






入侵检测论文阅读
论文介绍
该论文2021年发表在Expert Systems with Applications期刊上,提出了使用双向长短期记忆网络进行入侵检测的方法。
论文链接
背景介绍
入侵检测
入侵检测系统(IDS)即使不是最好的,也是最有前途的快速识别和处理网络入侵者的方法之一。 IDS 可以识别已经被入侵的网络系统和正在遭受入侵的系统。常见的入侵检测方法分为以下两种:
误用检测: 一种基于模式匹配的网络入侵检测技术,用已知发生的攻击的特征构建攻击知识库,是基于黑名单的检测方法。
异常检测: 总结正常的行为特征构建正常行为知识库,与正常行为特征不符合的则被认为是攻击,是基于白名单的检测方法。
当前相关研究存在的挑战
1、基于传统的机器学习,计算成本较高,没有对数据集有更深入的了解,会发出错误警报。
基础知识
RNN(循环神经网络)
它是一类神经网络,利用先前的输出作为输入,同时保留隐藏层。由于其循环(循环)连接方式,是一种更适合处理顺序数据的方法。
优势: RNN 可以处理任意长度的输入,并随着输入大小的增加而保持模型的大小。与传统的前馈网络不同,RNN 可以回忆之前学到的内容,并根据获得的知识指导决策。即RNN 不仅能够在训练过程中回忆事物,还能够在创建输出的过程中回忆从先前输入中获得的知识。
缺点: 存在梯度消失等缺点,无法学习长期依赖关系。
LSTM(长短期网络)
LSTM是RNN的一种变体,具有与RNN相同的控制流,其基本原理是细胞状态和不同的门。细胞状态相当于信息传输的路径,让信息能在序列连中传递下去;信息的添加和移除则通过“门”结构来实现,“门”结构在训练过程中会去学习该保存或遗忘哪些信息.在控制信息流的LSTM单元中有三个单独的门,即输入、输出和遗忘门,其结构如下图所示。
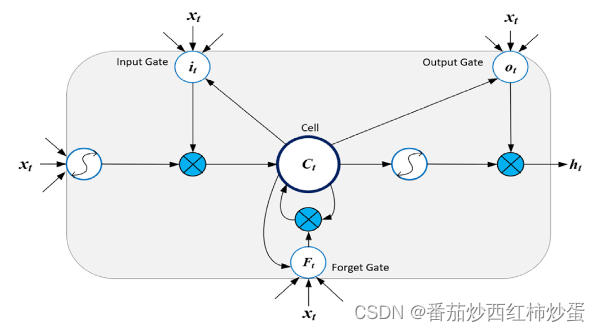
输入和输出之间的关系在时间 t 和 t − 1 处通过以下等式进行数学描述:其中各部分分别为:
i
t
=
σ
(
W
x
i
x
t
+
W
h
i
h
t
−
1
+
W
c
i
c
t
−
1
+
b
i
)
i_t=\sigma(W_{xi}x_t+W_{hi}h_{t-1}+W_{ci}c_{t-1}+b_i)
it=σ(Wxixt+Whiht−1+Wcict−1+bi) (1)
f
t
=
σ
(
W
x
f
x
t
+
W
h
f
h
t
−
1
+
W
c
f
c
t
−
1
+
b
f
)
f_t=\sigma(W_{xf}x_t+W_{hf}h_{t-1}+W_{cf}c_{t-1}+b_f)
ft=σ(Wxfxt+Whfht−1+Wcfct−1+bf) (2)
c
t
=
f
t
c
t
−
1
+
i
t
tanh
(
W
x
c
x
t
+
W
h
c
h
t
−
1
+
b
c
)
c_t=f_tc_{t-1}+i_t\tanh(W_{xc}x_t+W_{hc}h_{t-1}+b_c)
ct=ftct−1+ittanh(Wxcxt+Whcht−1+bc) (3)
o
t
=
σ
(
W
x
o
x
t
+
W
h
o
h
t
−
1
+
W
c
o
c
t
−
1
+
b
o
)
o_t=\sigma(W_{xo}x_t+W_{ho}h_{t-1}+W_{co}c_{t-1}+b_o)
ot=σ(Wxoxt+Whoht−1+Wcoct−1+bo) (4)
h
t
=
o
t
tanh
(
c
t
)
h_t=o_t\tanh(c_t)
ht=ottanh(ct)(5)
其中
c
c
c是细胞状态。
σ
\sigma
σ(sigmoid 函数)和
tanh
\tanh
tanh表示激活函数。
x
x
x表示输入向量,输出由
h
t
h_t
ht给出。
W
W
W和
b
b
b分别表示权重和偏差参数。
f
t
f_t
ft是忘记函数,其作用是筛选出不需要的信息。
i
t
i_t
it(输入门)和
c
c
c在细胞状态中引入新信息。
o
t
o_t
ot为输出门,输出相关信息。
BiLSTM(双向长短期记忆网络)
Bidirectional LSTM(BiDLSTM)是在LSTM基础上提出的,用以提高模型在分类问题上的性能。与LSTM不同的是,BiLSTM网络由前向和后向LSTM组成,其中数据可以向前和向后处理。反向处理捕捉了LSTM通常忽略的数据的隐藏特征和模式,可以更好的捕捉双向的语义依赖,对于提高分类的速度以及准确度具有重要意义。其具体结构如下图所示。


Keras 库使用双向层包装器通过将第一个 LSTM 层作为参数来实现BiLSTM。从图 2 中,输出 (y)、前向隐藏层 (→ ht) 和后向隐藏层 (← ht) 计算如下:
h
t
→
=
H
(
W
x
h
→
x
t
+
W
h
→
h
→
h
t
−
1
→
+
b
h
→
)
\overrightarrow{h_t}=H(W_{x\overrightarrow{h}}x_t+W_{\overrightarrow{h}\overrightarrow{h}}\overrightarrow{h_{t-1}}+b_{\overrightarrow{h}})
ht=H(Wxhxt+Whhht−1+bh)(1)
h
t
←
=
H
(
W
x
h
←
x
t
+
W
h
←
h
←
h
t
+
1
←
+
b
h
←
)
\overleftarrow{h_t}=H(W_{x\overleftarrow{h}}x_t+W_{\overleftarrow{h}\overleftarrow{h}}\overleftarrow{h_{t+1}}+b_{\overleftarrow{h}})
ht=H(Wxhxt+Whhht+1+bh)(2)
y
t
=
W
h
→
y
h
t
→
+
W
h
←
y
h
t
←
+
b
y
y_t=W_{\overrightarrow{h}y}\overrightarrow{h_t}+W_{\overleftarrow{h}y}\overleftarrow{h_t}+b_y
yt=Whyht+Whyht+by (3)
数据集
数据集介绍
本文使用了NLS-KDD数据集,是用来评估入侵检测系统的标准数据集之一,是著名的KDD99数据集的修订版本.该数据集由四个子数据集组成:KDDTest+、KDDTest-21、KDDTrain+、KDDTrain+_20Percent.其中KDDTest-21和KDDTrain+_20Percent是KDDTrain+和KDDTest+的子集.数据集每条记录包含 43 个特征,如表1所示.其中41个特征指的是流量输入本身,最后两个是标签(正常或攻击)和分数(流量输入本身的严重性).
数据集下载地址: NLS-KDD

该数据集中包括了4种不同类型的攻击:拒绝服务(Denial of service,DoS)、探测(probe)、用户到根(U2R) 和远程到本地(R2L).同时每种攻击又包含了多种子类型,具体如表2所示。

数据集中数据分布情况如表3所示。

数据预处理
由上面的数据集描述可知,NLS-KDD数据集中有三个非数值型的特征,分别是协议类型、服务和标志.但是由于本文所使用的深度学习模型BiDLSTM和LSTM只能处理数值型数据,因此在进行模型训练之前必须进行数据预处理:将非数值型数据转化为数值型数据.特征缩放可以确保数据集处于标准化形式,本文使用了sklearn库进行数据归一化,使用 Min–Max 缩放将每个特征的值缩放到 (0, 1) 范围内。
最小-最大特征缩放的表达式如下:
z
′
=
X
−
X
m
i
n
X
m
a
x
−
X
m
i
n
z^{'} =\frac{X-X_{min}}{X_{max}-X_{min}}
z′=Xmax−XminX−Xmin
评价指标
为了评估模型的性能,本文计算了准确性、召回率、特异性和误报率、精度和 F1分数。每个指标的解释和推导如下:
A
C
C
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
ACC=\frac{TP+TN}{TP+TN+FP+FN}
ACC=TP+TN+FP+FNTP+TN
A
C
C
=
T
P
T
P
+
F
N
ACC=\frac{TP}{TP+FN}
ACC=TP+FNTP
A
C
C
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
ACC=\frac{TP+TN}{TP+TN+FP+FN}
ACC=TP+TN+FP+FNTP+TN
实验与结果分析
实验设置
1、自适应矩估计 (Adam) 算法是用于更新模型权重的优化器,学习率为 0.001。
2、使用的损失函数是二元分类的二元交叉熵和多类分类的分类交叉熵。
3、对各层应用 0.2 的 dropout 概率。
4.使用分层 K 折交叉验证方法(K 设置为 10)进行验证。
K 折交叉验证:既可以解决数据集的数据量不够大问题,也可以解决参数调优的问题,防止过拟合。其详细使用参考:K折交叉验证
实验结果分析
二分类实验
在本实验中,作者使用 NSL-KDD 数据集中的所有 41 个特征对传统 LSTM 和双向 LSTM 进行二元分类(异常和正常)。作者使用混淆矩阵来评估,实验结果如下:
图 5a 和 b 中的混淆矩阵描述传统LSTM模型的性能。相比之下,图6a和b中的混淆矩阵用于描述双向LSTM模型的性能。
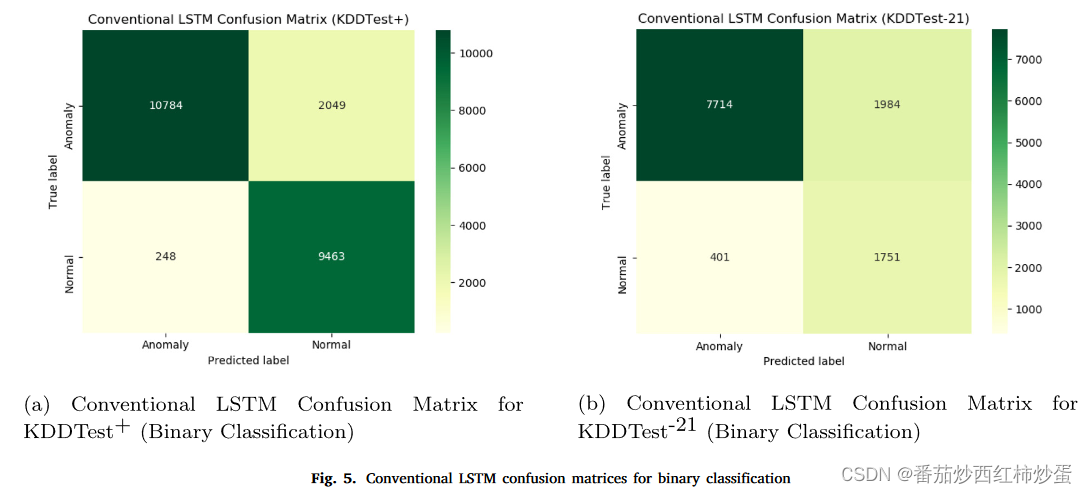
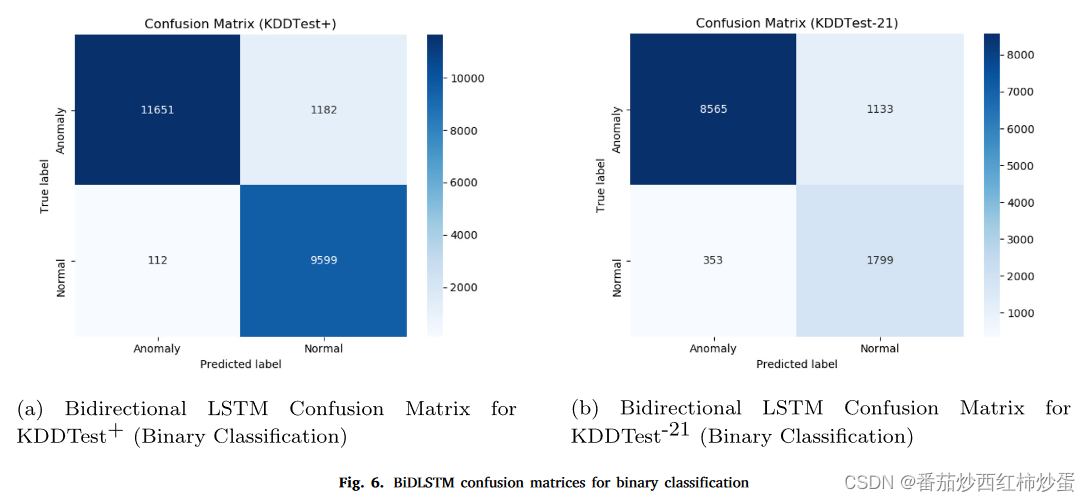
表 5 和表 6 总结了传统 LSTM 和 BiDLSTM 获得的性能结果,如下:

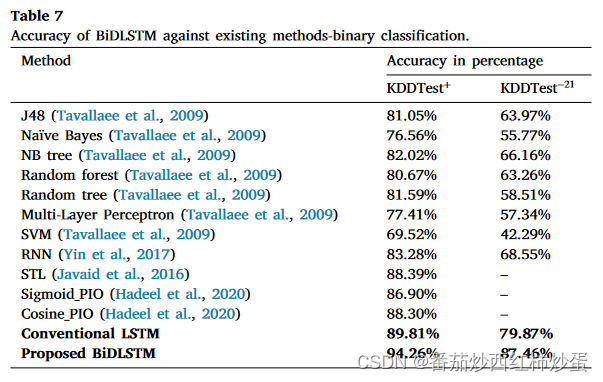
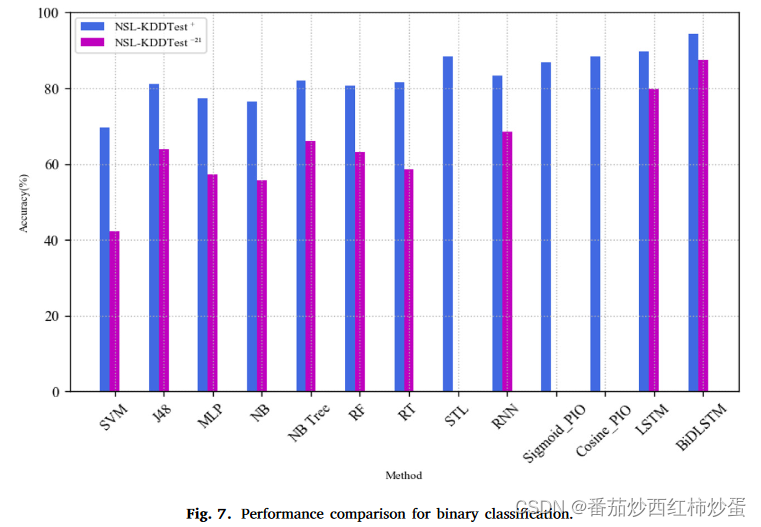
如表 7 和图 7 所示,本文将性能与 Hadeel 等人提到的其他技术进行了比较。
结果分析
1、BiDLSTM 分类器在基于准确度、精确度、召回率、特异性和 F 分数值的网络异常检测方面具有优越性;
2、从图7可以看出,所提出的BiDLSTMKDDTest+ 和 KDDTest−21 数据集上分别获得了 99.95% 的训练准确率、94.26% 的测试准确率和 87.46% 的测试准确率,优于其他现有模型获得的结果;
3、从表7可以看出,BiDLSTM 模型在 KDDTest+ 上将传统 LSTM 模型的检测精度提高了 4.45%,在 KDDTest−21 数据集上将检测精度提高了 7.59%。此外,与其他模型相比,它在 KDDTest+ 和 KDDTest−21 数据集上分别获得了 99.05% 和 96.04% 的更高准确率。而且BiDLSTM 模型获得了更好的 F1分数,同时降低了误报率。
多分类实验
作者使用所有 41 个特征训练的 5 类(Normal、DoS、Probe、R2L 和 U2R)分类器进行实验。
图 8a 和 b 描述了用于评估传统 LSTM 的混淆矩阵。相比之下,图 9a 和 b 描述了用于评估 BiDLSTM 的矩阵。
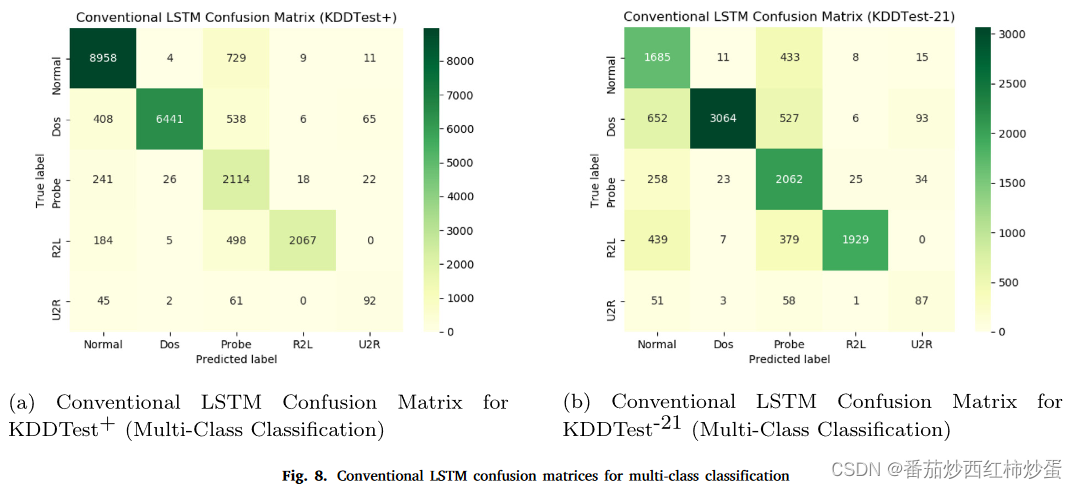
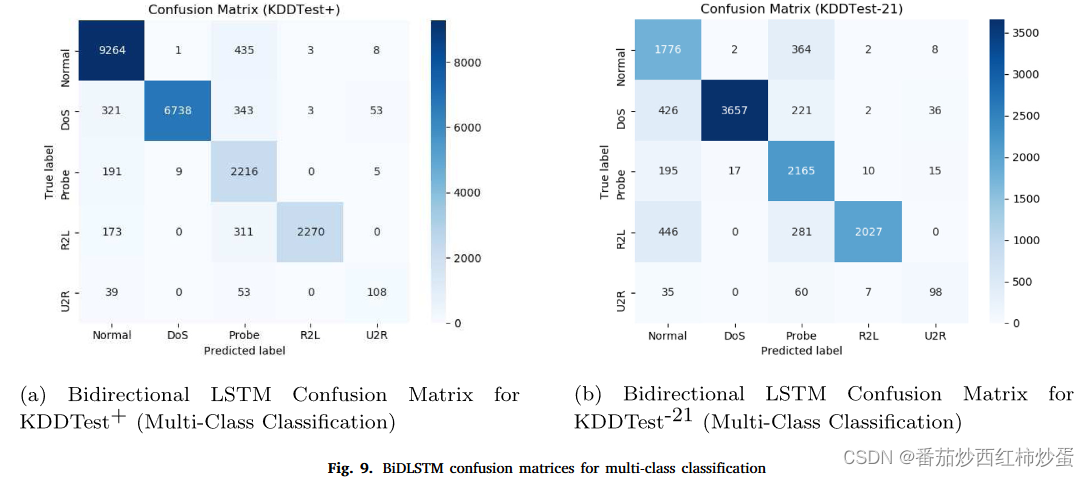
表8和表9总结了传统LSTM和BiLSTM模型的检测效果:
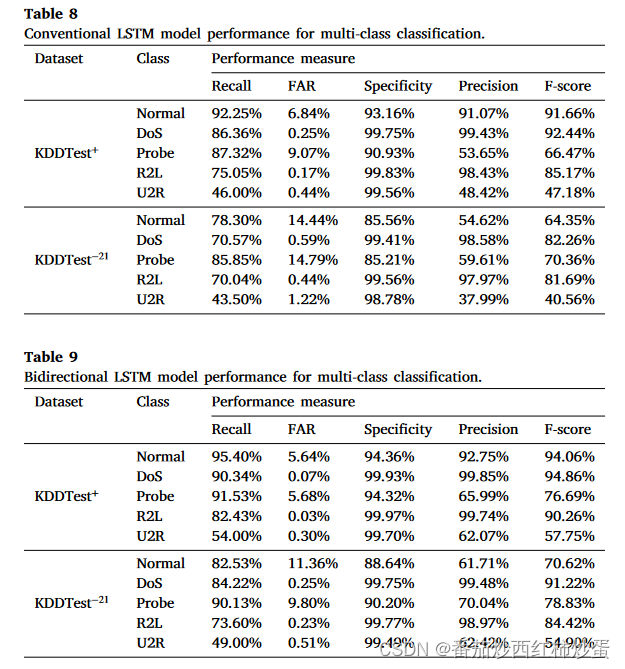
表10和表11分别展示了使用KDDTest−21和KDDTest+数据集时,本文提出的模型与最新的入侵检测模型的性能对比:
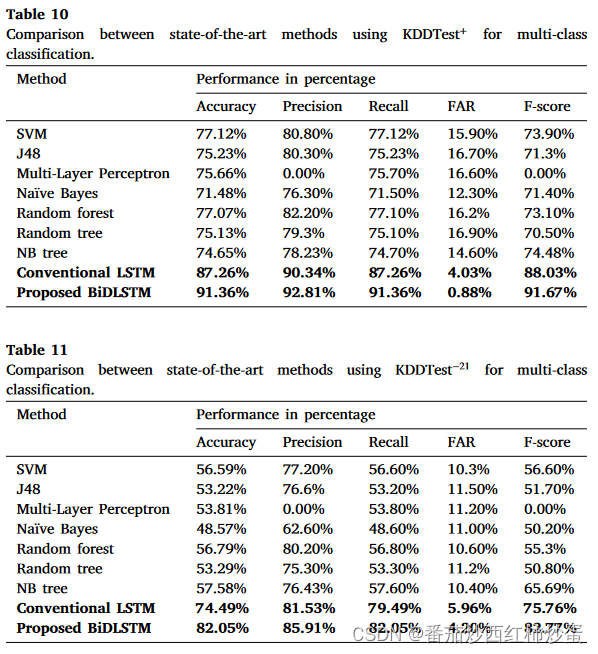
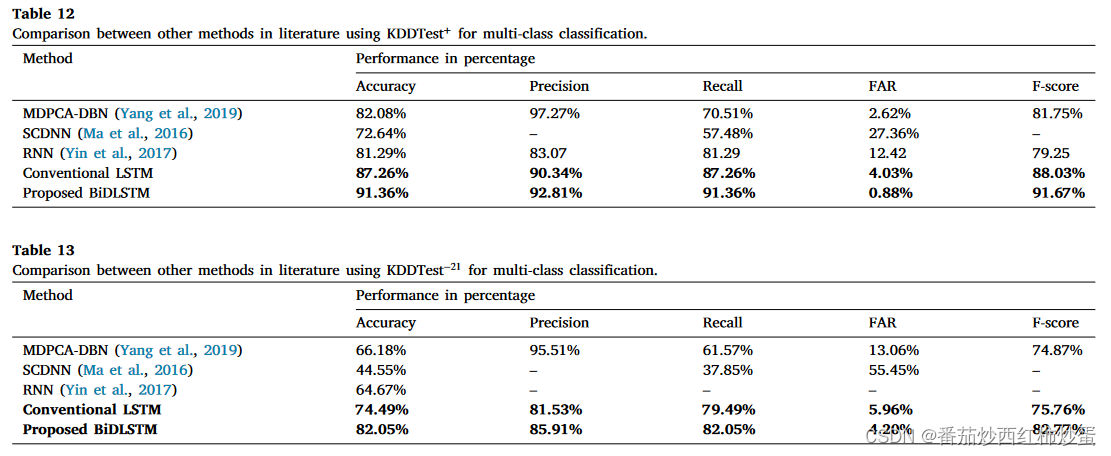
表12和表13展示了BiDLSTM 方法与同一数据集上的一些已发布方法(即 RNN-IDS、SCDNN 和 MDPCA-DBN)的比较结果:
结果分析
1、与二元分类相反,两种模型为多类分类提供较低的检测精度;
2、从表 10 和表 11 可以看出,所提出的 BiDLSTM 不仅提高了传统 LSTM 的性能,而且还比最先进的 IDS 模型具有更高的检测精度;
1)与现有的 IDS 模型相比,所提出的 BiDLSTM 模型在 KDDTest+ 和 KDDTest−21 上分别实现了 91.36% 和 82.05% 的更高准确率;
2)在引发误报方面,与其他算法相比,所提出的模型在 KDDTest+ 中实现了 0.88% 的误报率,在 KDDTest−21 中实现了 4.20% 的误报率。
3、如表 12 和表 13 所示,BiDLSTM 的性能也优于一些最近发布的模型:
与 MDPCA-DBN 相比,BiDLSTM 在两个测试数据集上获得了更好的召回值,分别为 91.36% 和 82.05%。
计算复杂度和运行时间分析
计算复杂度
作者分析了所提出的方法在算法设计构建块方面的总体时间计算复杂度;输入特征缩放、K 折交叉验证和 BiDLSTM。
1)输入特征缩放时间复杂度为:O(ZS),其中 Z 是特征数量,S 是特征尺寸;
2)K折交叉验证时间复杂度为:O(Kn),其中 K 表示算法遍历数据的次数,n 是样本大小。
3)BiDLSTM 在正向训练一个 LSTM,在反向训练另一个 LSTM。因此BiDLSTM的时间复杂度由两部分组成:前向训练一个 LSTM 所需的时间计算如下: O((QH) + (QMc Bs) + (HUf ) + (Mc BsUf )),其中,Mc是存储单元块的数量,Bs表示单元块的大小(Bs>0),Q表示输出单元的数量,H表示隐藏单元的数量。 Uf 表示正向连接到隐藏单元、门和存储单元的单元数量。反方向也需要同样的时间。因此,BiDLSTM 模型的总时间复杂度计算如下:O(2[(QH) + (QMc Bs) + (HUf ) + (Mc BsUf )]) = O(W )。其中 W 是网络中优化的权重总数。因此,该方法的总体时间复杂度为O(ZS + Kn + W )。
训练时间分析
图 11 描述了 NSL-KDDTrain+ 数据集上所有方法的训练时间。
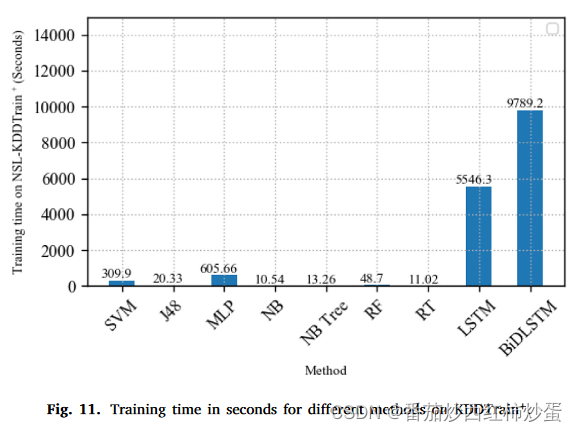
结论: 可以观察到 BiDLSTM 的训练时间最长,其次是 LSTM 模型。这是因为BiDLSTM是双向的LSTM模型。
对于本分析中使用的所有模型,NSL-KDDTest+ 和 NSL-KDDTest−21 数据集的评估时间如图 12a 和 b 所示。
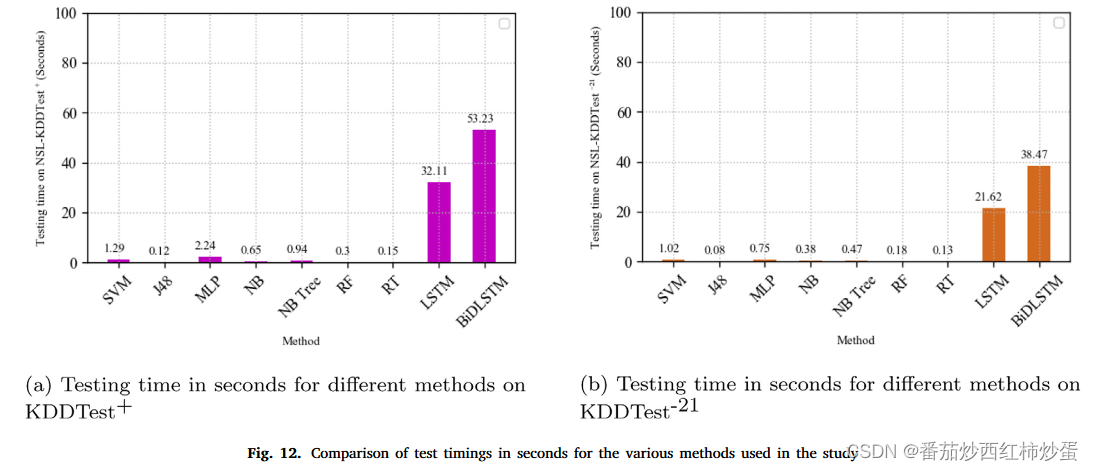
结论: 从图中可以看出,BiDLSTM需要的检测时间也是最长,理由同上。
局限性
本文所提出的BiDLSTM模型在识别不同攻击类型方面提供了更好的检测准确率。然而,本方法比传统的LSTM模型和其他机器学习模型具有更高的复杂度并且需要更多的训练时间。
结论与展望
结论
1、本文提出了应用深度学习方法(即双向长短期记忆)来检测网络入侵。所提出的方法表现出良好的性能并取得了准确的结果。
2、BiDLSTM模型获得了比传统LSTM模型和文献中其他现有入侵检测模型更高的准确率、召回率和F-score。
展望
未来,我们计划开发和探索集成系统的性能,将一些最先进的特征选择方法与传统的 LSTM 和 BiDLSTM 模型相集成。

















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









