








本文对论文:Heterogeneous Graph Attention Network for Malicious Domain Detection进行简要总结并对其进行了复现,提供复现代码。
背景介绍
- DNS:作为互联网的基础,DNS 提供了域和 IP 地址之间的映射关系,以识别网络中的服务、设备或其他资源。同时,DNS也被攻击者滥用,如网络钓鱼、垃圾邮件、僵尸网络等,造成严重的经济损失。因此,如何有效检测恶意域名成为网络安全研究的热点。
- 恶意域名检测方法
| 方法分类 | 优点 | 缺点 |
|---|---|---|
| 基于黑名单 | 实现简单 | 维护困难,且极易被绕过 |
| 基于域名字符特征的方法 | 有效应对Domain-Flux, Fast-Flux, Double-Flux等躲避技术 | 手工提取特征难 |
| 深度学习方法 | 自动提取特征 | 易被攻击者的精心设计绕过 |
| 基于域名关联特征的方法 | 特征难以被绕过,有效检测 | ~ |
- 本文贡献:
- 提出了一种名为 HANDom 的新型恶意域检测系统,它可以自适应地初始化域节点,学习域的全面且细粒度的表示并捕获域之间的隐式关系
- 设计了一种分层注意力机制,包括节点级注意力和元路径级注意力,同时考虑不同邻居的重要性和不同元路径的重要性。
- 在真实世界 DNS 数据集上的实验结果表明,提出的方法优于最先进的方法,并且适用于标记较少的数据场景。
系统设计
本论文的系统整体设计框架如图所示:
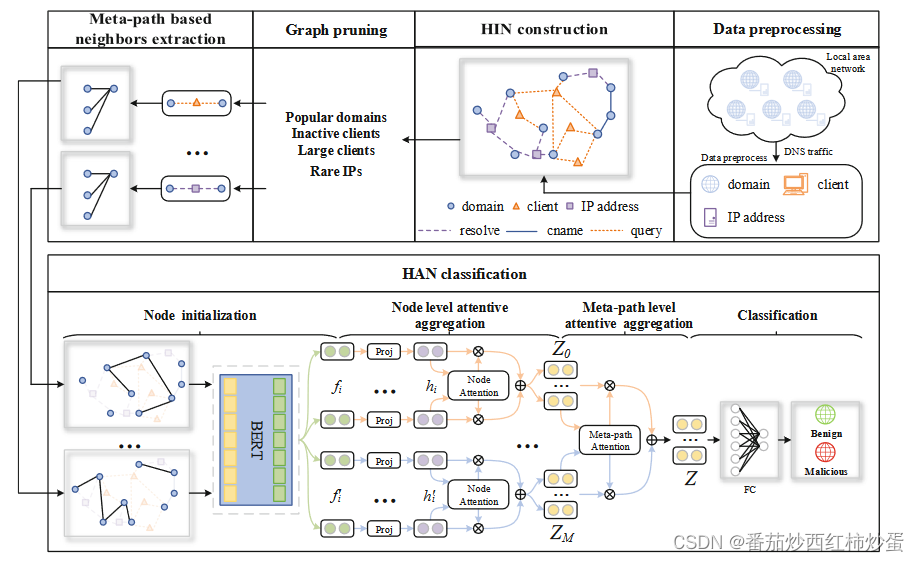
- 异构信息网络(HIN)构建
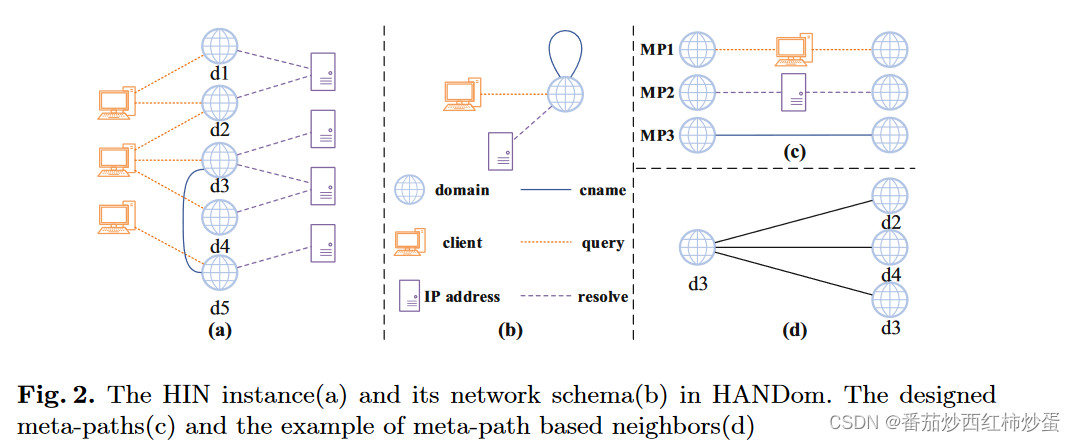
(1)异构图:节点类别的数量加边的类别的数量大于等于2,也就是包含不同类型节点和连接的图。
(2)本文使用域名、客户端、IP 地址三类节点以及它们之间的三种关系:查询、解析、cname构建异构图,构建的HIN如图所示:
- 图修剪
由于本文构建的异构图非常庞大,直接进行处理是非常耗时的,因此对一些噪声节点进行剪枝有利于节约资源,提高训练速度。本文使用的剪枝规则如下:
- 热门域名:大部分客户端查询的域通常是良性的。否则,将导致容易被检测到的重大攻击事件。因此删除了超过 35% 的客户端查询的域。
- 不活跃的客户端:查询几个域的客户端对于挖掘图结构信息是没有用的。因此删除查询少于4个域的客户端。
- 大客户:查询大量域的客户端更有可能是转发器或代理。为了减少噪音删除查询超过 100个域的客户端。
- 稀有IP:映射到一个域的IP地址对挖掘图结构信息影响不大。因此删除它们。
- 基于元路径的邻居提取
为了提取域名之间的关联特征,本文设计了三个元路径以获得域件关联信息。元路径定义如下:
- 元路径1:受到相同攻击者攻击的客户端倾向于查询相似的恶意域集,而正常客户端通常查询良性域。
- 元路径2:解析到相同 IP 地址的域更有可能属于同一所有者的观察结果。因此,它们往往是同一类域,即恶意域或良性域。
- 元路径3:如果两个域名在同一个cname记录中,则它们属于同一类。
- 域名节点特征聚合
- 域名节点初始化
本文使用自然语言处理中表现优秀的Bert模型对域名字符串进行初始化,更好地捕获领域的字符分布模式。
f i = B E R T ( T i ) f_i =BERT(T_i) fi=BERT(Ti)
其中, T i T_i Ti是域节点i的token序列, f i ∈ R x f_i \in R_x fi∈Rx是域节点i的初始嵌入, x x x是域初始嵌入的维度大小。 - 节点级关注聚合
为了捕获元路径中不同邻居的影响,本文使用节点级注意力来学习邻居的重要性并聚合邻居的信息以获得域节点表示。具体步骤如下:
(1)首先,因为直接处理HIN是非常复杂的,本文基于元路径将构建的HIN简化为几个同构子图,然后进行节点聚合。
(2)其次设计一个变换矩阵将域节点嵌入映射到特定的特征空间:
h i = W h ⋅ f i h_i = W_h · f_i hi=Wh⋅fi
其中, h i ∈ R H h_i \in R^H hi∈RH 是节点 i i i 的投影嵌入, H H H 是投影嵌入的维度大小, W h ∈ R H × x W_h \in R^{H×x} Wh∈RH×x 是变换矩阵。
(3)然后计算元路径 P P P中目标节点 i i i 与其邻居$ j$ 之间的相似度 e i j P e_{ij}^P eijP:
e i j P = a t t n o d e ( h i , h j ; P ) = σ ( a P T ⋅ [ h i ∣ ∣ h j ] ) e_{ij}^P = att_{node} (h_i,h_j ; P) = σ (a_P^T · {[h_i||h_j ]}) eijP=attnode(hi,hj;P)=σ(aPT⋅[hi∣∣hj])
其中, a t t n o d e att_{node} attnode 是节点级注意力, a P ∈ R 2 H a_P ∈ R^{2H} aP∈R2H是参数矩阵,它在每个元路径下共享参数,P 是第 P 个元路径,T 表示转置,σ 是激活函数,||表示连接操作。
(4)接着通过对相似度进行归一化得到权重 α i j P α_{ij}^P αijP:
α i j P = s o f t m a x ( e i j P ) = e x p ( σ ( a P T ⋅ [ h i ∣ ∣ h j ] ) ) ∑ k ∈ N i P e x p ( σ ( a P T ⋅ [ h i ∣ ∣ h k ] ) ) α_{ij}^P = softmax (e_{ij}^P )=\frac{exp (σ (a_P^T · [h_i||h_j]))} {\sum k∈N_i^P exp (σ (a_P^T · [h_i||h_k]))} αijP=softmax(eijP)=∑k∈NiPexp(σ(aPT⋅[hi∣∣hk]))exp(σ(aPT⋅[hi∣∣hj]))
(5)最后将邻居的投影嵌入与相应的权重聚合起来以获得节点 i 的表示:
z i P = σ ( ∑ j ∈ N i P α i j P ⋅ h j ) z_i^P=σ( \sum_{j \in N_i^P} α_{ij}^P·h_j) ziP=σ(∑j∈NiPαijP⋅hj)
其中 z i P ∈ R H z_i^P∈ R^H ziP∈RH 是元路径 P 中节点 i 的表示。
(6)为了减少训练过程中图数据异构性带来的高方差,本文将节点级注意力扩展到多头,重复节点级注意力聚合 K 次并连接嵌入:
z i P = ∥ k = 1 K σ ( ∑ j ∈ N i P α i j P ⋅ h j ) z_i^P=\rVert _{k=1}^Kσ( \sum_{j \in N_i^P} α_{ij}^P·h_j) ziP=∥k=1Kσ(∑j∈NiPαijP⋅hj)
其中 z i P ∈ Z P z_i^P∈ Z_P ziP∈ZP, Z P Z_P ZP 是元路径P 下所有节点的聚合表示的集合。 - 元路径级关注聚合
为了学习更全面的领域节点表示,本文使用元路径级别的注意力自动将权重分配给元路径。
其步骤如下:
(1)通过聚合表示和元路径注意向量 d 之间的相似性来衡量元路径的重要性。此外,计算一条元路径下所有节点的平均相似度,并将其视为该元路径的重要性:
s P = a t t s e m a n t i c ( Z P , d ) = 1 ∣ V ∣ ∑ i ∈ V d T ⋅ t a n h ( W d ⋅ z i P + b ) s_P = att_{semantic} (Z_P ,d)= \frac1 {|V |} ∑ _{i∈V} ^{d^T} · tanh (W_d · z^P_ i + b) sP=attsemantic(ZP,d)=∣V∣1∑i∈VdT⋅tanh(Wd⋅ziP+b)
其中 a t t s e m a n t i c att_{semantic} attsemantic 是元路径注意力,计算元路径 P 的重要性 s P s_P sP, d ∈ R q d ∈ R^{q} d∈Rq 是元路径注意力向量,q 是元路径注意力向量的大小, W d ∈ R q × H W_d ∈ R^{q×H} Wd∈Rq×H 是权重矩阵,b 是偏差向量。
(2)然后计算元路径P的权重 β P β_P βP:
β P = s o f t m a x ( s P ) = e x p ( s P ) ∑ l = 0 M e x p ( s l ) β_P = softmax (s_P )= \frac{exp (s_P )}{ ∑^M _{l=0} exp (s_l)} βP=softmax(sP)=∑l=0Mexp(sl)exp(sP)
(3)最后,将这些元路径级别的嵌入与相应的元路径权重进行聚合,以获得最终的域表示:
Z = ∑ P = 0 M β P ⋅ Z P Z= \sum ^M_{P =0} β_P · Z_P Z=∑P=0MβP⋅ZP
其中 Z = z 1 ′ , z 2 ′ , … , z ∣ V ∣ ′ Z = {z^′ _1,z^′ _2, … ,z^′_{ |V|}} Z=z1′,z2′,…,z∣V∣′ 是域表示的集合, z i ′ ∈ R H z^′_ i ∈ R^H zi′∈RH 。
- 节点分类
通过域表示,将恶意域检测简化为二元分类任务。最终的域表示 Z 被馈送到完全连接的网络以对域进行分类。然后在半监督范例中训练 HANDom,并最小化真实标签和恶意域检测预测之间所有标记节点的交叉熵损失:
y i ^ = s o f t m a x ( σ ( W o ⋅ z i ′ + b ) ) \hat{y_i }= softmax ( σ ( W_o · z^′_ i +b )) yi^=softmax(σ(Wo⋅zi′+b))
L = − ∑ i = 1 ∣ V L ∣ ( y i , 0 ⋅ l o g y i , 0 ^ + y i , 1 ⋅ l o g y ^ i , 1 ) L=− ∑^{|VL |} _{i=1} (y_{i,0} · log \hat{y_{i,0}} + y_{i,1} · log \hat{y}_i,1) L=−∑i=1∣VL∣(yi,0⋅logyi,0^+yi,1⋅logy^i,1)
其中KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: \hat{y_i| ∈ R^2 是第 i 个节点的预测, W o ∈ R 2 × H W_o ∈ R^{2×H} Wo∈R2×H 是转移矩阵, y i y_i yi 是第 i 个节点的真实情况, ∣ V L ∣ |VL| ∣VL∣是标记节点的大小。
相关实验及结果分析
- 数据集收集
- DNS流量收集:本文作者收集了某大学2020年8月1日至2020年8月14日两周内的真实DNS流量并从中提取了包括域、客户端、IP 地址及其关系信息。最后构建了包含 200,014 个域、5,670 个客户端、58,657 个 IP 地址以及它们之间的边缘的 DNS HIN。
- 数据集标记:通过Alexa 前 100 万个列表和VirusTotal,最终标记了 36,489 个良性域和 11,747 个恶意域,并将它们用作最终的标记数据集。实验数据集的描述如表所示:

- 作者将标记数据集以7:2:1的比例随机分为训练集、验证集和测试集,并通过10倍交叉验证得到平均结果。
- 实验结果
- 与基线的比较,作者将本文使用的节点嵌入方法与DeepWalk、Metapath2vec、GCN 、GAT四种基线进行了比较,结果如下:
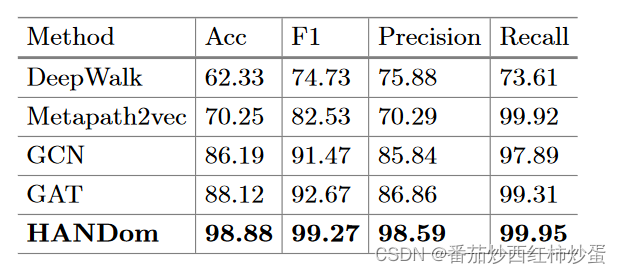
本文方法之所以表现好的原因是:
(1) 使用了节点属性来丰富节点表示
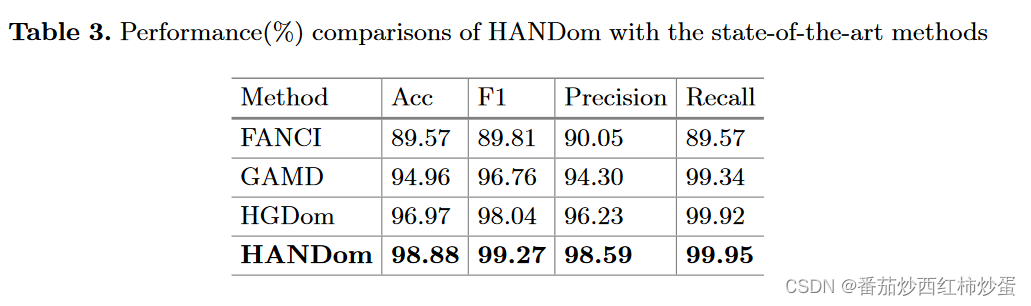
(2)元路径级注意力可以捕获异构图中的复杂语义信息 - 与最先进方法的比较,作者将提出的方法与FANCI、GAMD、HGDom三种最先进的恶意域名检测方法进行了比较,结果如下:
总结
本文通过将 DNS 场景建模为由域、客户端、IP 地址及其关联组成的异构信息网络。然后,结合考虑不同邻居的重要性和不同元路径的重要性以捕获多粒度的关键信息,可以有效区分恶意域和良性域。
代码复现
- 本文使用的数据集是自己收集的,我在复现本工作时使用的是自己构建的数据集,因此本复现代码仅公布方法,大家可根据自己使用的数据集进行相应的复用与修改
- 本代码是在HAN基础上进行的复现,且是在完全标记数据集下进行的,与原文实验不完全一致,提供引入Bert的utils.py代码,其他与HAN一致
import datetime
import errno
import os
import pickle
import random
from pprint import pprint
import pandas as pd
import dgl
from transformers import BertTokenizer, BertModel
import numpy as np
import torch
from dgl.data.utils import _get_dgl_url, download, get_download_dir
from scipy import io as sio, sparse
def set_random_seed(seed=0):
"""Set random seed.
Parameters
----------
seed : int
Random seed to use
"""
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
def mkdir_p(path, log=True):
"""Create a directory for the specified path.
Parameters
----------
path : str
Path name
log : bool
Whether to print result for directory creation
"""
try:
os.makedirs(path)
if log:
print("Created directory {}".format(path))
except OSError as exc:
if exc.errno == errno.EEXIST and os.path.isdir(path) and log:
print("Directory {} already exists.".format(path))
else:
raise
def get_date_postfix():
"""Get a date based postfix for directory name.
Returns
-------
post_fix : str
"""
dt = datetime.datetime.now()
post_fix = "{}_{:02d}-{:02d}-{:02d}".format(
dt.date(), dt.hour, dt.minute, dt.second
)
return post_fix
def setup_log_dir(args, sampling=False):
"""Name and create directory for logging.
Parameters
----------
args : dict
Configuration
Returns
-------
log_dir : str
Path for logging directory
sampling : bool
Whether we are using sampling based training
"""
date_postfix = get_date_postfix()
log_dir = os.path.join(
args["log_dir"], "{}_{}".format(args["dataset"], date_postfix)
)
if sampling:
log_dir = log_dir + "_sampling"
mkdir_p(log_dir)
return log_dir
# The configuration below is from the paper.
default_configure = {
"lr": 0.001, # Learning rate
"num_heads": [8], # Number of attention heads for node-level attention
"hidden_units": 8,
"dropout": 0.6,
"weight_decay": 0.001,
"num_epochs": 80,
"patience": 100,
}
sampling_configure = {"batch_size": 50}
def setup(args):
args.update(default_configure)
set_random_seed(args["seed"])
args["dataset"] = "ACMRaw" if args["hetero"] else "ACM"
args["device"] = "cpu"#"cuda:0" if torch.cuda.is_available() else "cpu"
args["log_dir"] = setup_log_dir(args)
return args
def setup_for_sampling(args):
args.update(default_configure)
args.update(sampling_configure)
set_random_seed()
args["device"] = "cuda:0" if torch.cuda.is_available() else "cpu"
args["log_dir"] = setup_log_dir(args, sampling=True)
return args
def get_binary_mask(total_size, indices):#设置指定位置为1
mask = torch.zeros(total_size)
mask[indices] = 1
return mask.byte()
def load_acm(remove_self_loop):
url = "dataset/ACM3025.pkl"
data_path = get_download_dir() + "/ACM3025.pkl"
download(_get_dgl_url(url), path=data_path)
with open(data_path, "rb") as f:
data = pickle.load(f)
labels, features = (#在这里,data 是一个字典,其中包含两个键值对,一个是 "label",另一个是 "feature"。代码的目的是将这两个稀疏矩阵转换为 PyTorch 张量。
torch.from_numpy(data["label"].todense()).long(),
torch.from_numpy(data["feature"].todense()).float(),
)
#获取label向量
num_classes = labels.shape[1]
labels = labels.nonzero()[:, 1]
if remove_self_loop:
num_nodes = data["label"].shape[0]
data["PAP"] = sparse.csr_matrix(data["PAP"] - np.eye(num_nodes))#单位矩阵
data["PLP"] = sparse.csr_matrix(data["PLP"] - np.eye(num_nodes))
# Adjacency matrices for meta path based neighbors
# (Mufei): I verified both of them are binary adjacency matrices with self loops
author_g = dgl.from_scipy(data["PAP"])#基于元路径的邻接矩阵
subject_g = dgl.from_scipy(data["PLP"])
gs = [author_g, subject_g]
train_idx = torch.from_numpy(data["train_idx"]).long().squeeze(0)#将 "train_idx" 数据从NumPy数组转换为PyTorch长整数张量 (long()),然后使用 squeeze(0) 方法去掉可能存在的多余的维度,"train_idx" 包含用于训练的示例的索引
val_idx = torch.from_numpy(data["val_idx"]).long().squeeze(0)
test_idx = torch.from_numpy(data["test_idx"]).long().squeeze(0)
num_nodes = author_g.num_nodes()
train_mask = get_binary_mask(num_nodes, train_idx)#行向量
val_mask = get_binary_mask(num_nodes, val_idx)
test_mask = get_binary_mask(num_nodes, test_idx)
print("dataset loaded")
pprint(
{
"dataset": "ACM",
"train": train_mask.sum().item() / num_nodes,
"val": val_mask.sum().item() / num_nodes,
"test": test_mask.sum().item() / num_nodes,
}
)
return (
gs,
features,
labels,
num_classes,
train_idx,
val_idx,
test_idx,
train_mask,
val_mask,
test_mask,
)
def get_keys_by_value(d, value):
return [key for key, val in d.items() if val == value]
def load_acm_raw(remove_self_loop):
assert not remove_self_loop
domain_to_numeric = {}
#读取数据集
domain_df = pd.read_csv('/HAN_pytorch_bert/data/domain.csv')#数据集文件地址
domains=domain_df['domain']
labels=domain_df['label'].tolist()
labels = [x - 1 for x in labels]
edge_df = pd.DataFrame(columns=['src_node', 'dst_node', 'edge_type'])
#读取节点数字映射文件,因为dgl库只能处理数字类型
file1="/HAN_pytorch_bert/data/domain_to_numeric.pkl"
file2="/HAN_pytorch_bert/data/client_to_numeric.pkl"
file3="/HAN_pytorch_bert/data/ip_to_numeric.pkl"
# 使用pickl读取字典
with open(file1, 'rb') as file:
domain_to_numeric = pickle.load(file)
with open(file2, 'rb') as file:
client_to_numeric = pickle.load(file)
with open(file3, 'rb') as file:
ip_to_numeric = pickle.load(file)
#读取边文件
edge_df=pd.read_csv("HAN_pytorch_bert/data/edges.csv",header=None)
query_edge0,resolve_edge0,cname_edge0=[],[],[]
query_edge1,resolve_edge1,cname_edge1=[],[],[]
query_value='query'
resolve_value='resolve'
cname_value='CNAME'
for index,row in edge_df.iterrows():
#print(row)
if row[2]==query_value:
query_edge0.append(client_to_numeric[row[0]])
#print(client_to_numeric[row[0]])
query_edge1.append(domain_to_numeric[row[1]])
if row[2]==resolve_value:
resolve_edge0.append(domain_to_numeric[row[0]])
resolve_edge1.append(ip_to_numeric[row[1]])
if row[2]==cname_value:
cname_edge0.append(domain_to_numeric[row[0]])
cname_edge1.append(domain_to_numeric[row[1]])
G = dgl.heterograph({
('client', 'query', 'domain'): (query_edge0,query_edge1), # 添加 'query' 类型的边
('domain', 'queried', 'client'): (query_edge1,query_edge0), # 添加 'queried' 类型的边
('domain', 'resolve', 'ip'): (resolve_edge0,resolve_edge1), # 添加 'resolve' 类型的边
('ip', 'resolved', 'domain'): (resolve_edge1,resolve_edge0), # 添加 'resolved' 类型的边
('domain', 'cname', 'domain'): (cname_edge0,cname_edge1), # 添加 'cname' 类型的边
('domain', 'cname', 'domain'): (cname_edge1,cname_edge0),
})
print(G)
# 图修剪
# 1. 删除超过35%的客户端查询的域名
client_num=G.number_of_nodes('client')
# 找到要删除的域名
threshold_percentage = 0.35
threshold_count = threshold_percentage * client_num
# 统计每个域名被查询的次数
domain_query_counts = G.in_degrees(etype='query')
domain_query_counts = domain_query_counts.numpy()
# 找到要删除的域名
domains_to_remove = [node_id for node_id, count in enumerate(domain_query_counts) if count > threshold_count]
new_labels = []
for i, element in enumerate(labels):
if i not in domains_to_remove:
new_labels.append(element)
domain_to_numeric = {key: value for key, value in domain_to_numeric.items() if value not in domains_to_remove}
# 删除指定的域名节点及相关边
G.remove_nodes(domains_to_remove, ntype='domain') # 指定节点类型为'domain'
num_specified_nodes = G.number_of_nodes('domain')
# 2. 删除查询域名少于4个或大于100个的客户端
# 统计每个客户端查询的域名数量
client_query_counts = G.out_degrees(etype='query')
client_query_counts=client_query_counts.numpy()
# 找到要删除的客户端
clients_to_remove = [node_id for node_id, count in enumerate(client_query_counts) if count < 4 or count > 100]
# 删除指定的客户端节点及相关边
G.remove_nodes(clients_to_remove, ntype='client') # 指定节点类型为'client'
# 4. 删除被一个域名解析到的IP地址
domain_resolved_counts = G.in_degrees(etype='resolve')
domain_resolved_counts=domain_resolved_counts.numpy()
# 找到要删除的IP地址
ips_to_remove = [node_id for node_id,count in enumerate(domain_resolved_counts) if count == 1]
# 删除指定的IP地址节点及相关边
G.remove_nodes(ips_to_remove, ntype='ip') # 指定节点类型为'ip'
# 定义BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained("/home/bert-domain")#Bert模型地址
bert_model = BertModel.from_pretrained("/home/bert-domain")
domain_names=domain_df.unique()
# 为每个域名生成BERT嵌入
domain_embeddings = {}
h = torch.zeros(len(new_labels),768)
i=0
for key, node_id in domain_to_numeric.items():
# 分词并添加特殊标记
tokens = tokenizer.tokenize(key)
inputs = tokenizer.encode(" ".join(tokens), return_tensors="pt")
# 获取BERT模型的输出
with torch.no_grad():
outputs = bert_model(inputs)
# 获取域名节点的初始嵌入表示
initial_embedding = outputs.last_hidden_state.mean(dim=1).squeeze().numpy()
values = torch.tensor(initial_embedding)
h[i, :] = values
# 将ID和嵌入添加到字典中
domain_embeddings[node_id] = initial_embedding
i=i+1
features = torch.FloatTensor(h)
labels = torch.LongTensor(new_labels)
num_classes = 2
import numpy as np
# 假设 N 为节点总数
N = labels.shape[0]
# 计算各子集数量
train_count = int(0.75 * N)
val_count = int(0.25 * N)
# 生成随机索引
all_indices = np.arange(N)
np.random.shuffle(all_indices)
# 划分数据集
train_idx = all_indices[:train_count]
val_idx = all_indices[train_count:]
num_nodes = N
train_mask = get_binary_mask(num_nodes, train_idx)
val_mask = get_binary_mask(num_nodes, val_idx)
return (
G,
features,
labels,
num_classes,
train_idx,
val_idx
)
def load_data(dataset, remove_self_loop=False):
if dataset == "ACM":
return load_acm(remove_self_loop)
elif dataset == "ACMRaw":
return load_acm_raw(remove_self_loop)
else:
return NotImplementedError("Unsupported dataset {}".format(dataset))
class EarlyStopping(object):
def __init__(self, patience=10):
dt = datetime.datetime.now()
self.filename = "early_stop_{}_{:02d}-{:02d}-{:02d}.pth".format(
dt.date(), dt.hour, dt.minute, dt.second
)
self.patience = patience
self.counter = 0
self.best_acc = None
self.best_loss = None
self.early_stop = False
def step(self, loss, acc, model):
if self.best_loss is None:
self.best_acc = acc
self.best_loss = loss
self.save_checkpoint(model)
elif (loss > self.best_loss) and (acc < self.best_acc):
self.counter += 1
print(
f"EarlyStopping counter: {self.counter} out of {self.patience}"
)
if self.counter >= self.patience:
self.early_stop = True
else:
if (loss <= self.best_loss) and (acc >= self.best_acc):
self.save_checkpoint(model)
self.best_loss = np.min((loss, self.best_loss))
self.best_acc = np.max((acc, self.best_acc))
self.counter = 0
return self.early_stop
#两个方法分别用于保存和加载深度学习模型的检查点。检查点通常包含了模型的参数和训练过程中的状态信息,可以用于恢复模型的训练或用于后续的推理任务。
def save_checkpoint(self, model):
"""Saves model when validation loss decreases."""
torch.save(model.state_dict(), self.filename)
def load_checkpoint(self, model):
"""Load the latest checkpoint."""
model.load_state_dict(torch.load(self.filename))















 1335
1335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









