-
返回类型: 它返回哈希对象。
-
4)hash.update()方法是加密模块的Hash类的内置函数。这用于用给定的数据更新哈希。可以多次调用此方法以更新哈希的内容,因为此方法可以获取流数据,例如文件读取流。
此函数将数据作为生成哈希的参数,它可以是字符串或文件对象。与数据一起,这也需要数据的编码类型,可以是utf-8,二进制或ASCII。如果未提供编码并且data是字符串,则使用utf-8。所需的输出长度(以字节为单位)。
-
用法:
hash.update(data [,Encoding]) -
参数: 此函数采用以下两个参数:
data: 需要添加到哈希中的数据。 encoding: 数据的编码类型。 -
返回值: 此方法返回具有更新数据的对象
5)hash.digest()方法是加密模块的Hash类的内置函数。这用于创建创建哈希时传递的数据的摘要。
例如,当我们创建一个哈希时,我们首先使用crypto.createHash()创建一个哈希实例,然后使用update()函数更新哈希内容,但是直到现在我们还没有得到结果哈希值,因此要获得哈希值我们使用Hash类提供的摘要函数。
此函数将字符串作为输入,该字符串定义返回值的类型,例如hex或base64。如果您离开此字段,您将得到Buffer作为结果。
- 用法:
hash.digest([encoding])
-
参数: 此函数采用以下一个参数:
- encoding: 此方法采用一个可选参数,该参数定义返回输出的类型。您可以使用‘hex’或‘base64’作为参数。
模块安装:使用以下命令安装所需的模块:
npm install crypto
返回值: 传递参数时,此函数返回String,而没有传递参数时,返回Buffer对象。假设我们传递了base64参数,那么返回值将是一个base64编码字符串。
3.3 MAC加密
MAC(Message Authentication Code):消息认证码,用以保证数据的完整性。运算结果取决于消息本身、秘钥。
MAC可以有多种不同的实现方式,比如HMAC。
HMAC(Hash-based Message Authentication Code):可以粗略地理解为带秘钥的hash函数。
MAC加密
const crypto = require('crypto');
// 参数一:摘要函数
// 参数二:秘钥
let hmac = crypto.createHmac('md5', '123456');
let ret = hmac.update('hello').digest('hex');
console.log(ret);
// 9c699d7af73a49247a239cb0dd2f8139
3.4 对称加密、非对称加密
-
加密/解密:给定明文,通过一定的算法,产生加密后的密文,这个过程叫加密。反过来就是解密
-
秘钥:为了进一步增强加/解密算法的安全性,在加/解密的过程中引入了秘钥。秘钥可以视为加/解密算法的参数,在已知密文的情况下,如果不知道解密所用的秘钥,则无法将密文解开。
根据加密、解密所用的秘钥是否相同,可以将加密算法分为对称加密、非对称加密。
1)对称加密
加密、解密所用的秘钥是相同的,即encryptKey === decryptKey。
常见的对称加密算法:DES、3DES、AES、Blowfish、RC5、IDEA。
AES有很多不同的算法,如aes192,aes-128-ecb,aes-256-cbc等
加、解密伪代码:
encryptedText = encrypt(plainText, key); // 加密
plainText = decrypt(encryptedText, key); // 解密
2)非对称加密
又称公开秘钥加密。加密、解密所用的秘钥是不同的,即encryptKey !== decryptKey。
加密秘钥公开,称为公钥。
解密秘钥保密,称为秘钥。
常见的非对称加密算法:RSA、DSA、ElGamal。
加、解密伪代码:
encryptedText = encrypt(plainText, publicKey); // 加密
plainText = decrypt(encryptedText, priviteKey); // 解密
3)对比与应用
除了秘钥的差异,还有运算速度上的差异。通常来说:
对称加密速度要快于非对称加密。
非对称加密通常用于加密短文本,对称加密通常用于加密长文本。
两者可以结合起来使用,比如HTTPS协议,可以在握手阶段,通过RSA来交换生成对称秘钥。在之后的通讯阶段,可以使用对称加密算法对数据进行加密,秘钥则是握手阶段生成的。
备注:对称秘钥交换不一定通过RSA,还可以通过类似DH来完成
4、util模块
5、bulebird模块
6、debug模块打印调试日志
- 安装
debug模块
npm install debug
- 使用很简单,运行node程序时,加上
DEBUG=app环境变量即可
/**
* debug基础例子
*/
var debug = require('debug')('app');
// 运行 DEBUG=app node 01.js
// 输出:app hello +0ms
debug('hello');
- 当项目程序变得复杂,我们需要对日志进行分类打印,debug支持命令空间,如下所示。
DEBUG=app,api:表示同时打印出命名空间为app、api的调试日志。
DEBUG=a*:支持通配符,所有命名空间为a开头的调试日志都打印出来。
/**
* debug例子:命名空间
*/
var debug = require('debug');
var appDebug = debug('app');
var apiDebug = debug('api');
// 分别运行下面几行命令看下效果
//
// DEBUG=app node 02.js
// DEBUG=api node 02.js
// DEBUG=app,api node 02.js
// DEBUG=a* node 02.js
//
appDebug('hello');
apiDebug('hello');
- 有的时候,我们想要打印出所有的调试日志,除了个别命名空间下的。这个时候,可以通过
-来进行排除,如下所示。-account*表示排除所有以account开头的命名空间的调试日志。
/**
* debug例子:排查命名空间
*/
var debug = require('debug');
var listDebug = debug('app:list');
var profileDebug = debug('app:profile');
var loginDebug = debug('account:login');
// 分别运行下面几行命令看下效果
//
// DEBUG=* node 03.js
// DEBUG=*,-account* node 03.js
//
listDebug('hello');
profileDebug('hello');
loginDebug('hello');
- debug也支持格式化输出,如下例子所示。
/**
* debug:自定义格式化
*/
var createDebug = require('debug')
createDebug.formatters.h = function(v) {
return v.toUpperCase();
};
var debug = createDebug('foo');
// 运行 DEBUG=foo node 04.js
// 输出 foo My name is CHYINGP +0ms
debug('My name is %h', 'chying');
7、validator 验证模块
- 安装模块
npm install validator
- 引入
var validator = require('validator');
-
验证介绍
-
contains(str, seed) : 是否包含字符串
-
equals(str, comparison) : 检查字符串是否匹配
-
isAfter(str [, date]) : 检查字符串是否在指定的日期之后,默认是当前日期
-
isBefore(str [, date]) 和 isAfter类似
-
isAlpha(str [, locale]) : 检查字符串是否只包含(a-zA-Z).语言环境是其中之一
[‘ar’, ‘ar-AE’, ‘ar-BH’, ‘ar-DZ’, ‘ar-EG’, ‘ar-IQ’, ‘ar-JO’, ‘ar-KW’,
‘ar-LB’, ‘ar-LY’, ‘ar-MA’, ‘ar-QA’, ‘ar-QM’, ‘ar-SA’, ‘ar-SD’, ‘ar-SY’,
‘ar-TN’, ‘ar-YE’, ‘cs-CZ’, ‘de-DE’, ‘en-AU’, ‘en-GB’, ‘en-HK’, ‘en-IN’,
‘en-NZ’, ‘en-US’, ‘en-ZA’, ‘en-ZM’, ‘es-ES’, ‘fr-FR’, ‘hu-HU’, ‘nl-NL’,
‘pl-PL’, ‘pt-PT’, ‘ru-RU’, ‘tr-TR’]
默认为:en-US -
isAlphanumeric(str [, locale]) : 检查字符串是否只包含字母和数字,语言环境和上面一样,默认也是 en-US
-
isAscii(str) : 检查字符串是否只包含ASCII字符
-
isBase64(str) : 检查字符串是否符合base64编码格式
-
isBoolean(str) : 检查字符串是否是boolean值
-
isByteLength(str, options) : 检查字符串的长度是否在一个范围内,包含最大最小临界值
-
isCreditCard(str) : 检查字符串是否是信用卡
-
isCurrency(str, options) : 检查字符串是否是有效金额,options是个对象 默认:{symbol: ‘$’, require_symbol: false,allow_space_after_symbol: false, symbol_after_digits: false, allow_negatives: true, parens_for_negatives: false,negative_sign_before_digits: false, negative_sign_after_digits: false, allow_negative_sign_placeholder: false,thousands_separator: ‘,’, decimal_separator: ‘.’, allow_space_after_digits: false }.
-
isDataURI(str) : 检查字符串是否是uri格式
-
isDate(str) : 检查字符串是否是日期
-
isDecimal(str) : 检查字符串是否是十进制数
-
isDivisibleBy(str, number) : 检查字符串是否是整除的数
-
isEmail(str [, options]) : 检查字符串是否是邮箱 ,options是一个对象默认为
{ allow_display_name: false, allow_utf8_local_part: true, require_tld: true }
-
isFQDN(str [, options]) : 检查字符串是否完全限定域名 , options是个对象,默认:{ require_tld: true, allow_underscores: false,allow_trailing_dot: false }.
-
isFloat(str [, options]) : 检查字符串是否是浮点数, options是个对象,包含最大最小值,比如{min:0.5,max:10.5}
-
isFullWidth(str) : 检查字符串是否包含全角字符
-
isHalfWidth(str) : 检查字符串是否包含半角字符
-
isHexColor(str) : 检查字符串是否是十六进制的颜色
-
isHexadecimal(str) : 检查字符串是否是十六进制数
-
isIP(str [, version]) : 检查字符串是否是一个IP(版本 4 , 6)
-
isISBN(str [, version]) : 检查字符串是否是一个ISBN(版本10 ,13),ISBN是国际标准书号,老版本10位,新版本13位.
-
isISIN(str) : 检查字符串是否是ISIN , ISIN是国际证券识别编码
-
isISO8601(str) : 检查字符串是否是有效的ISO8601日期
-
isIn(str, values) : 检查字符串是否在允许的值
-
isInt(str [, options]) : 检查字符串是否是整数,options是个对象,包含最大值,最小值,比如{min:0,max:100}
-
isJSON(str) : 检查字符串是否是有效的json格式
-
isLength(str, options) : 检查字符串长度是否在范围内,options是个对象,包含最大值,最小值,比如{min:0,max:100}
-
isLowercase(str) : 检查字符串是否都是小写字母.
-
isMACAddress(str) : 检查字符串是否是MAC地址
-
isMobilePhone(str, locale) : 检查字符串是否是手机号,地区:[‘ar-DZ’, ‘ar-SY’, ‘cs-CZ’, ‘de- DE’, ‘da-DK’, ‘el-GR’, ‘en-AU’,
‘en-GB’, ‘en-HK’, ‘en-IN’, ‘en-NZ’, ‘en-US’, ‘en-CA’, ‘en-ZA’, ‘en-ZM’, ‘es-ES’, ‘fi-FI’, ‘fr-FR’, ‘hu-HU’, ‘ms-MY’,
‘nb-NO’, ‘nn-NO’, ‘pl-PL’, ‘pt-PT’, ‘ru-RU’, ‘tr-TR’, ‘vi-VN’, ‘zh-CN’, ‘zh-TW’]). -
isMongoId(str) : 检查字符串是否是有效的mongodb objectid
-
isMultibyte(str) : 检查字符串是否包含一个或多个多字节字符
-
isNull(str) : 检查字符串是否为空,(length为0)
-
isNumeric(str) : 检查字符串是否只包含数字
-
isSurrogatePair(str) : 检查字符串是否包含 emoji表情字符 (主要是手机端)
-
isURL(str [, options]) : 检查字符串是否是个URL
-
isUUID(str [, version]) : 检查字符串是否是UUID(版本3,4,5)
-
isUppercase(str) : 检查字符串是否是大写
-
isVariableWidth(str) : 检查字符串是否包含全角和半角混合字符.
-
isWhitelisted(str, chars) 检查str是否都出现在chars中
-
matches(str, pattern [, modifiers]) : 检查字符串是否匹配,比如 : matches(‘foo’, /foo/i)或 matches(‘foo’, ‘foo’, ‘i’).
-
-
方法介绍
blacklist(input, chars) : 删除出现在黑名单中的字符
`var blacklist = validator.blacklist('abcdefga','a');`
`console.log('blacklist :', blacklist);`
结果 : bcdegf
whitelist(input, chars) : 和blacklist相反
escape(input) : 将 <, >, &, ', " 和 / 转换为html字符
`var escape = validator.escape('< - > - & - /');`
`console.log('escape :', escape);`
结果 : < - > - & - /
unescape(input) : 和 escape方法相反
`var unescape = validator.unescape('< - > - & - /');`
`console.log('unescape :', unescape);`
结果 : < - > - & - /
ltrim(input [, chars]) : 从左边开始删除满足chars中的字符,直到不满足为止.
`var ltrim = validator.ltrim('abcadefgabc','abc');`
`console.log('ltrim :', ltrim);`
结果 : defgabc
rtrim(input [, chars]) : 和 ltrim类似,从右边开始\
**trim(input [, chars]) : 从左右两边同时删除.**
toBoolean(input [, strict]) : 转换为boolean类型
**toDate(input) : 转换为日期类型**
toFloat(input) : 转换为浮点类型
**toInt(input [, radix]) : 转换为int类型**
七、for/for in/forEach/for of
1、for循环
var arr = ['nick','freddy','mike','james'];
for(var i = 0, len=arr.length; i<len; i++){
console.log(i + '.' + arr[i]);
}
输出结果:
0.nick
1.freddy
2.mike
3.james
for循环,通过累加数组索引,来输出数组中的值。(使用比较局限,一般只用于循环数组)
2、for in 循环
var arr = ['nick','freddy','mike','james'];
var userMsg = {
nick: {
name: 'nick',
age: 18,
sex: '男'
},
freddy: {
name: 'freddy',
age: 24,
sex: '男'
}
};
for(var index in arr){
console.log(index +'. ' + arr[index]);
}
console.log('-----------分割线-----------');
for(var key1 in userMsg){
console.log(key1);
for(var key2 in userMsg[key1]){
console.log(userMsg[key1][key2]);
}
}
输出结果:
0. nick
1. freddy
2. mike
3. james
-----------分割线-----------
nick
nick
18
男
freddy
freddy
24
男
相较于for循环,for in的功能会更加强大一些,使用范围也会更广,不但可以循环遍历数组,还可以循环遍历对象。代码中的index,key1,key2分别是目标对象(数组)中的键值(数组中叫习惯叫索引)。arr数组中的index分别0,1,2,3,userMsg对象下的key1分别是"nick"、“freddy"的键值, key2就是userMsg.nick和userMsg.freddy下的键值了,为"name”、“age”、“sex”。(for in在写法上会稍微复杂些,不过他很清晰的展示了循环过程)。
3、forEach()循环
var arr = ['nick','freddy','mike','james'];
arr.forEach(function(item,index,arr){
console.log(item);
console.log(index);
console.log(arr);
});
输出结果:
nick
0
[ 'nick', 'freddy', 'mike', 'james' ]
freddy
1
[ 'nick', 'freddy', 'mike', 'james' ]
mike
2
[ 'nick', 'freddy', 'mike', 'james' ]
james
3
[ 'nick', 'freddy', 'mike', 'james' ]
forEach循环,跟for循环有点相似,不过会更优美,可通过参数直接获取到值,arr.forEach(function(item,index,arr){}),其中item为该索引下的值,index为索引,arr为数字本身,参数名可改变,但是顺序不能改变。
4、for of 循环
var arr = ['nick','freddy','mike','james'];
for(var item of arr){
console.log(item);
}
输出结果:
nick
freddy
mike
james
遍历数组里的每一项。
5、for of 与 for in 的区别
-
区别①:for of无法循环遍历对象
-
区别②:遍历输出结果不同
for in循环遍历的是数组的键值(索引),而for of循环遍历的是数组的值。
- 区别③:for in 会遍历自定义属性,for of不会
var arr = ['nick','freddy','mike','james'];
arr.name = "数组";
for(var key in arr){
console.log(key+': '+arr[key]);
}
console.log('-----------分割线-----------');
for(var item of arr){
console.log(item);
}
输出结果:
0: nick
1: freddy
2: mike
3: james
name: 数组
-----------分割线-----------
nick
freddy
mike
james
给数组添加一个自定义属性name,并且赋值"数组"。然后进行遍历输出的,会发现新定义的属性也被for in输出来了,而for of并不会对name进行输出。
八、git
1、用户名和邮箱设置
$ git config --global user.name "输入用户名" (自定义)
$ git config --global user.email "输入email" (自定义)
2、git提交代码
-
创建远程仓库(GitHub,Gitee,coding…)
-
如果没有本地仓库
echo “# toutiao-publish-admin” >> README.md
-
初始化本地仓库
git init
-
把文件添加到暂存区
git add README.md
-
把暂存区文件提交到本地仓库形成历史记录
git commit -m “first commit”
-
添加远程仓库地址到本地仓库
git remote add origin https://github.com/hyjAdmin/toutiao-publish-admin.git
-
推送到远程仓库
git push -u origin master
-
如果已有本地仓库
-
VueCli 在创建项目的时候自动帮我们初始化了Git仓库,并且基于初始化代码默认执行了一次提交
git remote add origin https://github.com/hyjAdmin/toutiao-publish-admin.git
-
-u 记住本次推送的信息,下次就不用写推送信息了,可以直接 git push
git push -u origin master
-
-
之后如果代码有变动需要提交
git add git commit-
推送到远程仓库
git push
-
-
项目修改 git 远程仓库地址
(1)查看所有远程仓库,一般默认远程仓库名为origin git remote (2)修改当前项目远程地址为 http://192.168.1.88:9090/test/git_test.git git remote set-url origin http://192.168.1.88:9090/test/git_test.git (3)更改地址后,需要提交初始代码到远程库 git push
3、git创建和合并分支命令
3.1 拉取项目
首先,进入到想要拉取分支的 项目 中 (首页为 master 分支)
点击上图中标注出来的 复制 (复制 URL 到剪贴板)按钮复制路径
打开本地终端,进入到想把项目存放的 目录,git clone xxx ( xxx 为刚刚复制的 URL)
3.2 切换分支
使用 git clone xxx 命令后,系统会自动创建项目文件夹
进入 项目文件夹目录,此时所处分支为 master分支
git checkout -b 分支名 新建分支(分支名为 想要拉取的 指定分支的 分支名),然后此时系统会自动切换为新建的这个分支
git pull 拉取分支,更新分支内容
此时会提示让关联分支,按照提示内容输入命令
git branch --set-upstream-to=origin/新建的那个分支名
重新 git pull
此时指定分支上的内容就获取完毕。
3.3 git 命令
git checkout -b 分支名:新建并切换到新分支。git branch: 查看当前分支。git checkout 分支名:切换分支(已有分支)。git branch -d 分支名:删除分支。git pull:拉取分支最新内容。git merge develop:将本分支内容合并到 develop 分支上。git reset --hard origin/当前分支名:将当前分支本地编辑的所有内容舍弃。\
1)提交的时候:
git add .git commit -m "描述提交的内容"git push- git 如何把master分支代码合并到自己的分支
- 转载自https://blog.csdn.net/Bule_daze/article/details/103272403
查看分支:git branch
创建分支:git branch <name>
切换分支:git checkout <name>
创建+切换分支:git checkout -b <name>
合并某分支到当前分支:git merge <分支名> 合并分支时,加上--no-ff参数就可以用普通模式合并,合并后的历史有分支,能看出来曾经做过合并,而不加--no-ff合并就看不出来曾经做过合并。例git merge --no-ff -m "详细解释" 分支
删除分支:git branch -d <name>
查看分支合并图: git log --graph
4、gitlib配置SSH Key
在继续阅读后续内容前,请自行注册GitLab账号(一般进公司,配置管理员或者组长会给你创建账户的)。由于你的本地Git仓库和GitLab仓库之间的传输是通过SSH加密的,所以,需要以下设置:
4.1 第1步:
创建SSH Key。在用户主目录下,看看有没有.ssh目录,如果有,再看看这个目录下有没有id_rsa和id_rsa.pub这两个文件,如果已经有了,可直接跳到下一步。如果没有,打开Shell(Windows下打开Git Bash),创建SSH Key:
$ ssh-keygen -t rsa -C "youremail@example.com"
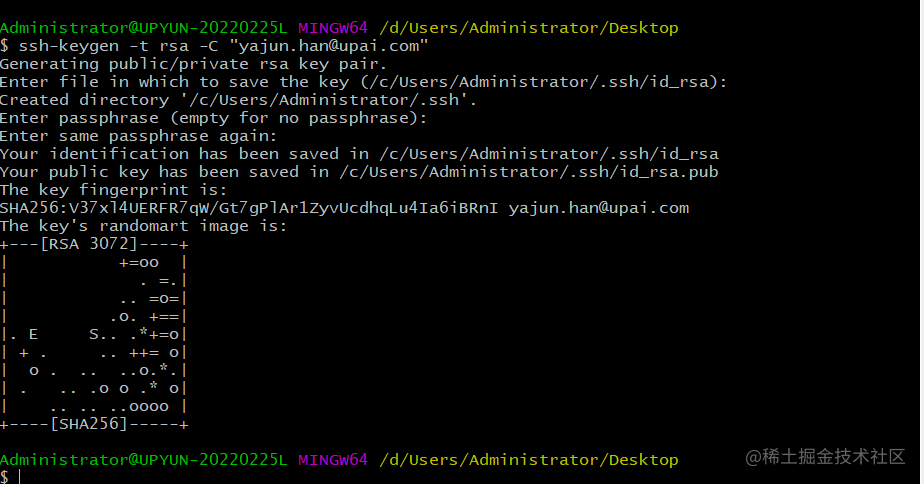
你需要把邮件地址换成你自己的邮件地址,然后一路回车,使用默认值即可,由于这个Key也不是用于军事目的,所以也无需设置密码。
如果一切顺利的话,可以在用户主目录里找到.ssh目录,里面有id_rsa和id_rsa.pub两个文件,这两个就是SSH Key的秘钥对,id_rsa是私钥,不能泄露出去,id_rsa.pub是公钥,可以放心地告诉任何人。
4.2 第2步:
登陆GitLab,打开“settings”,“SSH Keys”页面:
然后,点“Add SSH Key”,填上任意Title,在Key文本框里粘贴id_rsa.pub文件的内容:
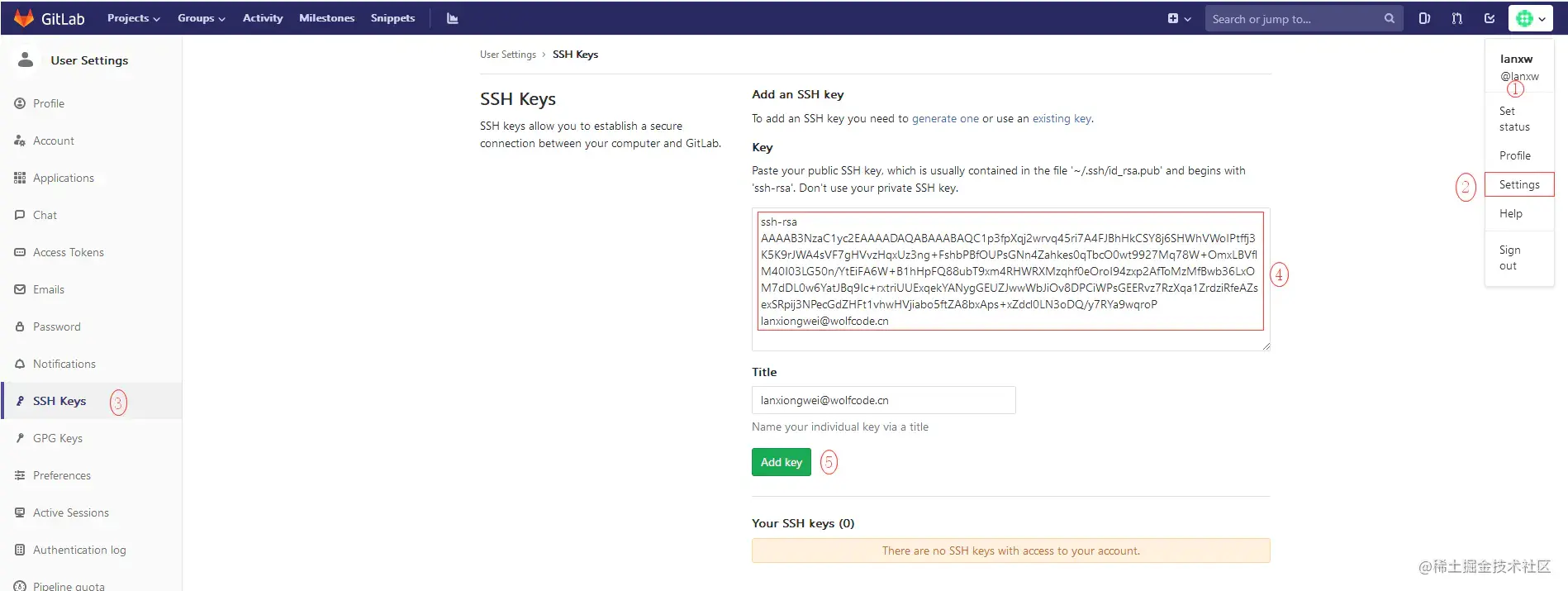
点“Add Key”,你就应该看到已经添加的Key:

为什么GitLab需要SSH Key呢?因为GitLab需要识别出你推送的提交确实是你推送的,而不是别人冒充的,而Git支持SSH协议,所以,GitLab只要知道了你的公钥,就可以确认只有你自己才能推送。
当然,GitLab允许你添加多个Key。假定你有若干电脑,你一会儿在公司提交,一会儿在家里提交,只要把每台电脑的Key都添加到GitLab,就可以在每台电脑上往GitLab推送了。
其他的操作就和GitHub是一样的了.
5、gitlib如何创建分支和拉取代码
从gitlab地址进入进行操作
5.1 登录GitLab
账号密码由company统一提供,如果是自己操作的话,就需要先注册
5.2 登录gitlab后对已创建好的项目进行分支创建
此处默认项目已创建好,如果为创建项目可点击右上角create project
- 创建项目:
- 点击进入:
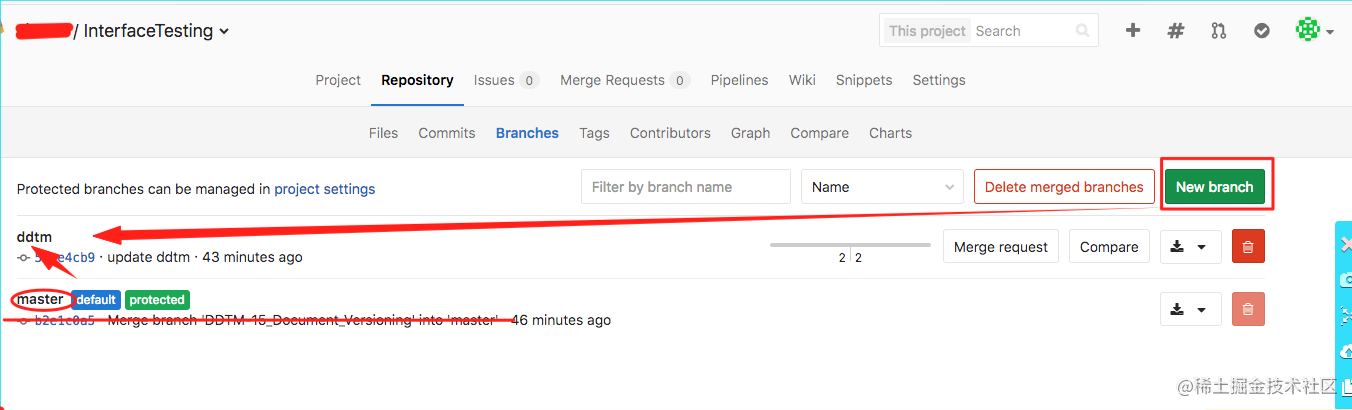
- 在master分支创建自己提交代码的分支,我命名为ddtm
5.3 创建后进入sourcetree(默认已安装,未安装的需要安装好)
1)操作检出代码
2)需要查看他人代码时需要合并master至想要的分支(ddtm)
3)则可以查看到结果
5.4 这样在master上创建分支拉取代码的任务就完成了。
一般情况在sourcetree上的也可以在master创建分支,但是我试过容易出问题,所以最好的办法就是在gitlab上使用账号登录的方式进行创建最好
6、gitlab修改远程分支名称
远程分支重命名 (已经推送远程-假设本地分支和远程对应分支名称相同)
- 重命名远程分支对应的本地分支
git branch -m oldName newName
- 删除远程分支
git push --delete origin oldName
- 上传新命名的本地分支
git push origin newName
- 把修改后的本地分支与远程分支关联
git branch --set-upstream-to origin/newName
7、git rebase 和 git merge
7.1 merge 和 rebase
-
merge 是一个合并操作,会将两个分支的修改合并在一起,默认操作的情况下会提交合并中修改的内容
-
merge 的提交历史记录了实际发生过什么,关注点在真实的提交历史上面
-
rebase 并没有进行合并操作,只是提取了当前分支的修改,将其复制在了目标分支的最新提交后面
-
rebase 操作会丢弃当前分支已提交的 commit,故不要在已经 push 到远程,和其他人正在协作开发的分支上执行 rebase 操作
-
merge 与 rebase 都是很好的分支合并命令,没有好坏之分,使用哪一个应由团队的实际开发需求及场景决定
7.2 git中多次commit合并成一个commit
- 看一下当前分支的提交情况
git log
- 进入编辑页面
git rebase -i HEAD~3
-
进入编辑模式,第一列为操作指令,第二列为commit号,第三列为commit信息。
- pick:保留该commit;
- reword:保留该commit但是修改commit信息;
- edit:保留该commit但是要修改commit内容;
- squash:将该commit和前一个commit合并;
- fixup:将该commit和前一个commit合并,并不保留该commit的commit信息;
- exec:执行shell命令;
- drop:删除该commit。
-
保存退出(:wq)
8、git commit vim 编辑器
8.1 进入编辑模式:(git commit -m 'your message')
- 小写i:在光标所在行位置停止不动开始写入内容
- 大写I:在光标所在行行首开始写入内容
- 小写a:在光标所在行当前字符后开始写入内容
- 大写A:在光标所在行行尾开始写入内容
- 小写o:在光标所在行下一行开始写入内容
- 大写O:在光标所在行上一行开始写入内容
8.2 退出编辑模式:(按下 “ESC” 键,退出编辑模式,切换到命令模式)
- :w:保存文本
- :q:退出编辑模式
- :w!:强制保存,在root用户下即使文本只读也可以强制保存
- :q!:强制退出,所有改动不生效
- :wq:保存并退出

















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









