







朝闻道,夕死可矣
本文共计 86564字,估计阅读时长1小时
点击进入—>Thread源码万字逐行解析
文章目录
一锁
什么是锁?
在Lock接口出现前,Java通过synchronized关键字实现锁功能,
Java 5 新增了Lock接口(及其相关实现类)用来实现锁功能
它功能与synchronized类似,只是在使用时需要显示地获取和释放锁
它缺点是失去了隐式获取释放锁的便捷性,但拥有锁获取与释放的可操作性,可中断性,以及 超时获取锁等多种synchronized关键字不具备的同步特性
公平锁FairSync:
多个线程按照申请锁的顺序获取锁
非公平锁NonfairSync:
多个线程获取锁的顺序不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁,有可能造成优先级反转或者饥饿现象,但是非公平锁吞吐量大
ReentrantLock的默认构造是非公平锁,可以在构造中写true变成公平锁
Synchronized也是非公平锁,由于其并不像ReentrantLock是通过AQS的来实现线程调度,所以并没有任何办法使其变成公平锁。
可重入锁/递归锁
可重复递归调用的锁,同一线程外层函数获取锁后,内层递归函数仍然可以获取锁,并且不发生死锁(前提是同一个对象或者class)
也就是说:线程可以进入任何一个它已经拥有的锁所同步着的代码块
ReentrantLock和synchronized都是可重入锁
自旋锁
线程在获取锁的时候,如果锁被其他线程获取,那么该线程将循环等待,然后不断判断锁是否能够被成功获取,直到获取到锁才会退出循环.
优势:
减少线程上下文切换的消耗,线程不会阻塞
缺点:
循环循环cpu
独占锁
锁一次只能被一个线程持有,ReentrantLock和Synchronized都是独占锁
ReentrantWriteLock是独占锁
共享锁
锁可以被多个线程共有,
ReentrantReadLock的读锁是共享锁,
读锁的共享可保证并发读是非常高效的,但是读写和写写,写读都是互斥的
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁,对于ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。
并发容器类的加锁机制是基于粒度更小的分段锁,分段锁也是提升多并发程序性能的重要手段之一。
在并发程序中,串行操作是会降低可伸缩性,并且上下文切换也会减低性能。在锁上发生竞争时将通通导致这两种问题,使用独占锁时保护受限资源的时候,基本上是采用串行方式—-每次只能有一个线程能访问它。所以对于可伸缩性来说最大的威胁就是独占锁。
我们一般有三种方式降低锁的竞争程度:
1、减少锁的持有时间
2、降低锁的请求频率
3、使用带有协调机制的独占锁,这些机制允许更高的并发性。
在某些情况下我们可以将锁分解技术进一步扩展为一组独立对象上的锁进行分解,这成为分段锁。
其实说的简单一点就是:
容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
比如:在ConcurrentHashMap中使用了一个包含16个锁的数组,每个锁保护所有散列桶的1/16,其中第N个散列桶由第(N mod 16)个锁来保护。假设使用合理的散列算法使关键字能够均匀的分部,那么这大约能使对锁的请求减少到越来的1/16。也正是这项技术使得ConcurrentHashMap支持多达16个并发的写入线程。
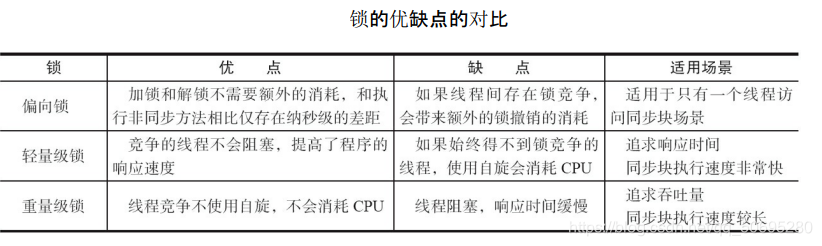
偏向锁 / 轻量级锁 / 重量级锁
1.6出现 的
锁的状态:
1.无锁状态
2.偏向锁状态
3.轻量级锁状态
4.重量级锁状态
锁的状态是通过对象监视器在对象头中的字段来表明的。
四种状态会随着竞争的情况逐渐升级,而且是不可逆的过程,即不可降级。锁不可逆是为了提高获取锁和释放锁的效率.
这四种状态都不是Java语言中的锁,而是Jvm为了提高锁的获取与释放效率而做的优化(使用synchronized时)。
偏向锁
偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动测试对象头的Mark Word获取锁。如果测试失败了,再测试以下Mark Word的偏向锁标识是否设置成1(表示当前是偏向锁):如果没用设置,则使用CAS竞争锁,如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程.
轻量级
轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
重量级锁
重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低
- 对于普通同步方法,锁是当前实例对象
- 对于静态同步方法,锁是当前类的Class对象
- 对于同步方法块,锁是Synchonized括号里配置的对象
二Java中13个原子操作类
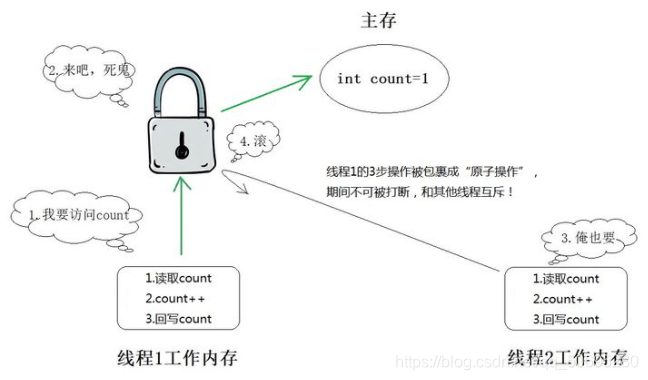
当程序更新一个变量时,如果多线程同时更新这个变量,可得到期望之外的值,比如
变量i=1,A线程更新i+1,B线程也更新i+1,经过两个线程操作后可能i不等于3而是等于2
因为A和B线程拿到的i都是1
通常我们使用synchronized来解决这个问题
而JDK.5后提供了java.util.concurrent.atomic包,这个包中的原子操作类提供了用法简单,性能高效,线程安全的更新一个变量的方式.
2.1原子更新基本类型
- AtomicBoolean原子更新布尔类型
- AtomicInteger原子更新整型
- AtomicLong原子更新长整型
这3个类提供的方法一模一样,这边解释一下AtomicInteger
- int addAndGet(int delta)以原子方式将输入的数值与实例中的值(AtomicInteger里的value)相加,并返回结果
- boolean compareAndSet(int expect,int update):如果输入的数值等于预期值,则以原子方式将该值设置为输入的值。
- int getAndIncrement():以原子方式将当前值加1,注意,这里返回的是自增前的值。
- int getAndSet(int newValue):以原子方式设置为newValue的值,并返回旧值。
- ·void lazySet(int newValue):最终会设置成newValue,使用lazySet设置值后,可能导致其他线程在之后的一小段时间内还是可以读到旧的值。关于这个方法可以查看并发编程网的一篇文章http://ifeve.com/how-does-atomiclong-lazyset-work/
一起来看一下:
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicIntegerTest {
static AtomicInteger ai = new AtomicInteger(1);
public static void main(String[] args) {
System.out.println(ai.getAndIncrement());
System.out.println(ai.get());
}
}
源码分析:
点击getAndIncrement()进入
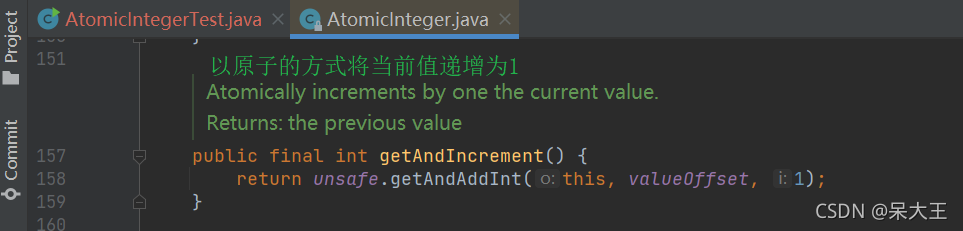
发现底层通过Unsafe类来实现
而AtomicBoolean,AtomicChar,AtomicFloat等先把值转换成整型
然后使用compareAndSwapInt方法进行比较并交换,这个是比较并交换的超链接:
点击进入 —> 比较并交换的CAQ思想
2.2原子更新数组
通过原子的方式更新数组里的元素,JUC包下有以下3个类
- AtomicIntegerArray 原子更新整型数组里的元素
- AtomicLongArray 原子更新长整型数组里的元素
- AtomicReferenceArray 原子更新引用类型数组里的元素
AtomicIntegerArray 类的 常用方法如下:
int addAndGet(int i, int delta)以原子方式将输入值与数组中索引 i 元素相加。
boolean compareAndSet(int i, int expectedValue, int newValue) 如果元素的当前值 == 预期值,则原子方式将数组位置 i 元素设置成 newValue的值
这3个类提供的方法几乎一样,这里仅以AtomicIntegerArray类讲解
import java.util.concurrent.atomic.AtomicIntegerArray;
public class AtomicIntegerArrayTest {
static int[] value = new int[]{1, 2};
static AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(value);
public static void main(String[] args) {
atomicIntegerArray.getAndSet(0,3);
System.out.println(atomicIntegerArray.get(0));
System.out.println(value[0]);
}
}
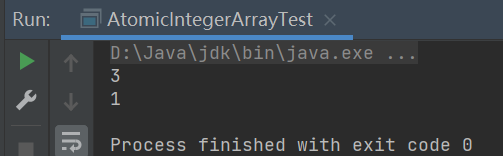
由于
AtomicIntegerArray会将当前数组复制一份
所以
即使AtomicIntegerArray将0索引位置元素修改为3,但是原来数组0索引位置元素依然没改变
2.3原子更新引用类型
原子更新基本类的AtomicInteger,只能更新一个变量,
如果要原子更新多个变量,使用这个原子更新引用类型提供的类,
JUC包下提供以下3个类
- AtomicReference: 原子更新引用类型
- AtomicReferenceFieldUpdater 原子更新引用类型里的字段
- AtomicMarkableReference 原子更新带有标记位的引用类型 可以更新布尔类型和引用类型
由于这三个类方法几乎一样,这里以AtomicReference为例子
import java.util.concurrent.atomic.AtomicReference;
public class AtomicReferenceText {
//将对象设置进AtomicReferenc中
public static AtomicReference<User> atomicUserRef = new AtomicReference<User>();
public static void main(String[] args) {
User user = new User("小明", 15);
atomicUserRef.set(user);
User updateUser = new User("小红", 22);
//进行原子操作
atomicUserRef.compareAndSet(user,updateUser);
System.out.println(atomicUserRef.get().getName());
System.out.println(atomicUserRef.get().getOld());
}
}
class User{
private String name;
private int old;
public User(String name, int old) {
this.name = name;
this.old = old;
}
public String getName() {
return name;
}
public int getOld() {
return old;
}
}
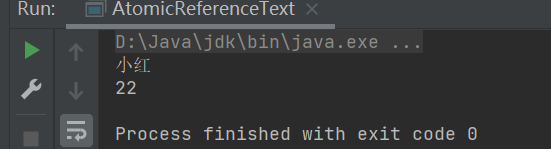
2.4原子更新字段类
JUC包下提供以下3个类进行原子字段更新
- AtomicIntegerFieldUpdater:原子更新整型的字段的更新器。
- AtomicLongFieldUpdater:原子更新长整型字段的更新器。
- AtomicStampedReference:原子更新带有版本号的引用类型,该类将整数值与引用关联起来,可用于原子的更新数据和数据的版本号, 解决CAS进行原子更新出现的ABA问题
要原子更新字段需要两步
- 由于原子更新字段类都是抽象类,每次使用时,必须使用静态方法newUpdater()创建更新器,并且需要设置想要更新的类和属性
- 更新类的字段(属性)必须使用public volatile修饰
由于这个3个类提供的方法几乎一样,这里用AstomicIntegerFieldUpdater来举例
import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;
public class AtomicIntegerFieldUpdaterTest {
private static AtomicIntegerFieldUpdater<User> a =
AtomicIntegerFieldUpdater.newUpdater(User.class, "old");
public static void main(String[] args) {
User user = new User("静仔", 22);
System.out.println(a.getAndIncrement(user));
System.out.println(a.get(user));
}
public static class User {
private String name;
public volatile int old;
public User(String name, int old) {
this.name = name;
this.old = old;
}
public String getName() {
return name;
}
public int getOld() {
return old;
}
}
}
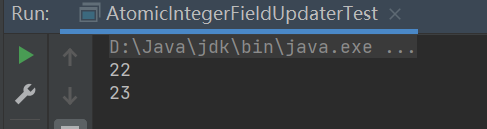
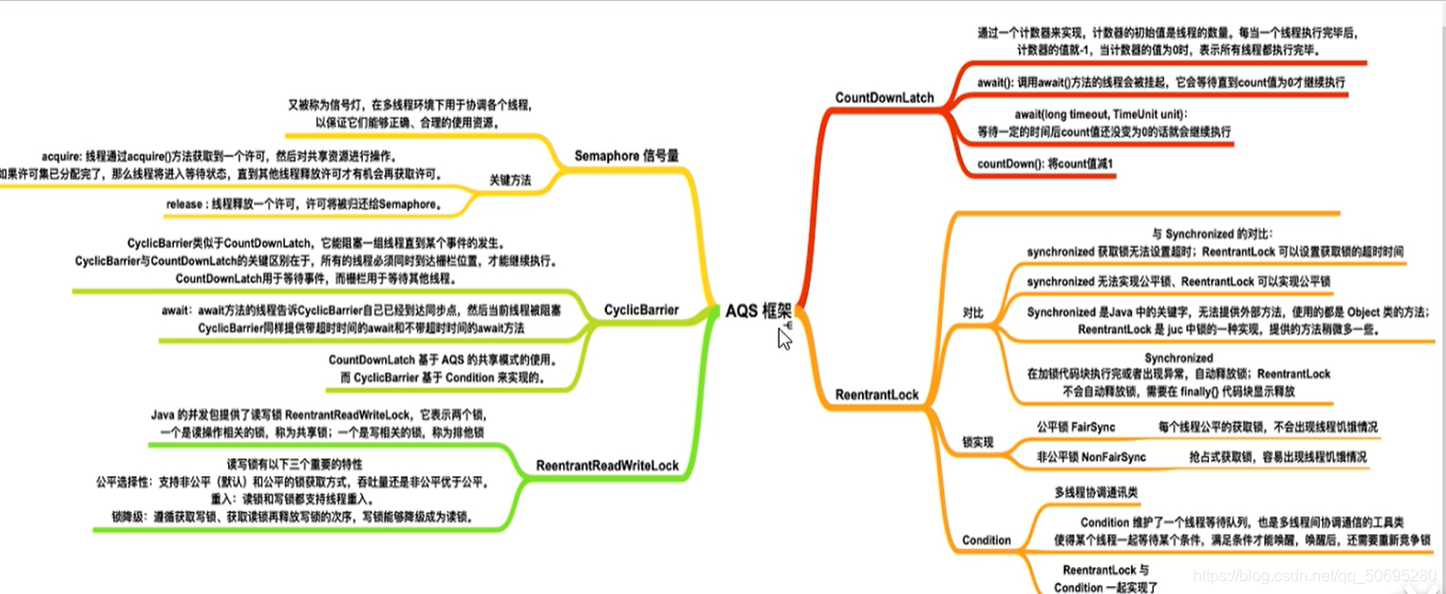
三并发工具类
3.1等待多线程完成的CountDownLatch
CountDownLatch允许一个或多个线程等待其他线程完成操作
实现原理:
CountDownLatch的构造函数接收一个int类型的参数作为计数器,如果你想等待N个点完成,这里传入N
线程调用await()该线程会被阻塞
其他线程调用countDown方法后,计数器-1,
计数器为0唤醒await线程
public class CountDownLanchDemo {
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 0; i < 6; i++) {
new Thread(() -> {
countDownLatch.countDown();
System.out.println(Thread.currentThread().getName() + " 离开了教室...");
}, String.valueOf(i)).start();
}
countDownLatch.await();
System.out.println("班长把门给关了,离开了教室...");
}
}

计数器必须大于0,只是等于0时计数器就是0,此时调用await方法不会阻塞当前线程
3.2同步屏障CyclicBarrier
CyclicBarrier
当满足一定条件执行
实现原理:
CyclicBarrier的构造函数接收一个int类型的参数作为屏障拦截的线程数量

public class CyclicBarrierDemo {
public static void main(String[] args) {
CyclicBarrier cyclicBarrier = new CyclicBarrier(6);
for (int i = 0; i < 8; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " 开始上车...");
try {
cyclicBarrier.await();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 号线程起飞");
}).start();
}
}
}
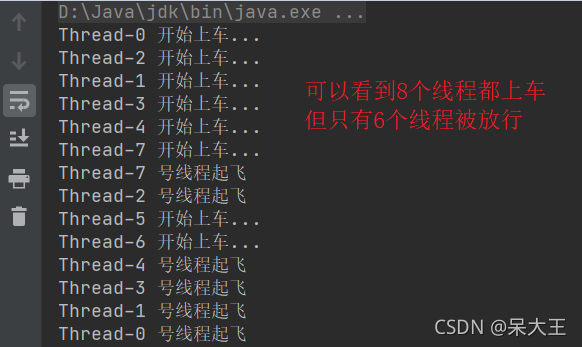
CyclicBarrier的另一个构造函数

用于在线程达到屏障时,优先执行Runnable barrierAction线程
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class CyclicBarrierTest2 {
public static void main(String[] args) {
CyclicBarrier cyclicBarrier = new CyclicBarrier(4, () -> {
System.out.println("车满了,开始出发...");
});
for (int i = 0; i < 8; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " 开始上车...");
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() +" 号线程起飞");
}).start();
}
}
}
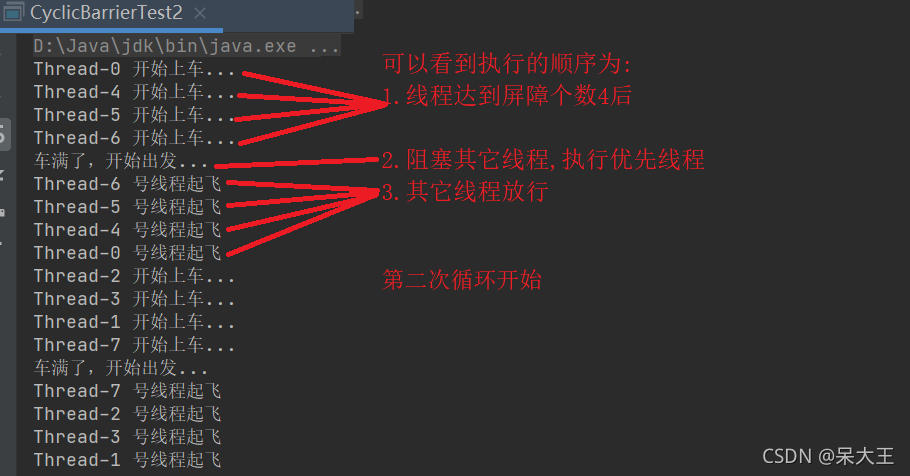
3.3CyclicBarrier和CountDownLatch的区别
CountDownLatch的计数器只能使用一次
CyclicBarrier的计数器可以使用reset()重置
CyclicBarrier.isBroken()方法判断阻塞的线程是否被中断
CyclicBarrier.getNumberWaiting()方法获取Cyclic-Barrier阻塞的线程数量。
3.4控制并发线程数的Semaphore
Semaphore
控制同时访问特定资源的线程数量,它通过协调各个线程,保证合理使用公共资源
public class SemaphoreDemo {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3);
for (int i = 0; i < 6; i++) {
new Thread(() -> {
try {
semaphore.acquire(); // 获取一个许可
System.out.println(Thread.currentThread().getName() + " 抢到车位...");
Thread.sleep(3000);
System.out.println(Thread.currentThread().getName() + " 离开车位");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release(); // 释放一个许可
}
}).start();
}
}
}

Semaphore还提供一些其他方法,具体如下。
- intavailablePermits():返回此信号量中当前可用的许可证数。
- intgetQueueLength():返回正在等待获取许可证的线程数。
- booleanhasQueuedThreads():是否有线程正在等待获取许可证。
- void reducePermits(int reduction):减少reduction个许可证,是个protected方法。
- Collection getQueuedThreads():返回所有等待获取许可证的线程集合,是个protected方法。
3.5线程间交换数据的Exchanger
Exchanger是用于线程间数据交换的工具类
它提供一个同步点 ,在这个同步点两个线程可以通过exchange彼此交换数据
第一个线程先执行exchange()方法,它会一直等待第二个线程也
执行exchange方法,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。
import java.util.concurrent.Exchanger;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ExchangerTest {
static final Exchanger<String> ex = new Exchanger<>();
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(()-> {
String a = "小红";
try {
ex.exchange(a);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
executorService.execute(()-> {
String b = "小明";
try {
String exchange = ex.exchange(b);
System.out.println("得到了: "+exchange);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
executorService.shutdown();
}
}
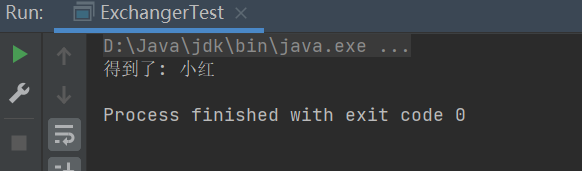
如果两个线程有一个没有执行exchange()方法,则会一直等待,如果担心有特殊情况发生,避免一直等待,可以使用exchange(V x,longtimeout,TimeUnit unit)设置最大等待时长。
四线程池
4.1线程池的优势
线程池用于多线程处理中,它可以根据系统的情况,可以有效控制线程执行的数量,优化运行效果。线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,那么超出数量的线程排队等候,等其它线程执行完毕,再从队列中取出任务来执行。
主要特点为:
- 线程复用
- 控制最大并发数量
- 管理线程
主要优点为:
- 降低资源消耗,通过重复利用已创建的线程来降低线程创建和销毁造成的消耗。
- 提高相应速度,当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性,线程是稀缺资源,如果无限制的创建,不仅仅会消耗系统资源,还会降低体统的稳定性,使用线程可以进行统一分配,调优和监控。
4.2线程池的创建
ThreadPoolExecutor
ThreadPoolExecutor作为java.util.concurrent包对外提供基础实现,以内部线程池的形式对外提供管理任务执行,线程调度,线程池管理等等服务。
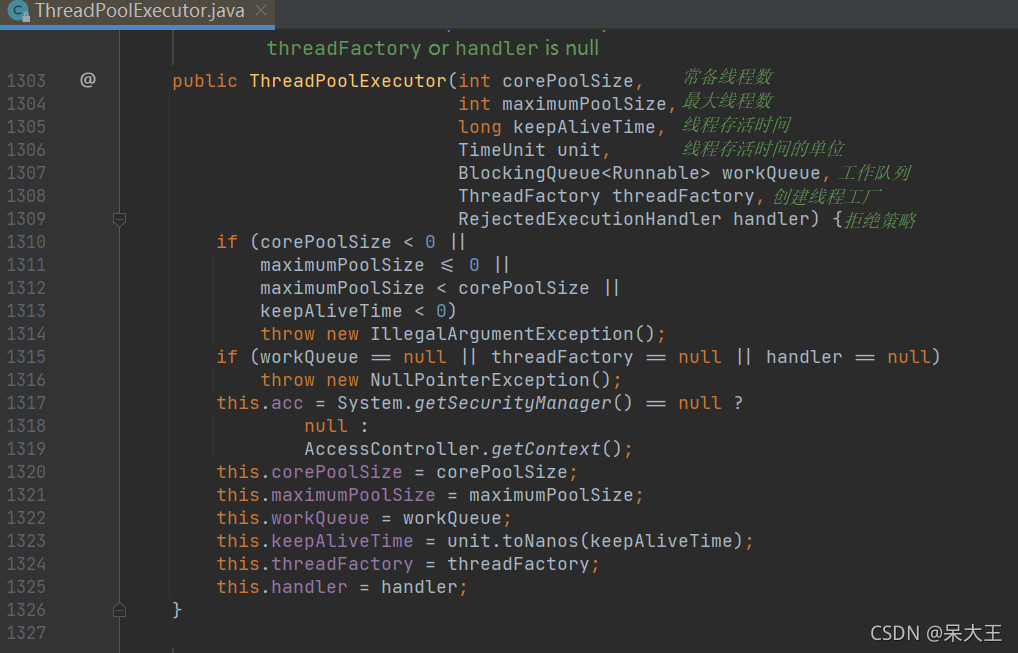

4.2.1线程池参数之BlockingQueue队列
关于队列可以看下文 16章阻塞队列
4.2.2线程池参数之threadFactory
参数详解:
ThreadFactory 创建线程工厂 按需创建新线程的对象
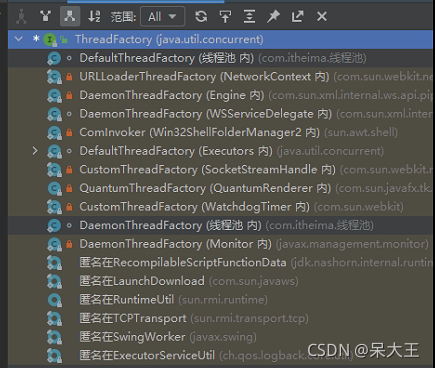
图为ThreadFactory的实现类 共有 16个 ,2个是我们可以用的,其他都是被private修饰的
方式一:
DaemonThreadFactory 是创建守护线程的工厂:
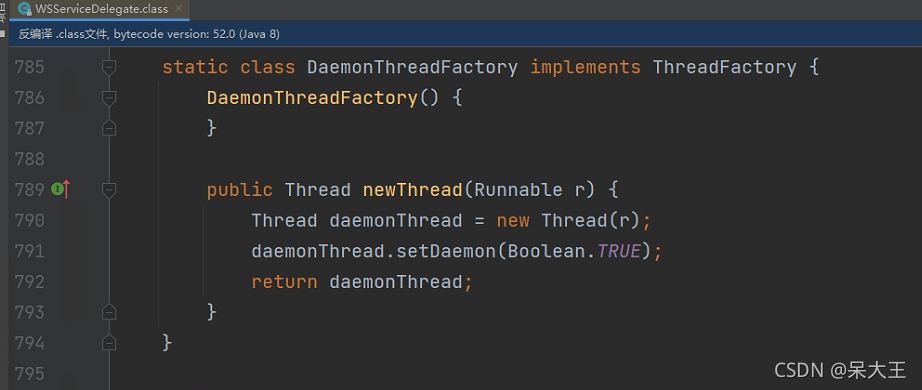
方式二:
DefaultThreadFactory 默认方式 此工厂创建的线程 不是守护线程 优先级为5 堆大小为0 有线程组 有线程名字
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);//原子整型操作类
private final ThreadGroup group;//线程组,根据是否获取系统安全接口 判断新线程的 线程组 如何创建
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;//通过原子的方式给线程池里的线程起 名字
//本方法解决 线程组 和 线程名字
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();//获取系统安全接口
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();//如果系统安全接口!=null就通过系统安全接口获取线程组 否则 通过当前线程对象获取线程组
namePrefix = "pool-" +
poolNumber.getAndIncrement() +//int getAndIncrement():以原子方式将当前值加1,注意,这里返回的是自增前的值。
"-thread-";
}
//开启一个线程,解决线程 不是守护线程 优先级==5 堆大小==0
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,//线程参数: 线程组, Runnable,
namePrefix + threadNumber.getAndIncrement(),//线程名字
0);//堆大小为 0
if (t.isDaemon())//此线程是守护线程。进入if 是守护线程 则 t.isDaemon()==true
t.setDaemon(false);//无论是否为守护线程,这个默认工厂创建的线程都不是 守护线程 t.setDaemon(false);将守护线程改为非守护线程
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);//无论原来的优先级是什么,这个默认工厂创建的线程优先级都是5
return t;
}
}
4.2.3线程池参数之handler拒绝策略
等待队列已经满了,再也塞不下新的任务,同时线程池中的线程数达到了最大线程数,无法继续为新任务服务。
拒绝策略
AbortPolicy:处理程序遭到拒绝将抛出运行时 RejectedExecutionException
CallerRunsPolicy:线程调用运行该任务的 execute 本身。此策略提供简单的反馈控制机制,能够减缓新任务的提交速度。
DiscardPolicy:不能执行的任务将被删除
DiscardOldestPolicy:如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重试执行程序(如果再次失败,则重复此过程)
4.3线程池的实现原理
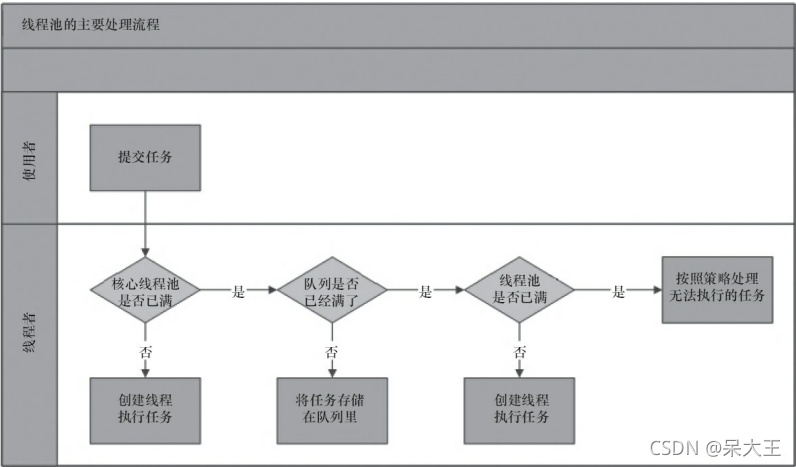
图为: 线程池主要处理流程
线程池的工作流程:
线程池初始化就创建 常备线程数 个数的线程
随着任务的增加,
当任务大于 常备线程数 个数时,
线程池把多于 常备线程数 个数的任务放入 工作队列 中, 等到"常备线程数" 线程空闲了,就到这里执行任务
当任务大于 "常备线程数" + "工作队列" 时,线程池会根据 "创建线程工厂" 创建新线程
当任务大于 "最大线程数" + "工作队列" 时,线程池会根据 "拒绝策略" 来决定对多于的任务的策略
"常备线程数" 和 "临时创建的线程" 谁完成任务后都会到 "工作队列" 里拿任务执行
当 "任何线程" 没有任务且等待任务时间超过了 "线程存活时间" 后,会被杀死, 保证你的 "常备线程数" 与实际线程池里的线程数 一样
你是一个老板你有2个服务员,
客人多了
客人大于 2个服务员 时,
你告诉可以让客人 等待(放入 工作队列 ),
等待的客人越来越多了, 你不得不去找临时工
客人多到你的桌子都没有了 (任务大于 "最大线程数" + "工作队列" 时) ,
你不得不放弃这些多余的客人 (线程池会根据 "拒绝策略" 来决定对多于的任务的策略)
客人少了 , 你看到有空闲的服务员(无论他的正式工还是临时工)就把他干掉了
总结一下如下图:
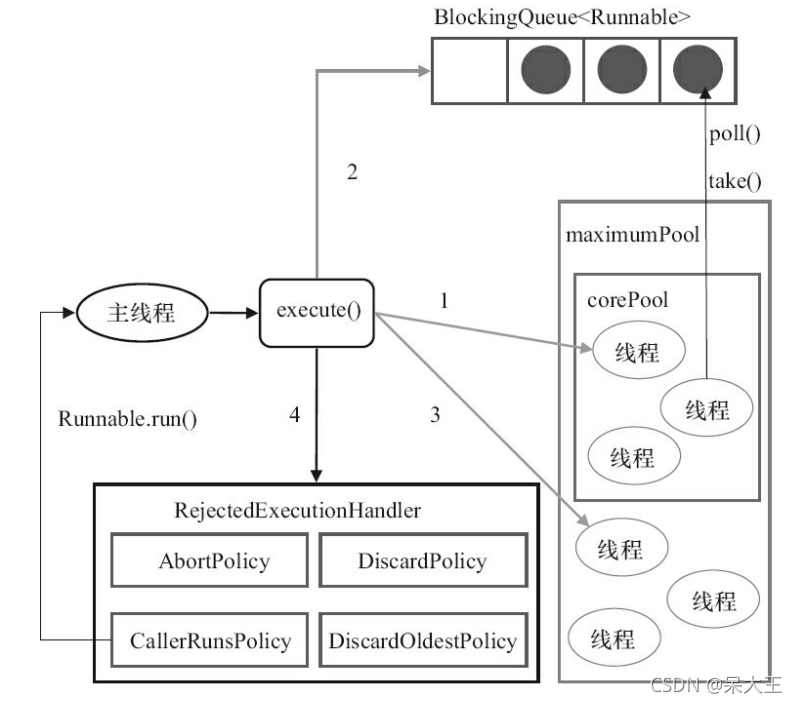
一起开看一下源码;
点击进入ThreadPoolExecutor.execute这个方法
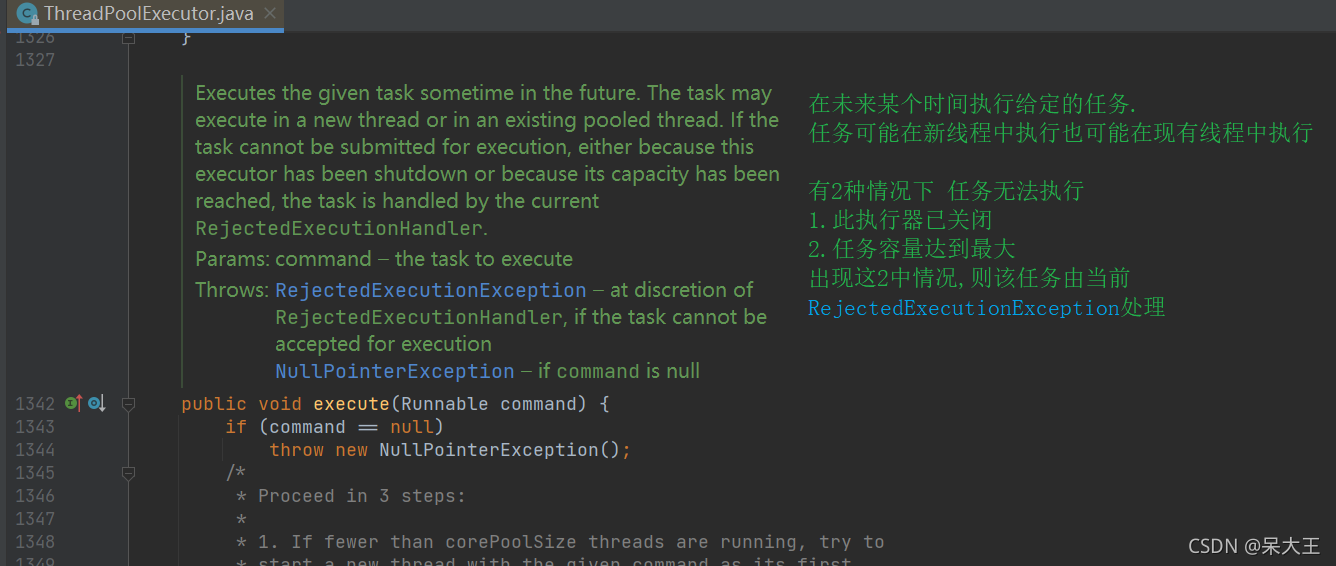
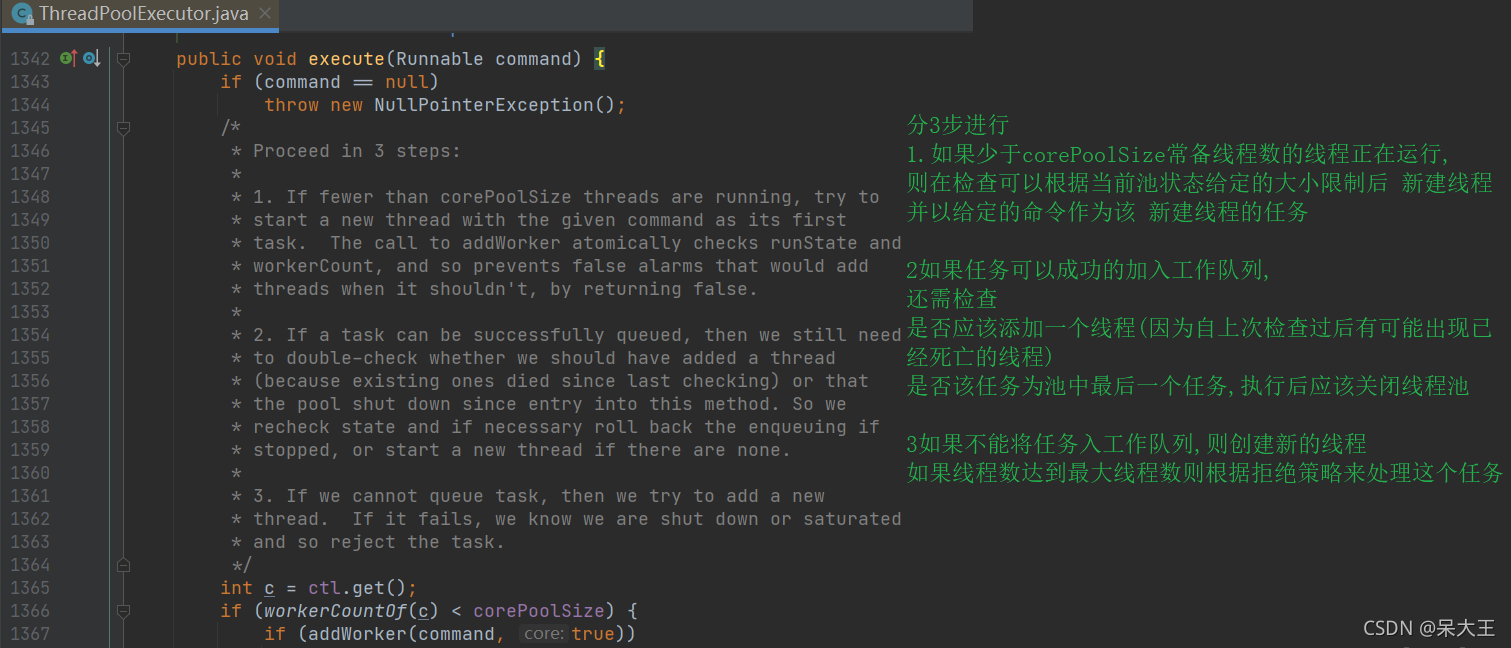
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//如果当前正在运行的线程数 < 常备线程数
if (workerCountOf(c) < corePoolSize) {
//检查是否可以根据当前池状态和给定界限(核心或最大值)添加新的工作线程。
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
上面这个代码解析我是写不出来了sry ,真的太难了…啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊
线程池中线程执行任务分两种情况:
- 在execute()方法中创建一个线程时,此线程执行当前任务
- 在线程执行任务后,会从工作队列中获取任务执行
4.4向线程池提交任务
execute()与submit()方法都可以向线程池提交任务
execute()方法提交 没有返回值 的任务,所以也无法知道线程池执行是否成功
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExecutorText {
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
2,
5,
10,
TimeUnit.SECONDS,
new LinkedBlockingDeque(5),
Executors.defaultThreadFactory(),//没构造,只能通过类名点调用
new ThreadPoolExecutor.AbortPolicy());//有自己的构造,所以new
threadPoolExecutor.execute(()->{
System.out.println("启动了一个线程");
System.out.println(Thread.currentThread().getName());
});
}
}
submit()方法用于提交需要返回值的任务
线程池会返回一个 future类型的对象来判断任务是否执行完成
future.get()方法来获取返回值,get()方法会阻塞当前线程一段时间后返回
import java.util.concurrent.*;
public class ThreadPoolExecutorText {
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
2,
5,
10,
TimeUnit.SECONDS,
new LinkedBlockingDeque(5),
Executors.defaultThreadFactory(),//没构造,只能通过类名点调用
new ThreadPoolExecutor.AbortPolicy());//有自己的构造,所以new
Future<?> future = threadPoolExecutor.submit(() ->
System.out.println("启动另一个线程"));
try {
Object o = future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} finally {
//关闭线程池
threadPoolExecutor.shutdown();
}
}
}
4.5关闭线程池
shutdown()与shutdownNow()方法都可以向线程池提交任务
这2个方法的原理都是
遍历线程池中的工作线程,然后逐个调用线程的 interrupt方法来中断线程
interrupt()方法的详解可以见下文的 12.2.2线程中断
所以线程池中无法响应中断的线程可能永远无法关闭
这个两个方法的区别是
shutdownNow()方法是
先将线程池的状态设置为STOP,
然后尝试停止所有正在执行或暂停任务的线程,
最后返回等待执行任务的列表
shutdown()方法是
先将线程池的状态设置为SHUTDOWN状态
最后 中断所以没有正在执行任务的线程
如果任务不需要执行完毕则调用 shutdownNow()
任务需要执行完毕则调用 shutdown()
isShutdown方法可以检查线程池是否关闭
4.6合理配置线程池
CPU密集型
配置尽可能小的线程
CPU核数+1
+1个线程为了防止其他原因导致的任务暂停,而CPU处于空闲状态,多出来一个线程就可充分利用CPU的空闲时间
场景:
任务需要大量运算,没有阻塞,CPU一致运行
IO密集型
配置尽可能多的线程
CPU核数 * 2。
场景:
线程在处理I/O时不会占用CPU,
可以多分配一些线程数
如何判断是CPU密集型还是IO密集型任务?
CPU密集型简单理解就是利用CPU计算能力的任务比如对内存大量数据排序
但凡涉及网络读取,文件读取这类都是IO密集型,
这类 任务特点CPU计算耗费时间比等待IO操作完成的时很快
大部分时间花在等待IO操作上,所以可以分配 CPU核数*2的线程数
可以通过下面代码获取CPU核数
public class getProcessors {
public static void main(String[] args) {
int i = Runtime.getRuntime().availableProcessors();
System.out.println(i);
}
}
优先级不同的任务可以通过下文的 16.3PriorityBlockingQueue队列来处理
该队列作为工作队列可以让优先级高的任务先执行
注意: 如果一直有优先级高的任务提交到改队列,队列中优先级低的任务永远不能执行
五并发编程带来的问题
5.1上下文切换
什么是上下文切换?
cpu不停切换线程执行,让我们感觉是多个线程在同时执行,在切换前会保存上一个任务的状态,以便下次切换回此任务时可以加载到这个任务状态,所以一个任务从保存到再加载的过程就是一次上下文切换.
注意:这也就是并行不一定比串行快的主要原因
用并行流与串行流来表示 上下文切换的具体表现如下:
public class TTT {
public static void main(String[] args) {
List<Student> list = new ArrayList<>();
for(int i=0;i<2000000;i++){
Student s = new Student("zhangsan"+i,"123456", new String[]{"篮球","排球"});
list.add(s);
}
int start = (int) System.currentTimeMillis();
//串行流(顺序流)
//Stream<Student> stream = list.stream();
//stream.forEach(item->{
// System.out.println(Thread.currentThread().getName()+"----"+item.getUsername());
//});
//int end = (int) System.currentTimeMillis();
//System.out.println("串行流耗时: "+(end-start));
//并行流
Stream<Student> parallelStream = list.parallelStream();
parallelStream.forEach(item->{
System.out.println(Thread.currentThread().getName()+"----"+item.getUsername());
});
int end2 = (int) System.currentTimeMillis();
System.out.println("并行流耗时: "+(end2-start));
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
class Student{
private String Username;
private String id;
private String[] like;
}
通过上面代码我们可以我们可以得知
数据量少的情况下,并行没串行快,
数据量大的情况下,串行的优势就来了
但是值得注意的是:
- parallelStream是线程不安全的
- parallelStream适用于CPU密集型(忘记CPU密集型是什么的小伙伴,请翻看4.6合理配置线程池
的),只是做到别浪费CPU,假如本身电脑CPU负载很大,还使用并行流并不能起到作用 - I/O密集型 磁盘I/O 网络I/O都是I/O操作,这操作是较少消耗CPU资源,一般并行流中不适用于I/O密集型的操作.就比如使用并行流大量消息推送,涉及到大量I/O,使用并行流反而慢
- 并行流无法保证元素顺序
- 频繁的上下文切换是并行流在数据量少
如何减少上下文切换?
无锁并发编程,CAS算法,使用最少线程或使用协程
- 无锁并发编程:多线程竞争锁时,会引起上下文切换,我们可以避免使用锁如:将数据的ID按照Hash取摸分段,不同线程策略不同段数据.
- CAS算法,
- 使用最少线程,避免创建不需要的线程,比如任务很少,但是创建了很多线程处理,这样会造成大量线程处于等待状态
- 协程:在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换
5.2查看死锁
jps -l 查看后台进程
jstack 线程编号 找到死锁查看
jinfo 查看正在运行的各种信息
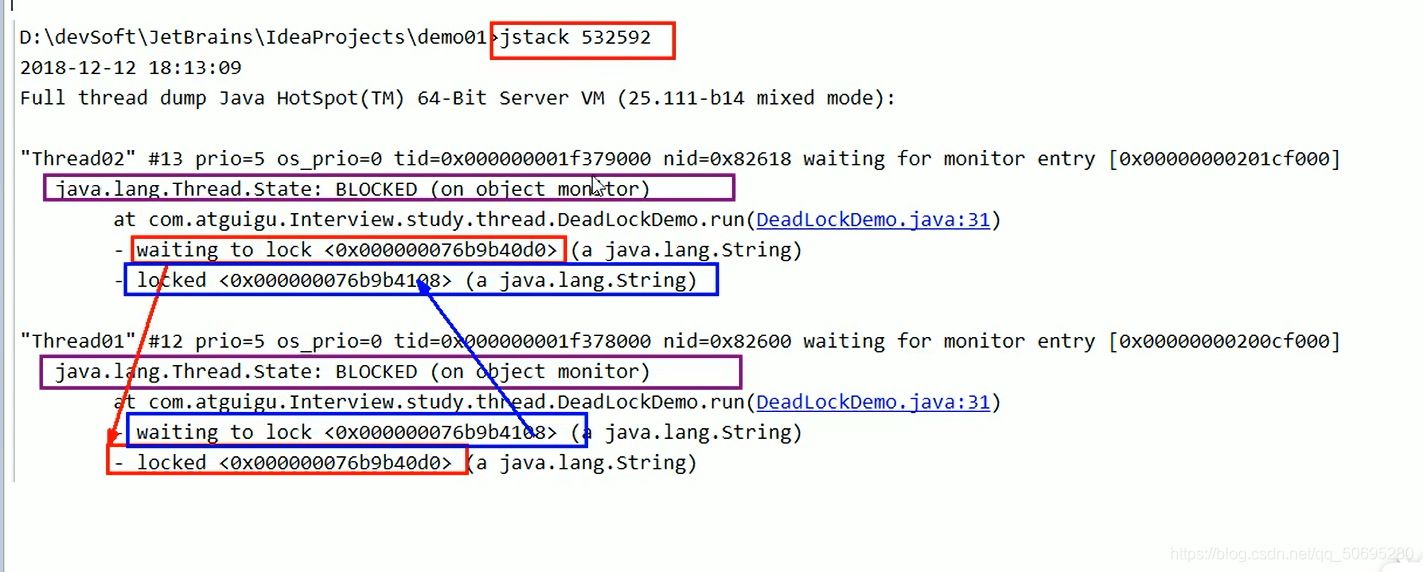
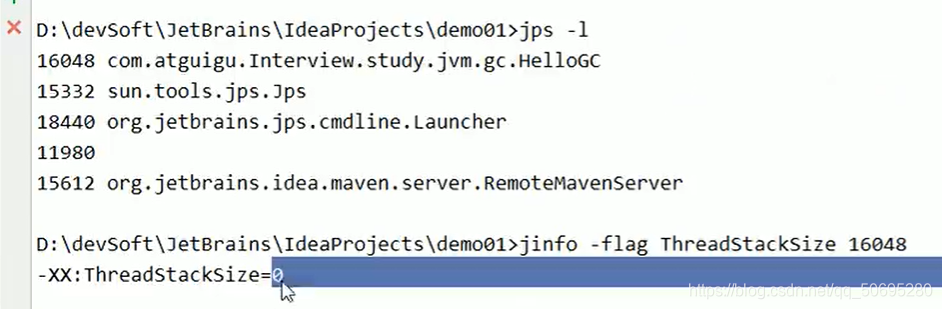
如何避免死锁?
- 避免一个线程同时获取多个锁
- 避免一个线程在锁内同时占用多个资源,尽量保证每一个锁只占一个资源
- 尝试使用定时锁.使用lock.tryLock(timeout)来替代
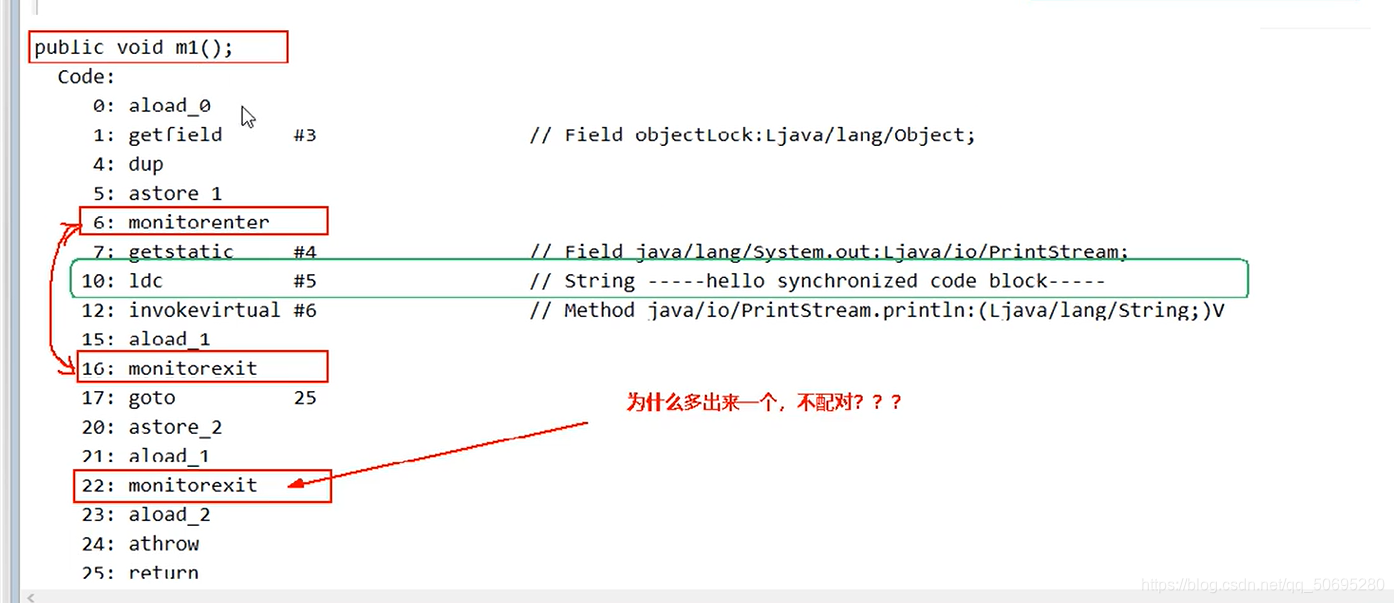
保证出现异常,一定会释放锁
六LockSupport

6.1等待与唤醒的方式
Object的wait()方法 让线程等待, Object的notify()方法 唤醒线程
JUC包Condition的await() 让线程等待, signal()方法 唤醒线程
LockSupport可以阻塞当前线程以及唤醒指定被阻塞的线程
LockSupport的 park() 让线程等待, unpark() 唤醒线程
6.2wait()和Notify()方法
详细请参考 12.4 线程的通信


上面线程先要获取并持有锁,必须在锁块中(synchronized或lock)
必须先等待后唤醒
而
6.3park()和unpark()方法
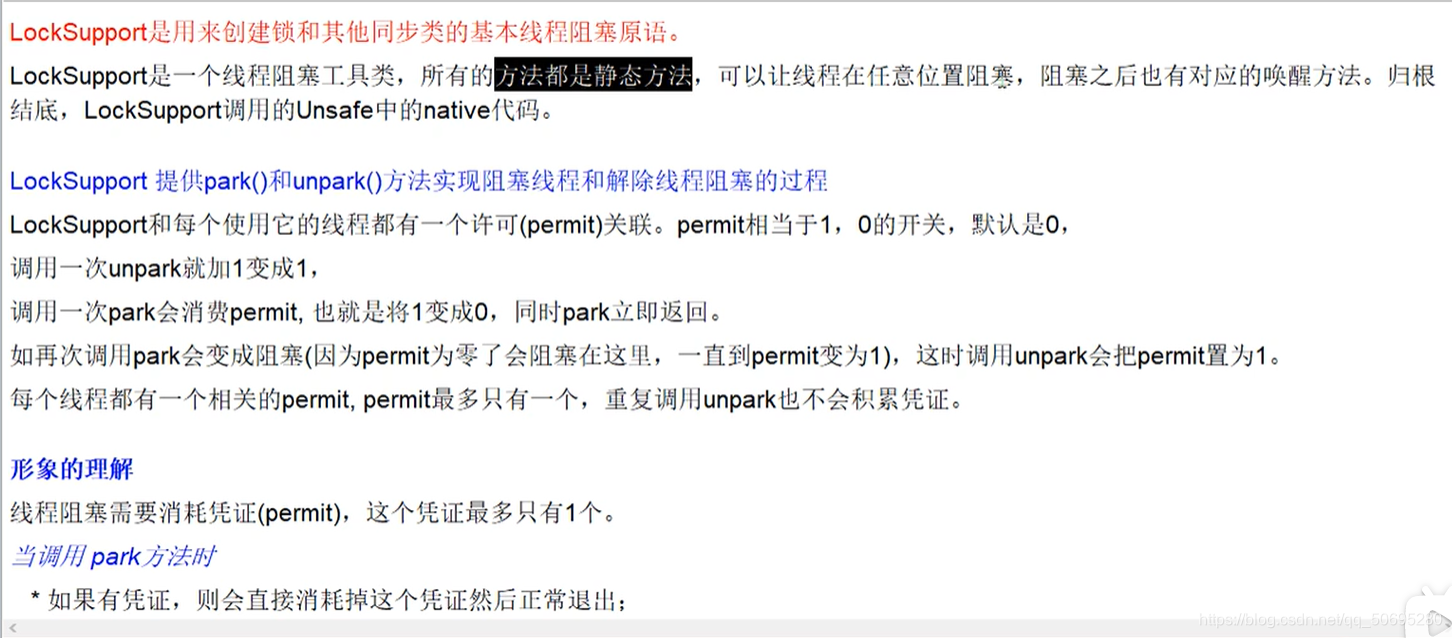
LockSupport是创建锁和其他同步类的基本线程阻塞原语
LockSupport使用了Permit(许可)的概念来阻塞和唤醒线程,
每个线程都有一个许可证,permit只有1和0两个值
与Semaphore不同,许可证上限是1

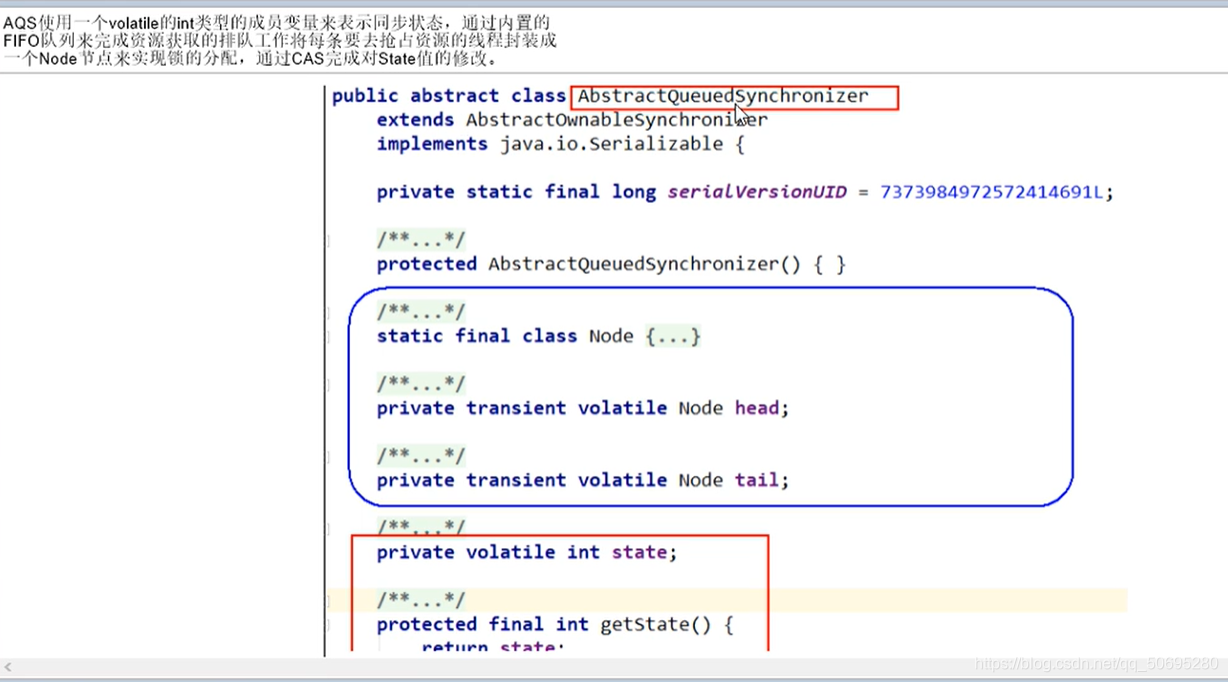
七AbstractQueuedSynchronizer之AQS
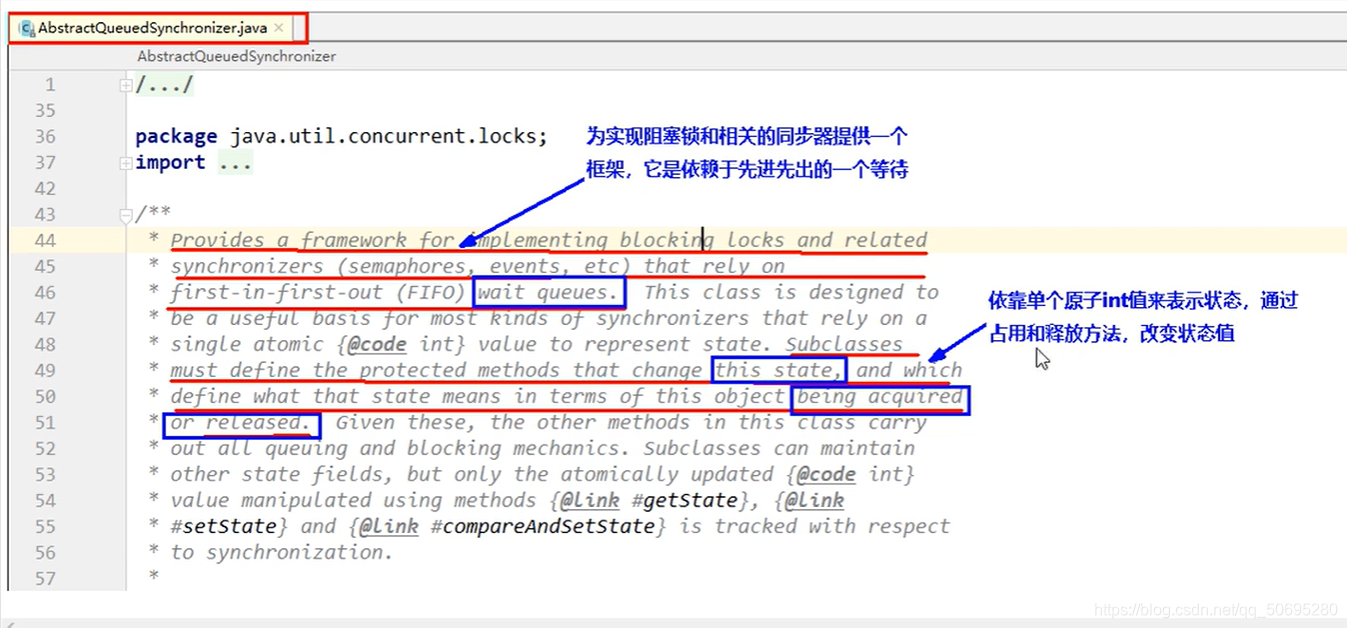
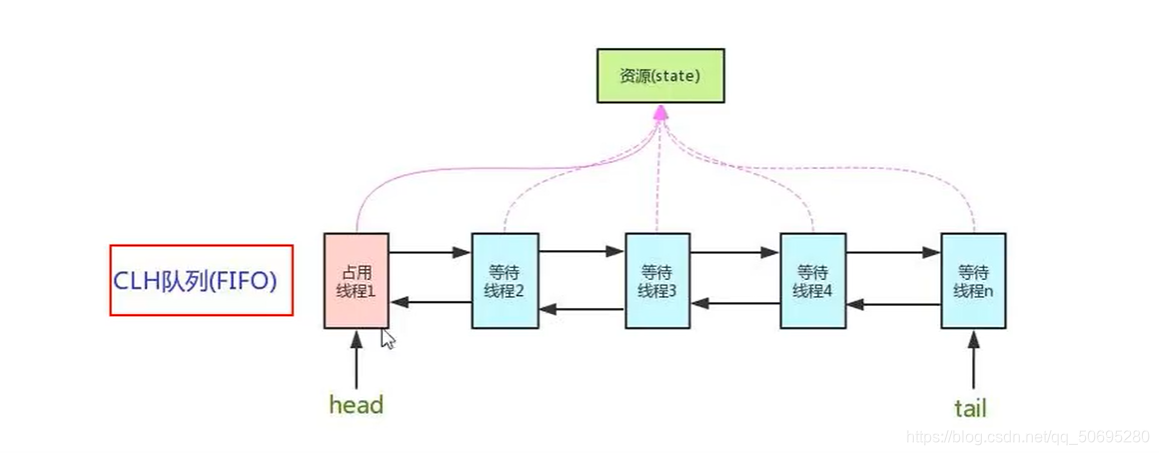
AbstractQueuedSynchronizer用来构建锁或者其他同步器组件的重量级基础框架及整个JUC体系基石,它使用了一个int成员变量表示同步状态,通过内置的FIFO队列完成资源获取线程的排队工作,
AQS 的主要使用方式是继承,子类通过继承AQS并实现AQS的抽象方法来管理同步周日,
AQS提供3个方法
(getState()、
setState(int newState)
compareAndSetState(int expect,int update))
来对同步状态进行更改,同时保证状态的改变是安全的
AQS自身没有实现任何同步接口,仅仅定义若干同步状态获取和释放的方法来供自定义同步组件使用,
AQS既可以支持 独占式 获取同步状态
也可以支持 共享式 获取同步状态,这样方便实现不同类型的同步组件(ReentrantLock、
ReentrantReadWriteLock和CountDownLatch等)
AQS与锁的关系:
锁是面向使用者的,它定义了使用者与锁交互的接口,隐藏了实现细节
AQS是面向锁,它简化了所的实现方式,
屏蔽了
同步状态管理,
线程排队,
等待与唤醒
等底层操作
锁和AQS隔离了 锁的使用者 和 锁的实现者使需要关注的领域
原理:
使用volatile的int类型的成员变量来表示同步状态,
通过内置的 FIFO队列来完成资源获取线程的排队工作,
将每条区抢占资源的线程封装成一个Node节点来实现锁的分配
通过AQS完成对同步状态int类型的state变量值的修改
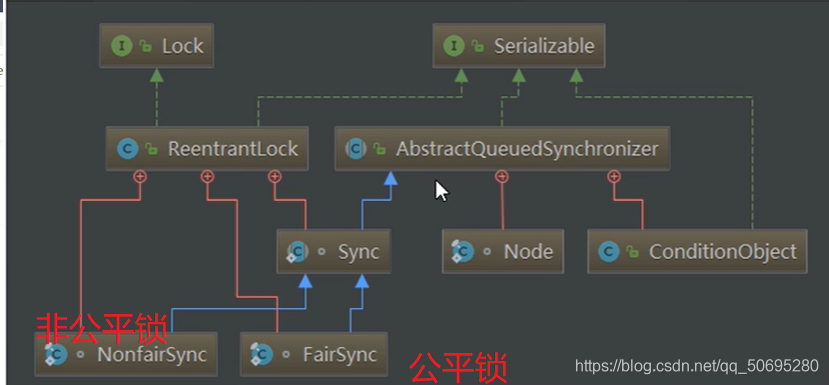
继承结构:
7.1 AQS
AQS = state变量 + CLH 变种 的双端队列
int类型的state变量
零就是没人,大于等于1,有人占有,需要等待

CLH队列:

有阻塞需要排队,实现排队需要队列
AQS = state变量 + CLH 变种 的双端队列
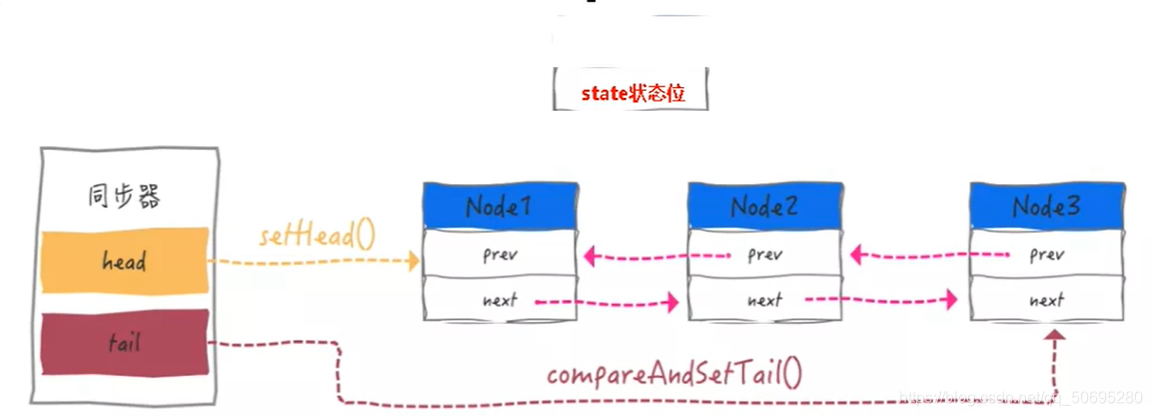
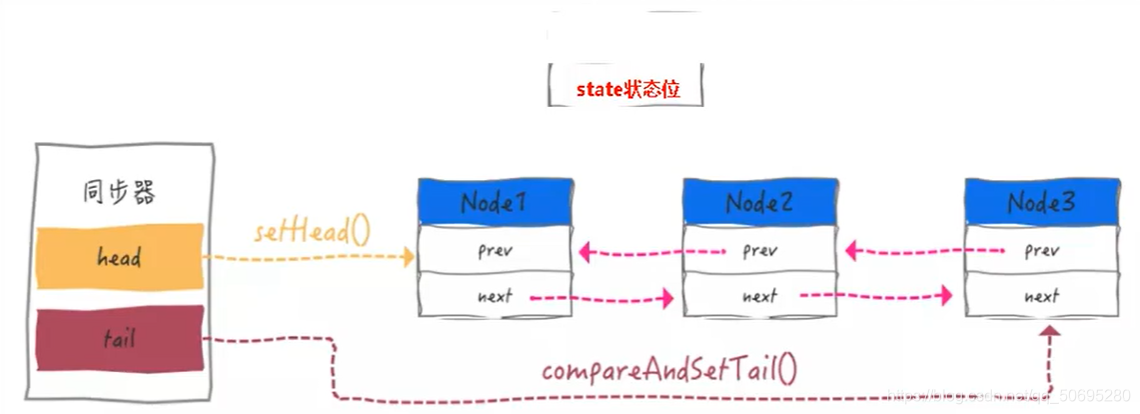
7.2 内部类 Node(Node类在AQS类的内部)
Node = waitStatus + 前后指针指向
Node类的属性 :

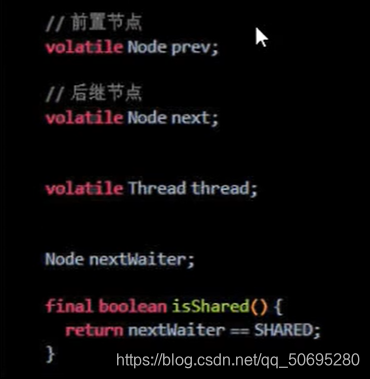
Node类属性说明: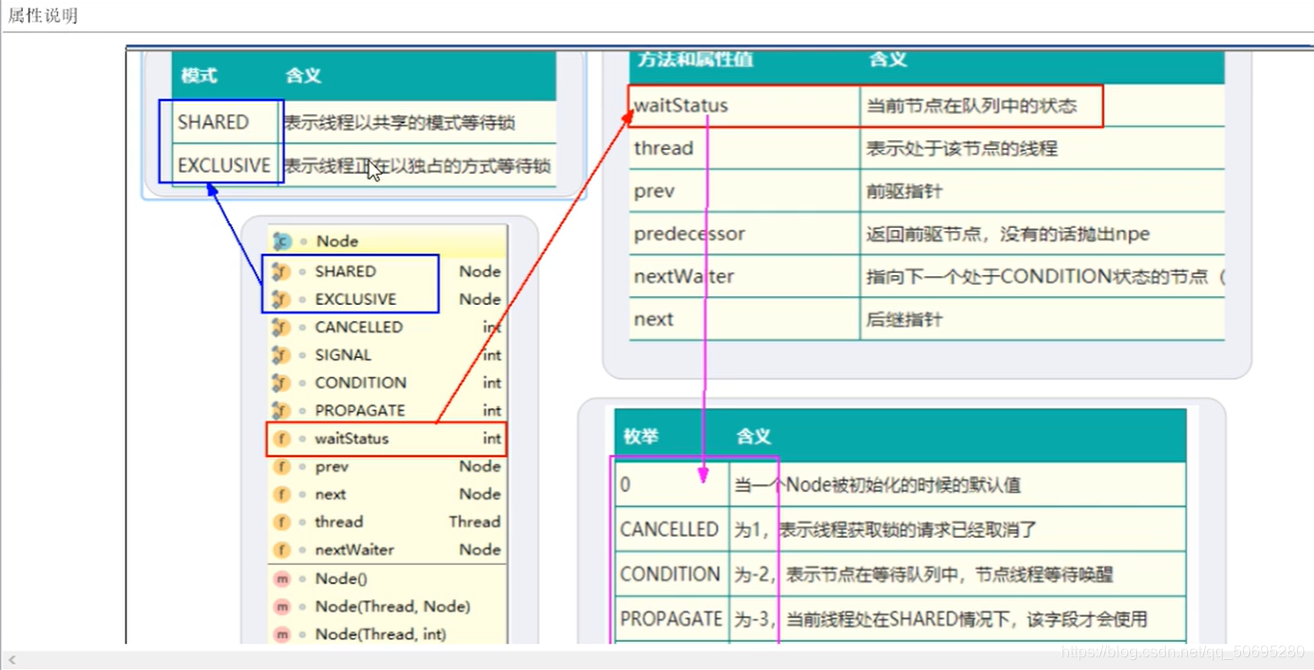
7.4.1Lock类的实现
Lock接口的实现类,基本都是通过 聚合 了一个 队列同步器 的子类完成线程访问的控制.
如图 lock()实际上是内部的sync类的方法 , 而sync又继承AQS
**** :
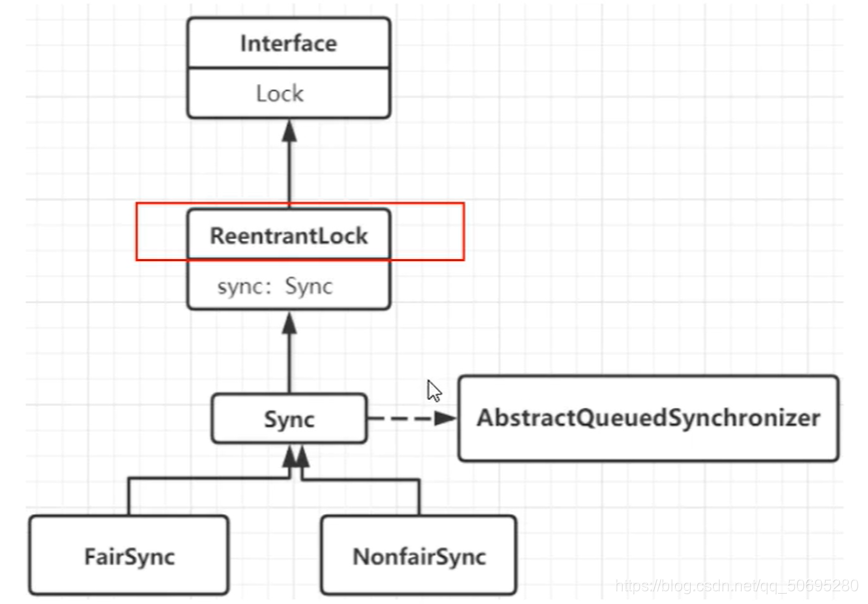
7.4.2 ReentrantLock与AQS的关系
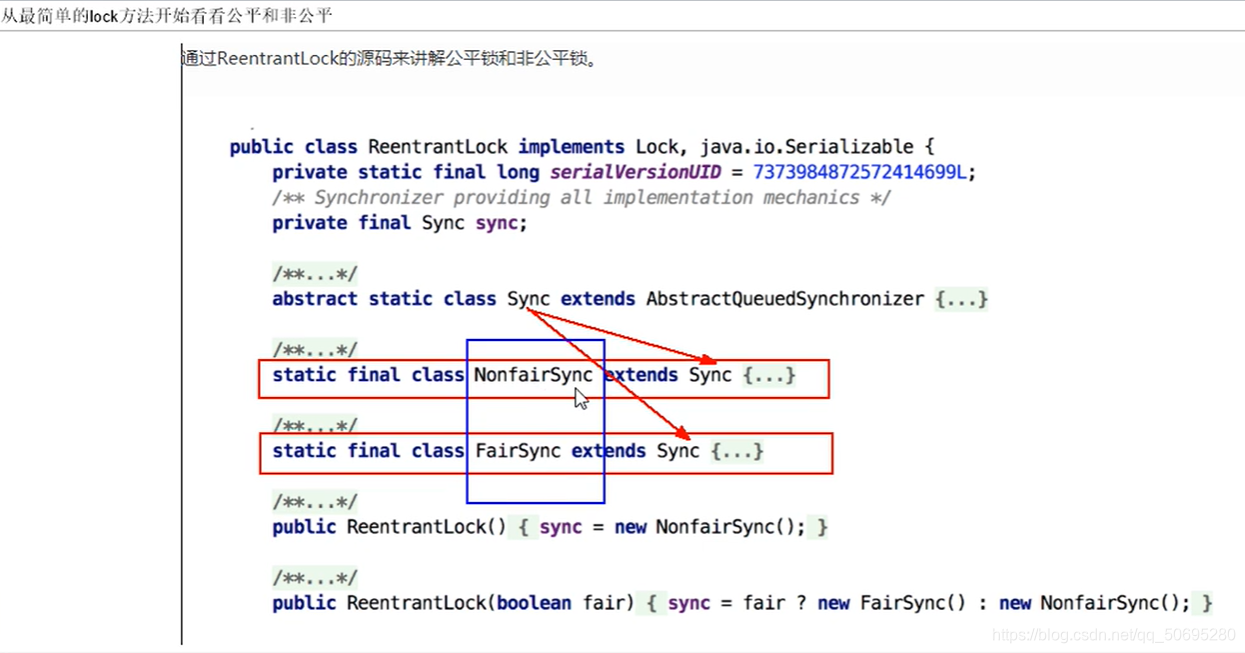
7.4.3 ReentrantLock的构造 与 公平非公平锁的关系


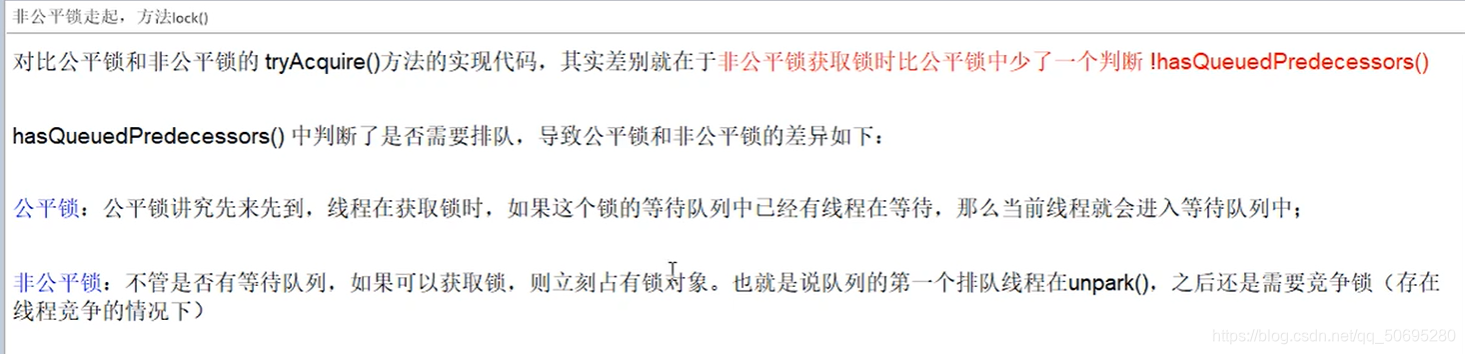
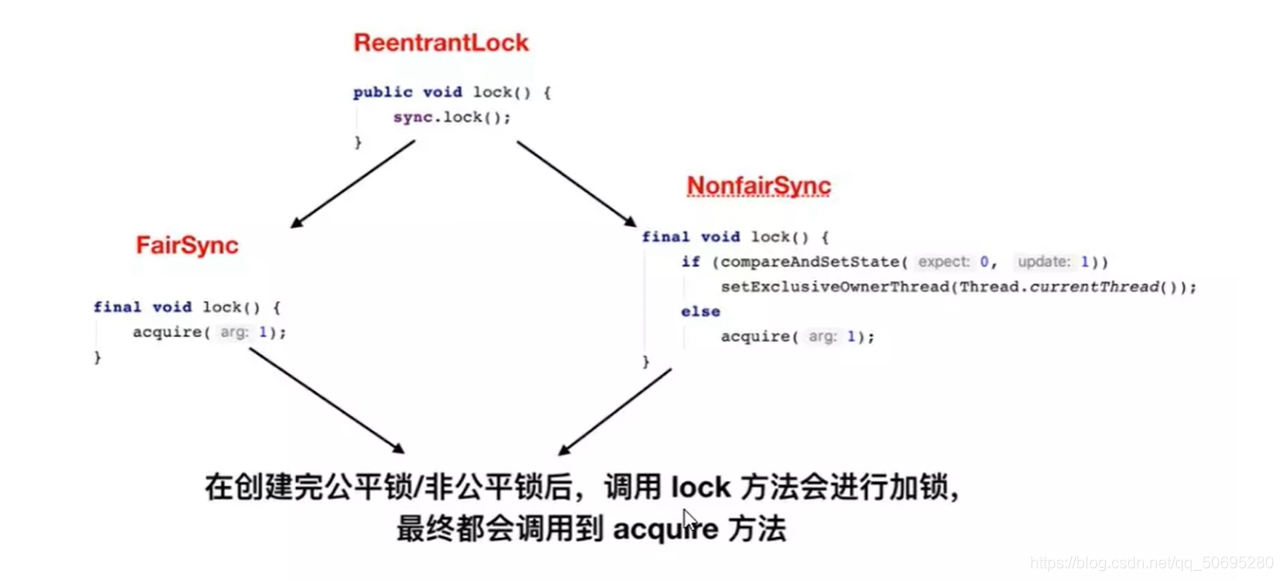
7.5 高能预警 lock()源码正式开始
整个ReentrantLock加锁的过程分三阶段
1.尝试加锁
2.加锁失败,线程入队列
3.线程入队列后,进入阻塞状态
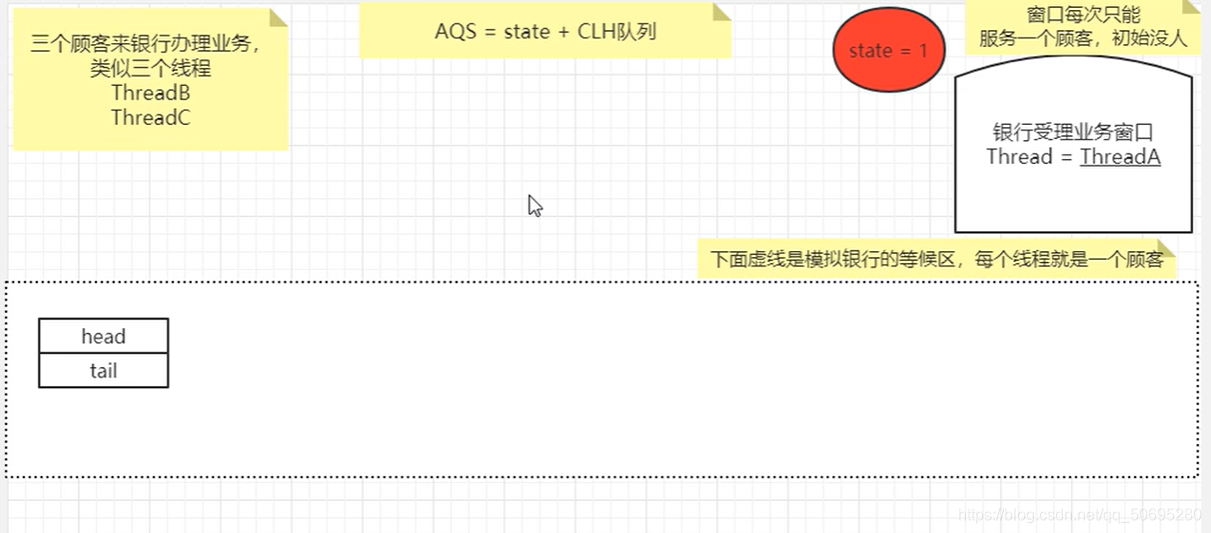
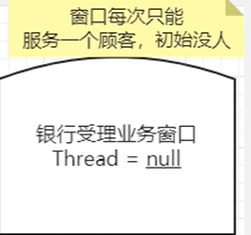
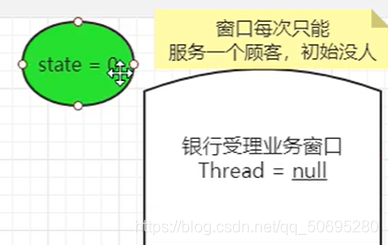
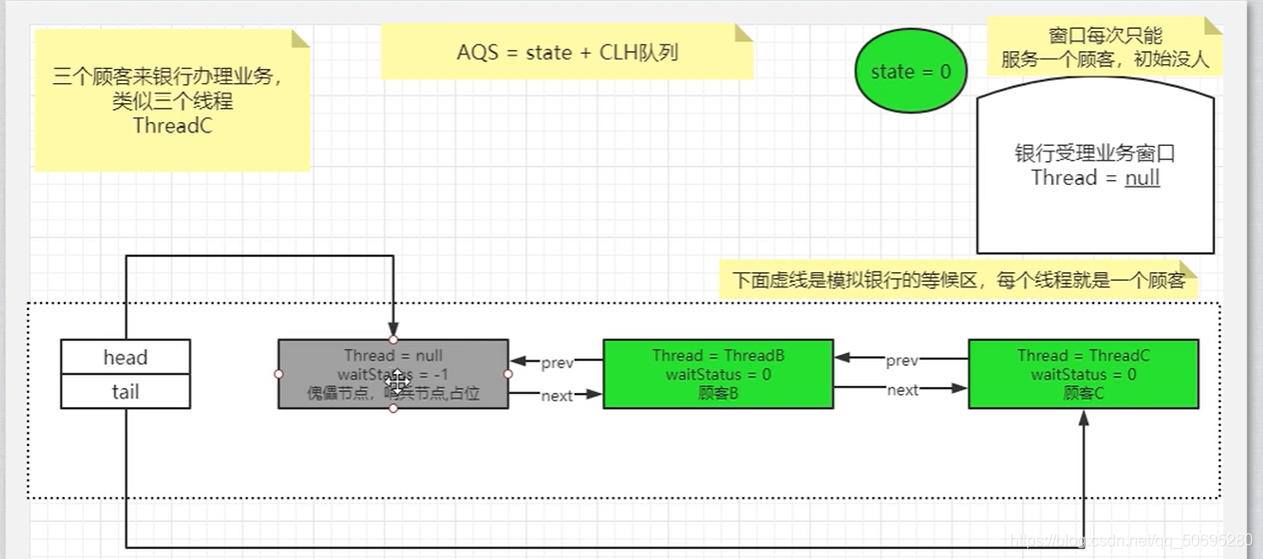
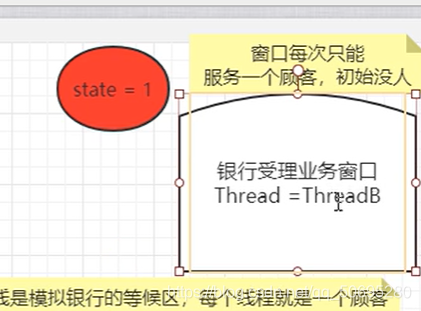
带入一个银行办理业务的案例模拟
我们的AQS如何进行线程管理和通知唤醒机制
主线程里有三个线程 ABC,A休眠20分钟,BC由于A持有锁并休眠而进入阻塞队列:
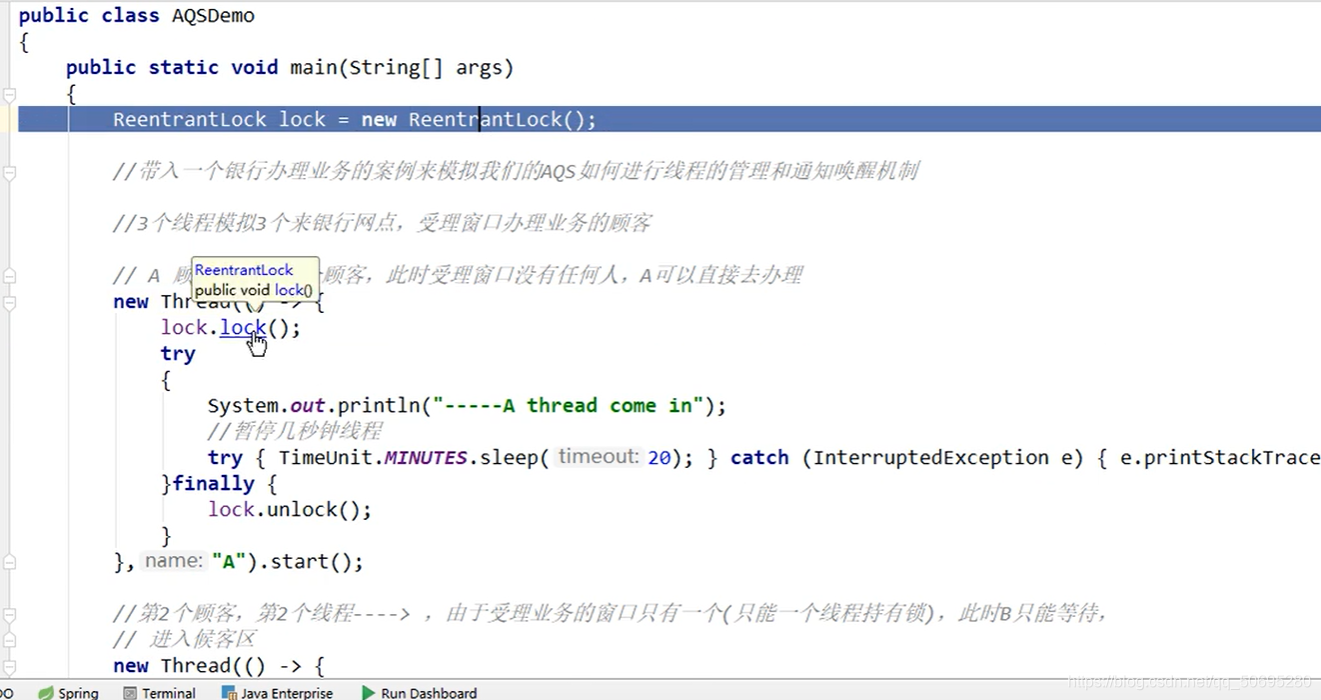
7.5.1 A线程
点击进入lock()方法

而sync是ReentrantLock的内部类,它继承了AQS
Lock接口的实现类,基本都是通过 聚合 了一个 队列同步器 的子类完成线程访问的控制.
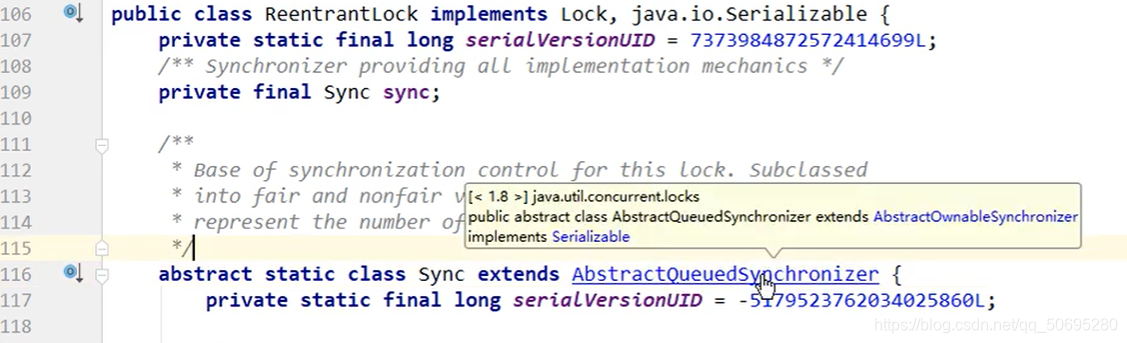
AQS内部的Node封装了一个个节点,Node就是一个媒介载体
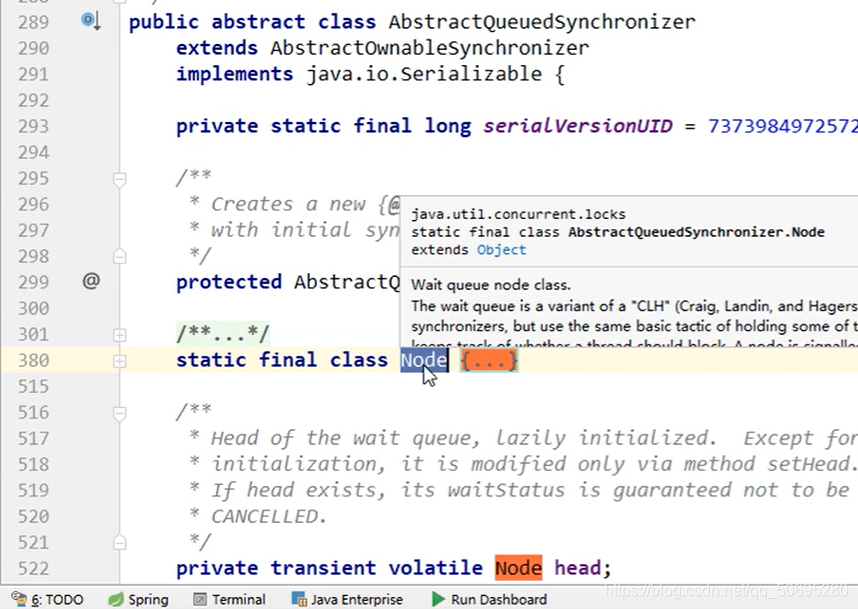
Node类里有一个int变量state,;表示同步的状态,相当于银行办理业务窗口的信号灯 ,
state==0,没人办理业务(占有锁),由于是队列,Node里还有前,后指针
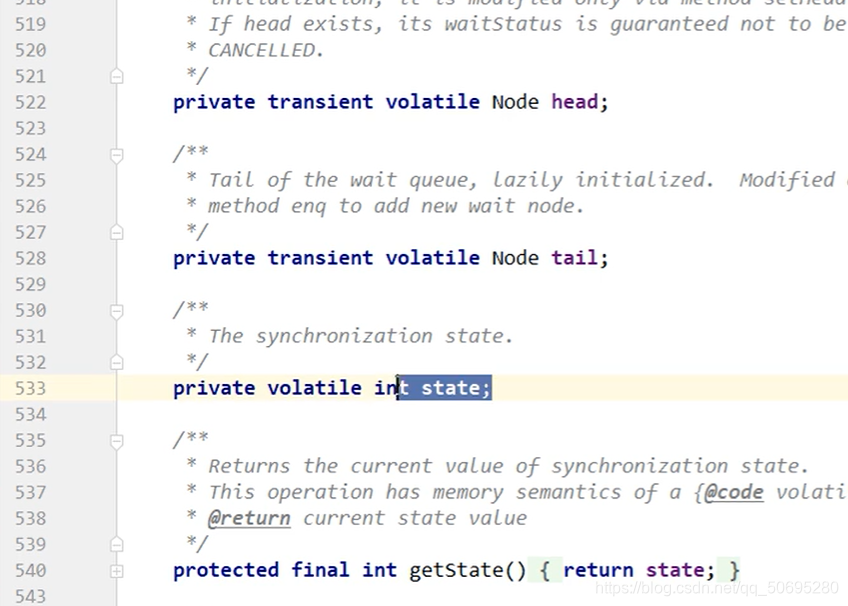
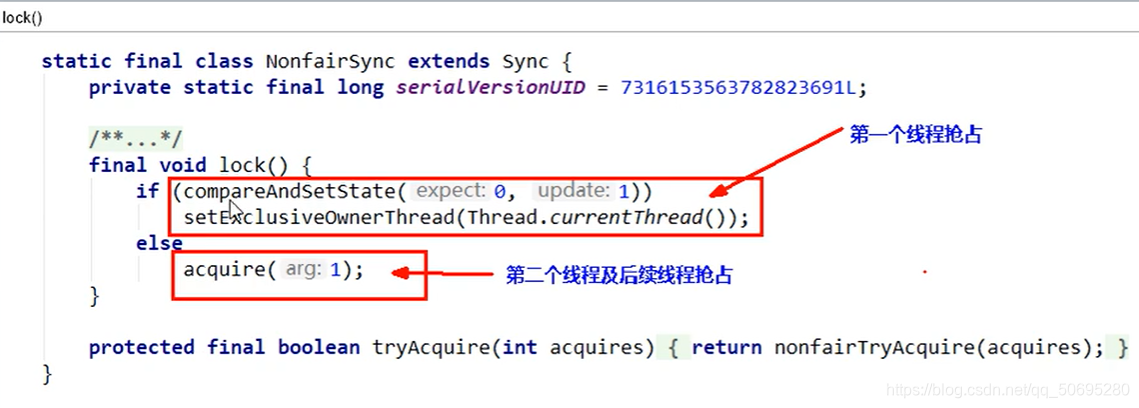
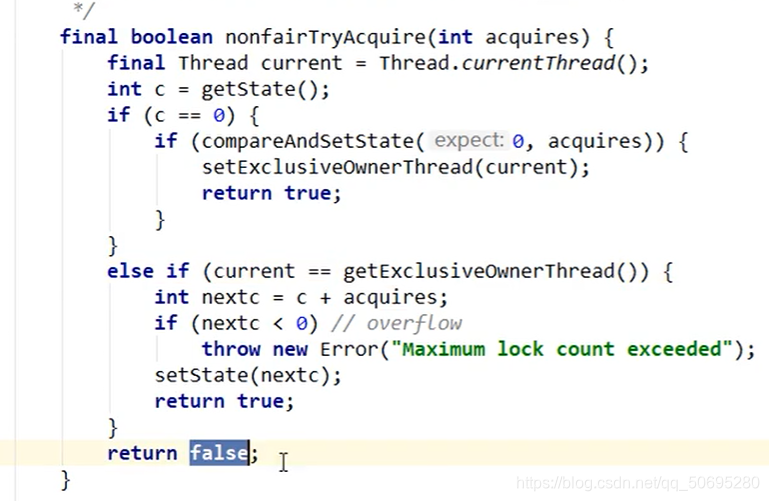
点击Sync的lock方法,有公平与非公平,我们是默认构造进入非公平锁
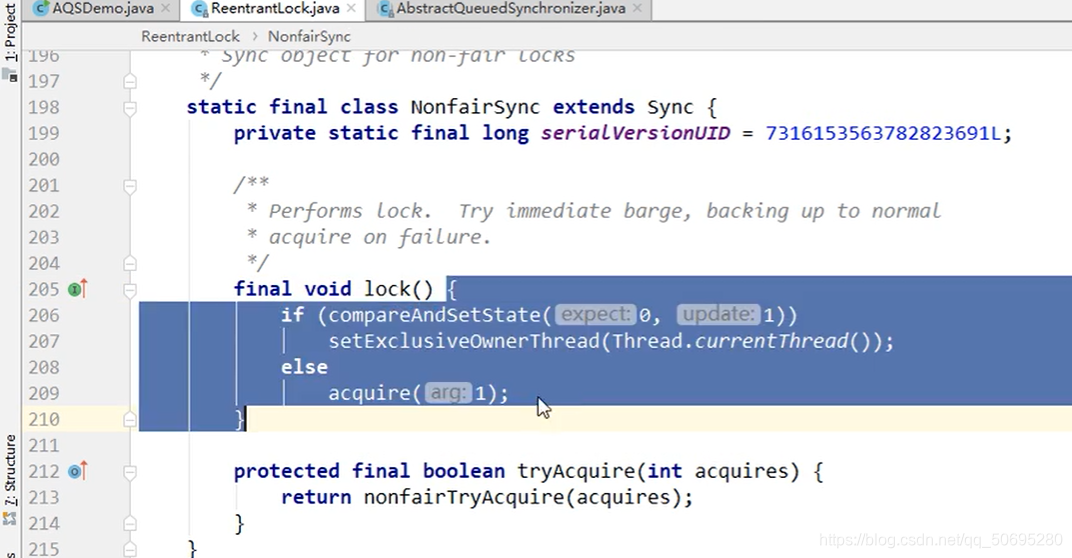
compareAndSetState(0,1)
这就是一个CAS方法,
第一个参数0表示期望值是0(A去银行办理业务,期望窗口没人),
第二个参数1表示修改值是1(A线程开始办理业务时,窗口的信号灯为红的(state的值为1))
所以 就是一个比较并交换的思想
点击进入 —> 比较并交换的CAQ思想
A线程第一个到,开始办理业务(A线程持有锁),
A线程到后期望窗口没人(第一个参数)
A线程修改窗口信号灯为红的(第二个参数),
compareAndSetState(0,1)返回true

进入setExclusiveOwnerThread(Thread.currentThread);方法,
点击进入 ,我们发现这个方法是AQS的父类里的方法
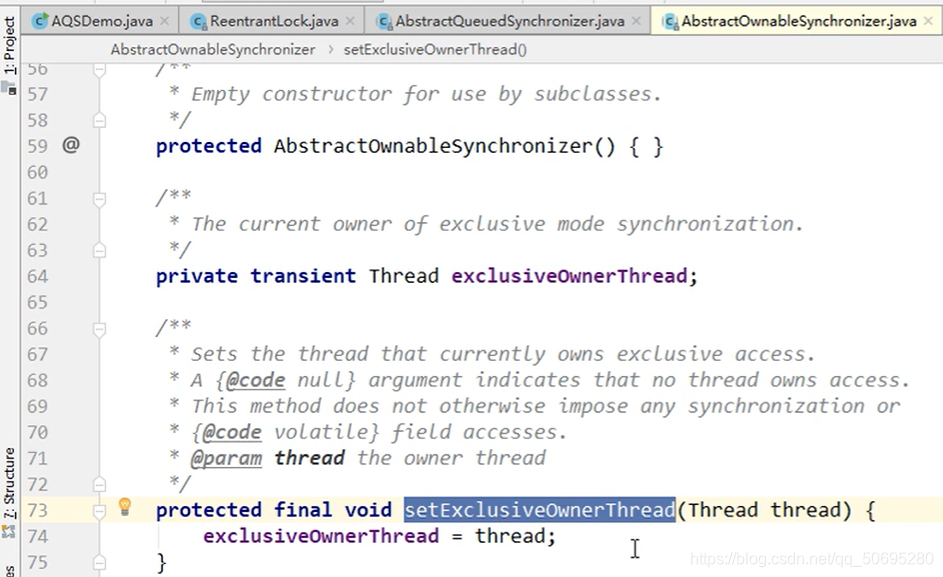
此方法后
将当前占用窗口的值设置为当前线程(A线程的刚把窗口信号灯改成红色后,屁股坐在了小姐姐对面的凳子上说 我是A,然后开始20分钟的休眠)
7.5.2 B线程
7(AQS) 5(源码分析) 2(B线程)
B线程入场了,它通过Sync的lock非公平方法
和A线程一样走到了下图方法:
compareAndSetState(0,1)
它期望信号灯是绿色的(state==0),但是A把信号灯改为红色了(实际值为1),期望值与实际值不同,无法修改
所以compareAndSetState(0,1)返回flase
所以B只能执行
acquire(1);


现在总结一下:
7.5.2.1 B线程的acquire()阻塞方法
7(AQS) 5(源码分析) 2(B线程) 1(acquire())
书接上文,A占有锁,信号灯state==1,为红色
B被阻塞进入acquire(),
注意这个方法 , 请记忆这个方法 ,或者手机拍照这个方法
否则 您会迷失 :

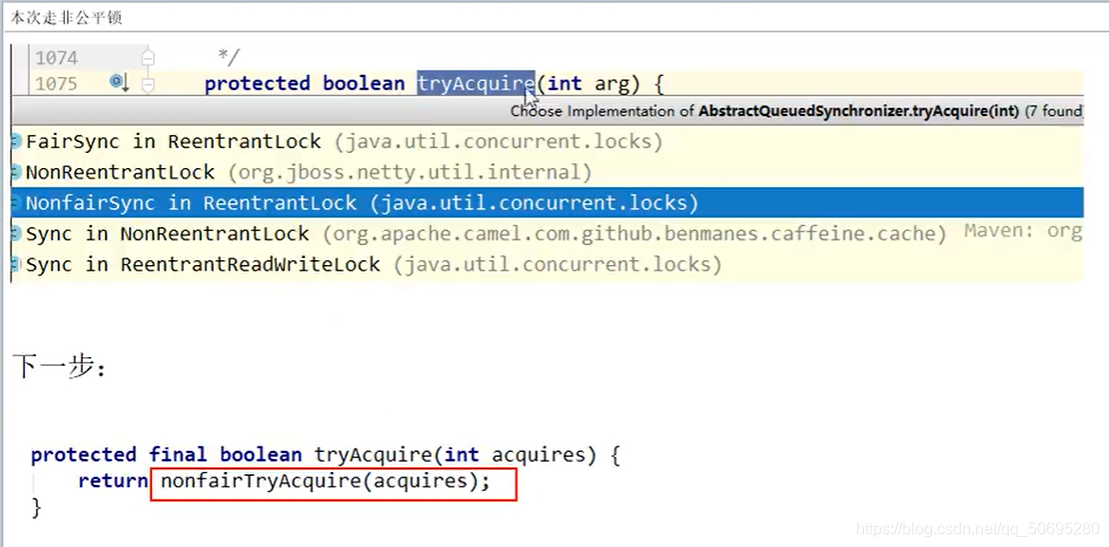
7.5.2.1.1 B线程的tryAcquire(1)到非公平锁里通过比较并交换强执行权
7(AQS) . 5(源码分析). 2(B线程) .1(acquire()) . 1(tryAcquire())
B先进入了tryAcquire(1)方法

B一脸懵逼 这是个啥?为什么没有逻辑语句就给我抛异常了?
这其实是模板方法设计模式,
子类必须实现此方法,否则父类就会抛出异常.
模板放的足够高(父类定义)
落地却很低(子类实现)
B知道了它只能走此类子类的实现方法

,ReentrantLock的默认是非公平的进入第二个

点击进入
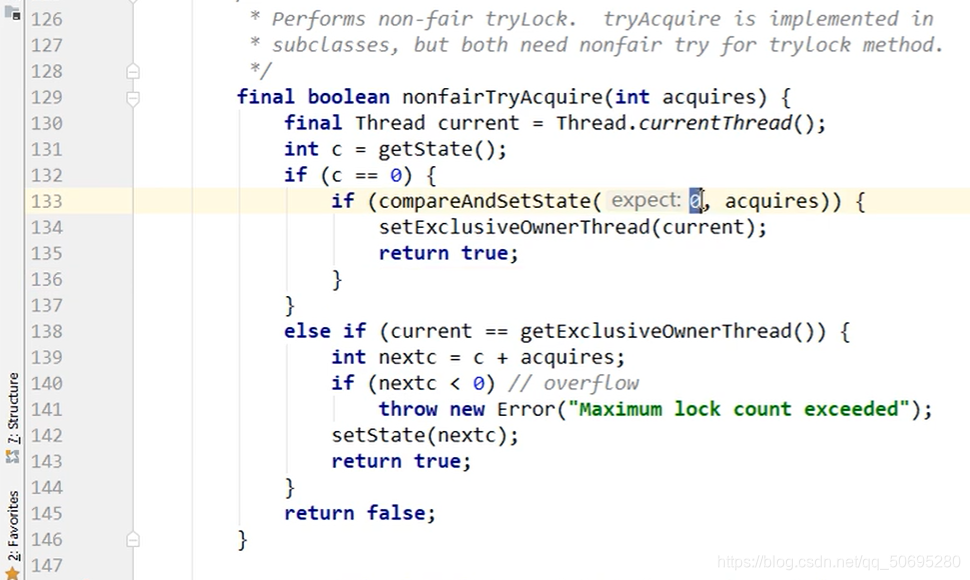
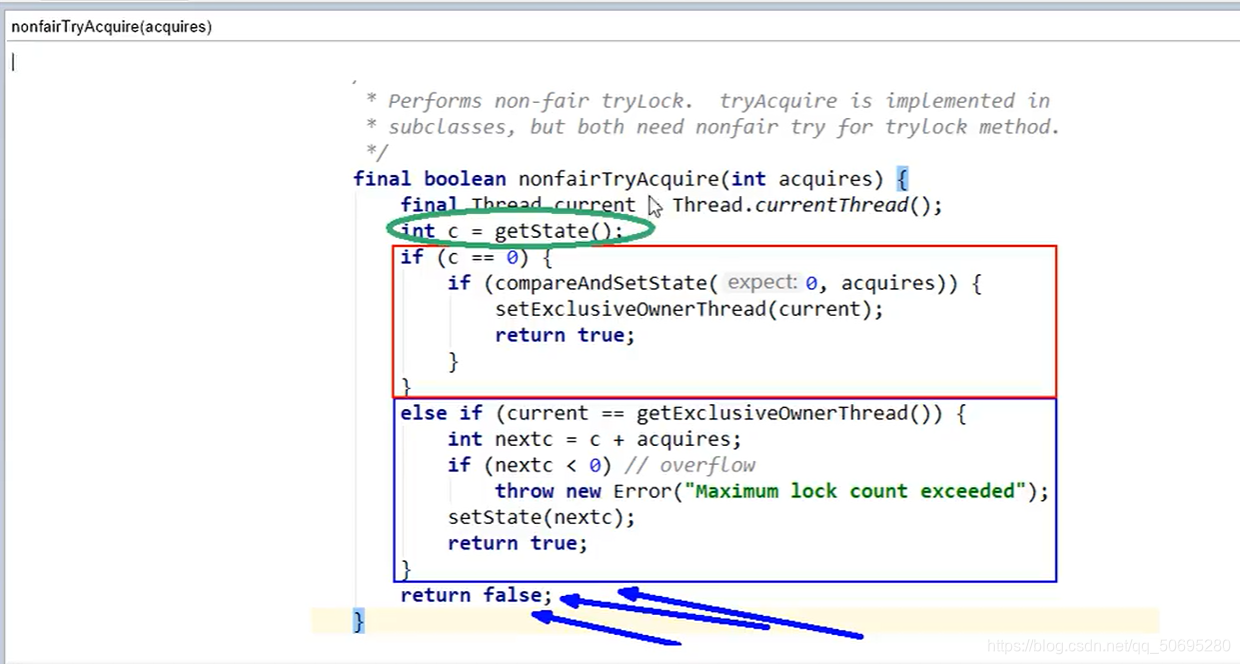
getState()就是获取信号灯的值 已经被A修改为 1 了
所以c!=0
然后通过getExclusiveOwnerThread()判断坐在凳子上的是不是进来的线程
A坐在凳子上,而B走的这个方法
所以是flase
最后tryAcquire()返回flase
---------------------------我是分割线,以下内容与主事件无关----------------------------------
if
如果B刚好走到这里
A刚刚好就完事了,A把信号灯改回了绿色(state改回了0)
即132行的 c==0,
133行compareAndSetState(0,1)比较并交换,
点击进入 —> 比较并交换的CAQ思想
setExclusiveOwnerThread(B线程),
B比较并交换后,
屁股马上坐到了凳子上(将当前占用窗口的值设置为当前线程)
,
eles if
如果B刚好走到这里,
A刚刚好就完事了
但是A又强到执行权 (B在A后面,A站起来了 ,B还没执行,A屁股又坐在了凳子上)
int nextc = 1 +1 ;
setState(2);
return true;
这其实是可重入锁的应用
-----------------------------------我是分割线,平行宇宙结束,进入主事件,--------------------------------
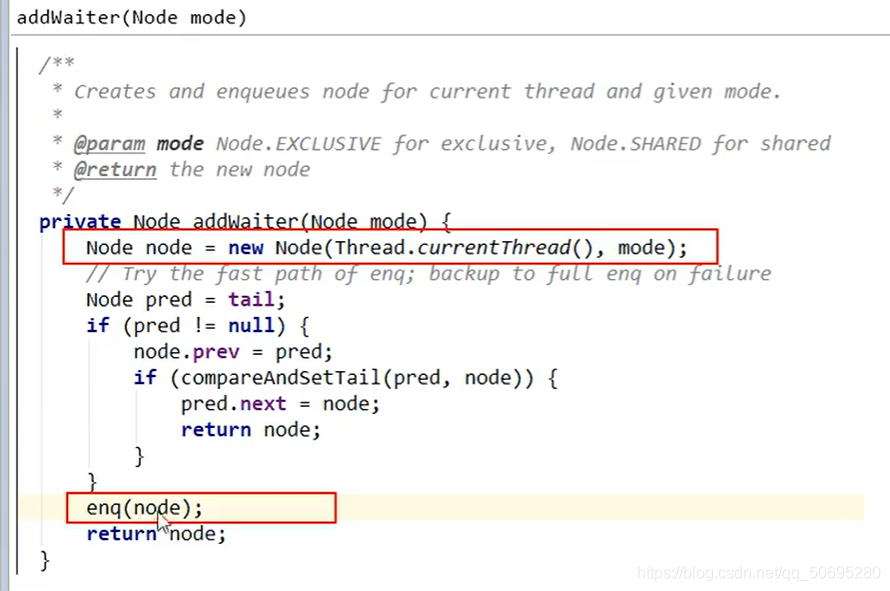
7.5.2.1.2 B线程的addWaiter(Node.EXCLUSIVE)
7(AQS) . 5(源码分析). 2(B线程) .1(acquire()) .2(addWaiter(Node.EXCLUSIVE))
我们回到

,最后tryAcquire()返回flase,取反 返回true
======================进入addWaiter(Node.EXCLUSIVE),-------------------------------------
Node.EXCLUSIVE是独占的意思,上面有Node类的细节详解(是黑色图片)
点击进入
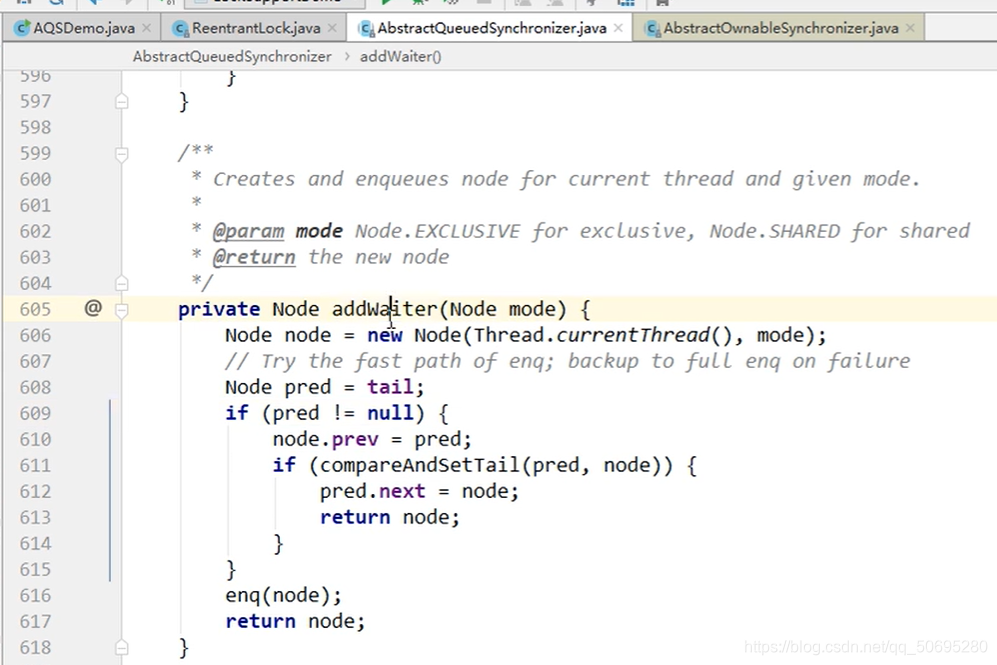
上图606行参数:
当前线程 是B线程 , Thread.currentThread() 是B线程
mode 英文注解 :Node.EXCLUSIVE
把当前线程和线程的状态(独占)封装成一个新的Node节点
608行
记得Node的属性有前后指针吗
tail 就是尾节点同步器的指针
tail赋值给pred,现在阻塞队列还没有人,(A在凳子上,B在这里执行,C还没出生呢)
tail==null,
609行
不执行 if里面的内容
进入616行
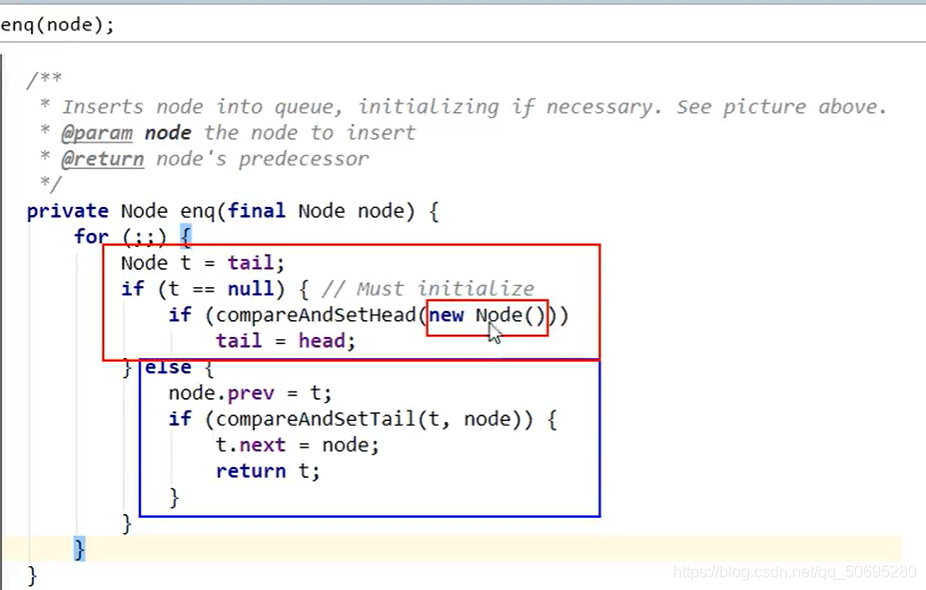
---------------------------------------------enq(node)执行入队方法------------------------------------------------
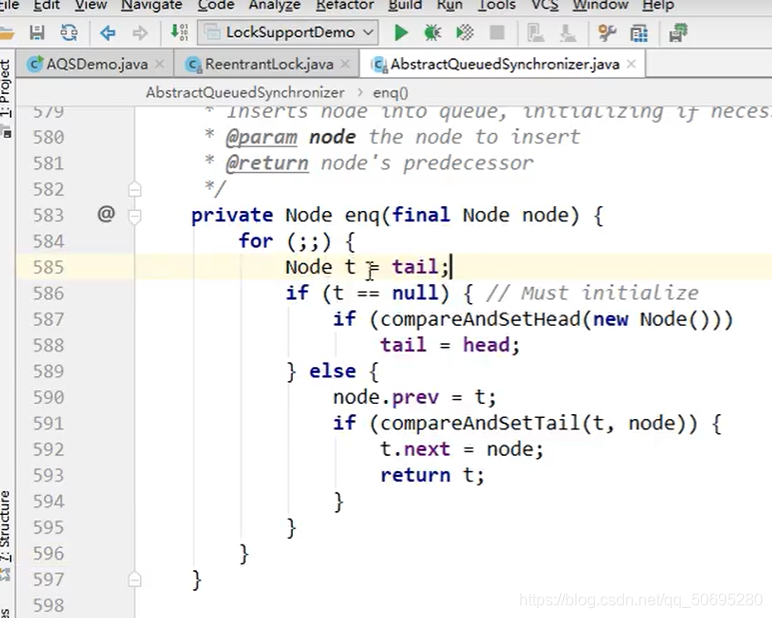
for(;;)等同于while(true)
585行
尾指针的值赋值给 t,(t现在没有指向任何人) ,t==null
587行
compareAndSetHead(new Node()),这里new了一个Node(),所以说enq入队的第一个节点不是我们的B,而是一个傀儡节点,哨兵节点,用于占位,把阻塞队列同步器的头指针指向这个傀儡节点,

588行
尾指针也和头指针一样指向这个傀儡节点
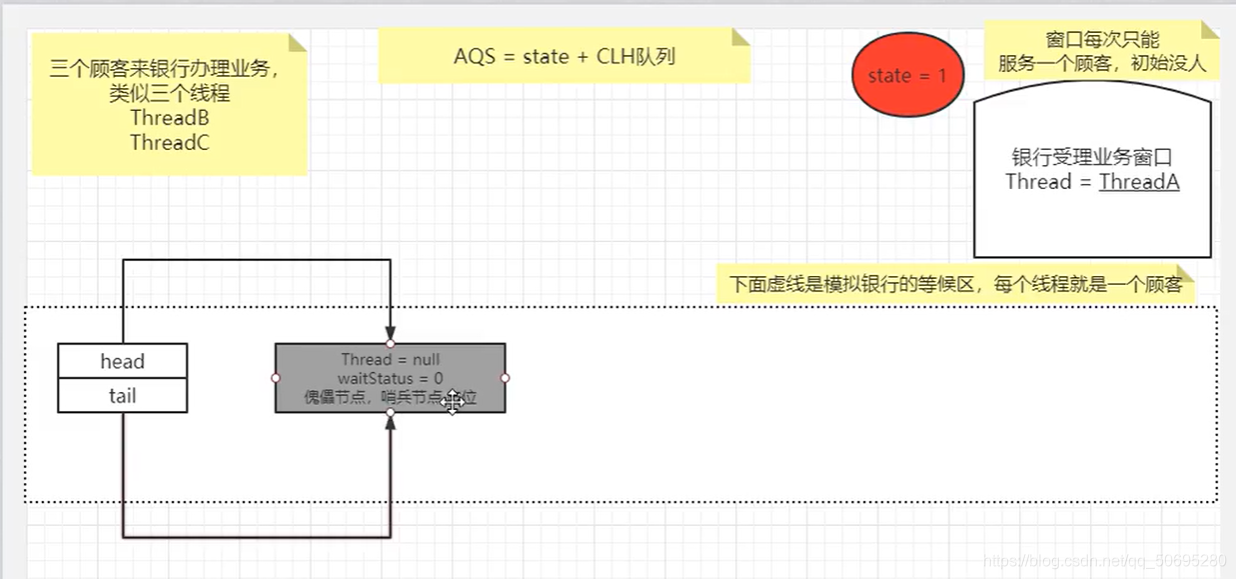
--------------------------再次进入enq(node)执行入队方法,开启平行宇宙,此时傀儡节点已经在队列中-------------------------------------------
由于队列的尾指针tail指向了傀儡节点,所以不执行585行
执行589行 }eles{
B节点开始真真正正的入队
590行node.prev = t;
B节点的前指针指向傀儡节点(节点是前后指针)
591行if(compareAndSetTail(t,node)){
队列同步器的尾指针指向B节点 (同步器是头尾指针)
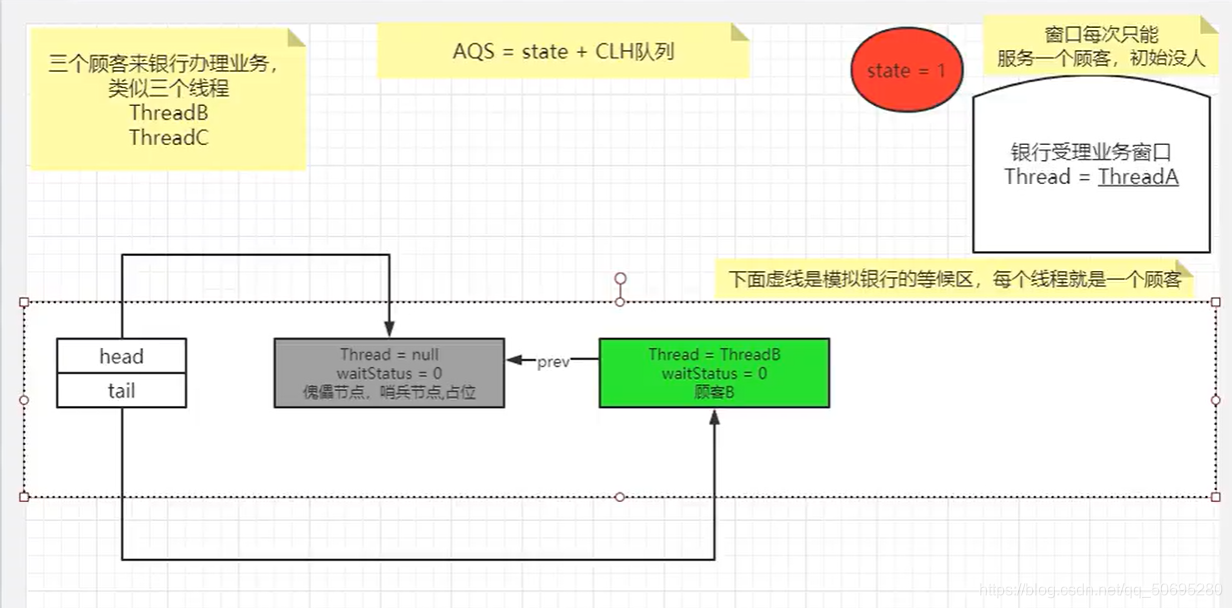
592行t.next=node;
傀儡节点的后指针,指向B节点
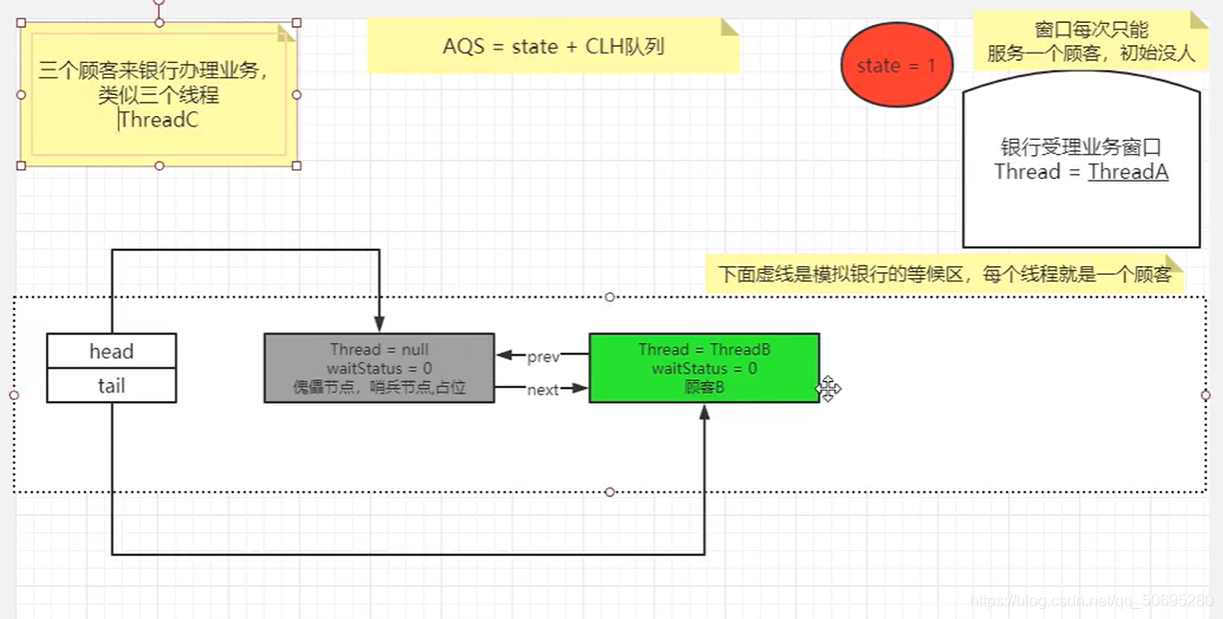
593行return t;
--------------------------平行宇宙结束,此时B节点已经在队列中-------------------------------------------
---------------------------------------------enq(node)入队方法结束------------------------------------------------
return node;
======================addWaiter(Node.EXCLUSIVE)方法结束-------------------------------------
7.5.3.1 C线程
7(AQS) . 5(源码分析). 2(C线程) .1(acquire())
C线程的tryAcquire(1)到非公平锁里通过比较并交换强执行权,
但是没有抢到 ,
执行addWaiter(),执行enq()加入队列

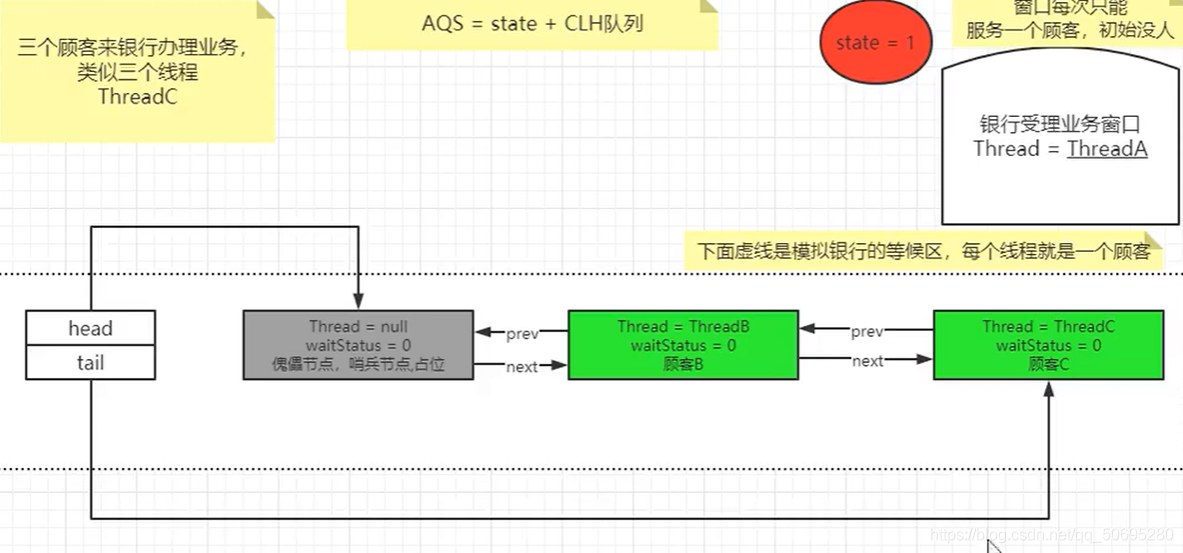
7.6小结源码
AQS的acquire方法
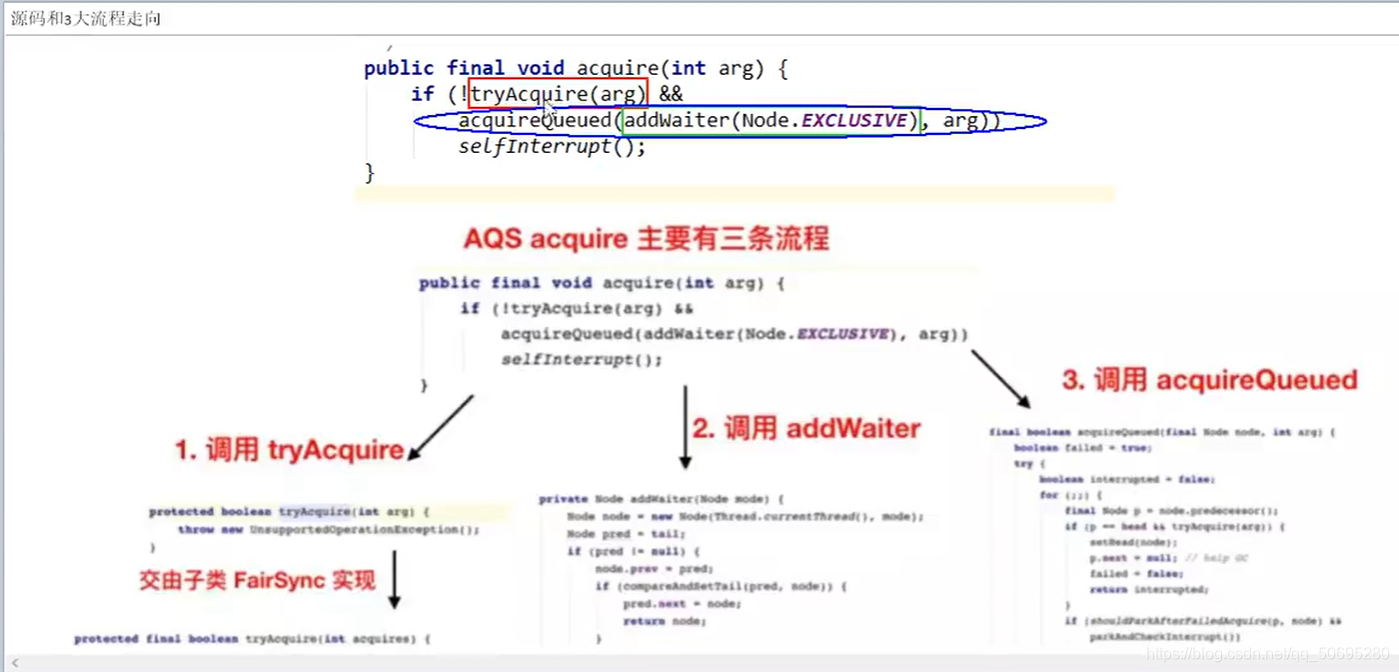

tryAcquire()方法
nonfairTryAcquire() 返回 false 继续推进条件addWaiter()
返回true 结束
addWaiter(Node mode)
enq(node)
傀儡节点在第一个
B在队列的第二个
7.7 acquireQueued(addWaiter(Node.EXCLUSIVE),arg)
还有最后一个方法acquireQueued(addWaiter(Node.EXCLUSIVE),arg)
我们还是将B线程执行来带入看看

进入看看:
-------------------------acquireQueued(node,arg)方法-----------------------------------------------------

862行调用node.predecessor();
进去看看

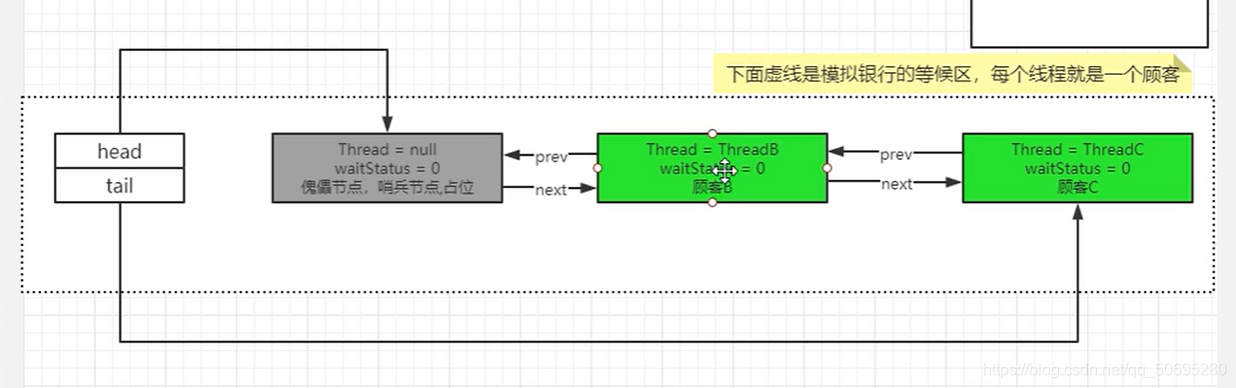
我们B节点的prev就是哨兵节点
862行调用node.predecessor();返回的就是哨兵节点
863行if(p= =head&&tryAcquire(arg)){
p是哨兵节点,队列同步器的头指针指向哨兵节点
p==head返回true
tryAcquire(arg)通过非公平锁抢cpu,
让B线程再次去强一下,由于A在窗口的凳子上,B抢不到,返回false,(解析上面有,走的是下图方法)
863行if(p==head&&tryAcquire(arg)){
返回flase
869行if(shouldParkAfterFailedAcquire(p,node)&&
---------------------------shouldParkAfterFailedAcquire(pred,node)开启----------------------------
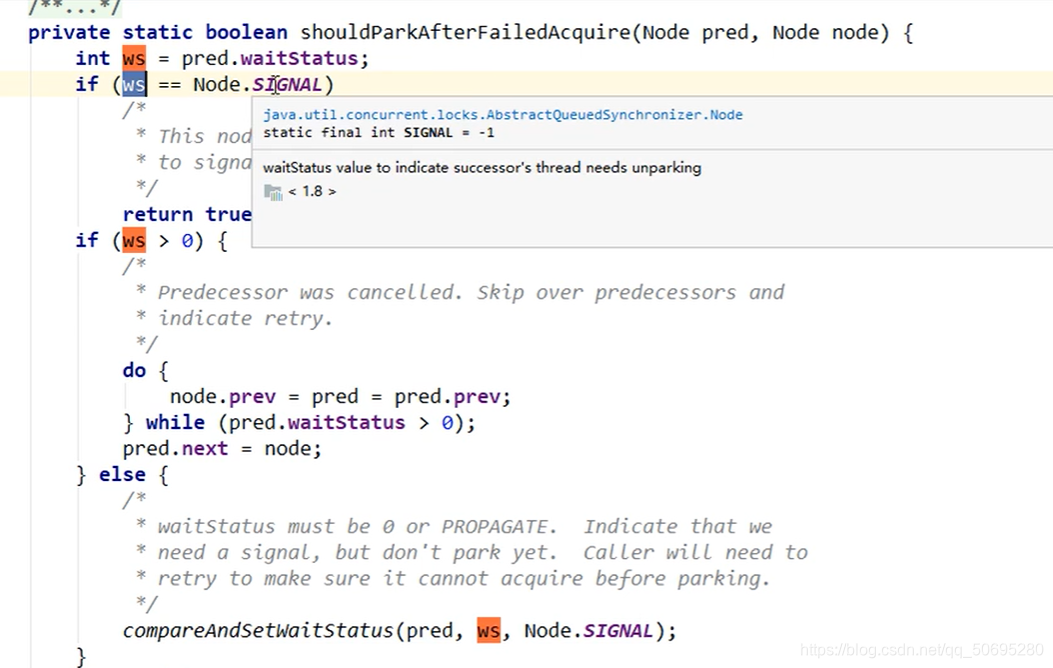

此方法的第一个参数pred就是哨兵节点,
pred.waitStatus是0(线程等待的状态是0,上面有张Node节点的属性的黑色图片,唯一一张黑色图片)
ws=pred.waitStatus = = 0;
Node.SIGNAL==-1(这也是那张黑色图片上的Node属性)
ws!=Node.SIGNAL,不走if(ws == Node.SIGNAL){
ws也不大于0,不走if(ws > 0){
所以
走compareAndSetWaitStatus(pred,ws,Node.SIGNAL);
比较并交换
compareAndSetWaitStatus(哨兵节点,0,-1);
将哨兵节点的等待状态改为-1
return false;
---------------------------shouldParkAfterFailedAcquire(pred,node)开启平行宇宙------------
pred是哨兵节点,但是哨兵节点的等待状态已经被改为了-1
ws=pred.waitStatus==-1;
if(-1 = = Node.SIGNAL = = -1){
return true;}
---------------------------shouldParkAfterFailedAcquire(pred,node)平行宇宙结束------------
---------------------------shouldParkAfterFailedAcquire(pred,node)结束--------------------------
当shouldParkAfterFailedAcquire(pred,node)返回true的时候,指向870行

acquireQueued(node,arg)方法的870行parkAndCheckInterrupt()方法如下:
private final boolean parkAndCheckInterrupt(){
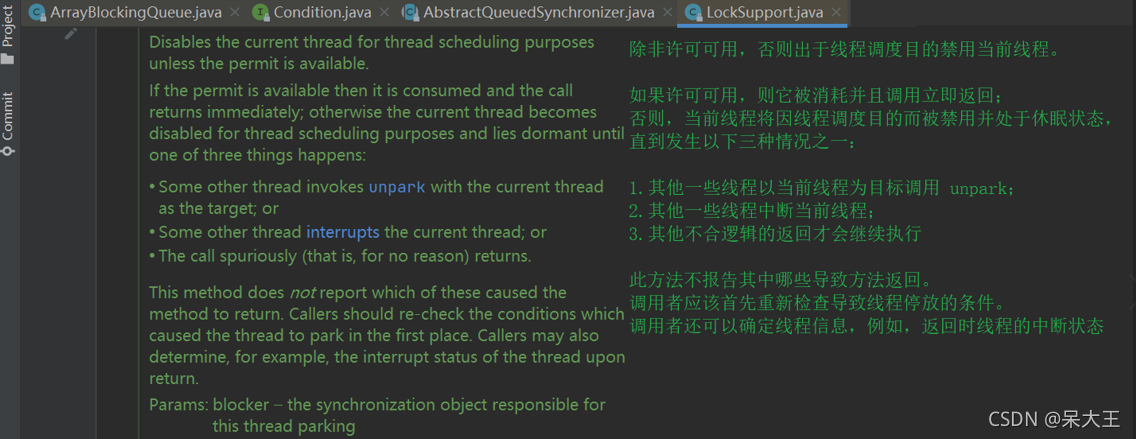
LockSupport.park(this);//this是当前线程,把B线程挂起,B线程没有停止
//根据park方法API描述.程序在下述三种情况下回继续执行
//1.被unpark
//2.被中断(interrupt)
//3.其他不合逻辑的返回才会继续执行
//由于上述三种情况程序执行到此行,返回当前线程的中断状态,并清空中断状态
//如果由于被中断,改方法返回true
return Thread.interrupted();
}
B被park()挂起
B真真正正的坐在了候客区的椅子上
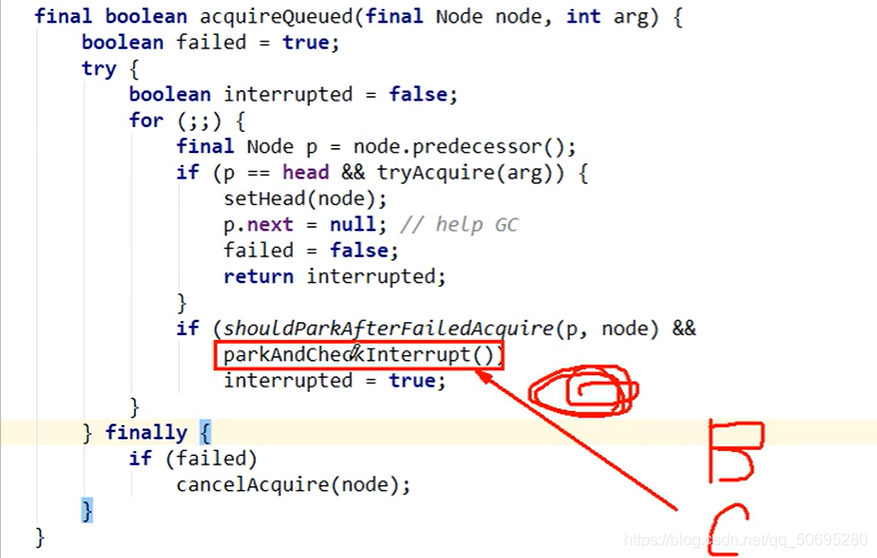
注意 :请手机拍照上图
由于BC线程在parkAndCheckInterrupt()方法内部挂起,
finally{
if(failed)cancelAcquire(node);
finally就是取消排队
B线程等着不等了走了
-------------------------acquireQueued(node,arg)方法结束-----------------------------------------------------


发现这是一个模板方法
逼着子类必须实现此方法
我们进入子类的实现方法

----------------tryRelease(int releases)开始------------------------------------------------
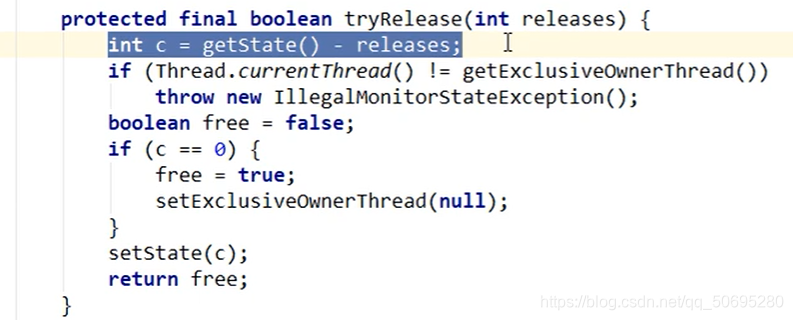
上图中
A线程的getState()==1;
而一路传递下来的releases==1
int c == getState() - releases ;
int c = = 1-1;
int c = = 0;
做了个健壮型判断,如果当前线程不是窗口占用线程抛出异常(因为是unlock()方法,必须是持有锁的线程才可以调用unlock()方法)
setExclusiveOwnerThread(null);设置当前窗口的占用线程为null;
setState©;//把0设置给状态state标识位
return free;
return true;
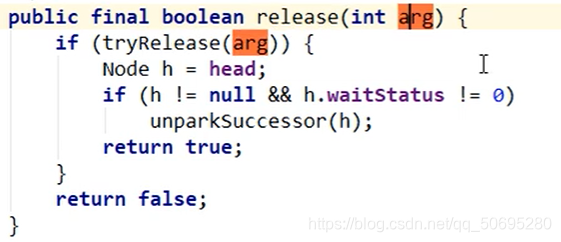
----------------tryRelease(int releases)结束------进入release(1)------------------------------------------
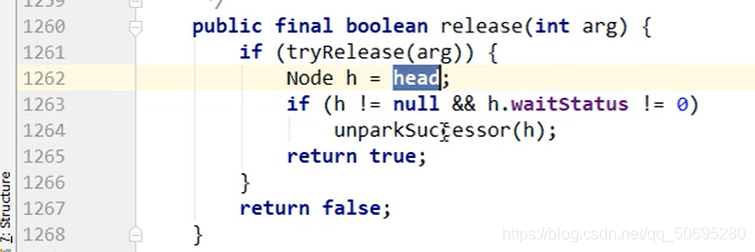
1262行head是队列同步器的头指针
就是我们的哨兵节点
1262行
哨兵节点不为null同时,哨兵节点的waitStatus等待状态为-1
-------------------------------进入unparkSuccessor(哨兵节点)----------------------------------
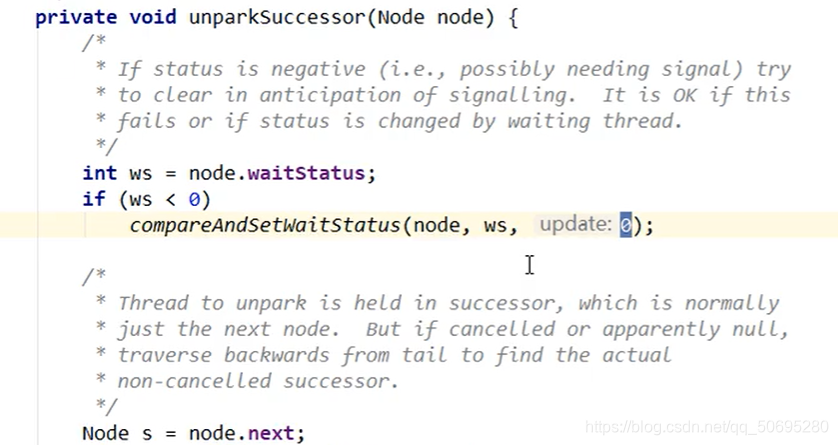

哨兵节点的waitStatus等待状态为-1,compareAndSetWaitStatus(哨兵节点,-1,0);
比较并交换,将哨兵节点的等待状态改为0

node.next就是我们哨兵节点的下一个节点(B节点),s就是B节点
B节点不等于null
B节点的等待状态也不大于0(等于0)
不进入if( s == null || s.waitStatus > 0){
进入
LockSupport.unpark(s.thread);
通知B线程停止挂起,而B线程在parkAndCheckInterrupt()的候客区椅子上坐着
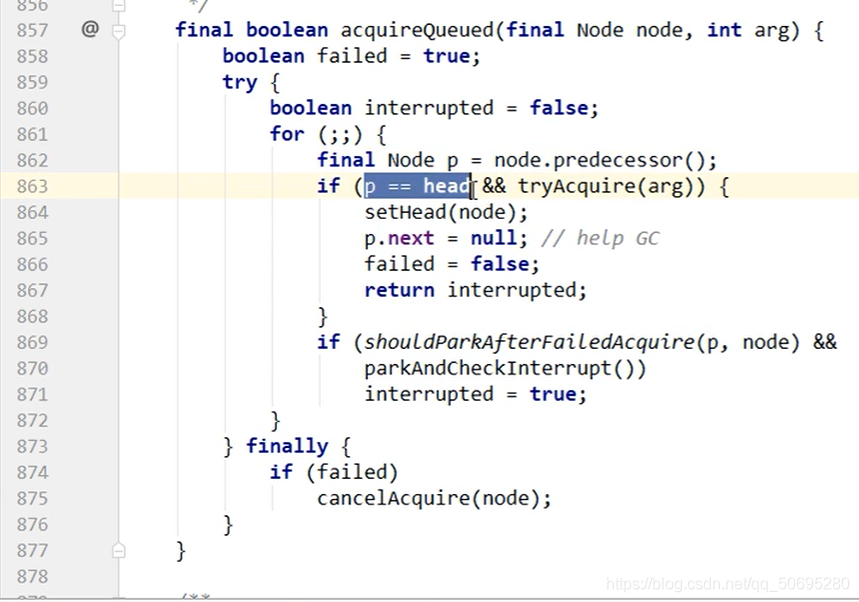
现在B跳出869行的if(shouldParkAfterFailedAcquire(p,node)
进入下面的白底图的tryAcquire(arg),进入它的子类的nonfairTryAcquire(),
由于A走了信号灯变成绿色的了 getState()==0
compareAndSetState(0,acquires)比较并交换,期望是0,变化为0,返回true
setExclusiveOwnerThread(B线程);B线程坐在窗口的凳子上
返回true
所以B线程执行nonfairTryAcquire(),

现在一个B在窗口办理业务
一个B在队列里这是不合理的

由于上图的for(; ; ){}是个死循环 同时队列的头指针指向哨兵节点
所以上图的if(p == head && tryAcquire(arg){开始执行
上图864行setHead(node)
private void setHead(Node node){
head = node;//队列中的头指针指向B节点
node.thread =null;//B节点的封装的thread已经坐了办理业务的窗口凳子上,所以变成null.
node.prev = null;//B节点的前指针变成null
//原来的哨兵节点只剩下一个next指向B节点了,
}
上白底图865行原来哨兵节点的最后一个引用也被清空,下次GC 原哨兵会被回收
原来的B节点变成新的哨兵,
B线程出队,办理业务
----------------tryRelease(int releases)结束-----------------------------------------------

AQS完结撒花
★,°:.☆( ̄▽ ̄)/$:.°★ 。
八并发机制底层实现原理
java代码通过编译变成字节码,字节码通过加载,验证,准备,解析,初始化后完成加载过程
当然这是题外话
8.1volatile的实现原理
https://blog.csdn.net/qq_50695280/article/details/114855608.
8.2原子操作的实现原理
在java可以通过锁和循环CAS的方式实现原子操作
(1)使用循环CAS实现原子操作
自旋CAS实现的基本思路是循环进行CAS操作直到成功,
CAS的缺点:
- ABA问题
- 循环 时间开销大
- 只能保证一个共享变量的原子操作
(2)使用锁机制实现原子操作
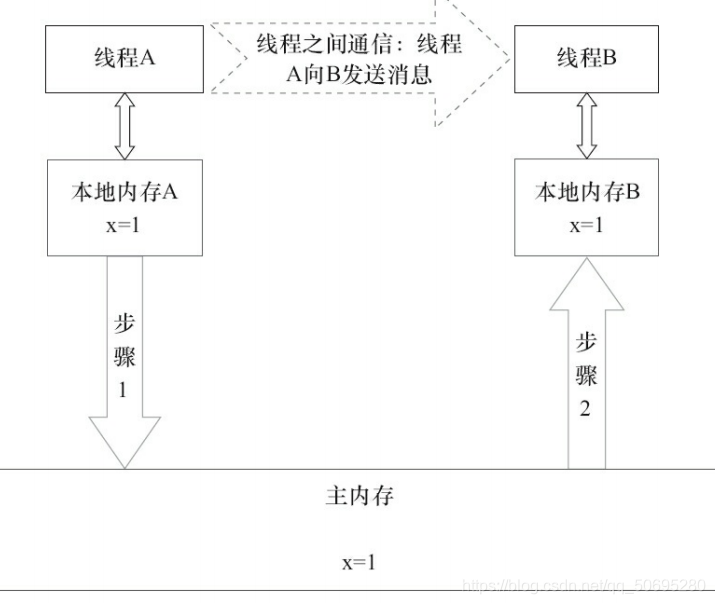
九Java内存模型
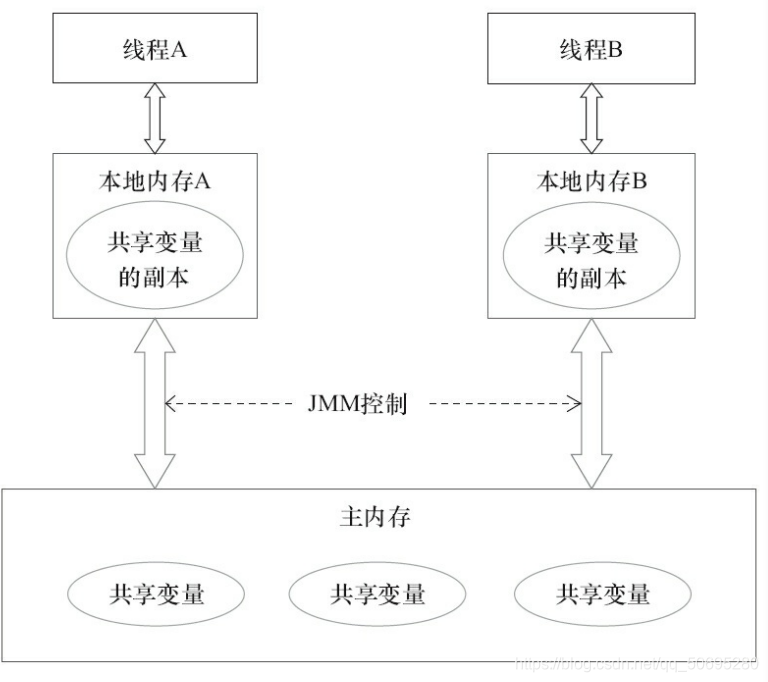
线程A与线程B通信必须经历下面2步
- 线程A吧本地内存A更新过的共享变量刷新到主内存中去
- 线程B到主内存中读取线程A已更新过的共享变量
十快速失败与安全失败
java.util包的集合都是快速失败,
迭代器遍历集合对象时,对遍历过程中的集合对象内容修改会快速失败
原理
1.迭代器在遍历时,直接访问集合内容,并使用一个modCount变量
2.集合在遍历过程中内容变化会改变变量的值
3.迭代器使用hashNext/next遍历下一个元素前会检查变量是否改变
4.改变抛出异常
juc下的容器都是安全失败的
遍历时,先copy原有集合内容,在拷贝的集合上遍历
原理
是对原集合的拷贝值遍历,所以遍历过程中修改原集合迭代器无法检测
不会抛出异常
缺点:
迭代器无法访问到修改后的内容,(遍历的是开始遍历那一刻拿到的集合拷贝,之后的修改迭代器不知道)
与程序员密切相关的happens-before规则如下::
- 程序顺序规则:一个线程每个操作,happens-brfore于该线程中的任意后续操作
- 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读
- 传递性:如果A happens-before B,且 B happens-before C,那么A happens-before C
这些规则是什么意思?
我也不清楚。
多少工资对得起这些规则?
//TODO
//理解这些规则
十一重排序
重排序是 编译器 和 处理器 为了性能优化 而对指令序列进行重新排序的方式
11.1数据依赖性
如果两个操作访问同一个变量,且有一个操作为写操作,那么这两个操作就存在数据依赖性
注意:
- 编译器 和 处理器 做重排序不会改变数据依赖性关系
- 数据依赖性仅针对单个处理器
11.2顺序一致性内存模型
顺序一致性内存模型是一个理想化的理论参考模型
特征是:
- 一个线程中的所有操作必须按照程序顺序执行
- 所有线程都只能看到一个单一操作执行顺序,在顺序一致性内存模型中,每个操作必须原子执行且立刻对所有线程可见
假设有两个线程AB,他们分别有3个操作,操作的执行顺序是:A1>A2>A3与B1>B2>B3
假设这两个线程使用监视器锁来正确同步:A线程的3个操作执行后释放监视器锁,随后B
线程获取同一个监视器锁。那么程序在顺序一致性模型中的执行效果将如图所示。
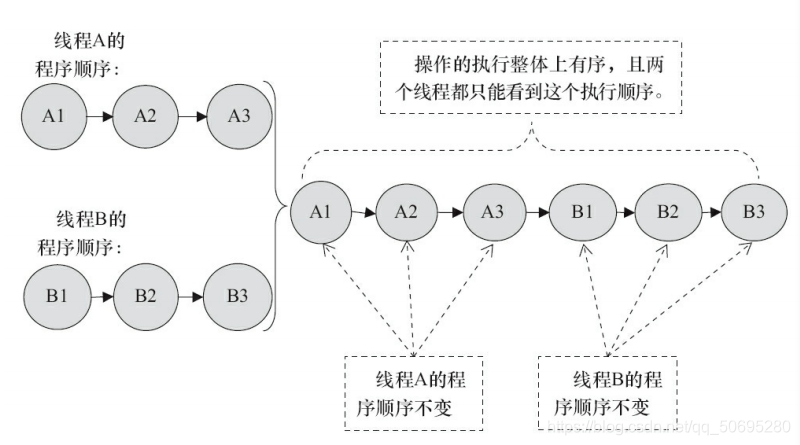
如果两个线程没有做同步,那么程序在顺序一致性模型中的执行示意图:
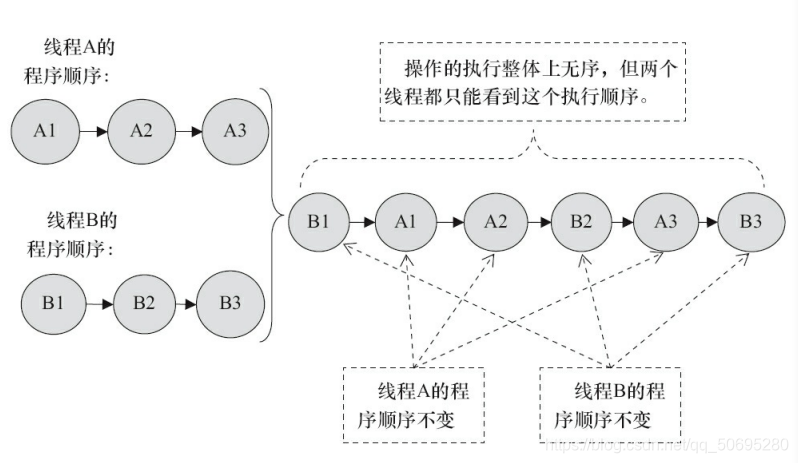
没有同步程序在顺序一致性模型中,虽然整体执行无序,但所有线程只能看到一个一致的整体执行顺序
如上图顺序为:B1>A1>A2>B2>A3>B3,
正是由于顺序一致性内存模型的每个操作 必须 立即对 任意线程可见保证了类似这样的顺序…
lass SynchronizedExample {
int a = 0;
boolean flag = false;
public synchronized void writer() { // 获取锁
a = 1;
flag = true;
} // 释放锁
public synchronized void reader() { // 获取锁
if (flag) {
int i = a;
} // 释放锁
}
}
我们假设线程A执行writer()方法后,线程B执行reader()方法,下图是上面代码在顺序一致性模型与JMM执行过程对比图:
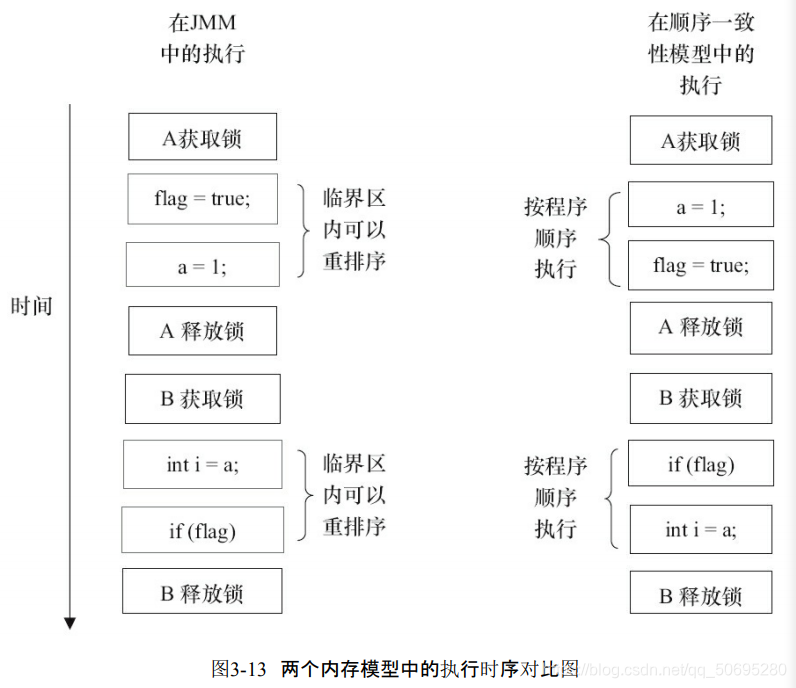
在顺序一致性模型中,所有的操作完全按程序顺序串行执行
在JMM中,临界区内代码可以重排序(但是JMM不容许临界区代码"“溢出”"到临界区外,这样会破坏监视器的语义),
线程A在在临界区做了重排序,但是由于监视器互斥的特征,线程B不知道线程A在临界区的重排序,
这样既提高了效率,有没有改变程序执行结果…
JMM在具体实现上的基本方针为:在不改变(正确同步的)程序执行结果的前提下,尽可能为编译器和处理器优化打开方便之门.
十二线程
12.1线程简介
12.1.1 什么是线程
操作系统在运行一个程序时,会为其创建一个进程
操作系统调度的最小单元是线程
一个进程可以创建多个线程,这些线程都拥有自己的计数器,站堆 和局部变量 等属性,且可以访问共享变量
12.1.2 线程优先级
线程会被系统分配若干时间片,当线程的时间片用完会发生线程调度,
而线程优先级决定了分配多少处理器资源的一个线程属性
优先级的范围是 1~10
默认是优先级是 5
修改优先级的方法是 setPriority(int)
设置优先级小技巧
针对 阻塞频繁(休眠或者I/O操作)的线程 设置较高优先级
针对 偏重计算(需要较多CPU时间)的线程 设置较低优先级
确保处理器不被 独占
来一个小测试
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* The minimum priority that a thread can have.
* 线程可以拥有的最低优先级。
* public final static int MIN_PRIORITY = 1;
* <p>
* The default priority that is assigned to a thread.
* 分配给线程的默认优先级。
* public final static int NORM_PRIORITY=5;
* <p>
* The maximum priority that a thread can have.
* 线程可以拥有的最大优先级。
* public final static int MAX_PRIORITY=10;
*/
public class Priority {
/**
* 定义变量
*/
private static volatile boolean notStart = true;
private static volatile boolean notEnd = true;
public static void main(String[] args) throws Exception {
List<Job> jobs = new ArrayList<Job>();
//给前5线程设置低优先级,给后5线程设置高优先级
for (int i = 0; i < 10; i++) {
int priority = i < 5 ? Thread.MIN_PRIORITY : Thread.MAX_PRIORITY;
Job job = new Job(priority);
jobs.add(job);
Thread thread = new Thread(job, "Thread:" + i);
thread.setPriority(priority);
thread.start();
}
//改变变量
notStart = false;
TimeUnit.SECONDS.sleep(10);
notEnd = false;
//打印输出
for (Job job : jobs) {
System.out.println("Job Priority : "
+ job.priority
+ ",Count : "
+ job.jobCount);
}
}
static class Job implements Runnable {
private int priority;
private long jobCount;
public Job(int priority) {
this.priority = priority;
}
@Override
public void run() {
while (notStart) {
//当前线程放弃CPU,和其它线程一起抢夺一次CPU
Thread.yield();
}
while (notEnd) {
Thread.yield();
//变量值++
jobCount++;
}
}
}
}
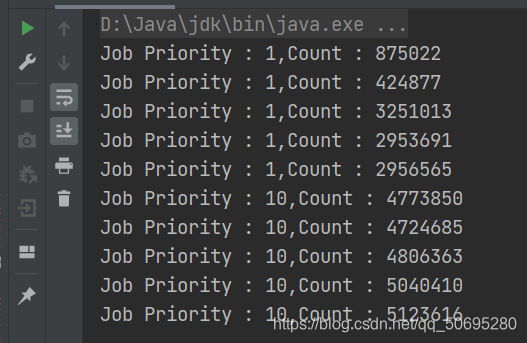
可以看出在这台电脑上优先级的影响还是蛮大的,优先级为1的值要明显小于优先级为10的

注意:
Java将操作系统中的运行和就绪两个状态合并称为 运行状态。
线程进入synchronized修饰的方法或者代码块的状态,,
java.concurrent包下Lock接口的线程状态 是 等待状态,,因为Lock接口对于阻塞的实现使用了LockSupport的方法
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc,
boolean inheritThreadLocals) {
//当前线程为父线程
Thread parent = currentThread();
this.name = name;
this.group = g;
this.daemon = parent.isDaemon();
this.priority = parent.getPriority();
//设置当前线程的contextClassLoader为同父线程一样
if (security == null || isCCLOverridden(parent.getClass()))
this.contextClassLoader = parent.getContextClassLoader();
else
this.contextClassLoader = parent.contextClassLoader;
this.inheritedAccessControlContext =
acc != null ? acc : AccessController.getContext();
this.target = target;
setPriority(priority);
//设置当前线程的InheritableThreadLocal同父线程一样
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
//将新线程放到堆里
this.stackSize = stackSize;
//设置线程ID
tid = nextThreadID();
}
子线程继承了父线程的 Daemon 优先级 加载资源的contextClassLoader以及可继承的threadLocal,
同时还被分配一个唯一的ID标识子线程,
一个新鲜的线程就出锅了,在碗里(堆里)等待着我们操作.
这里的daemon在12.2.3 线程终止会详细介绍
12.2线程常见动作
12.2.1启动线程
线程对象的初始化完成后,调用start()方法可以启动线程
start(): 当前线程(即父线程)告诉JVM,只有线程规划器空闲,就立即启动调用start()方法的线程
12.2.2线程中断

中断就是线程的一个标识属性,表示一个运行的线程是否被其它线程进行了中断操作.
其它线程通过interrupt()方法对本线程进行中断操作.
本线程通过isInterrupted()方法检查自身是否被中断,也可以调用Thread.interrupted()对当前线程的中断标识位进行复位,
isInterrupt()方法返回Boolean值,
为true表示拥有打断标识
为false表示没有打断标识正在阻塞的线程
- 当线程正在阻塞时(线程调用了sleep,wait等方法)被打断, 会抛出InterruptedException异常,同时中断标识符不会改变
- 当线程正常运行时被打断则中断标识符正常改变
注意如果本线程是终结状态,那么即使该线程被中断过,在调用该线程对象的isInterrupted()方法后返回值为false
来吧直接看代码:
@Slf4j
public class interruptDemo {
public static void main(String[] args) throws InterruptedException {
test1();
}
public static void test1() throws InterruptedException {
Thread t1 = new Thread(() -> {
sleep(5000);
});
t1.start();
Thread.sleep(1000);
log.error("interrupt");
t1.interrupt();
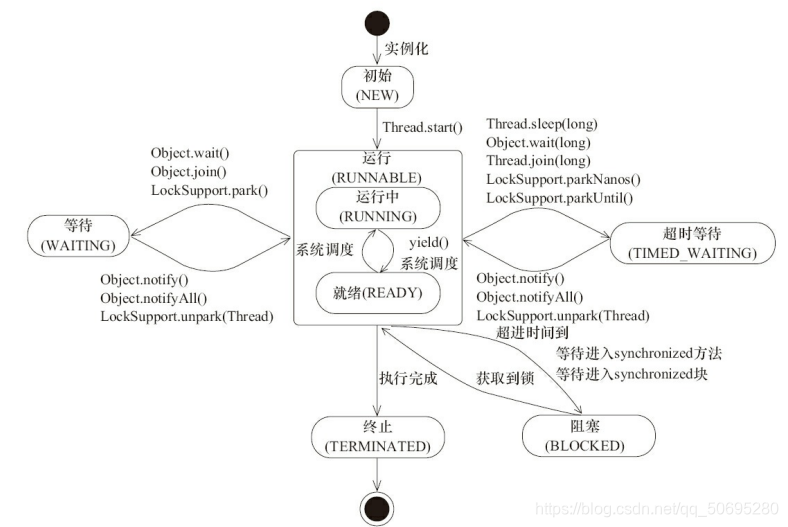
boolean interrupted = t1.isInterrupted();
log.error(String.valueOf(interrupted));
}
}
通过interrupt()方法和isInterrupted()方法的配合
我们可以得到一个Boolean类型的打断标识
我们可以通过打断标识来做一些真正的打断操作
/**
* 通过interrupt()方法和isInterrupted()方法的配合
* 我们可以得到一个Boolean类型的打断标识
* 我们可以通过打断标识来做一些真正的打断操作
*/
@Slf4j
public class interruptDemo使用 {
public static void main(String[] args) throws InterruptedException {
test2();
}
public static void test2() throws InterruptedException {
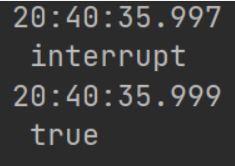
Thread t1 = new Thread(() -> {
while (true){
boolean interrupted = Thread.currentThread().isInterrupted();
if (interrupted){
log.error("被打断了,被迫退出");
break;
}
}
});
t1.start();
Thread.sleep(1000);
log.error("interrupt");
t1.interrupt();
boolean interrupted = t1.isInterrupted();
log.error(String.valueOf(interrupted));
}
}
在java的Api里许多方法声明抛出InterruptedException异常之前,虚拟机会先将改线程的中断标识位(daemon)清除.
public static void main(String[] args) throws Exception {
//创建sleepThread
Thread sleepRunner = new Thread(new SleepRunner(), "SleepRunner");
//设置Daemon为true
sleepRunner.setDaemon(true);
//创建busyRunner
Thread busyRunner = new Thread(new BusyRunner(), "BusyRunner");
//设置Daemon为true
busyRunner.setDaemon(true);
sleepRunner.start();
busyRunner.start();
//main休息10秒
TimeUnit.SECONDS.sleep(10);
//sleepRunner被中断
sleepRunner.interrupt();
//busyRunner被中断
busyRunner.interrupt();
System.out.println("SleepThread interrupted:"+sleepRunner.isInterrupted());
System.out.println("BusyRunner interrupted:"+busyRunner.isInterrupted());
}
static class SleepRunner implements Runnable{
@Override
public void run() {
while (true){
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class BusyRunner implements Runnable{
@Override
public void run() {
while (true){
}
}
}

抛出InterruptedException的线程sleepThread 的标识位(daemon)被清除了,而一直运行的BusyThread中断标识位没有被清除
12.2.3线程两阶段终止模式
Two Phase Termination
通过标识来停止线程
下面代码为:
- interrupt()和isInterrupted()的配合用来终止线程
- 通过自定义标识cancel()方法用来终止线程
public static void main(String[] args) throws Exception {
Runner one = new Runner();
Thread countThread = new Thread(one, "CountThread");
countThread.start();
// 睡眠1秒,main线程对CountThread进行中断,使CountThread能够感知中断而结束
TimeUnit.SECONDS.sleep(1);
countThread.interrupt();
Runner two = new Runner();
countThread = new Thread(two, "CountThread");
countThread.start();
// 睡眠1秒,main线程对Runner two进行取消,使CountThread能够感知on为false而结束
TimeUnit.SECONDS.sleep(1);
two.cancel();
}
//自定义Runnable的实现类
private static class Runner implements Runnable {
private long i;
private volatile boolean on = true;
@Override
public void run() {
while (on && !Thread.currentThread().isInterrupted()) {
i++;
}
System.out.println("Count i = " + i);
}
public void cancel() {
on = false;
}
}
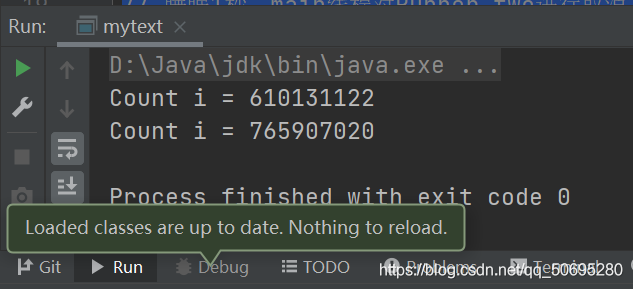
可见 无论是interrupt()还是cancel()都可以使线程终止,
这种通过标识位或者中断操作的方式使线程终止时有机会去清理资源,
比stop()给了被终止线程料理后事的机会
12.2.4线程阻塞状态下被中断
- 当线程正在阻塞时(线程调用了sleep,wait等方法)被打断, 会抛出InterruptedException异常,同时中断标识符不会改变
- 当线程正常运行时被打断则中断标识符正常改变
在来一个小例子,
我们有一个守护线程 每隔2秒运行一下,现在需要个按钮来一键停止这个守护线程,思路:
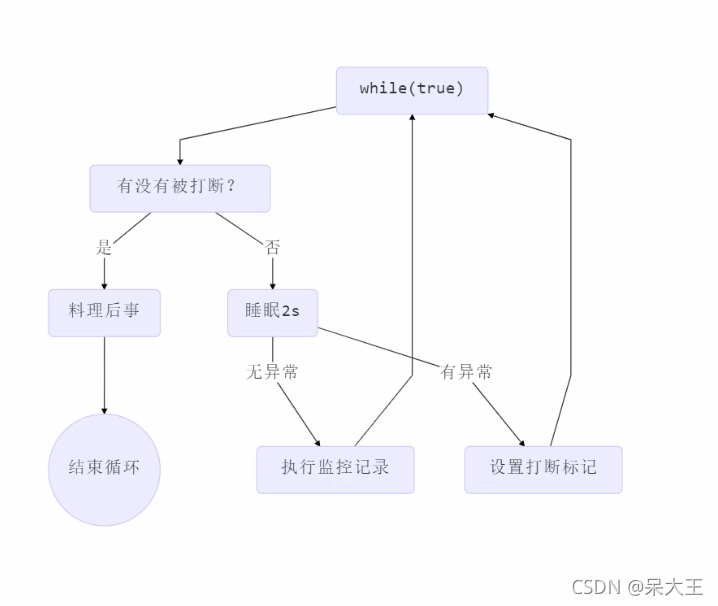
图为:第二个例子的思路图
@Slf4j
public class 线程阻塞与正常状态下被打断 {
public static void main(String[] args) throws InterruptedException {
TwoPhaseTermination tp = new TwoPhaseTermination();
tp.start();
Thread.sleep(3500);
tp.stop();
}
}
@Slf4j
class TwoPhaseTermination{
private Thread monitor;
//启动监控线程
public void start(){
monitor = new Thread(()->{
while (true){
//返回对当前正在执行的线程对象的引用。
Thread thread = Thread.currentThread();
if (thread.isInterrupted()){
log.error("开始料理后事");
break;
}
try {
Thread.sleep(1000);
log.error("守护线程开始干活了...");
} catch (InterruptedException e) {
//注意:如果线程正在阻塞状态被中断会抛出InterruptedException异常
//且中断标识不会正常改变
//所以一旦由于阻塞状态被中断进入catch,
//我们需要重新调用interrupt()方法来更新中断标识
thread.interrupt();
e.printStackTrace();
}
}
});
monitor.start();
}
//停止监控线程
public void stop(){
monitor.interrupt();
}
}
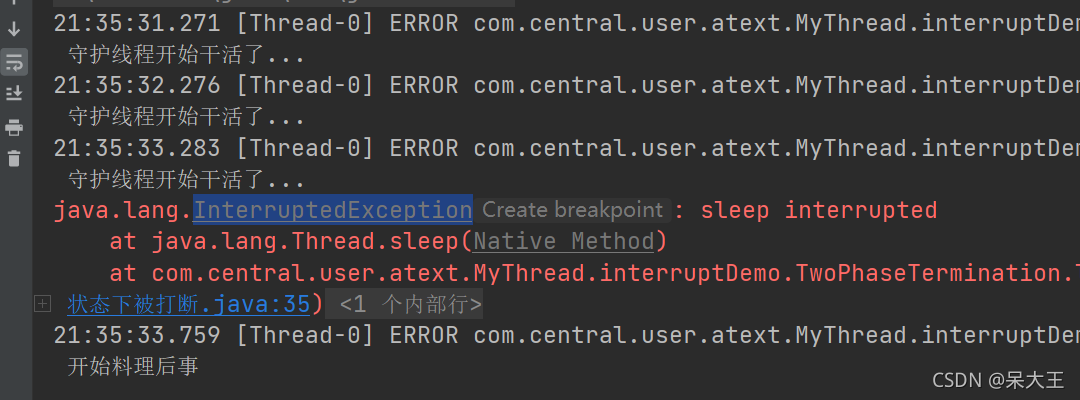
可以看出前3秒守护线程正常执行,
第3.5秒守护线程在sleep时被中断,
所以抛出异常,通过catch里的中断标识符复位
守护线程正常料理后事
12.2.5LockSupport.park()线程被中断
回忆一下 LockSupport的unpark与park
unpark函数为线程提供“许可(permit)”,线程调用park函数则等待“许可”。这个有点像信号量,但是这个“许可”是不能叠加的,“许可”是一次性的。
比如线程B连续调用了三次unpark函数,当线程A调用park函数就使用掉这个“许可”,如果线程A再次调用park,则进入等待状态。
注意,unpark函数可以先于park调用。比如线程B调用unpark函数,给线程A发了一个“许可”,那么当线程A调用park时,它发现已经有“许可”了,那么它会马上再继续运行。
那么当park遇上interrupt()会发生什么呢?
@Slf4j
public class LockSupportpark线程被中断 {
public static void main(String[] args) {
test3();
}
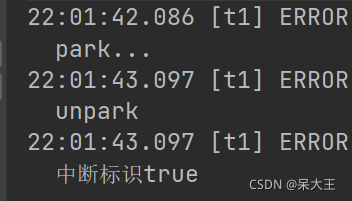
public static void test3() {
Thread t1 = new Thread(() -> {
log.error("park...");
//LockSupport.park()表示线程挂起,不在继续运行
LockSupport.park();
log.error("unpark");
Thread thread = Thread.currentThread();
log.error("中断标识" + thread.isInterrupted());
}, "t1");
t1.start();
sleep(1000);
t1.interrupt();
}
}
12.3线程的通信
12.3.1volatile和synchronized关键字
任意一个对象都拥有自己的监视器,当对象由同步块或者这个对象的同步方法调用时,执行方法的线程必须先获取该对象的监视器才能进入同步块,
没有获取监视器的线程将会被阻塞在同步块和同步方法的入口,进入BLOcked状态
未完成
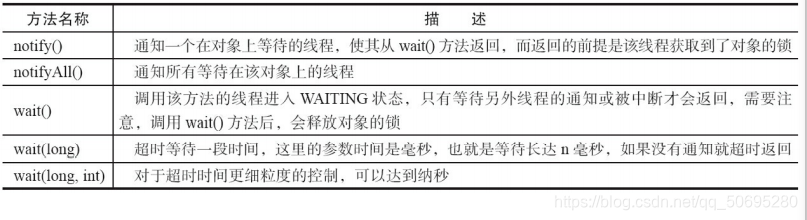
12.3.2等待/通知机制
图为: 等待/通知机制的方法
等待/通知机制:
线程A调用对象C的wait()方法进入**等待状态**,,
线程B调用对象C的notify()或者notifyall()方法
线程A收到notify()或者notifyall()的通知后继续执行
wait()和notify/notifyAll()如同红绿灯一样,用力完成等待方和通知方之间的交互工作,
等待/通知机制依托于同步机制
这样的好处是确保线程从wait()返回时能够感知到通知线程对变量做出的修改
import jodd.util.ThreadUtil;
import lombok.SneakyThrows;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.TimeUnit;
public class WaitNotify {
static boolean flag = true;
static Object lock = new Object();
public static void main(String[] args) throws Exception {
Thread waitThread = new Thread(new Wait(), "WaitThread");
waitThread.start();
//流程2
//主线程休眠1秒
TimeUnit.SECONDS.sleep(1);
Thread notifyThread = new Thread(new Notify(), "NotifyThread");
notifyThread.start();
}
static class Wait implements Runnable {
@SneakyThrows
@Override
public void run() {
synchronized (lock) {
while (flag) {
System.out.println(Thread.currentThread() + "flag is true: " + new SimpleDateFormat("HH:mm:ss").format(new Date()));
//流程1
//线程Wait进入休眠
lock.wait();
}
//流程4
//同Notify抢夺cpu执行权
System.out.println(Thread.currentThread() + " flag is false. running " + new SimpleDateFormat("HH:mm:ss").format(new Date()));
}
}
}
static class Notify implements Runnable {
@Override
public void run() {
synchronized (lock){
//流程3
//唤醒线程Wait()
System.out.println(Thread.currentThread() + " hold lock. notify @ " +
new SimpleDateFormat("HH:mm:ss").format(new Date()));
lock.notifyAll();
flag = false;
ThreadUtil.sleep(5000);
}
//流程4
//同Wait抢夺cpu执行权
synchronized (lock) {
System.out.println(Thread.currentThread() + " hold lock again. sleep " + new SimpleDateFormat("HH:mm:ss").format(new Date()));
ThreadUtil.sleep(5000);
}
}
}
}
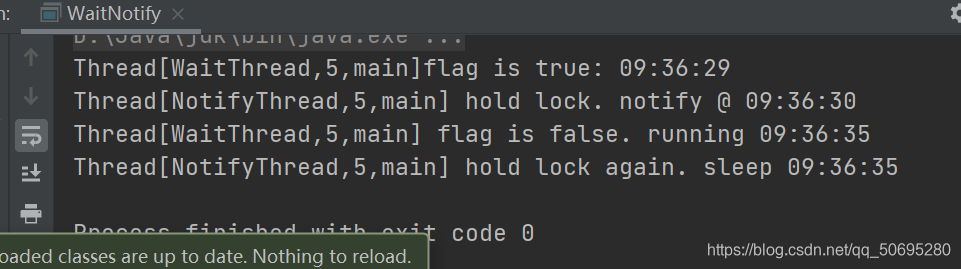
图为 运行结果1
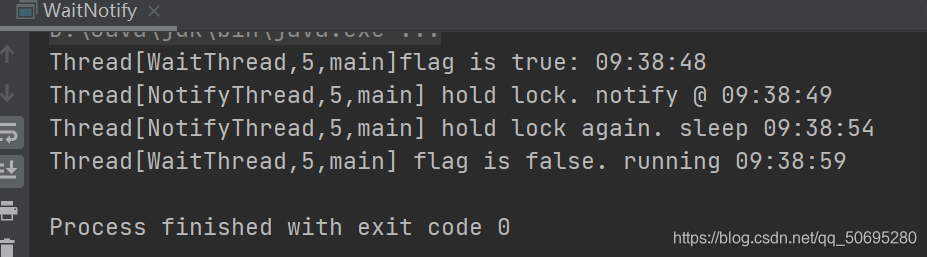
图为:运行结果2
这说明调用wait(),notify()/notifyAll()时的细节
- 使用前先对调用对象加锁
- 调用wait()后,线程状态由RUNNING变为WAITNG,并将当前线程放置对象的等待队列
- notify()/notifyAll()调用后,等待线程不会从wait()返回,需要notify()/notifyAll()释放锁后,等待线程才从wait()返回..即从wait()返回的前提是获得调用对象的锁
- notify()方法将等待队列中的一个等待线程从等待队列中移到同步队列中,
- 而notifyAll()方法则是将等待队列中所有的线程全部移到同步队列,被移动的线程状态由WAITING变为BLOCKED。
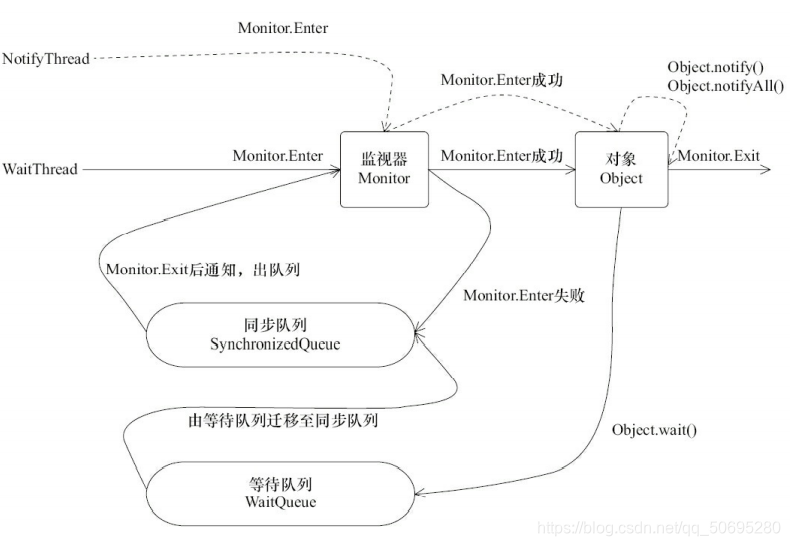
图为: WaitNotify java运行过程
在上图中
- WaitThread先获取对象锁,
- 调用对象的wait()方法,放弃锁,
- 进入等待队列WaitQueue,进入等待队列
- 由于WaitThread释放对象的锁,NotifyThread随后获取对象的锁,
- NotifyThread调用对象的notify()方法,将WaitThread从WaitQueue移动到SynchronizedQueue中,此刻WaitThread状态变为阻塞状态
- NotifyThread释放锁后,WaitThread获取锁并从wait()返回继续执行
12.3.3等待/通知机制的经典范式
从上一小姐中骂我们可以提取等待/通知的经典范式,
分别针对等待方(消费方)和通知方(生成者)
消费者遵循的原则如下:
- 获取对象的锁
- 条件不满足,调用对象的wait()方法,被通知后仍要检查条件
- 条件满足则执行对应的逻辑
synchronized(对象){
while(条件不满足){
对象.wait();
}
对应的处理逻辑
}
生成者遵循的原则如下:
- 获取对象的锁
- 改变条件
- 通知在对象上等待的线程
synchronized(对象) {
改变条件
对象.notifyAll();
}
12.3.4管道输入/输出流
管道字节输入流:PipedOutputStream
管道字节输出流:PipedInputStream
管道字符输入流:PipedReader
管道字符输出流:PipedWriter
管道输入流主要用于
线程之间的数据传输
传输的媒介为内容
public class PipelineFlow {
public static void main(String[] args) throws Exception {
PipedWriter out = new PipedWriter();
PipedReader in = new PipedReader();
// 将输出流和输入流进行连接,否则在使用时会抛出IOException
out.connect(in);
Thread printThread = new Thread(new Print(in), "PrintThread");
printThread.start();
int receive = 0;
try {
while ((receive = System.in.read()) != -1) {
out.write(receive);
}
} finally {
out.close();
}
}
static class Print implements Runnable {
private PipedReader in;
public Print(PipedReader in) {
this.in = in;
}
@Override
public void run() {
int receive = 0;
try {
while ((receive = in.read()) != -1) {
System.out.print((char) receive);
}
} catch (IOException ex) {
}
}
}
}
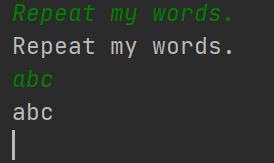
运行代码输入字符串,可以看到被printThread输出什么字符串
12.3.5Thread.join()
线程A执行了thread.join()的含义是:
当前线程A等待thread线程终止之后才从thread.join()返回
join(long millis)和join(long millis,int nanos)两个具备超时特性的重载
含义是
如果线程thread在给定的超时时间没有终止,将从该超时方法中返回
public class myJoin {
public static void main(String[] args) throws Exception {
Thread previous = Thread.currentThread();
for (int i = 0; i < 10; i++) {
// 每个线程拥有前一个线程的引用,需要等待前一个线程终止,才能从等待中返回
Thread thread = new Thread(new Domino(previous), String.valueOf(i));
thread.start();
previous = thread;
}
TimeUnit.SECONDS.sleep(5);
System.out.println(Thread.currentThread().getName() + " terminate.");
}
static class Domino implements Runnable {
private Thread thread;
public Domino(Thread thread) {
this.thread = thread;
}
@Override
public void run() {
try {
thread.join();
} catch (InterruptedException e) {
}
System.out.println(Thread.currentThread().getName() + " terminate.");
}
}
}
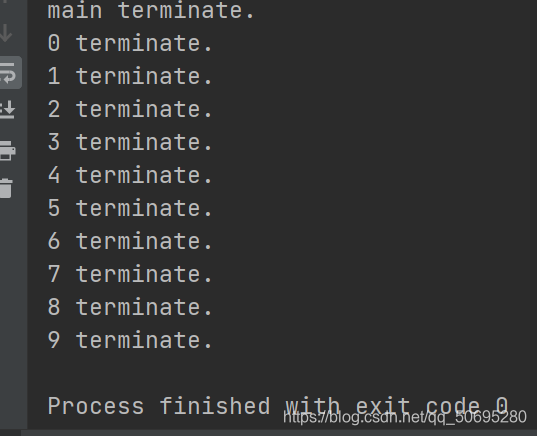
每个线程终止的前提是前驱线程的终止
等待前驱线程结束,接收前驱线程结束通知
每个线程等待前驱线程终止后,才从join()中返回
源码解读
当我们都用join()方法时走的是1326
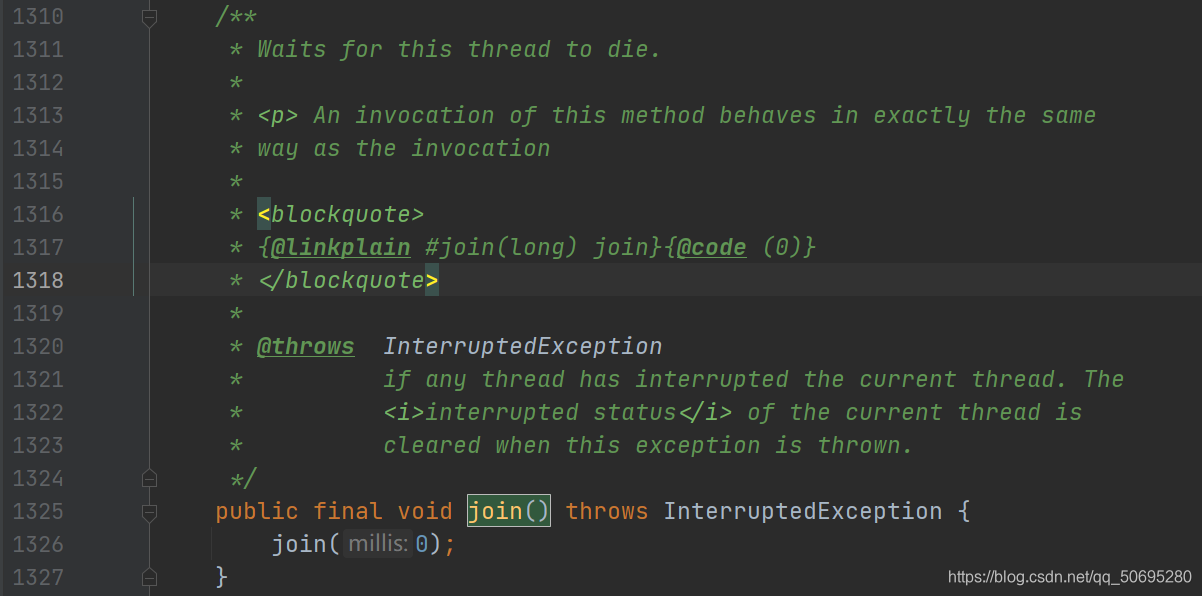
进入1326join(long millis)
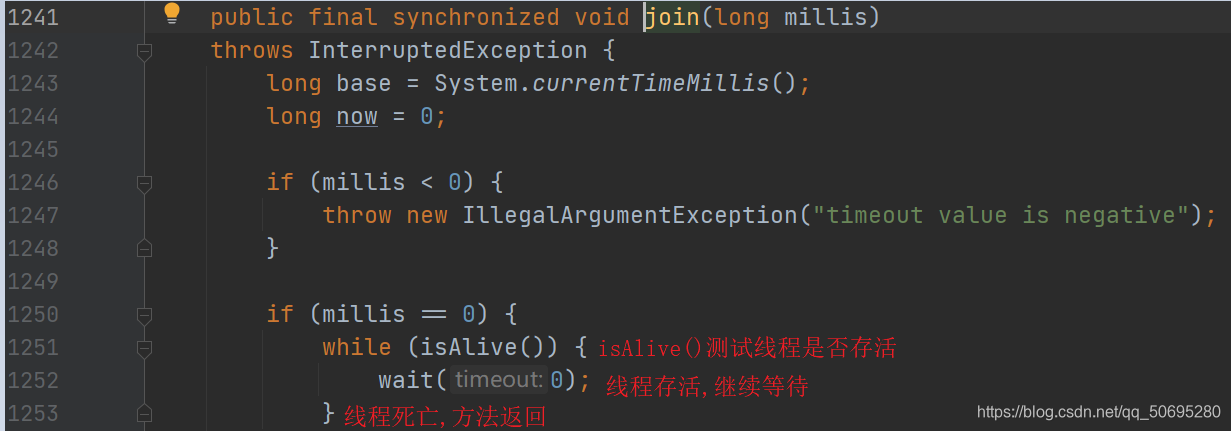
当线程终止时,会调用线程自身的notifyAll()方法,会通知所有等待在该线程对象上的线程
可以看出join()方法的逻辑结构和12.4.3 等待/通知机制的经典范式一致即
加锁,循环,处理
这3步
12.3.6ThreadLocal的使用
- 每个Thread维护一个ThreadLocalMap映射表
这个等Thread源码阅读完后写
点击进入—>Thread源码万字逐行解析
12.4线程的应用
12.4.1等待超时模式
我们先来复习一下前文的,等待/通知的经典范式,
加锁
条件循环
处理逻辑
而加入等待超时后,即使方法执行时间过长,也会按照调用者的要求"按时"返回
// 对当前对象加锁
public synchronized Object get(long mills) throws InterruptedException {
long future = System.currentTimeMillis() + mills;
long remaining = mills;
// 当超时大于0并且result返回值不满足要求
while ((result == null) && remaining > 0) {
wait(remaining);
remaining = future - System.currentTimeMillis();
}
return result;
}
十三Executor框架
在Java中线程即使工作单元,也是执行机制
JDK5出现Executor框架,把工作单元与执行机制分离开
工作单元包括 Runnable和 Callable
执行机制是 Executor框架
13.1Executor框架的两极调度模型
搞不懂2021/10/13/18:05
13.2Executor框架的结构
搞不懂2021/10/13/18:16鸽了鸽了
Executors.newSingleThreadExecutor():只有一个线程的线程池,因此所有提交的任务是顺序执行
Executors.newCachedThreadPool():线程池里有很多线程需要同时执行,老的可用线程将被新的任务触发重新执行,如果线程超过60秒内没执行,那么将被终止并从池中删除
执行很多短期异步的任务
Executors.newFixedThreadPool():拥有固定线程数的线程池,如果没有任务执行,那么线程会一直等待
执行长期任务,
Executors.newScheduledThreadPool():用来调度即将执行的任务的线程池
Executors.newWorkStealingPool(): newWorkStealingPool适合使用在很耗时的操作,但是newWorkStealingPool不是ThreadPoolExecutor的扩展,它是新的线程池类ForkJoinPool的扩展,但是都是在统一的一个Executors类中实现,由于能够合理的使用CPU进行对任务操作(并行操作),所以适合使用在很耗时的任务中



十四ConcurrentHashMap
14.1ConcurrentHashMap的实现原理
ConcurrentHashMap是线程安全且高效 的hashMap,
由于HashMap线程不安全,如下,在jdk1.8之前是头插法,会出现死循环问题
jdk1.8后引入了 红黑树 和 尾插法 扩容
但在多线程下还是有问题
而HashTable是通过synchronized来保证线程的安全,但在线程竞争激烈的情况下HashTable的效率底下,因为所有访问HashTable的线程都必须竞争同一吧锁,
假如容器里有多吧锁,
每一把锁用于锁容器其中一部分数据,
那么当多线程访问容器不同数据段的数据时,
线程就不会存在锁竞争,从而提高并发效率,
这就是ConcurrentHashMap的 锁分段技术
,
先将数据分成一段一段的存储,给每一段数据分配一把锁,当一个线程占用锁访问其中一段数据时,其它段的数据也能被其它线程访问
14.2ConcurrentHashMap的结构
ConcurrentHashMap是由 Segment数组结构 和 HashEntry数组结构组成
Segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色,且以数组的形式存在于一个ConcurrentHashMap中.
HashEntry则用于存储键值对
一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素
每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组数据修改时,必须先获取它对应的Segment锁
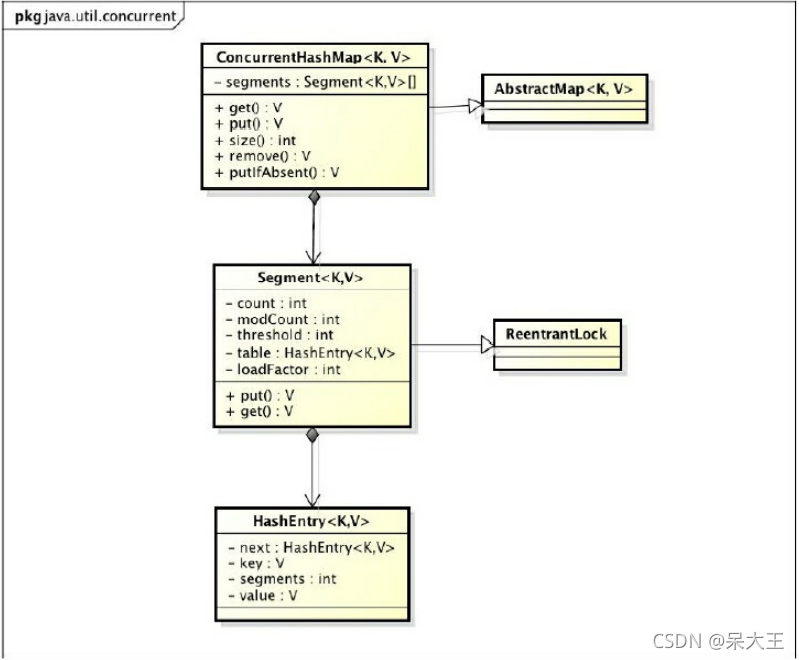
ConcurrentHashMap;类的结构图1
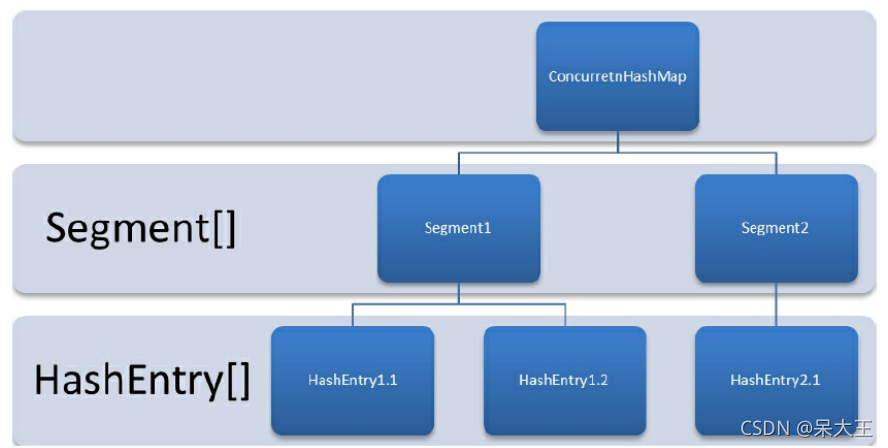
ConcurrentHashMap结构图2
14.3ConcurrentHashMap的操作
十五ConcurrentLinkedQueue
线程安全的队列有两种方式:
- 阻塞算法
- 非阻塞算法
阻塞算法的的队列可以用 锁 来实现
非阻塞算法的队列可以用 CAS 方式来实现
Doug Lea是如何使用非阻塞的方式来实现线程安全队列ConcurrentLinkedQueue的呢?
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列,它先进先出的FIFO队列,
当添加原始元素时,元素被添加到队列尾部
获取元素时,获取队列 头部的元素
15.1ConcurrentLinkedQueue的入队列
入队列就是将节点添加到队列尾部
假设在一个队列中依次插入4个节点
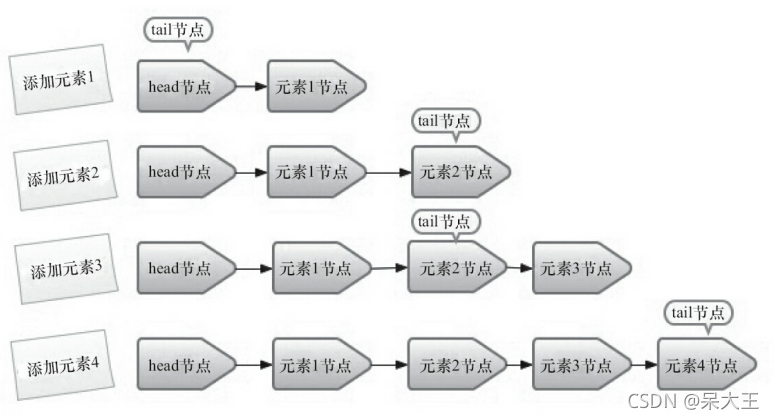
·添加元素1。队列更新head节点的next节点为元素1节点。又因为tail节点默认情况下等于head节点,所以它们的next节点都指向元素1节点。
·添加元素2。队列首先设置元素1节点的next节点为元素2节点,然后更新tail 节点指向元素2节点。·
·添加元素3,设置tail节点的next节点为元素3节点。
·添加元素4,设置元素3的next节点为元素4节点,然后将tail节点指向元素4节点。
观察发现head节点和tail节点的变化,发现入队主要做两件事情:
-
将入队节点设置成当前队列尾节点的下一个节点
-
更新tail节点,
如果tail节点的next节点不为空,则将入队节点设置为tail节点
如果tail节点的next节点为空,则将入队节点设置成tail的next节点
所以:
tail节点不总是尾节========================================================
通过上面的分析,我们从 单线程入队 的角度理解了入队过程,但是 多线程同时入队 那么情况就复杂了
eg:一个线程正在入队,
那么它的 在获取尾节点,并将尾节点的next节点设置为入队节点时
可能其他线程插队将队列的尾节点发送变化
那么
当前线程只能暂停入队操作,然后重新获取尾节点
这样当前线程不断的 CAS算法入队
我们通过源码看看当前线程是如何CAS入队的::::
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
// 入队前,创建一个入队节点
Node<E> n = new Node<E>(e);
retry:
// 死循环,入队不成功反复入队。
for (;;) {
// 创建一个指向tail节点的引用
Node<E> t = tail;
// p用来表示队列的尾节点,默认情况下等于tail节点。
Node<E> p = t;
for (int hops = 0; ; hops++) {
// 获得p节点的下一个节点。
Node<E> next = succ(p);
// next节点不为空,说明p不是尾节点,需要更新p后在将它指向next节点
if (next != null) {
// 循环了两次及其以上,并且当前节点还是不等于尾节点
if (hops > HOPS && t != tail)
continue retry;
p = next;
}
// 如果p是尾节点,则设置p节点的next节点为入队节点。
else if (p.casNext(null, n)) {
/*如果tail节点有大于等于1个next节点,则将入队节点设置成tail节点,
更新失败了也没关系,因为失败了表示有其他线程成功更新了tail节点*/
if (hops >= HOPS)
casTail(t, n); // 更新tail节点,允许失败
return true;
}
// p有next节点,表示p的next节点是尾节点,则重新设置p节点
else {
p = succ(p);
}
}
}
}
整个入队过程两件事:
定位出尾节点,
使用CAS算法将入队节点设置成尾节点的next节点,如果不成功则重试
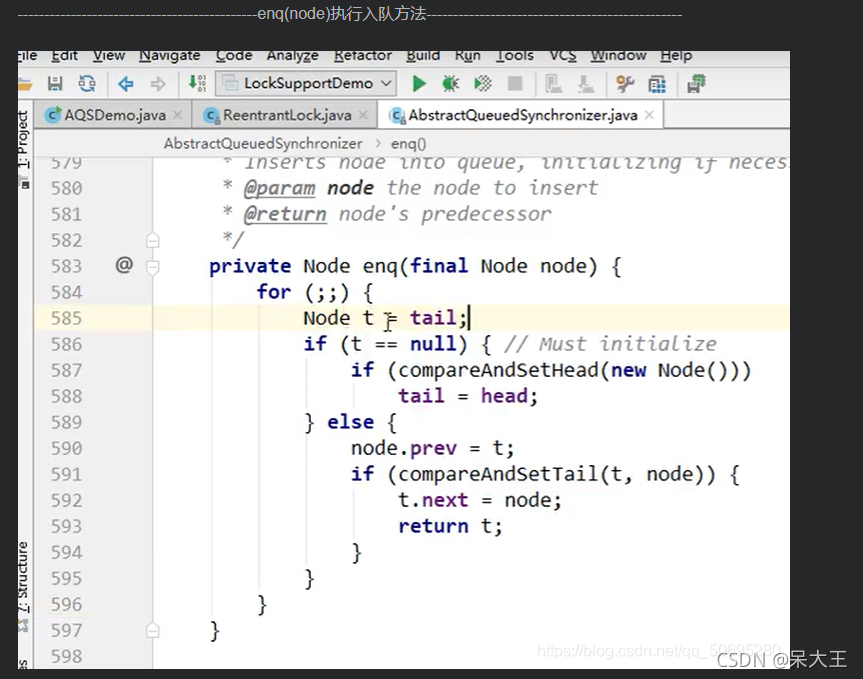
585 将tail节点赋值给t
586 如果t为空,只有一种情况tail节点为空,那就是队列初始化的时候,因为哪怕队列中有一个节点,那么这个节点就是tail,tail也不会为空.现在tail为空说明,队列中一个节点也没有
587 compareAndSetHead(new Node) 如果没有节点创建一个傀儡节点
588 将new Nade傀儡节点设置为 head
589 如果tail不为null
590 将入队节点的头节点指向tail
591
592 将tail节点的next节点设置为入队节点
15.1.2定位尾节点
tail节点并不总是尾节点.
所以每次入队先通过tail节点来找到尾节点
尾节点可能是tail节点,也可能是tail节点的next节点
代码中循环体第一个if就是判断tail是否有next节点,
有则表示next节点可能是尾节点
获取tail节点的next节点需要注意的是p节点等于p的next节点的情况
只有一种可能就是p节点和p的next节点都等于空,就是这个队列刚初始化,
获取p节点的next节点代码如下:
final Node<E> succ(Node<E> p){
Node<E> next = p.getNext():
return (p == next) head:next;
}
15.1.3设置入队节点为尾节点
p.casNext(null,n)方法用于将入队节点设置 为当前队列尾节点的next节点,如果p是null
表示p是当前队列的尾节点,如果不为null,表示有其他线程更像是了尾节点.则
需要重新获取当前队列和尾节点
15.1.4tail节点不总是尾节点的原因
假设tail节点永远作为队列的尾节点,这样逻辑清晰且易懂,
但是
每次都需要使用CAS更新tail节点
如果减少CAS更新tail节点的次数
那么 入队的效率 就提高了
所以 doug kea使用 一个 hops 变量来控制并减少tail节点的更新频率
当 tail节点和 尾节点 的距离大于等于 hops的值时, 才更新tail节点
这样 tail与 尾节点的距离越长(即 hops的值越大)
使用CAS更新tail节点的频次越少
那么是不是 hops越大 越好?
不是的
当 hops越大.,
由于 每次入队时定位尾节点 的循环体 需要多一次循环来定位 出尾节点
所以 hops越大 每次入队时定位尾节点的时间就越长
总结 tail节点不总是尾节点的原因:
通过增加 对 volatile变量的 读操作 减少对 volatile变量的写操作,
由于volatile的写操作开销大于读操作,
所以 tail节点不总是尾节点
15.2ConcurrentLinkedQueue的出队列
出队列的本质是:
从队列中返回一个节点元素,并清空该节点对元素的引用
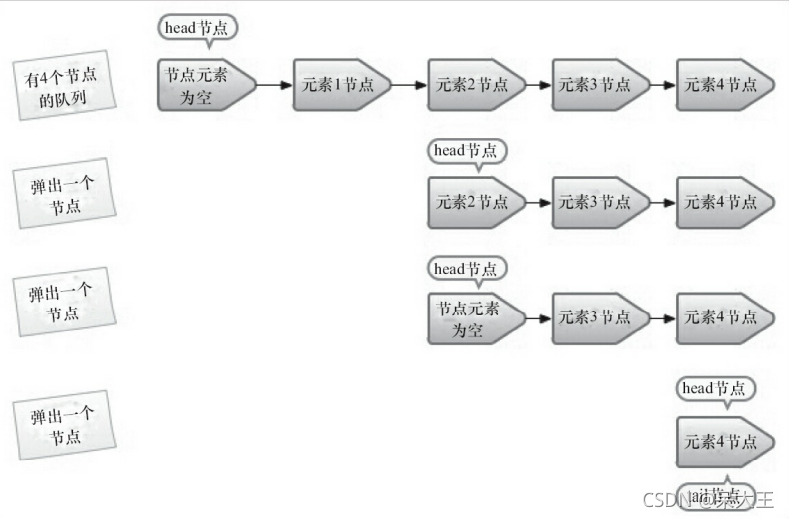
如图: 并不是每次出队列时都更新head节点
当head节点有元素时,直接弹出head节点的元素,而不会更新head节点
当head节点没有元素时,出队才会更新head节点
这样也是通过 hops变量来减少使用CAS更新head节点的消耗.从而提高出队效率
public E poll() {
Node<E> h = head;
// p表示头节点,需要出队的节点
Node<E> p = h;
for (int hops = 0; ; hops++) {
// 获取p节点的元素
E item = p.getItem();
// 如果p节点的元素不为空,使用CAS设置p节点引用的元素为null,
// 如果成功则返回p节点的元素。
if (item != null && p.casItem(item, null)) {
if (hops >= HOPS) {
// 将p节点下一个节点设置成head节点
Node<E> q = p.getNext();
updateHead(h, (q != null)q :p);
}
return item;
}
// 如果头节点的元素为空或头节点发生了变化,这说明头节点已经被另外
// 一个线程修改了。那么获取p节点的下一个节点
Node<E> next = succ(p);
// 如果p的下一个节点也为空,说明这个队列已经空了
if (next == null) {
// 更新头节点。
updateHead(h, p);
break;
}
// 如果下一个元素不为空,则将头节点的下一个节点设置成头节点
p = next;
}
return null;
}
先获取头节点元素,
判断头节点元素是否为空如果不为空,使用CAS将头节点的引用设置为null
如果CAS成功,则直接返回头节点元素
如果不成功,表示另一个线程已经进行了出队操作,更新了head节点,需要重新获取头节点
十六阻塞队列
BlockingQueue是一个支持 阻塞的 插入 和 移除 的队列
- 支持阻塞的 插入 : 当队列满时,队列会阻塞插入元素的线程,直到队列不满
- 支持阻塞的 移除 : 当队列为空时, 获取元素的线程会等待队列变成非空
阻塞队列常用于生产者 和 消费者的场景(生产者向队列添加元素,消费者从队列取元素, 阻塞队列就是元素的容器)
-
抛出异常 : 当队列满时,再往队列里插入元素,会抛出IllegalStateException(“Queuefull”)异常。当队列空时获取元素会抛出NoSuchElementException异常。
-
返回特殊值 : 当往队列里插入元素时,会返回元素是否插入成功 ,成功返回true. 当往队列移除元素时,如果没有则返回null
-
一直阻塞 : 当阻塞队列满时, 如果生产者线程往队列里put元素,队列会一直阻塞生产者线程,直到队列可用或者响应中断退出… 当队列为空时,如果消费者线程从队列中移除元素 ,队列会阻塞消费者线程, 直到队列不为空.
-
超时退出:当阻塞队列满时,如果生产者线程往队列里插入元素,队列会阻塞生产者线程一段时间,如果超过了指定的时间,生产者线程就会退出。

注意 如果是无界阻塞队列,队列不可能会出现满的情况,所以使用put或offer方法永远不会被阻塞,而且使用offer方法时,该方法永远返回true。
jdk7有7个阻塞队列:
- ·ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
- DelayQueue:一个使用优先级队列实现的无界阻塞队列。
- SynchronousQueue:一个不存储元素的阻塞队列。
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
-
公平访问队列是指阻塞线程,可以按照阻塞的先后顺序访问队列
即 先阻塞的线程先访问队列 -
非公平是对先等待的线程是非公平的
即 当队列可用时 ,阻塞的线程都有访问队列的资格, 有可能先阻塞的线程最后访问队列
了保证公平性,通常会降低吞吐量。
16.1ArrayBlockingQueue
ArrayBlockingQueue是 数组 实现的 有 界阻塞队列
先进先出(FIFO) 的原则对元素排序
创建一个 公平的阻塞队列
ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000,true);

16.2LinkedBlockingQueue
LinkedBlockingQueue是 链表 实现的 有 界阻塞队列
此队列的默认和最大长度为 Integer.MAX_VALUE。
先进先出(FIFO) 的原则对元素排序
16.3PriorityBlockingQueue
PriorityBlockingQueue是支持 优先级 的 无 界阻塞队列,
默认情况下元素采取 自然顺序升序 排序
可以通过自定义类实现compareTo()方法指定元素排序规则
或者初始化PriorityBlockingQueue队列时,指定 构造参数Comparator对元素进行排序
注意:
- 不能保证同优先级元素的顺序。
- 如果一直有优先级高的任务提交到改队列,队列中优先级低的任务永远不能执行
16.4DelayQueue
DelayQueue是支持 延时获取元素 的 无 界阻塞队列
队列的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素(只能在延迟期满才可以从队列提取元素)
应用场景:
- 缓存系统:DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue获取元素,表示缓存期到了
- 定时任务调度: 使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,比如 TimerQueue就是通过DelayQueue实现的
时间轮(TimingWheel)
在Netty,Zookeeper,Kafka等各种框架中,甚至Linux内核中都有用到。
其底层就是使用了DelayQueue概念描述:
时间轮(TimingWheel): 实现延迟功能(定时器)的巧妙算法理解时间轮使用动态图来理解时间轮<–点击进入
代码实现:
gethub搜索TimingWheel找到java实现的TimingWheel
那么如何实现Delayed接口呢?
DelayQueue队列的元素必须实现 Delayed接口
一共3步
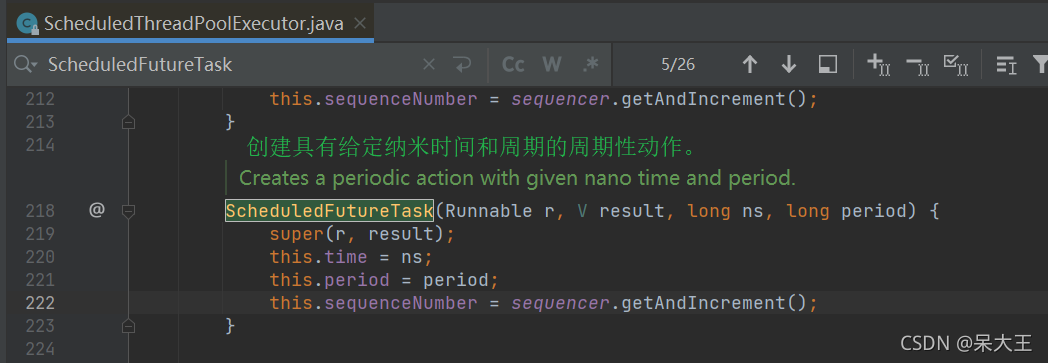
-
在对象创建时,初始化基本数据.
time记录当前对象延迟到什么时候可以使用,
sequenceNumber记录元素在队列的先后顺序
源码如下:
-
实现getDelay方法,该方法返回当前元素还需要延时多长时间,单位是纳秒
源码如下:

通过构造函数可以看出延迟时间参数ns的单位是纳秒
注意
当time小于当前时间时,getDelay会返回负数
自己写的时候最好也是纳秒,
因为实现getDelay()方法可以指定任意单位,一旦以秒或分为单位,而延时时间又精确不到纳秒就麻烦了 -
实现compareTo方法指定元素顺序,
eg:让延时时间最长的放在队列的末尾
public int compareTo(Delayed other) {
if (other == this) // compare zero ONLY if same object
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<> x = (ScheduledFutureTask<>)other;
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long d = (getDelay(TimeUnit.NANOSECONDS) -
other.getDelay(TimeUnit.NANOSECONDS));
return (d == 0) 0 : ((d < 0) -1 : 1);
}
说实话 我是没看懂代码
,
那么如何实现延时阻塞队列?
当消费者从队列里获取元素时,判断一下延时时间,没达到就阻塞当前线程
如下.leader是一个等待获取队列头部元素的线程
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if (delay <= 0)
return q.poll();
//如果leader!=null,说明已经有线程在等待获取队列的头元素
else if (leader != null)
//所以,使用await()让当前线程等待信息
available.await();
else {
//如果leader为null将当前线程赋值给leader
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
//调用awaitNanos()放当前线程等待接收信号或等待delay时间
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
16.5SynchronousQueue
SynchronousQueue 是一个 不存储元素 的阻塞队列
每一个put操作必须等待一个take操作,否则不能继续添加元素
默认情况下
线程常用非公平策略访问队列,但它也支持公平访问队列

点击进入:
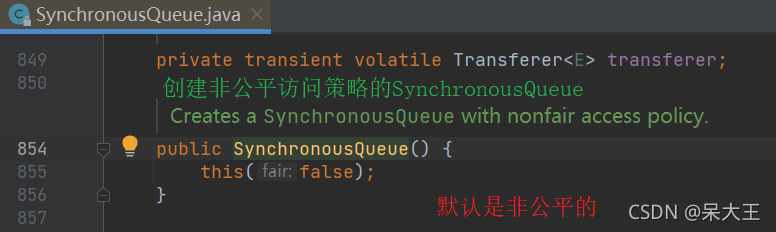
在点击进入

应用场景:
SynchronousQueue 负责吧生产者线程处理的数据直接传递给消费者线程
队列本身不存储任何元素,非常适合传递性场景
SynchronousQueue 的吞吐量高于LinkedBlockingQueue和ArrayBlockingQueue
16.6LinkedTransferQueue
LinkedTransferQueue是一个由 链表 结构组成的 无界 阻塞队列
相对于其他阻塞队列,LinkedTransferQueue多了tryTransfer和transfer方法。
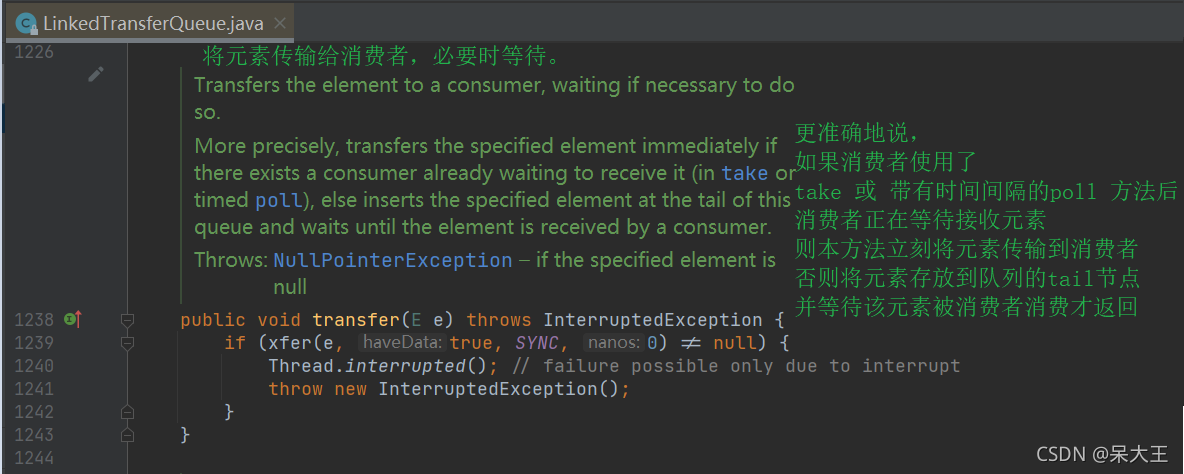
16.6.1transfer()
这个方法名翻译就是: 转移,传输 的意思.
2021/9/30/18:45 加班摸鱼写,我急着给祖国母亲庆生
这个方法太难了

16.6.2trytransfer()
尝试将生产者传入的元素直接传递给消费者,
如果没有消费者消费该元素 则等待指定的时间在返回
如果超时还没有消费该元素,则返回false
如果在超时时间内消费了元素,则返回true
如果没有消费者等待接收元素,则返回false。
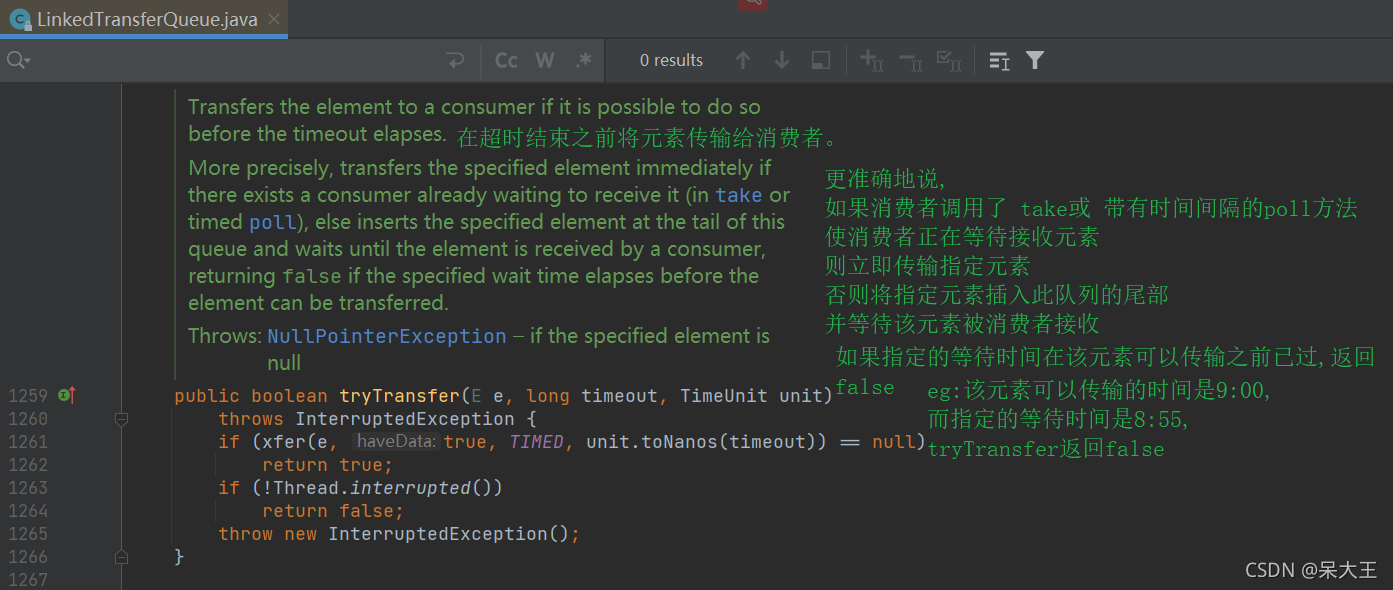
transfer()和tryTransfer()的区别是:
tryTransfer()无论消费者是否接收,方法立即有返回值
transfer()必须等到消费者消费后才有返回值
16.7LinkedBlockingDeque
是一个 有链表结构组成的 双向阻塞队列
双向队列: 可以从队列两端插入和移出元素
由于双向队列多了一个入队列的地方,所以多线程同时入队时减少了一半的竞争
常见方法有:
addFirst()将元素插入到队列头
addLast()将元素插入到队列尾
offerFirst()将该元素设置为队列头,如果队列已经满了,返回false
offerLast()将该元素设置为队列尾,如果队列已经满了,返回false
peekFirst()获取队列头元素
peekLast()获取队列尾元素
removeFirst()删除队列头元素
removeLast()删除队列尾元素
在初始化LinkedBlockingDeque时可以指定容量,防止其过度膨胀
16.8阻塞队列的实现原理
获取队列是空的,消费者会一直等待,当生产者添加元素时,消费者是如何知道当前队列有元素的?
JDK使用了 通知模式 来实现
通知模式:
当生产者往满的队列添加元素时会阻塞住生产者,
只有当消费者消费了一个队列中的元素后,会通知生产者当前队列可用
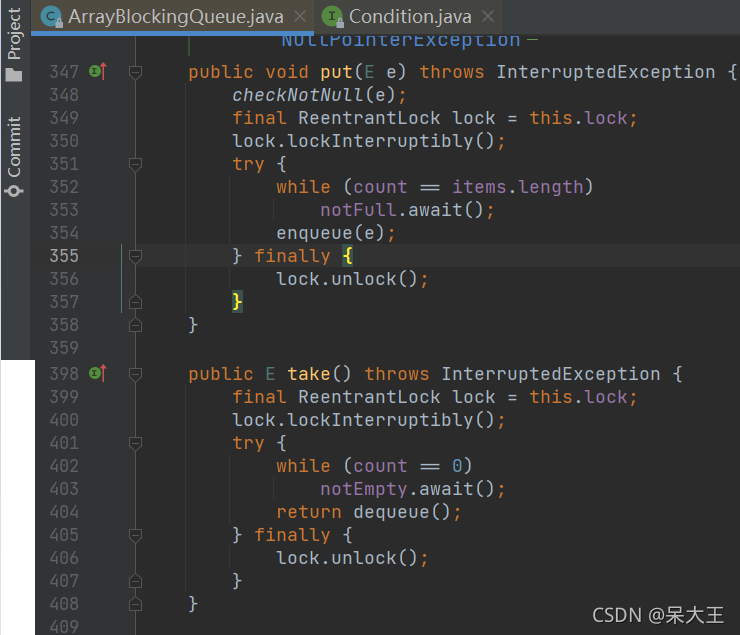
当往队列里插入一个元素时,如果队列不可用,那么阻塞生产者主要通过LockSupport.park(this) 来实现
比如我们进入ArrayBlockingQueue来看看它的put()和take方法
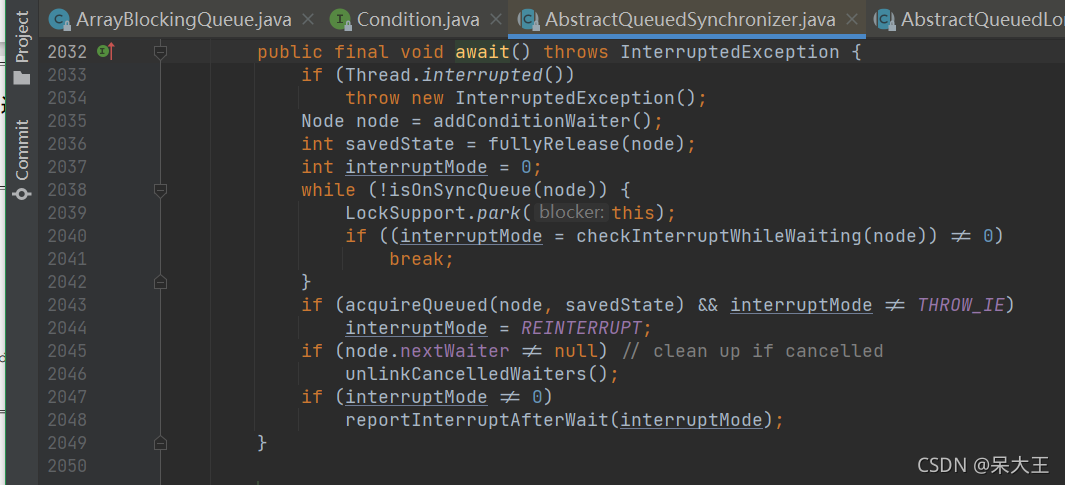
点击await()方法进入,就发现其实是使用了Condition来实现

进入Condition的await方法的实现
点击进入2039行 LockSupport.park(this);

173 获取当前线程对象
175 UNSAFE.park(false,0L)是个native方法,点击进入
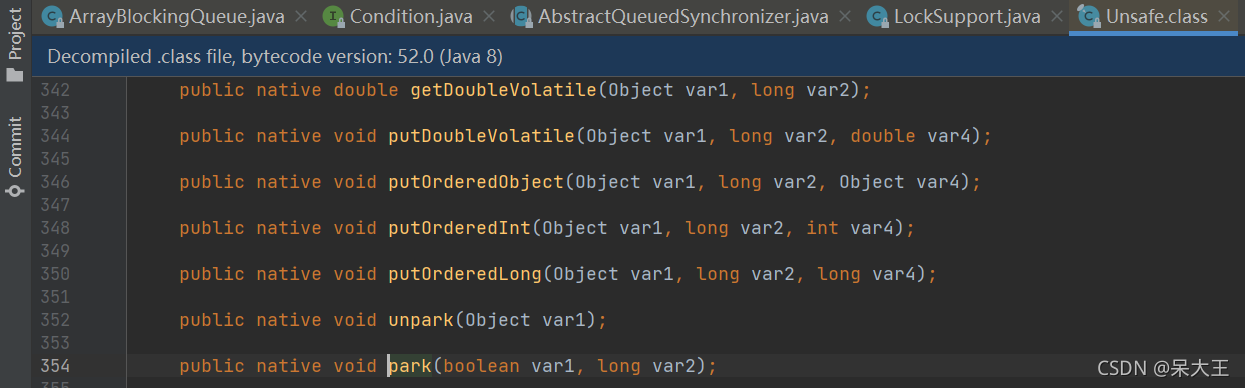
park这个方法会阻塞当前线程,只有以下4种情况中的一种发生时,该方法才会返回。
- 其它一些线程以当前线程为目标调用unpark
- 其它一些线程中断当前线程
- 其它不和逻辑的返回,当前线程会继续执行
- 等待完成time参数指定的毫秒数时
我们接着看JVM是如何实现park方法的:
在Linux下使用系统方法
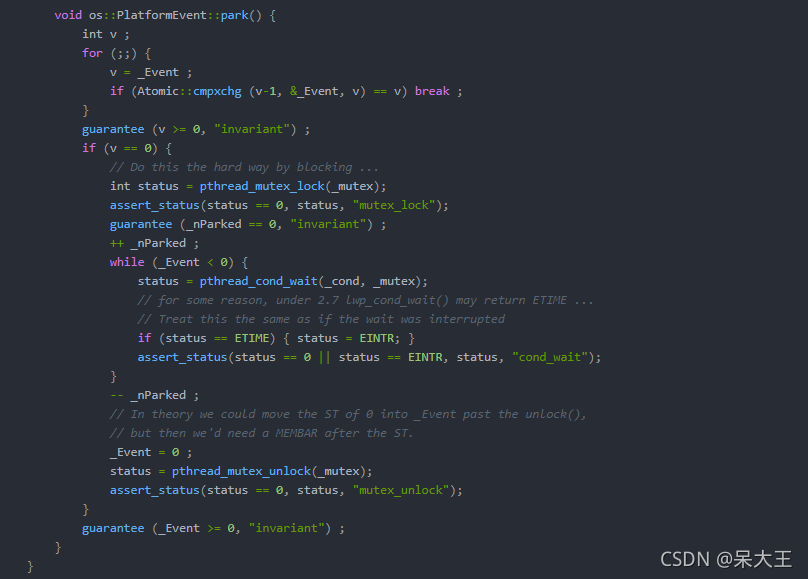
pthread_cond_wait实现的.实现代码在JVM源码路径src/os/linux/vm/os_linux.cpp里的os::PlatformEvent::park方法,
代码如下。
pthread_cond_wait是一个多线程的条件变量函数,cond是condition的缩写
字面意思为:线程在等待一个条件发生,这个条件是一个全局变量
这个方法接收两个参数:
一个是共享变量_cond
一个是互斥量_mutex在Windows下使用
WaitForSingleObject实现的unpark方法在Linux下使用的是
WaitForSingleObject实现的
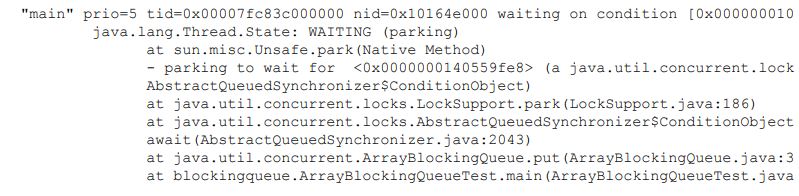
当线程被阻塞队列阻塞时,线程会进入 WAITING(parking)状态
我们可以使用 jstack dump数组的生产者线程看到:
十七Fork/Join框架
17.1什么是Fork/Join框架
Java7提供了一个用户 并行 执行任务的框架,
其作用是 吧大任务分割成若干小任务,最终汇总每个小任务结果后得到大任务结果的框架
Fork就是吧大任务切分为若干子任务 并行 的执行
Join就是 合并 这些子任务的执行结果,最终得到大人物的结果
比如:
计算1+2+3+4…+100,分割成10个小任务,每个子任务分别对10个数求和,最终汇总这个10个子任务的结果

图为:Fork/Join的运行流程图
17.2工作窃取算法
工作窃取(work-stealing)算法
是 某个线程从其他队列窃取任务来执行
比如: 有一个大任务,我们将大任务分割为若干互不依赖的子任务
为了减少线程竞争, 子任务放在不同的队列里,并每个队列创建一个单独的线程来执行队列里的任务,即线程和队列一一对应
但是有的线程会先把自己队列任务干完,它会去其它队列里 窃取 任务来执行
为了减少窃取任务线程和被窃取任务线程间的竞争 ,通常将队列设置为双端队列,
被窃取任务线程永远从双端头部拿任务执行
窃取任务线程永远从双端尾部拿任务执行
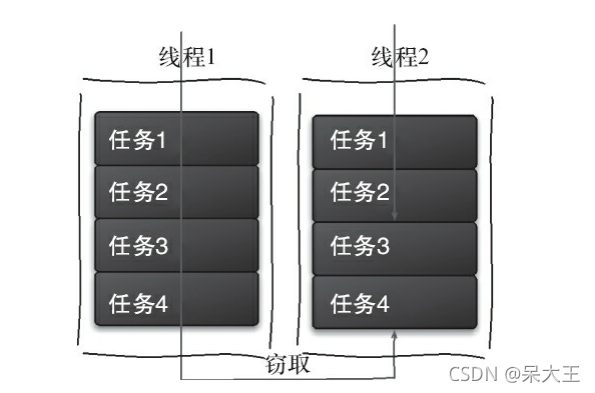
工作窃取算法的优点: 充分利用线程进行并行计算 ,减少线程间的竞争
工作窃取算法的缺点: 比如队列只有有一个任务时,还是存在竞争,并且该算法会消耗更多的系统资源(创建多个线程和多个双端队列)
17.3Fork/Join框架的设计
步骤1 分隔任务
一个fork类把大任务分隔成子任务,有可能子任务还是很大,所以需要不停分隔,直到子任务足够小
步骤2 执行任务并合并结果
分隔的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行… 子任务执行完的结果统一放在一个队列里,启动一个线程从队列里拿数据,最后合并数据
Fork/Join使用两个类来完成这两步
-
ForkJoinTask: 使用Fork/Join框架必须参加一个ForkJoin任务,该类提供了任务中执行fork()和join()操作的机制
通常我们继承 ForkJoinTask的两个子类RecursiveAction 没有返回值的任务 RecursiveTask 有返回值的任务
2. ForkJoinPool:ForkJoinTask需要 ForkJoinPool来执行
任务分割出的子任务会添加到当前工作现场所维护的双端队列头部
当一个工作线程完成了其任务,它随机从其他工作线程队列的尾部获取一个任务来执行
17.4使用Fork/Join框架
例如计算 1+2+3+4的结果
首先考虑的是如何分割任务,
如果希望自任务最多执行两个数相加,那么阈值是2
所以把这个任务 fork 成两个子任务,
最后 join 两个子任务的结果,
既然是有返回值的任务,需要使用 RecursiveTask 类
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
@Slf4j
public class ForkJoinDome {
public static void main(String[] args) throws ExecutionException, InterruptedException {
myFork myFork = new myFork(1, 4, 2);
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask submit = forkJoinPool.submit(myFork);
log.error("最终结果: " + submit.get());
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
@Slf4j
class myFork extends RecursiveTask {
private int startRow;
private int endRow;
private int threshold;//阈值
@Override
protected Integer compute() {
Integer result = 0;
//如果结束减去开始小于阈值,开始计算
if (endRow - startRow < threshold) {
System.out.println("开始计算的部分:startValue = " + startRow + ";endValue = " + endRow);
for (int index = startRow; index <= endRow; index++) {
result += index;
}
//如果结束减去开始大于阈值,开始创建子任务
} else {
myFork leftTask = new myFork(startRow, (startRow + endRow) / 2, threshold);
myFork rightTask = new myFork((startRow + endRow) / 2 + 1, endRow, threshold);
//执行子任务
leftTask.fork();
rightTask.fork();
//等待子任务执行完毕,获取其结果
Object leftJoin = leftTask.join();
Object rightJoin = rightTask.join();
//合并子任务
result = (Integer) leftJoin + (Integer) rightJoin;
}
return result;
}
}
通过这个例子,了解到ForkJoinTask需要实现compute()方法
在这个方法里
首先判断任务是否足够小,如果足够小就执行
不足够小分割成2个子任务,
每个子任务调用fork方法时,有会进入compute()方法
看看当前子任务是否需要继续分割成子任务,如果不需要继续分割,则执行当前子任务并返回结果
使用join()方法会等待子任务执行完并得到其结果
17.5Fork/Join框架的异常处理
ForkJoinTask在执行时可能抛出异常,但是没有办法在主线程中捕获异常,使用ForkJoinTask.isCompletedAbnormally()来检查任务是否抛出异常或已经被取消了.
并且可以通过font color=red>ForkJoinTask.getException()获取异常
,返回Throwable对象,
如果任务被取消则返回CancellationException
如果任务没有完成 或 没有抛出异常返回null
if(task..isCompletedAbnormally()){
System.out.println(task.getException());
}
17.6Fork/Join框架的实现原理
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成
ForkJoinTask数组负责将存放程序提交给ForkJoinPool的任务,
ForkJoinWorkerThread数组负责执行这些任务
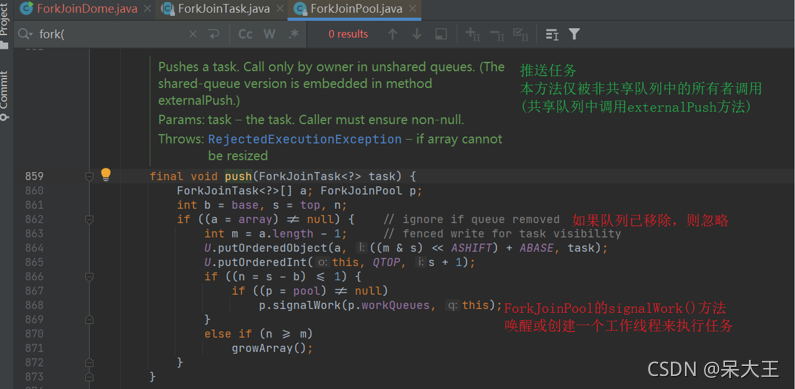
(1)ForkJoinTask的fork方法实现原理
调用fork方法时,程序会调用ForkJoinWorkerThread.pushTask来异步执行这个任务,然后返回结果

点击push方法
(2)ForkJoinTask的join方法实现原理
join方法主要是阻塞当前线程并等待获取结果
如下join的源码:
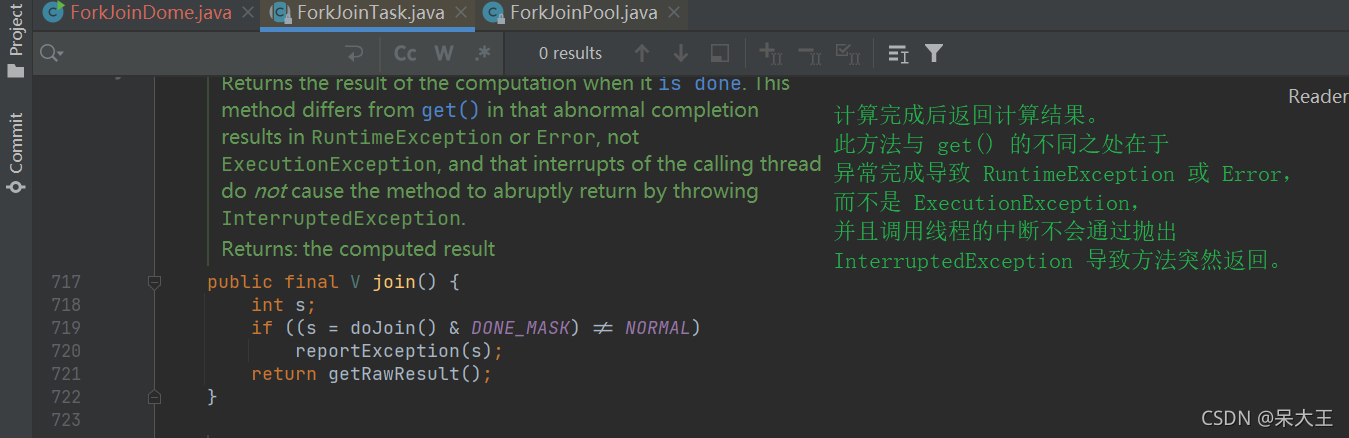
719行调用doJoin()方法,点击进入
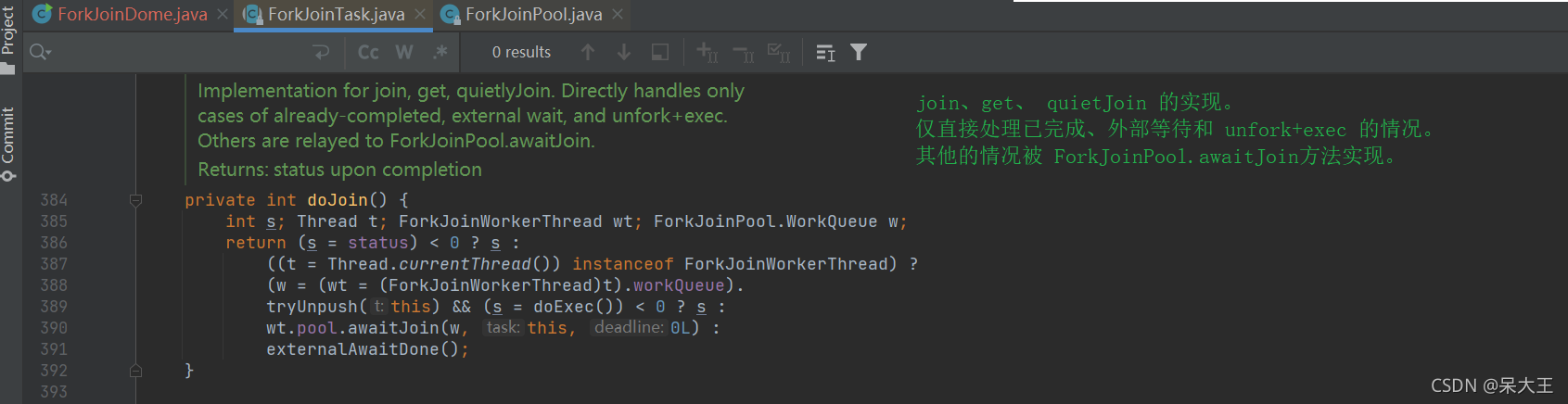
通过 dojoin() 方法得到当前任务的状态来判断返回什么结果,
任务的状态由4种:
已完成(NORMAL)、
被取消(CANCELLED)、
信号(SIGNAL)、
出现异常(EXCEPTIONAL)。
- 如果任务状态是已完成,则直接返回任务结果。
- 如果任务状态是被取消,则直接抛出CancellationException。
- 如果任务状态是抛出异常,则直接抛出对应的异常。
2021/10/13 18:28第一次编写完成,还有很多地方是搞不定的,
朝闻道,夕死可矣















 132
132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









